工业互联网中数字孪生系统的机理+数据融合建模方法
2022-11-09李硕刘天源黄锋解鑫张金义
李硕 刘天源 黄锋 解鑫 张金义
(百度在线网络技术有限公司,北京 100086)
0 引言
随着近十年工业互联网技术的快速发展、分布式传感器和高性能计算设备的逐渐进步以及仿真建模算法的更新迭代,学术界和工业界积累了海量的多层级数据,从不同角度反映了工业生产过程中的内在物理信息[1],这为大数据的发展提供了良好的土壤,形成了数据驱动的新型范式,学者们[2]将之称为“第四范式”——数据密集型科学发现,以区别于实验归纳范式、模型推演范式和仿真模拟范式3种传统研究范式,强调直接从大量已知数据中自行归纳、推导和预测,获得未知且可信的结论。
近5年来,以深度学习[3]为代表的数据驱动方法不仅在视觉、自然语言处理以及博弈类场景应用中超越了人类,更在蛋白质结构预测[4]、三体问题[5]、气象预报[6]、核聚变控制[7]等一系列基础科学以及工业界难题中取得了重大突破。可以断言,人类社会正处于由仿真模拟范式向数据密集型科学范式的过渡发展阶段。
在工业互联网数据和深度学习算法的双重驱动下,“数字孪生系统”(Digital Twin)[8]在这个时代被赋予了更强大的生命力,这种技术体系可以有效结合目前过渡阶段的仿真模拟和数据驱动方法,充分挖掘服役历史、实时传感数据以及物理知识,用数字虚拟模型表征物理实体状态,实现对物理系统的理解、学习、推理和预测。经过近十年的技术储备和发展,数字孪生系统已经被认为是工业互联网中的战略性技术之一,是解决新时代工业产品全生命周期中设计、制造、服役和运维问题的有效方法。
构建数字虚拟模型是数字孪生系统技术的重中之重。与传统基于物理机理的模型不同,数字孪生系统更强调仿真的快速实时(快速反映物理世界的变化、计算响应速度快)和反馈学习(利用物理实体反馈的数据进行自我学习和完善),并且要求建模和仿真可以和更多的工业真实场景实现频繁的信息交互,以便实现模型的自动更新迭代;而机理仿真受制于求解速度,对计算机资源消耗巨大,难以布置到工业现场的边缘设备中,且无法对物理世界反馈的数据和经验进行再学习,必须借助人类对数据的理解进行调整;纯粹的数据驱动模型难以嵌入物理规律以及领域知识,而现阶段传感器测量仍然存在固有缺陷,这导致构建的模型缺乏可解释性,尤其是在处理非线性、多学科和多尺度的物理系统时,模型的精度低、稳定性差且泛化能力严重不足。
总之,就目前发展而言,无论是机理仿真还是数据驱动均难以满足未来工业互联网的发展需求。
1 基本架构
一般的物理系统均遵循如下方程。
N[y](x;θ)=0
(1)
其中,x表示对物理系统模型的输入变量(时间、空间坐标等);y表示需要获得的输出变量(物理场、信号等超高维变量);N[y]表示输出y对输入x的各阶微分、差分、积分或非线性算子构成的映射,这个方程由物理第一性原理在具体场景中给出,例如描述航天飞行器运动中的万有引力和牛顿力学定律、流体力学中的N-S方程(N-S:Navier-Stokes)、电磁场的麦克斯韦(Maxwell)方程、统计力学中的玻尔兹曼(Boltzmann)方程、量子力学中的薛定谔(Schrödinger)方程等;θ表示系统参数,用来表征系统的拓扑、几何以及物理特性。
