基于集成学习的专利质量分析与分类预测研究*
2022-10-19付振康柳炳祥周子钰彭启宁
付振康 柳炳祥 周子钰 彭启宁
(1.景德镇陶瓷大学知识产权信息中心 景德镇 333403;2.景德镇陶瓷大学管理与经济学院 景德镇 333403;3.景德镇陶瓷大学信息工程学院 景德镇 333403)
科技创新在国际竞争格局中占据着重要地位,专利作为科技创新成果的主要载体,蕴含了全球90%~95%的科技信息[1],同时专利文献也包含着丰富的法律信息以及经济信息。我国自2008年发布《国家知识产权战略纲要》以来,专利申请量激增。随着我国专利数量的增加,非正常申请的“问题专利”“垃圾专利”也不断涌现,专利质量需进一步提高。根据专利竞赛理论,专利质量要胜于专利数量,高质量专利可以为企业带来较高的经济价值和法律价值,低质量专利往往会降低企业自身的核心竞争力[2]。故我国向专利强国迈进的必由之路是提升专利质量,而专利质量的提升首先要对海量专利进行质量分类进而明晰高质量专利的特征。基于此,本文结合前人研究,构建了专利质量评价指标体系,并采用基于Stacking框架的集成学习算法搭建了专利质量分析与分类预测模型,并以人脸识别技术作为实证分析案例进行专利质量的分析与分类预测。
1 相关研究综述
1.1 专利质量评价指标体系相关研究 对于专利质量的内涵,目前学界并未给出统一的定义,大部分学者基于专利的创造性、实用性和新颖性的角度抑或是技术质量、申请质量和经济质量等维度对专利质量进行阐述。本文所指的专利质量是融合了技术质量、申请质量、法律保护质量以及经济质量的综合专利质量[3]。21世纪初,美国的知识产权咨询公司CHI提出了一套科学的专利质量评价指标体系,包括专利数量、专利引证次数、影响指数、技术实力、技术生命周期、科学关联度和科学强度这7个指标[4],该评价指标体系后来在全球范围内得到了广泛应用。随后,国内外的许多学者展开了关于专利质量评价指标体系的研究。
李春燕在CHI指标体系的基础上增加了内容指标、时间指标以及国际指标,构建了多维度的专利质量评价指标体系[5]。于晶晶等根据我国专利文献的特点构建了包括数量类指标、质量类指标以及综合类指标的专利组合评价指标体系[6]。冯君等就单件专利质量提出了基于专利技术质量、专利保护质量、产业高度以及社会经济效益4个一级指标的单项专利质量评价指标体系[7]。刘驰等构建了专利宽度、专利长度以及专利高度的专利质量要素三维模型[8]。
综上,目前大多数学者倾向采用多维度指标对专利质量进行评价,尤其是根据专利的技术质量、法律保护质量和经济质量对专利综合质量进行测度。但许多学者认为,专利申请人的技术研发能力以及技术实力会对专利质量产生较大影响[9-10],故应将专利申请人等主体性因素融入专利评价指标体系。
1.2 专利质量评价模型相关研究
在专利质量评价模型方面,目前的研究主要集中在两方面。一是采用传统的专家赋权法或客观赋权法对专利质量进行评价。张黎等在建立专利质量评价指标体系后,采用直觉模糊层次分析法确定了各个指标的权重,然后采用模糊评价法对专利质量进行了综合评价[11]。杨登才等基于熵权理论,构建了高校专利质量评价模型,并选取了北京市23所高校进行了实证分析[12]。郜梦蕊等采用AHP法改进熵权法确定专利评价指标的权重,然后对深度学习相关专利进行了专利质量评价[13]。
二是采用神经网络、机器学习等方法对大规模专利数据集进行专利质量分类。李欣采用随机森林、人工神经网络、支持向量机以及自适应增强4种机器学习算法构建了多种分类器模型对专利质量进行分类,通过对比分析发现基于支持向量机的专利质量评价模型优于其他模型[14]。Wu J L等通过自组织映射神经网络(SOM)算法对专利评价指标进行聚类,然后采用KPCA方法对专利评价指标进行降维,最后采用SVM方法对专利质量进行分类,并且对比了基于不同核函数的SVM模型的准确度[15]。
综上,传统的专利质量评价模型需要结合专家调查问卷,其具有过程复杂、结果可信度不高以及不适用于大规模专利数据集等缺陷。在采用机器学习等方法进行专利质量分类的研究中,大部分学者都采用单一的机器学习算法进行专利质量的分类,而单一的机器学习算法在不同数据集上的准确性及泛化能力有待提高。
2 研究思路及方法
2.1 研究思路
本文的研究框架如图1所示。首先,通过数据库采集相关的专利数据,然后选取专利质量评价指标并对相关指标进行计算和预处理;之后将数据集划分为训练集和测试集;然后,建立两层集成学习模型,第一层基分类器选用预测精度高且具有一定差异的机器学习分类算法,第二层采用逻辑回归分类器对基分类器进行集成,获得最终的专利质量分类预测模型;最后,采用机器学习中常用的模型评价算法对模型进行评价,通过训练效果不断改进训练模型,提高模型的性能。

