融合汉字多特征的指挥控制保障领域命名实体识别*
2022-10-23袁清波杜晓明
袁清波,杜晓明,姚 奕,杨 帆,蒋 祥
(陆军工程大学指挥控制工程学院,南京 210007)
0 引言
指挥控制(command and control,C2)简称指控,是指参谋人员利用设备、器材,通过对信息进行收集、传输、处理和利用,从而为指挥员提供作战辅助决策的一门科学。近年来,大量新型指控装备陆续配发到各级部队,给部队的信息保障工作提出了新的要求。当前,围绕对指控系统的保障,部队一方面积累了大量的技术手册数据资料,另一方面由于这些数据资料散落各处、形态各异,造成部队在使用上效率低下、效益不高。因此,如何对这些数据资料进行挖掘处理和高效融合应用,已成为当前部队指控保障领域急需解决的重要问题之一。
知识图谱(knowledge graph,KG)技术在进行关键数据获取、有效信息融合、知识驱动应用等方面则展现出巨大优势,已成为当前及未来知识及大数据应用领域的一个重要研究方向。命名实体识别(named entity recognition,NER)则主要完成从多源异构数据文本中识别出特定类型的实体,是自动化构建知识图谱过程中的一项重要基础性工作。具体到军事领域中的命名实体识别工作,已有很多学者展开了研究。