一般而言,为了获得y和x的映射关系,需要求解上述方程组。例如,连续介质力学中在空间域上采用有限元方法、有限体积方法离散,时间域利用Runge-Kutta法离散,当然更加灵活的无网格离散方法近年来也是研究热点之一。虽然在过去半个世纪得益于计算硬件以及算法的进步,基于机理的建模-仿真-求解方法获得了长足的发展,被广泛应用于工业领域,大幅减少了不必要的试验、加快了设计研发周期并节省了实际运维成本;但目前仍然面临诸多挑战:前处理以及后处理过程极度繁琐、计算时间过长或计算资源消耗过大、难以适应灵活的任务需求(如信息缺失时的反向问题);甚至在近十年基于传统机理方法的发展已经裹足不前[9]。
数据驱动的方法避免了求解上述复杂的数学物理方程,通过将关注的物理场或信号y简化为低维信息,然后采用一个近似模型逼近上述方程的解,例如设计优化中常用的经验公式、代理模型以及对物理减缩模型,从而采用机器学习模型构造输入和输出之间的映射关系,通过最小化模型预测和标记数据之间的差异确定模型中的待定参数,具体如公式(2)所示。
(2)

虽然工业物联网目前可以为数据驱动方法提供大量的训练数据,但这些数据存在分散性、有限性、高噪声以及潜在同质化的缺陷(例如在故障检测中,大量故障工况运行数据是无法采集的,而且传感器的可测量位置极为有限且噪声成分极大);同时,目前这种完全数据驱动的方法缺乏对物理系统的建模,使得专业人员无法解释这些数据,更不能高效地利用这些数据,而获得模型的精度和可靠性也存疑。
机理+数据融合模型通过将物理机理嵌入数据驱动模型[10]中,可充分发挥机理模型可解释性和泛化能力强、数据驱动模型灵活和可学习的优势。从机器学习的视角来看,需要根据实际物理问题满足的对称性以及工业场景选择合适的机器学习模型,此外还需引入如下物理机理以及工业过程任务需求的损失函数。

(3)


图1 数字孪生系统中3种建模方法之间的联系以及区别
数字孪生系统中3种建模方法的关系如图1所示,机理+数据融合模型整合了两种传统建模方式,具体而言,相比于公式(2),公式(3)修正了所有输出的损失函数为稀疏布置传感器的可测量输出损失,还引入了物理机理约束的正则项以及任务需求的目标,以确保学习获得的模型可以满足物理方程和任务需求的约束。
事实上,机理+数据融合建模方法的思想可以追溯到更早的物理学建模方法[11],例如传热学中的试验关联式和部件剩余寿命预测的经验公式都是基于这类思想——将复杂的物理系统通过经验知识简化为低自由度的系统,并抽象出简化过程中待定的参数,由于模型中包含了对物理系统的经验性反应,增强了模型的可解释性且减少了模型中的待定参数,推而广之,理论物理的重整化思想(如Boltzmann方程向N-S方程简化),工程的模型降维(如管道中忽略三维流动效应只研究沿管道流动方向的一维流动)本质都属于此类建模方法。相关抽象目前是由人工经验或领域知识给出的,而在机理+数据融合模型中,有望通过模型选择、物理约束以及任务需求将这个抽象过程通过机器学习或数据驱动方法表征出来,接下来本文主要从这3个方面讨论机理+数据融合建模方法的最新研究进展。
2 研究进展
2.1 模型选择
传统的代理模型(Surrogate Model)(如多项式、支持向量机、径向基模型、基于树的模型、高斯过程等方法)通过直接构造输入参数和输出的映射关系形成代理模型,由于模型简单且无需人工干预,被广泛应用于计算成本较高的黑箱函数的优化和控制任务中[12],但难以处理物理建模中所关注的物理场信息(一般可表示为在空间域和时间域上分布的高维张量)。过分简化的建模方式缺乏对物理系统本身的关注,依赖繁琐的特征工程以及大量数据采样,因此难以适用于精细化的物理系统建模。