图1 研究框架图
2.2 研究方法
2.2.1基于Stacking思想的集成学习方法
集成学习是一种将多种不同的算法或者不同参数的同一种算法融合到一个模型的方法,目前常用的集成学习方法主要有Boosting、Bagging以及Stacking[16]。由于Stacking的集成学习是通过自组织抽样或者交叉验证的方式融合来自多个模型的预测信息进而生成新模型的一种方法,相较于单一算法性能更为优越,故本文采用Stacking方法构建集成学习模型。Stacking集成学习一般是由基分类器和元分类器组成,该方法的构建流程如图2所示。
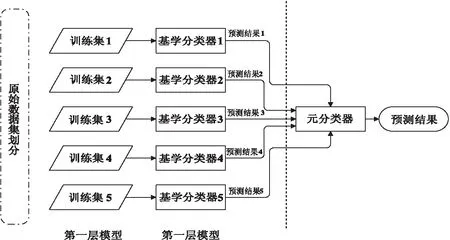
图2 Stacking方法过程图
Stacking集成学习的具体训练方式为,将数据集D={(xp,yn),p=1,2,…,P,n=1,2,…,N},随机划分为K个大小基本相同的数据子集{D1,D2,…,Dk}以及D-k=D-Dk,其中Dk,D-k分别代表第k折训练的测试集和训练集。每个基分类器采用训练集D-k进行k折交叉训练得到最优基分类器模型Ck,k=1,2,……,K。在k折交叉训练过程中Ck对于Dk包含的特征xp的预测结果可以表示为Zkn,基分类器的输出集合构成了新的指标特征数据集Dnew={(yn,(Z1n,Z2n,…Zkn)),k=1,2,……,K,n=1,2,…,N}。Dnew则为集成学习模型中第二层分类器的输入数据,第二层模型采用新数据集训练元分类器CMeta。
在基分类器构建过程中,需要选择精度高且具有差异性的机器学习分类器,故本文从分类效果较好的KNN算法、逻辑回归分类算法、感知机分类算法、随机森林算法(RF)、支持向量机算法(SVM)、AdaBoost算法、LightGBM算法(LGBM)以及XGBoost算法8种机器学习算法当中选择具有差异性的算法进行基分类器集成,元分类器选择Stacking集成模型常用的逻辑回归算法。
2.2.2模型评估方法
本文采用集成学习模型最终完成的任务是专利质量的三分类,故本文采用准确率(Accuracy)、宏平均精确率(Macro_P)、宏平均召回率(Macro_R)、宏平均F1值(Macro_F1)以及汉明损失(Hamming_L)5个指标对模型的性能进行评价。
准确率是模型分类正确的专利样本数量与所有的专利样本数量的比值,其计算公式如式(1)所示:
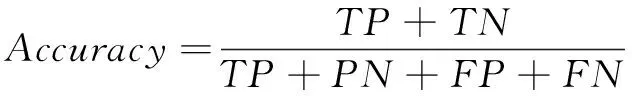
(1)
宏平均精确率表示所有类别当中精确率的均值,精确率表示被正确分为某一特定类别的专利数与实际被分为该类别的专利数的比例,其计算公式如式(2)所示:

(2)
宏平均召回率代表所有类别召回率的均值,召回率表示对于某一特定专利质量类别,被模型正确分类的专利样本数量与该类别下所有专利样本数量的比值,其计算公式如式(3)所示:
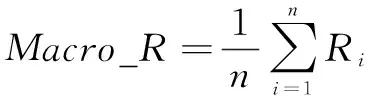
(3)
在实际应用当中,对于分类模型性能的评估,往往需要综合考虑模型的精确率与召回率,因此采用两者的加权调和平均作为评价指标,该指标即为F1值,而宏F1值代表的是所有类别F1值的均值,其计算公式如式(4)所示:

(4)
汉明损失是通过计算预测样本与真实样本之间的汉明距离来评价模型性能的,Hamming_L越小,则模型预测的准确率越高。Hamming_L的计算公式如式(5)所示:

(5)