冯蕴天等针对军事文本提出了一种基于CRF 模型的半监督命名实体识别方法;宋瑞亮针对军事领域提出了一种结合CRF 的半监督学习算法模型Tri-Training 来进行军事命名实体识别;朱佳晖等提出了一种基于双向LSTM 和CRF 的实体识别链接框架,以用于军事语料文本中作战相关命名实体的识别和链接;王学锋等针对传统军事命名实体识别方法存在人工构建特征复杂和军事文本分词不准确等问题,提出了一种基于深度学习的军事命名实体识别模型character+Bi-LSTM+CRF;单义栋等针对当前双向LSTM 模型存在提取特征不充分的特点,提出了一种基于注意力机制的命名实体识别模型;张晓海等针对军事命名实体识别任务的特点,提出了一种基于自注意力机制的军事命名实体识别方法;车金立等针对军事领域的命名实体识别问题,提出了一种融合词位字向量的命名实体识别方法;徐树奎等针对军事情报分析领域难以快速准确抽取军事目标活动相关属性和事件要素的问题,提出了一种基于Bi-LSTM-CRF 模型的军事目标实体识别方法;尹学振对基于多神经网络协作的中文军事领域命名实体识别方法进行了相关研究,提出了基于BERT-BiLSTM-CRF 的多神经网络协作军事领域实体识别模型。
1 整体研究框架