减缩模型(Reduced Order Model)是通过数据驱动的方法或者经验分解的方法对原始的物理系统进行降阶或减缩,减少对高维信息描述的复杂度,继而加快对物理场或信号的求解和预测,常用的方法有本征正交分解和动态模态分解等方法。这些方法不仅展现出了良好的效果,同时也具备一定的可解释性;但也存在明显的缺陷,如处理复杂非线性问题依赖于核函数、基函数的选择,与问题不匹配时可能会导致模型表达能力不足或者训练收敛困难;此外,在将整个物理场或信号展开成一维向量时,未对定义在求解域的时空关联性以及物理量间的关联性建模,无法捕捉时间上的瞬态突变、空间上多尺度的信息,不具备物理约束中要求的空间平移、旋转不变性,限制了本身的应用范围[13]。
利用神经网络(Neural Network)作为近似映射对物理系统建模、求解可以追溯到20世纪90年代的若干工作[14-15]中,但受制于硬件效率以及算法的灵活性,一直以来没有被关注。
自2012年以来,深度神经网络的发展将机器学习方法带入了深度学习(Deep Learning)时代,相比于传统机器学习,深度学习具备更强的表达能力、更广泛的适应性、更显著的灵活性。
从计算机视觉和时序信号处理中发展出的各种神经网络算子,如卷积神经网络(Convolutional Neural Network,CNN)、关注时序信号的循环神经网络(Recurrent Neural Network,RNN)以及近年发展迅速的Transformer结构、图神经网络(Graph Neural Network,GNN)结构以及处理离散点云数据的点云网络等结构,可以灵活地处理工业互联网或机理仿真获得的超高维数据。例如,CNN可以有效地分析结构化数据[16];RNN适合对时间关联信息建模[17];图神经网络可以适应非结构化网格数据[18];点云网络可以用于处理无网格的物理场[19];注意力机制可以处理多尺度物理信息[20];利用傅里叶算子分解[21]可以捕捉物理场的低频成分,提升模型对物理系统的表征性能。同时,这些方法保留了物理场在空间域、时间域以及拓扑内的不变性,通过这些物理对称性的约束可以显著减少模型的冗余度并增强可解释性,使得模型可以更加有效地处理超高维的物理系统。
2.2 物理约束
在损失函数中引入物理系统方程的正则项约束,典型工作是物理信息神经网络(Physics-Informed Neural Network,PINN)[22],这种方法通过自动微分机制将物理系统遵循的动力学方程的微分形式纳入模型的损失函数中,使模型具备更强的物理解释性和对参数θ的泛化能力。PINN方法由于采用深度神经网络,充分利用深度学习中的自动微分机制,将物理约束通过损失函数引入神经网络,形成了端到端的微分方程求解器[23],补充了必要的边界条件或初始条件等,即可应用于各种偏微分方程和常微分方程的求解,如流体力学N-S方程[24]、弹塑性问题的静力学方程[25]、量子力学中的薛定谔方程[26]、分数阶微分方程[27]、气象问题的洛伦兹方程[28]、新冠病毒传播的动力学模型[29]。
PINN方法是目前机理+数据融合建模方法中发展的较为成熟的方向,在学术界引起了广泛的关注,且许多研究机构基于主流深度学习框架开发了相应的架构(见表1),目前除了美国以外,我国的国防科技创新研究院和百度公司也率先开发了相应的架构,尤其是百度公司目前基于国产化的深度学习框架PaddlePaddle开发的Paddle Science。