2.3 专利质量评价指标体系构建及专利质量划分
2.3.1专利质量评价指标体系构建
本文基于综合专利质量的角度,构建适用于集成学习模型的专利质量评价指标体系,指标体系的设计遵循以下原则:a.指标体系要涵盖技术、法律、市场以及主体4个维度。技术维度主要从目标专利的技术自身出发衡量专利质量,法律保护维度是从专利的申请以及维护的角度衡量专利的法律保护质量,市场维度主要从专利的布局市场以及剩余有效期来衡量专利的经济质量,主体性维度是从创新主体的角度衡量专利的综合质量;b.指标的选取应该具有可操作性,避免主观因素的影响;c.由于本文采用集成学习模型进行评价,故各指标要能够量化。综上,本文选取技术、法律、市场以及主体4个维度构建了包含19个指标的专利质量评价指标体系,各个指标的含义及计算方法如表1所示。

表1 专利质量评价指标体系
2.3.2专利质量划分
专利的质押和转让是专利商业化的重要形式,在专利质押融资过程中,质权人对于目标专利的市场前景会进行评估,只有专利权稳定、质量较高且具有良好市场前景的专利才会发生质押,故发生过质押融资的专利一般可以认定其为高质量专利[22];而专利的转让和许可是专利权人获得经济收益的重要形式,专利转让和许可可以一定程度上反映专利的经济质量,故发生过转让和许可的专利一般可以认定为重要专利[23]。故本文将发生过质押融资的专利划分为高质量专利,发生过转让和许可的专利划分为重要专利,未发生过质押融资和转让、许可的专利划分为一般专利。
3 实证分析
3.1 数据来源与数据处理
本文使用的专利数据库为incoPat数据库,检索时间截至2021年9月,检索范围为在中国公开并且获得授权的发明专利以及实用新型专利,检索表达式为TIAB=(人脸识别 OR 面部识别) AND ((PNC=CN) AND (AP-COUNTRY=CN)) AND (AD=[20020101 TO 20210918])。在得到检索结果后,通过对IPC分类号的筛选结合人工标引进行数据清洗,去除与人脸识别核心技术不相关的专利数据,共得到17 667条专利文献数据。得到专利文献数据集后,提取表1所述的指标数据,部分数据可由著录项直接获得,无法直接获取的指标数据,本文根据表1所述的指标计算公式进行编程计算。根据相应算法得到指标数据之后,对数据进行描述性统计,结果如表2所示。为保证模型的准确性,消除量纲对模型的影响,本文采用标准化算法对原始的专利指标数据进行标准化,公式如式(6)所示,其中xi表示第n项专利的第i个评价指标,xstd表示进行标准化以后的专利评价指标数据。

(6)

表2 专利评价指标数据描述性统计
由于本文构建的集成学习模型所要完成的任务为专利质量的分类预测,因此需要将专利质量划分为不同的类别。依据上文提到的划分标准进行专利质量划分,具体分类情况如表3所示。由表3可知,3种专利类别的数量不均衡,高质量专利数量与一般专利数量的比值仅为1.85%,与重要专利数量的比值为7.64%,数据类别不平衡,进而会影响模型的预测精度。故本文采用SMOTETomek算法对数据集进行采样,该算法的采样方式是将过采样和欠采样进行结合[24],进而解决数据不平衡的问题。

表3 专利质量分类情况
3.2 特征贡献度分析
通过对不同特征的重要度进行分析,可以发现不同特征对于模型的影响程度,从而在构建模型过程中可以更好的解释模型和调整模型。本文选择特征重要度以及shap值来分析不同特征对于模型的影响。选用XGBoost模型为基准模型进行特征贡献度分析,结果如图3所示。

(a)特征重要性图

(b)Class0类shap摘要图
图3(a)显示了不同专利类别的特征重要度,图3(b)显示了class0类(高质量专利)的shap值分布,由图可知在class0类中,技术先进性、技术稳定性以及保护范围对于高质量专利的影响较为显著,且这3个特征的shap值均对模型有正向推动作用,即这3个指标其值越高,成为高质量专利的概率越大;在class1类(重要专利)中,技术先进性、技术影响力、技术稳定性以及保护范围这3个特征对重要专利的影响较为显著,且均为正向影响,即这4个指标值的增加,目标专利成为重要专利的概率越大。上述结果与2.3节的分析也是相契合的。此外,由图3(a)可知,技术先进性、技术影响力、技术稳定性以及保护范围这4个特征对模型影响较大。
3.3 基于集成学习的专利质量分类预测模型构建
Stacking集成学习模型最终的性能主要取决于基分类器的准确度以及基分类器之间的相似度,性能优越的集成学习分类器应该是遵循“好而不同”的原则[25]。为此,本文首先在Jupyter Notebook平台使用Python中的scikit-learn机器学习库进行实验,分别建立KNN分类器、逻辑回归分类器、感知机分类器、RF分类器、AdaBoost分类器、LightGBM分类器、XGBoost分类器以及GBDT分类器8种机器学习分类模型,在训练集上进行单独训练,采用交叉验证结合随机搜索以及学习曲线的方式寻找最优超参数组合,各个分类器的超参数组合及预测精度如表4所示。由表4可知,逻辑回归分类器以及感知机分类器在9种分类器当中性能较弱,为保证基分类器“好”的特性,在后续集成过程中可抛弃这2种分类器。