本文提出了一种融合汉字多特征的指控保障领域命名实体识别方法,过程框架如图1 所示。在运用有监督深度学习方法进行领域命名实体识别时主要包含以下内容:1)确定实体类别,需在领域本体构建的基础上进行;2)文本数据预处理,主要包括文档格式转换、数据清洗和语句分割等内容,原始数据处理的越好,后期在进行语料标注和模型算法训练时效果越好;3)命名实体识别语料库构建,对经过数据预处理后的文本,按照语料标注规范构建出可用于模型训练的语料库;4)文本数据向量化,在字符嵌入向量的基础上,融合了汉字的拼音特征、五笔编码特征、分词边界特征,以提高模型效果;5)模型训练、评估和调整,将向量化后的命名实体识别语料库划分为训练集、验证集和测试集,用于对模型算法进行训练、评估和调整,以生成最终的命名实体识别预测模型。本文将重点对第4)点和第5)点内容进行研究。
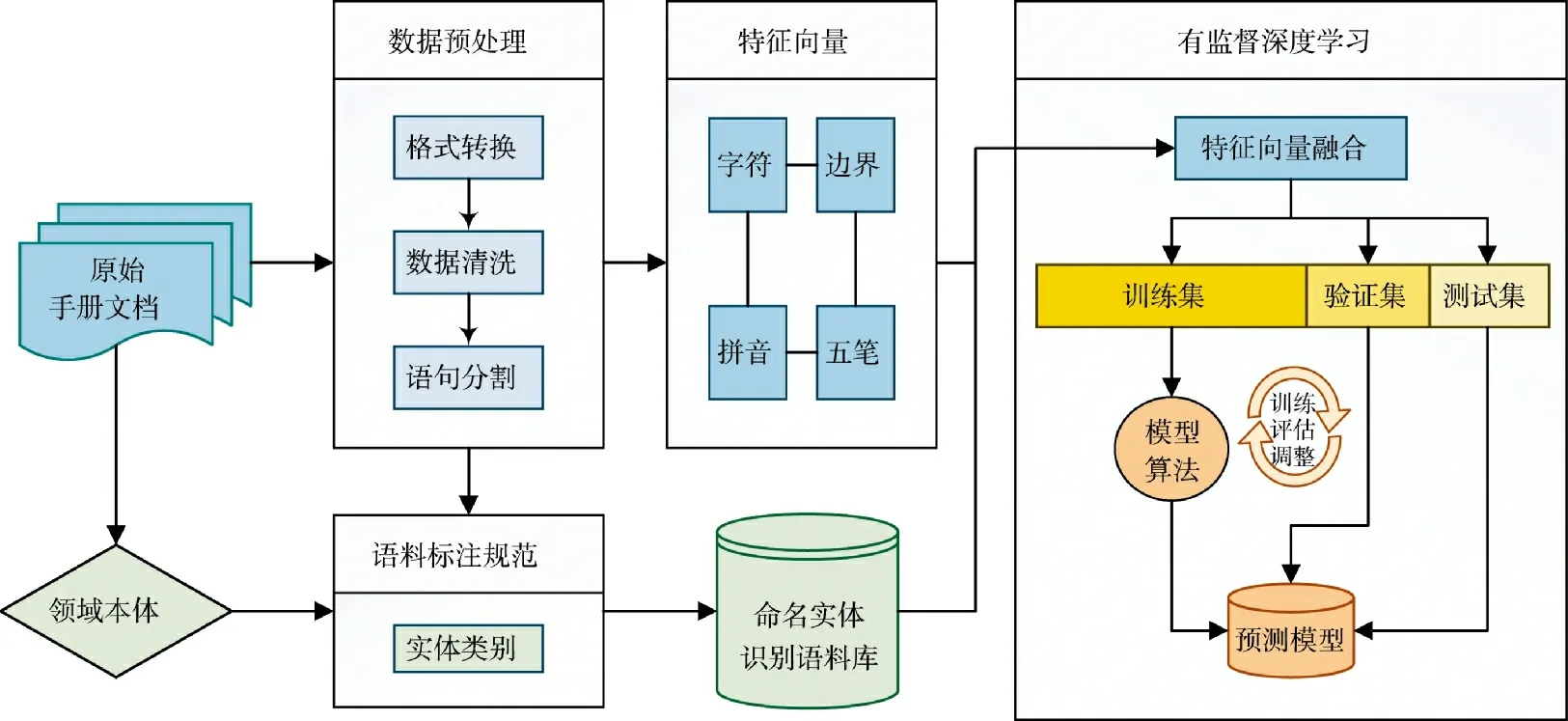
图1 命名实体识别过程框架图
2 融合汉字多特征的命名实体识别模型
采用了融合汉字多特征的BiLSTM-CRF 模型对指控保障领域技术手册文本中的命名实体进行识别。该模型核心主要包含3 个层次:嵌入层、双向LSTM 层和CRF 层。模型结构如图2 所示。
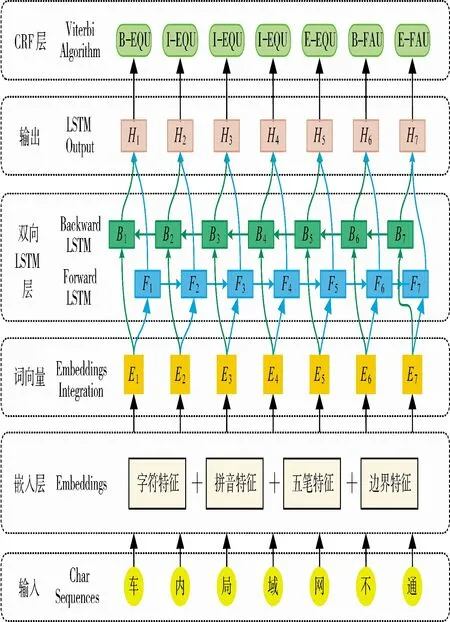