当然除了上述的自动微分方法引入物理约束,还有一些结合传统机理仿真模型的引入方式,例如利用有限差分、有限体积和有限元[39]格式构造。广义而言,谱方法、无网格方法也可以看作其中的一种,只是这两种方法选择了另外的可学习模型构造函数逼近器,再用加权余量法等数值求解方法计算损失函数。当然,从物理本质上讲选择合适的网络模型与物理规律的约束实际上是密不可分的,事实上近两年来PINN的重要发展方向正在朝统一两种方式到一个架构[10]中走,例如采用不同形式的网络模型[40]、与算子驱动方法结合[41]、与仿真模拟结合[39]、模型迁移[42]、更加高效的计算方式[43]、更加稳定的训练过程[44]、更加灵活的任务构造[45]。
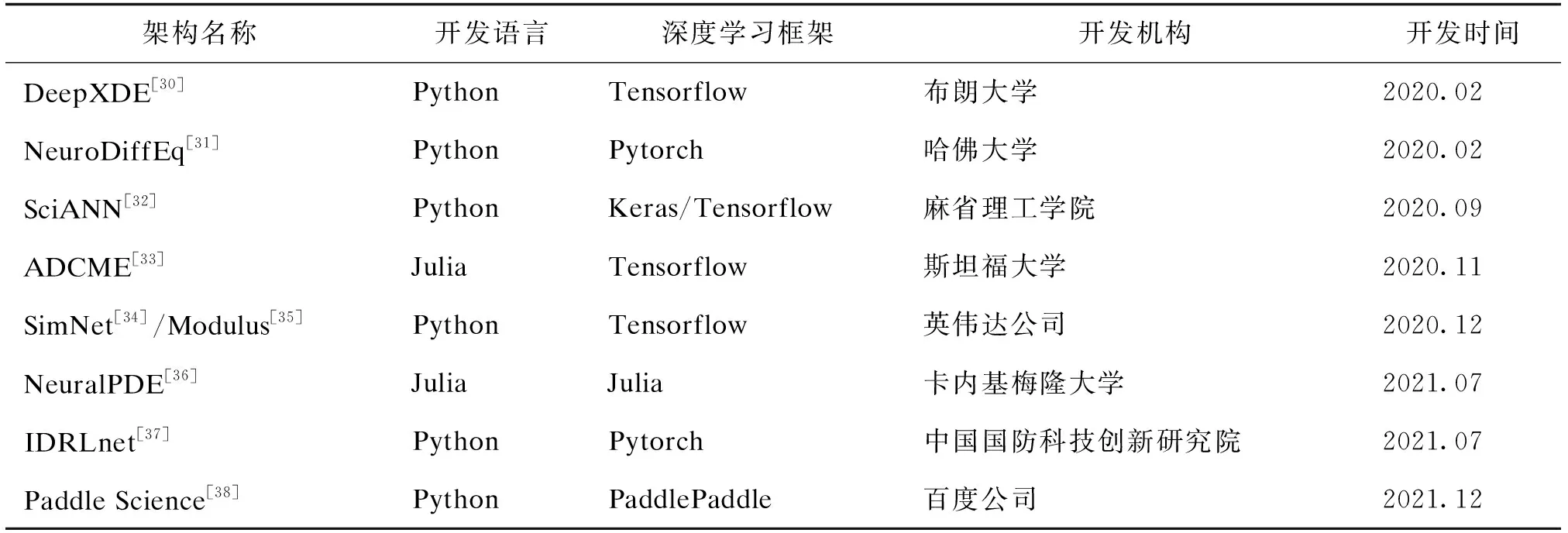
表1 物理信息神经网络相关架构
2.3 任务需求
机理+数据融合建模方法的最大优势是可以将虚拟模型本身与数字孪生系统中的设计、制造、控制、运维等任务需求灵活对接,并充分发掘海量传感器获得的数据,这是机理模型方法所不具备的。考虑公式(1)中更一般的问题,即方程中描述物理系统的部分参数θ需要被识别、控制或优化,在求解方程时是未知的,这导致方程一般是不适定的,在传统机理方法中需要大量的数值仿真对参数进行搜索,甚至结合数据驱动方法对参数进行寻优。而在机理+数据融合模型中,可以将该部分未知参数纳入模型中,即令θ∈Θ显然此时原始方程增加了未知数,因此需要利用具体任务的约束将待求解问题封闭,从而转化为在机器学习方法中的可优化问题。实际工业场景中的任务可大致构造成如下3类方式。
(1)在物理场重构或系统的参数辨识问题中,由于缺失了部分边界条件、初始条件、几何信息、物理性质参数,必须引入必要的可测点使方程封闭,因此需在测点中补充更多的传感器测量,即
(4)
(2)在设计优化任务中,需要对部件的几何信息或工况参数进行优化,因此需要补充待优化目标,使得被设计对象获得更好的设计性能,即
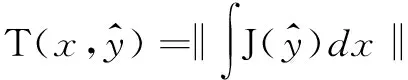
(5)
(3)在控制问题中,需要保证系统的某个输出参数接近需要达到的控制目标,因此需要补充待控制目标,补充待控制目标和实际目标之间的差异,即

(6)

鉴于各种任务的一致性,在机理+数据融合模型中可以将这几种任务统一在一起[46],从而更加凸显机理+数据融合建模方法的灵活性和通用性,事实上实际工业场景中往往也需要同时兼顾上述3种任务。
近两年来,这种机理+数据融合建模方法已经被用于不同的物理场重构任务,如散热结构的设计[47]、基于核磁共振图像及少数测点的血管状态重构[48];系统参数辨识任务,如材料的几何缺陷检测[49]、汽车扭振阻尼结构的参数识别及校正[50];优化任务,如机翼形状优化[18]、电力系统优化[51];控制任务,如流动控制[45]、四容水箱液位控制[52]。另外,这种方法也能胜任一些复杂系统的物理场以及关注的性能参数预测,如热化学反应过程中的温度场预测[42]、气动轴承的气膜厚度以及力学特性预测[53]。
此外,虽然本文是以监督学习形式给出的物理机理嵌入方式,实际上该方法还可以与无监督学习方法以及强化学习方法结合,以进一步扩展该建模方式的应用场景,如进行物理系统的动力学方程的发现[54]、形状设计优化[55]、复杂的湍流控制[56]和电网系统控制[57]。
3 应用场景