表4 各分类器的超参数组合及预测精度
为选择最佳的基分类器组合,本文对不同算法的预测结果进行了相关性分析,通过计算不同基分类器的预测误差分布,采用相关系数计算基分类器之间的差异性[26],得到如图4所示的相关性热度图。图中颜色越深代表模型的相关性越高,颜色越浅代表模型的相关性越低。

图4 不同模型相关性分析
由图4可知,除感知机分类器(PPN)以及逻辑回归分类器(Logistic)外,其余分类器之间的相关性均较大,原因是不同的基分类器预测的精度均较高,在训练过程中,固有误差不可避免。其中LGBM模型、XGBoost模型、GBDT模型以及RF模型之间的相关系数达0.8以上,原因是这3类模型虽然原理不同,但其本质都是基于树模型的集成算法,因此数据的观测与处理方式基本相同。
为保证基分类器的差异性,本文在进行集成模型构建的过程中。选取相关性系数<0.7的分类器作为基分类器,构建两层集成学习模型,本文共构建了8种集成学习模型,每个模型的内部具体结构如表5所示。

表5 不同集成学习模型的构成
3.4 模型评估
采用2.2节所述的评估指标,将构建的8种集成学习模型在测试集上的表现与传统的机器学习模型KNN、SVM、决策树(DCT)和朴素贝叶斯模型(GNB)以及传统的集成学习模型随机森林(RF)、AdaBoost、GBDT、LGBM和XGBoost单独在测试集上的表现进行对比,结果如表6所示。
由表6可知在测试集中,StackingModel3的Accuracy、Macro_P、Macro_R以及Macro_F1的评分均为0.9942,其Hamming_L也是最低的,为0.0058。综合整体实验分析可知,本文构建的StackingModel3模型的整体性能优于传统单个机器学习分类模型以及其他集成学习模型,故本文选择StackingModel3为最优专利质量分类预测模型,该模型的内部构成见表5。

表6 专利质量分类预测模型在测试集上的性能评估
4 结 论
本文首先根据专利质量评价指标体系的相关研究,提出了基于技术维度、法律维度、市场维度以及主体性维度的4维度19个指标的专利质量评价指标体系;其次,采用Stacking思想,建立双层集成学习模型对专利质量进行分类预测;最后,选取在我国授权的人脸识别技术相关专利数据进行了实证分析,对本文构建的评价指标体系以及评价模型的有效性及准确性进行验证。
通过实证分析得出如下结论:一是通过对专利质量的划分以及前人相关研究可以发现,进行专利质量分类的专利指标数据集往往是类别不平衡数据集,高质量专利占比较少,在进行分类预测时,需要对数据进行采样处理;二是通过特征贡献度分析可知,在不同类别的专利当中,各个评价指标对模型的贡献度是不一致的,故在不同的应用场景下,应该考虑对不同的评价指标赋予不同的权重,例如在高质量专利筛选过程中,要着重考查专利的技术先进性、技术稳定性以及保护范围这3个指标,在重要专利筛选过程中,除了要考查专利的技术先进性、技术稳定性以及技术保护范围以外,还要着重对专利的技术影响力进行评判;三是在专利质量分类预测模型方面,本文构建的集成学习模型相较于传统的机器学习模型的预测精度更高,模型的泛化能力更强,尤其是本文构建的StackingModel3模型,与传统的机器学习模型KNN、SVM、DCT以及GNB模型相比,宏平均F1值分别提高了1.8%、4.67%、1.01%以及17.4%,与传统的集成学习模型RF、AdaBoost、LGBM、XGBoost以及GBDT相比,宏平均F1值分别提高了0.26%、1.06%、0.27%、0.23%、0.27%以及0.29%,这说明本文构建的专利质量分类预测集成模型效果较好。
综上所述,本文构建的专利质量评价指标体系以及专利质量分类预测模型具有一定的科学性以及现实意义,可为政府以及相关创新主体把握产业未来发展方向提供一定的决策支持,为高质量专利的筛选及培育提供技术支撑。当然,本文构建的评价指标以及模型也具有一定的局限性:一是本文构建的评价指标体系,并未充分的考虑新申请专利质量的评判;二是本文构建的集成学习模型的时间复杂度较高,还需进一步降低模型的时间复杂度。因此,未来研究过程中,本文将对上述不足进行进一步研究,力求推进本文构建的评价指标体系以及分类预测模型应用到实际工作当中。