图2 融合汉字多特征的命名实体识别模型结构
2.1 嵌入层
嵌入层结构如图3 所示,主要完成输入分布式表示,完成输入字符序列到特征向量的转化。嵌入层共融合了4 种特征,分别为字符特征(char embeddings)、拼音特征(pinyin embeddings)、五笔编码特征(wubi embeddings)、分词边界特征(seg embeddings)。将以上字符各特征向量拼接后形成总特征向量E,用作后续双向LSTM 层的输入。
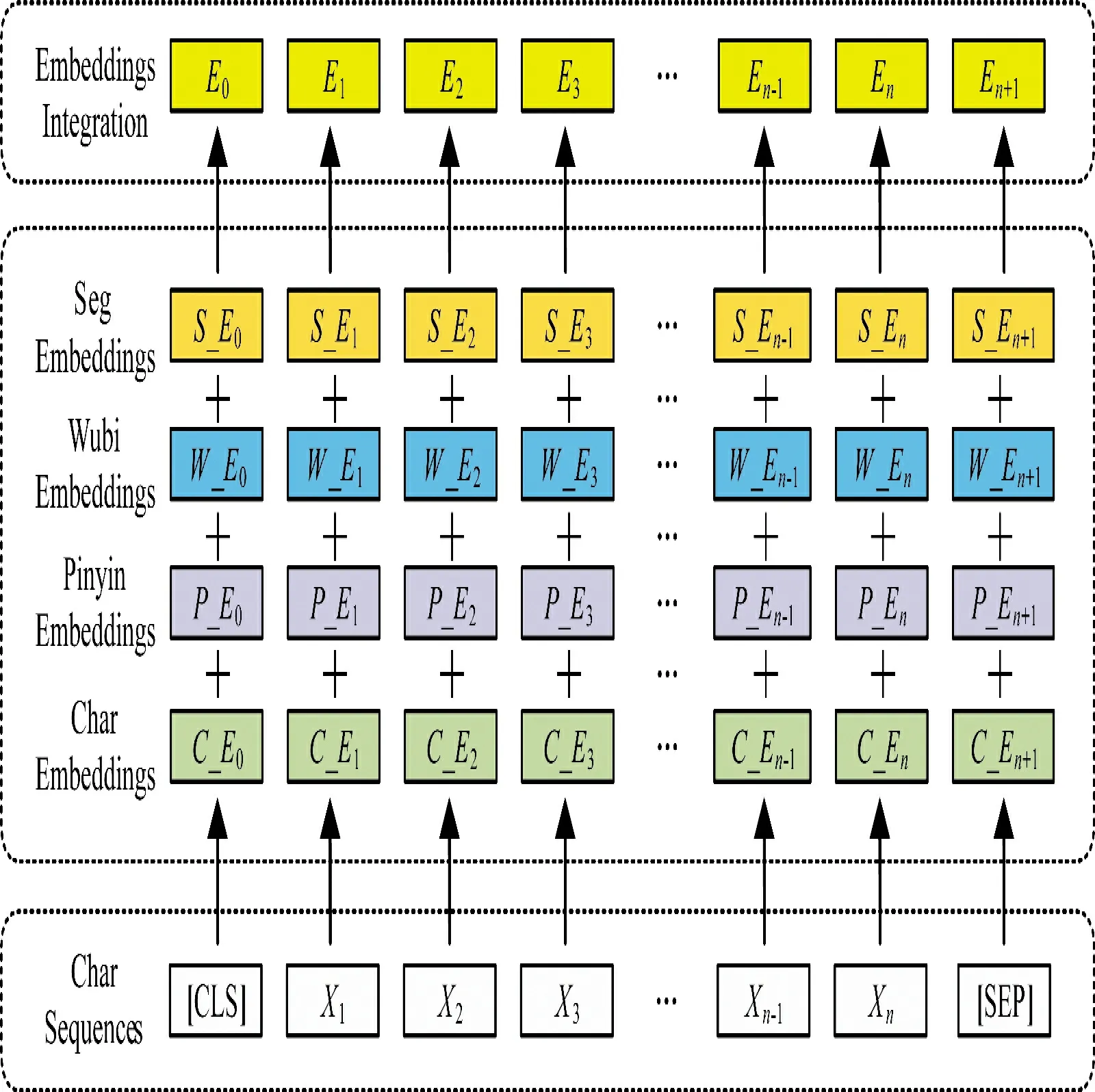
图3 嵌入层结构
为了缩短模型训练时间和提升效果,其中字符特征采用了预训练的100 维word2vec 字向量。拼音特征、五笔编码特征和分词边界特征,采用映射方式将对应特征转化为了数字id,通过查询向量词表,来获取对应字符的初始化嵌入向量,从而送入后续网络模型进行处理。
2.2 双向LSTM 层
LSTM(Long Short Term Memory),即长短时记忆网络,在基础RNN 模型上对隐藏层进行了改进,改善了梯度消失问题,并可以更好地捕捉到深层网络的连接信息。单向LSTM 前向传播过程如图4所示。