机理+数据融合模型由于其灵活性以及通用性,也获得了工业界的广泛关注。世界范围内的大型重工业企业开始陆续布局该模型,将这种方法应用于工业领域的设计优化—生产制造—运行维护环节,从而实现工业互联网中的数据闭环。例如美国通用电气公司和安斯科技(ANSYS)公司、英国罗尔斯·罗伊斯(Rolls-Royce)公司、法国达索(Dassault)公司,德国西门子(Siemens)公司、我国百度公司等相继推出了利用机理+数据融合方法构建数字孪生系统的战略规划,并在实际工业场景中实现了落地应用。
在设计优化方面:美国通用电气公司[58]基于工业互联网技术与安斯科技公司合作打造了基于数值仿真的数字孪生系统,结合结构、热学、电磁、流体以及控制等多物理场耦合分析技术,构建了更加精确快速的综合仿真模型来分析、预测航空发动机的性能,通用电气公司于2018年宣称已经拥有120万个数字孪生系统;英伟达(Nvidia)公司开发了Modulus[34]用于融合物理知识与数据以快速响应设计需求,为芯片散热的流场模拟提供了新的解决方案,使计算流体动力学等模拟的速度比传统工程模拟和设计优化工作流程方法加快1万倍。
在生产制造方面:Fero Labs公司利用机器学习分析传感器数据,预防机器故障并减少资源浪费,每年为钢铁生产企业节省数百万美元的成本;安斯科技公司在材料分析中结合专家经验与机器学习方法,取得了比反复试验效果更好、改进更快、成本更低的结果;西门子利用深度学习使用天气和部件振动数据来不断微调风机,使转子叶片等设备能根据天气调整到最佳位置,从而提高了发电效率、增加了发电量。
在运行维护方面:英国罗尔斯·罗伊斯公司在最新的UltraFan航空发动机[59]的验证机中对每块风扇叶片都安装了传感器,并构造了数据孪生体,辅助叶片运行的健康管理;西门子利用数字孪生的混合建模模型[60]辅助电厂运维,使得燃气轮机的性能增加3.5 Mw,氮氧化物(NOx)排放量下降10%;法国电力集团利用融合建模方法的数字孪生系统进行设备故障诊断以及健康管理,故障检测准确率达到87%;百度公司[61]将机理模型、机器学习与环保水务业务深度融合,帮助水务公司实现节能降耗5%~15%,停机时间减少50%,总成本降低5%~10%,设备利用率提升5%~15%。
2021年8月,美国国防部[62]发布关于开展燃气轮机的大规模集成模拟和综合仿真的研究项目,相关研究人员认为:近期流体力学和人工智能方法的融合出现了巨大突破,有助于提升下一代燃气涡轮发动机的效率和安全性。同时,俄罗斯土星公司也报道了对船用重型燃气轮机的数字孪生项目,并声称目前已完成了第一阶段关于变速箱的融合建模,表示该方法将有助于减少下一代船用燃气轮机的设计时间和成本、缩短试验测试过程,提升产品生命周期的管理质量。由此可见,无论是在民用还是国防工业,机理+数据融合模型已经逐渐融入了新一代工业互联网的数字孪生系统。
4 结束语
综上所述,“第四范式”下的机理+数据融合建模方法是实现数字孪生系统中实时或准实时仿真、模型—数据双向反馈的理想工具,可以在统一的架构下灵活地处理工业领域不同的任务需求,这种方法正在重塑着传统工业领域,引领着新一轮工业互联网技术的发展,也必将在未来扮演关键角色。但仍然需要承认的是:如何将工业中有限容量的数据和物理机理更加高效的结合,无论是将物理知识和经验嵌入机器学习模型,还是改造机理仿真方法以自适应数据,相关探索均缺乏理论支撑,也面临着新的挑战。首先,融合模型的精度、收敛性、可解释性和鲁棒性问题无论是在理论上还是应用中都是亟需解决的问题;其次,构建可验证的标准数据集以及相关开源社区,在传统工业领域仍然是极为困难的;最后,将仿真模拟、实验室中获得的融合模型向真实工业场景推广,确保模型的可迁移性和泛化能力也是一大挑战。