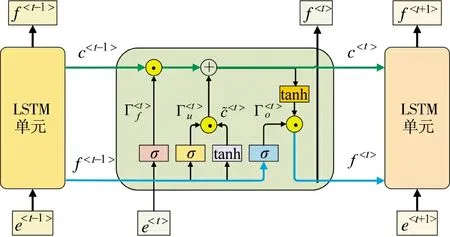
图4 单向LSTM 前向传播过程
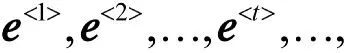

双向LSTM 层可以进一步结合上下文信息形成特征矩阵,能够有效解决军事指挥保障领域中较长实体识别中的远距离依赖问题。双向LSTM 层以嵌入层形成的词向量E 作为输入,在前向LSTM 序列F 和后向LSTM 序列B 的参与下进行上下文特征结合,生成特征矩阵H,H 用作后续CRF 层的输入。
2.3 CRF 层
CRF 层以双向LSTM 层生成的特征矩阵H 作为输入,基于相邻标签间的依赖关系,通过Viterbi算法来获得全局最优的标签序列Y。
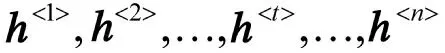
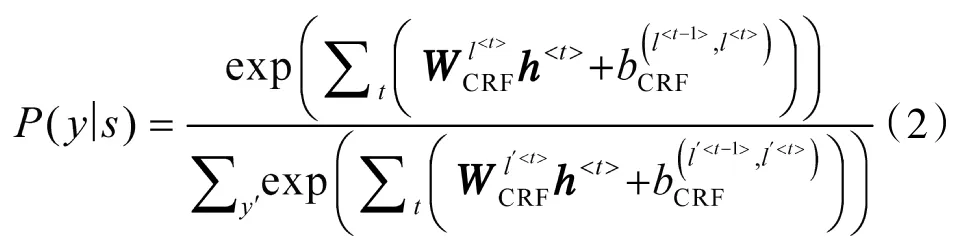
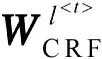
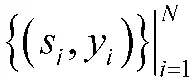
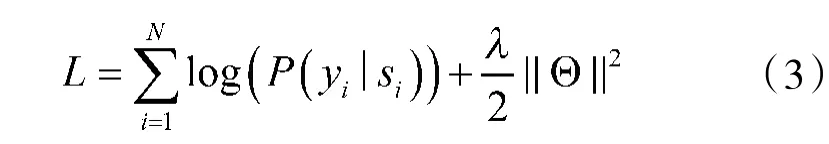
3 实验结果与分析
3.1 实验语料
为了验证模型在指控保障领域的有效性,本文以指控装备保障相关手册文本为基础,构建了指控保障领域命名实体识别语料库C2NER。利用基于实体词典的自动标注及Brat 系统手工标注方式,共标注了5 种命名实体类型。标注文件采用了BIEO 编码格式进行保存,具体如表1 所示,所有类型实体以外的字符均用“O”进行标注。
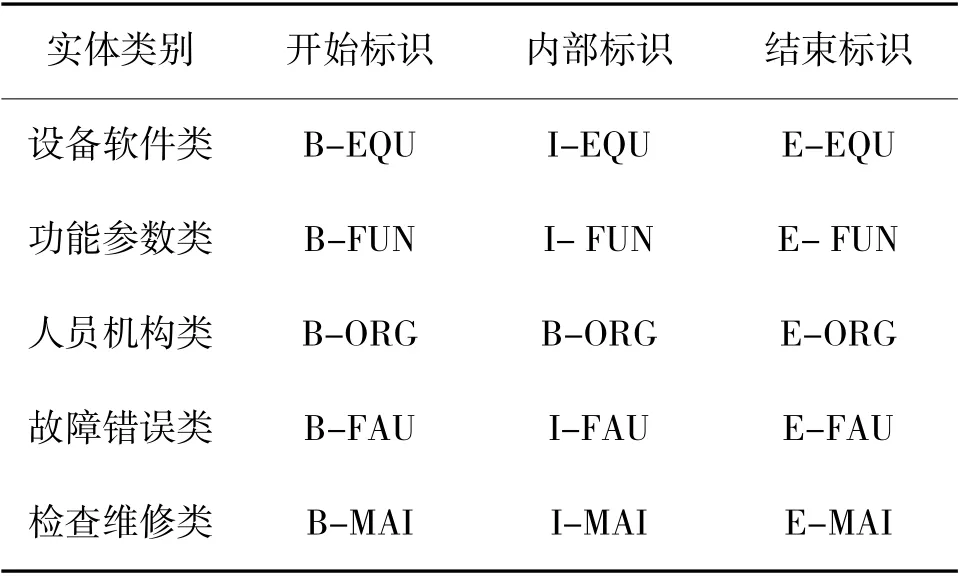
表1 不同类别实体BIEO 编码格式
C2NER 语料库按照8∶1∶1 的比例划分为了训练集、验证集和测试集,其中的各实体类别数量统计如表2 所示。
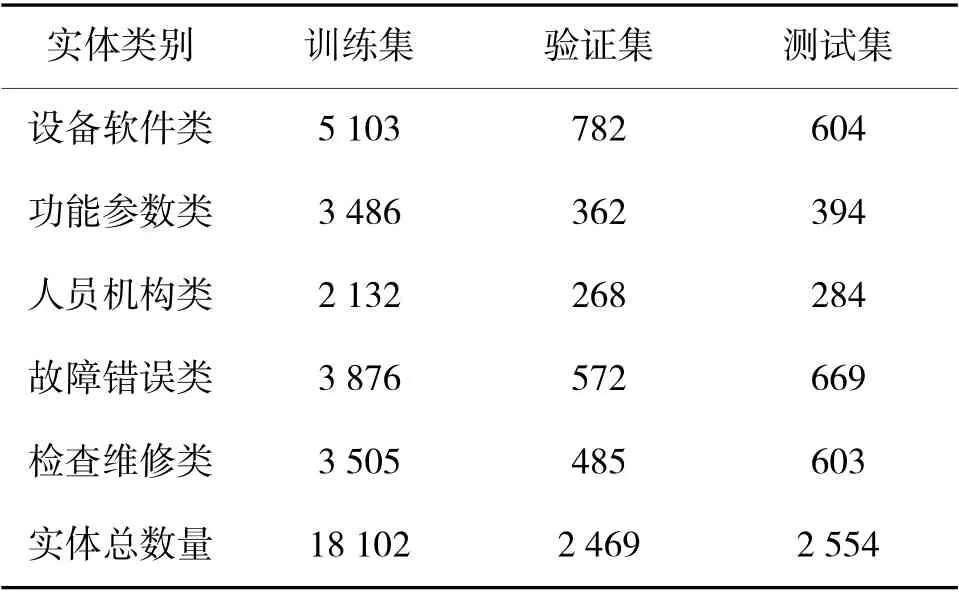
表2 C2NER 语料库中各实体类别数量
3.2 实验模型超参数设置

表3 实验中超参数设置
3.3 实验结果对比分析
为了深入了解汉字中各特征信息对模型所带来的影响,在基线Char+BiLSTM+CRF 模型的基础上分别加入了单个汉字的拼音特征、五笔编码特征、分词边界特征。按照3.2 中的超参数进行设置后,模型在迭代30 次时在训练集和验证集上的实验结果如表4 所示。
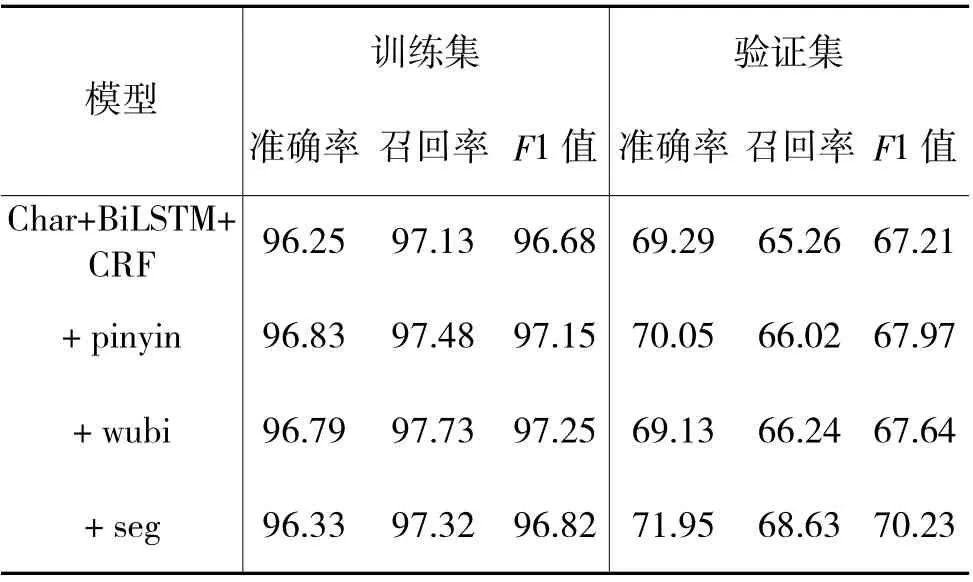
表4 各模型实验结果
图5 和下页图6 分别显示了基于字符以及加入拼音特征、五笔编码特征、分词边界特征后的模型,在训练集和验证集上经过多次迭代后的准确率、召回率和F1 值。从图5 训练集上的结果可以看出,各特征对于提高模型在训练集上的性能都有所帮助,拼音特征将基线模型准确率从96.25%提升到了96.83%,分词边界特征将基线模型召回率从97.13%提升到了97.73%、F1 值从96.68%提升到了97.25%。从图6 验证集上的结果可以看出,分词边界特征对于提升基线模型的性能最为明显,准确率、召回率和F1 值分别从69.29%、65.26%和67.21%提升到了71.95%、68.83%和70.23%。与分词边界特征相比,拼音特征与五笔特征对于验证集性能提升则没有那么明显,这可能是因为在命名实体识别任务中,实体的起始和结束位置对于实体能否正确识别起到重要的作用,而分词边界特征从一定程度上带有位置信息,因此,会提高模型的性能。
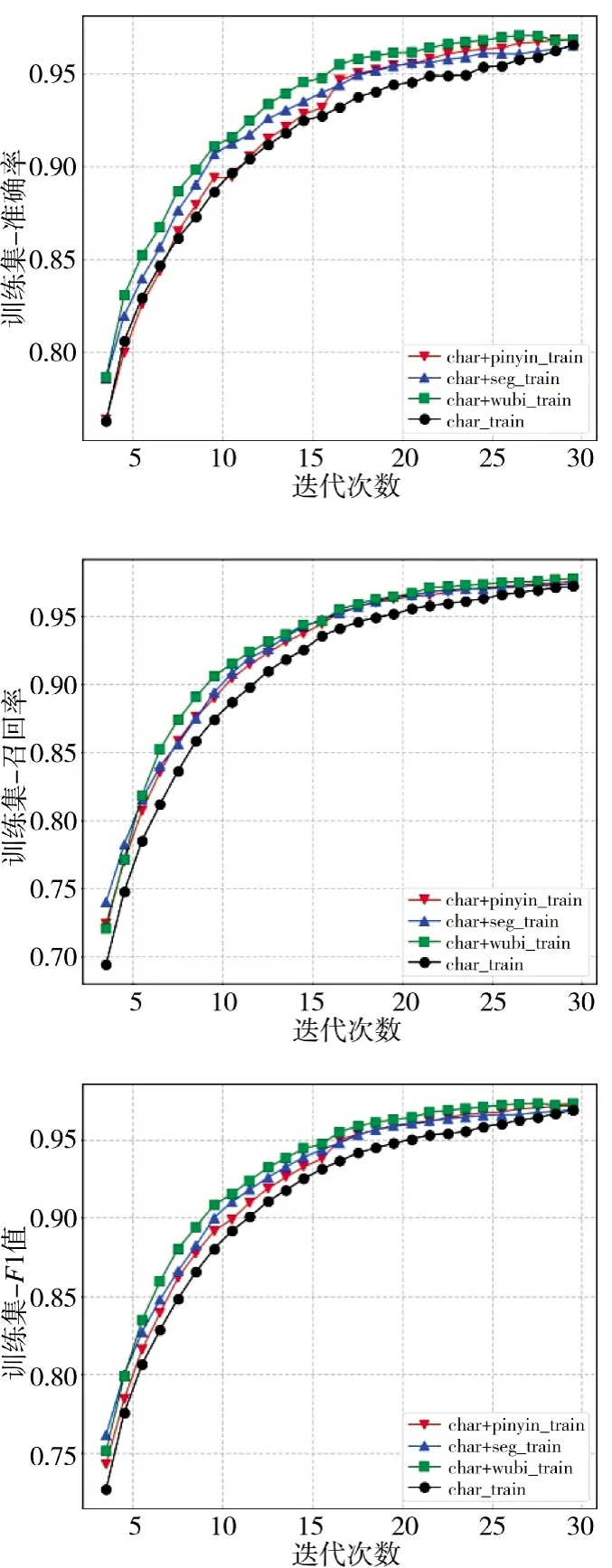
图5 各模型在训练集上的性能表现
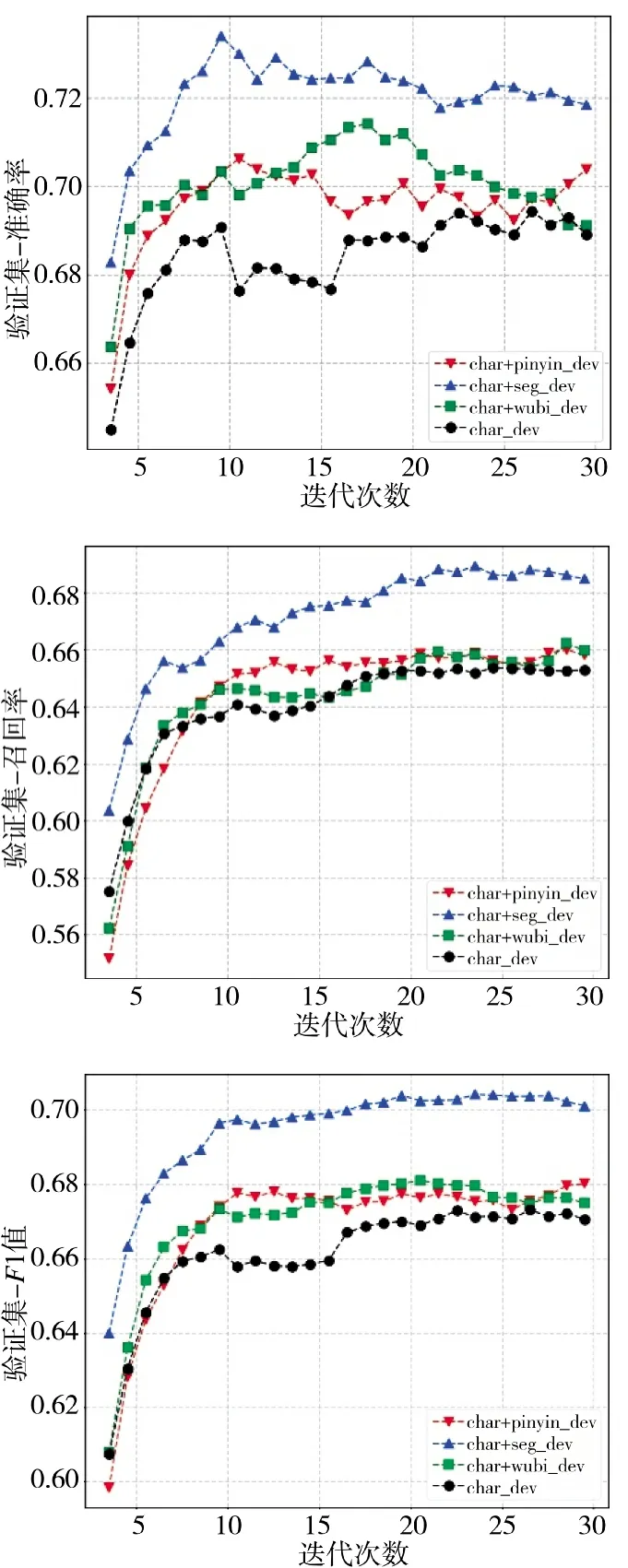
图6 各模型在验证集上的性能表现
在基线Char+BiLSTM+CRF 模型的基础上加入分词边界特征后,形成的char+seg 模型在测试集上的实验结果如表5 所示。对所有实体的识别结果中,对功能参数类实体的识别率最高,F1 值达到了81.62%,最有可能的原因是功能参数类实体较为固定,且大多与数字相关。而对检查维修类的实体识别率较低,F1 值仅为54.73%,最有可能的原因是在日常工作中检查维修的方法和程序较为灵活,涉及到的实体数量较多,而训练语料库内的此类实体数量较为有限,因此,很多实体不能很好地被识别出来。
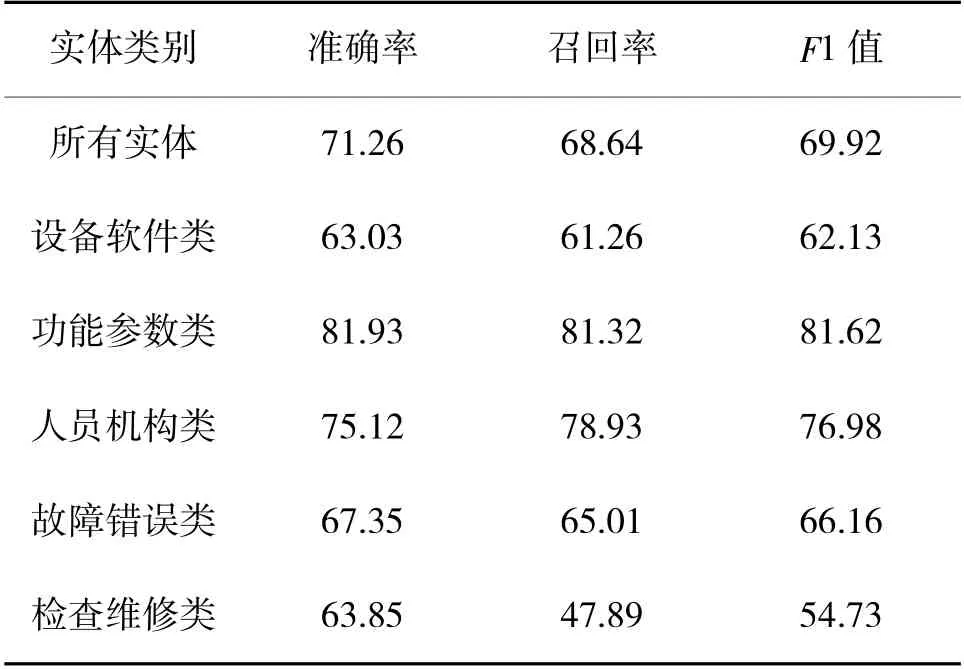
表5 char+seg 模型在测试集上的实验结果
4 结论
本文重点对军事指控保障领域相关文本的命名实体识别方法进行研究,提出了一种融合汉字多特征的BiLSTM+CRF 模型方法。该模型方法主要对嵌入层结构进行了改进,在基线模型的基础上加入了拼音特征、五笔编码特征和分词边界特征,以此来提高模型的性能。通过在自行构建的军事指控保障领域命名实体识别语料库C2NER 上进行实验,实验结果表明分词边界特征对于模型性能的提升效果较为明显,而拼音特征和五笔编码特征则对模型性能影响较小。在后续研究过程中,将对汉字的偏旁部首特征、笔画特征和字形结构特征进行实验,以检验这些特征对于模型命名实体识别效果的影响。
