移动应用众包测试人员信誉度复合计算模型研究
2022-09-22谭顶梅
谭顶梅,成 静
(西安工业大学计算机科学与工程学院,陕西西安 710021)
0 引言
随着互联网平台的快速发展,众包技术被广泛应用于解决各种工程任务,尤其是软件测试[1]。众包一词是由Howe[2]于2006 年提出,其是一种分布式问题解决模式,即公司或组织通过一个开放网络平台,以自由和自愿的方式将以往由全职员工完成的工作任务外包给一群不特定的解决方案提供者[3]。众包测试是依托新一代互联网技术衍生出来的新兴测试方法,其利用互联网的即时性和共享性,采用分布、协作的方式组织生产,协同测试需求和测试资源,最终聚合形成规模效益[4]。
随着新兴移动应用数量的激增,移动应用测试中也引入了众包测试形式。移动应用众包测试任务的完成需要发包方、众包平台与众包测试人员三者之间良好协作,典型的移动应用众包测试模型如图1 所示。与传统测试相比,众包测试可以轻松、廉价地获得大量候选测试人员,他们可以在不同环境、平台以及知识背景下进行测试,能快速且低成本地发现软件缺陷[5],提高了测试效率,解决了企业人手与资金不足的问题。
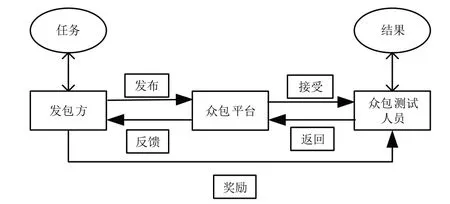
Fig.1 Typical mobile application crowdsourcing testing model图1 典型移动应用众包测试模型
虽然移动应用众包测试有很多候选测试人员,但由于成本限制,不可能让所有候选人员都执行测试任务。同时在众包测试背景下,软件测试成功与否很大程度取决于众包测试人员的反馈。然而,由于众包测试的匿名性与非契约性,众包测试人员会产生懈怠、欺诈等行为,使测试结果质量得不到保证[6],因此如何选取众包测试人员十分重要。为使发包方更加方便地选择众包测试人员,本文以数据化的方式对众包测试人员信誉度进行研究与展现。
1 相关研究
国内外学者对众包测试人员的信誉度进行了积极研究并取得了一定成果。例如,芮兰兰等[7]采用重复博弈方法计算测试人员信誉值并构建了激励机制,同时设置了惩罚机制针对恶意工作者作出相应惩罚,有效激励了理性工作者尽力工作;阮闪闪等[8]提出基于证据理论的信任评估模型实现众包平台的质量监控,通过计算众包测试人员的直接信誉值和间接信誉值综合评定其信誉值,模型中同时引入奖惩机制,用以激励接包方参与众包并提供高质量众包,同时遏制恶意的接包方;严俊等[9]通过控制众包交互过程中测试人员的积极性和任务完成质量构建众包测试人员信誉模型,实现了众包平台的质量控制;肖江辉[10]提出一种基于可信度的众包协同测试算法,即通过统计测试人员在测试过程中发现的bug数目和等级计算其客观可信度,然后通过评估bug的可信程度给出主观可信度,最后通过集成二者获得测试人员的全局可信度;Lee 等[11]提出基于质量评估和用户等级任务分配框架的众包质量提升策略。然而,目前已有的信誉度计算方法均未考虑到众包测试人员受到的主客观因素影响。本文在前人研究的基础上充分考虑影响众包测试人员信誉度的主客观因素,提出移动应用众包测试人员信誉度复合计算模型,通过众包测试人员主观评分计算主观信誉度,采用层次分析法计算其客观信誉度,最后评估出众包测试人员的综合信誉度。
2 基于主客观因素的众包测试人员信誉度计算
2.1 主观信誉度计算
采用评分算法选取用户可靠评分并更新目前众包测试人员的个人评分,在个人评分不断更新的基础上计算其主观信誉度。目前,评分算法已被广泛应用于各类场合,具有一定的有效性,可以很好地反映被评价方的任务完成度、信誉度以及满意度,对其有一定的督促作用[12]。常用用户评分机制包括2 分制、5 分制和10 分制。本文采用10分制对众包测试人员信誉度进行评分,评分越高表示发包方对众包测试人员越满意。
发包方的评分范围包括众包平台上给出的众包测试人员各方面属性,维度越多,众包测试人员的个人信誉度越准确[13-14]。为方便计算,本文选取3 个维度,分别为测试人员可靠性、测试结果质量和测试结果数量。发包方对众包测试人员的评价用V表示,V1、V2和V3分别表示发包方对众包测试人员的可靠性、测试结果质量和测试结果数量评分。由于无法保证新发包方给众包测试人员的评分全部真实可靠,本文通过研究评分的可靠置信区间计算偏离值,去除恶意评分,更新众包测试人员的历史评分,使评分更加真实有效。
2.1.1 评分可靠置信区间计算
为保证新发包方给出的评分具有可信度,本文根据新评分与众包测试人员历史评分之间的关系提出评分置信区间的概念,计算出新评分与样本总体评分之间的偏差,偏差在可靠置信区间内即为有效评分[15-16]。当新发包方的评分明显低于或高于该众包测试人员历史评分时,这个新评分便有可能是虚假评分,在更新用户评分时不予采纳。若新发包方的评分在给出的可靠置信区间内,说明该评分可信,则将新评分纳入众包测试人员历史评分中进行评分更新。具体计算方法如下:
首先,计算第j个众包测试人员的第k个属性评分均值,公式为:

然后,计算新发包方对众包测试人员评分向量相对于该人员历史评分向量平均值的偏离大小,即新评分的可信度L,采用距离向量表示,距离越小,说明新发包方的评价与该人员的历史评价越相似,评分信息也越可靠,反之则不可信。具体计算公式为:
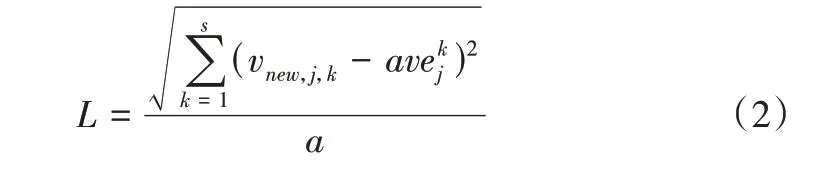
2.1.2 众包测试人员主观信誉度计算
对众包测试人员信誉度的计算实际上是对其评分的不断更新。在测试任务结束后,发包方对众包测试人员进行评分,通过计算该评分与该用户总体评分均值之间的偏离度来判断新评分是否可用,偏离度越小说明新评分越可信,则将新评分代入该用户历史评分,计算出该人员新的综合评分V,即为其主观信誉度值。以下给出计算过程部分数据作为实例进行分析。
表1 给出了20 个发包方对众包测试人员T1 的评价,具体计算方法为:
首先根据式(1)计算T1各维度评分的均值,分别为:

可以得出T1 的评分均值为(8.1,7.9,7.1)。由表1 可以看出,U6 对T1 的评分明显偏离,即以该评分为例,根据式(2)计算出偏离大小,即为:

L=0.790>0.3,即该评分不可信,不予采纳。若新用户对T1 的评分为(9,9,7),根据式(2)可得L=0.142<0.3,说明新评分可信,则采纳新评分并代入计算T1 的新评分,得到:=7.09,T1 的新主观信誉度V=7.76。
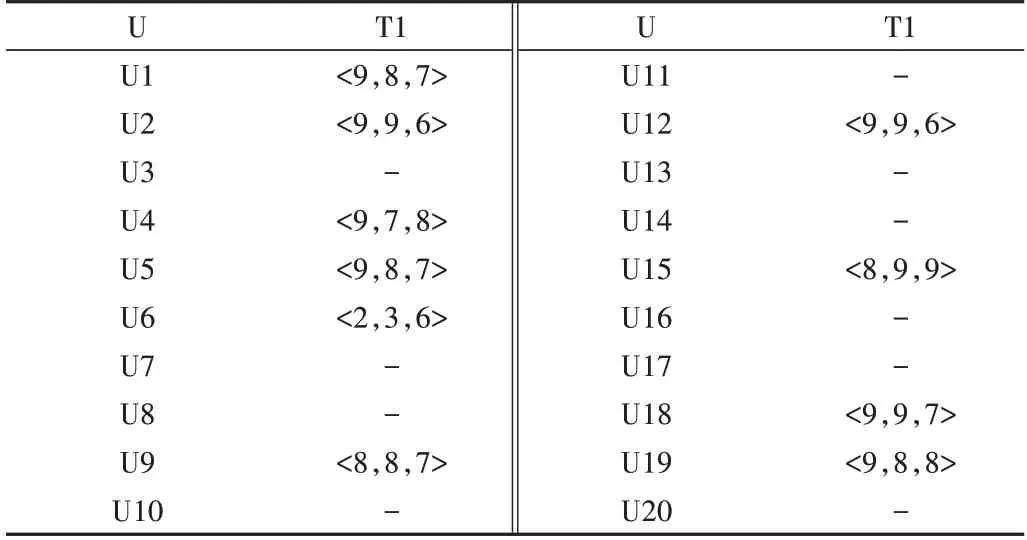
Table 1 Scoring table for crowdsourcing tester T1表1 众包测试人员T1评分表
2.2 客观信誉度计算
2.2.1 影响因素
选择按时交稿任务数量、发现Bug 数量、有效Bug 数量以及测试人员等级4 个影响因素对测试人员客观信誉度进行研究分析[17],具体如表2所示。
(1)按时交稿任务数量。众包测试人员的按时反馈对于发包方错误的及时更正具有重要意义,基层严重Bug 的出现会导致整条生产线重新测试。同时按时交稿任务数量也体现了众包测试人员的时间观念,是影响众包测试人员信誉度的重要因素。
(2)发现Bug 数量。发现Bug 数量多少是测试人员能力和工作积极性的一种体现,发现Bug 数量越多,众包测试人员的信誉度也会有一定提高。
(3)有效Bug 数量。有效Bug 数量是相对于发现Bug数量来说的,有效Bug 越多,且在Bug 数量中占比越大,说明众包测试人员测试质量越高,其信誉度也就越高。
(4)测试人员等级。众包测试人员等级分为初级、中级、高级,等级划分是对众包测试人员能力的认定,其等级越高,信誉度也就越高。

Table 2 Influencing factors of tester's credibility表2 众包测试人员信誉度影响因素
2.2.2 层次分析法
层次分析法是一种解决多目标复杂问题的定性与定量相结合的决策分析方法[18],其在对复杂决策问题的本质、影响因素及内在关系等进行深入研究的基础上,利用较少的定量信息使决策思维过程数学化,从而为多目标、多准则或无结构特性的复杂问题提供简便的决策方法[19]。本文采用层次分析法评估众包测试人员信誉度的客观评分,将影响众包测试人员信誉度的客观因素分为4 个层次,然后借助定性和定量分析得到评价指标的权重向量[20],依据权重计算出众包测试人员的客观信誉度。
层次分析法的具体步骤为:①建立层次结构模型。依据上述影响众包测试人员客观信誉度的目标因素构建出层次结构图,将各因素分为不同层级,构建多层级多指标结构;②构造判断矩阵。依据专家或相关资料对同一层的影响因子两两打分,比较确定影响因子的重要性,以此建立判断矩阵U=(Aij)n×n,其中Aij为因素i相较于因素j的重要程度量化值,判断矩阵中Aij的值越大,说明因素i相对于因素j 越重要,Aij取值范围为1~9;③层次单排序及其一致性检验。计算上述判断矩阵中最大特征根λmax的特征向量,经标准化处理后记为W。W 为同一层次因素对于上一层次因素相对重要性的排序权值,这一过程称为层次单排序[21]。为检验判断矩阵的一致性,需要计算一致性指标CI,公式为:

式中,λmax为矩阵的最大特征值,n 为矩阵阶数。当CI=0 时,表示有完全的一致性,当CI接近于0 时,表示有满意的一致性,CI越大,不一致性越高。
为降低主观偏差,引入判断矩阵的平均随机一致性比率CR,计算公式为:

式中,RI为平均随机一致性指标,对于低阶矩阵可直接通过查表得到。当CR<0.1 时,则表明判断矩阵U通过一致性检验,判别结果为可以接受,否则需要重新构造判别矩阵U,直至通过一致性检验。
2.2.3 判断矩阵构造
如表3 所示,A表示众包测试人员信誉度;B表示影响A的指标,其中B1为按时交稿任务数量,B2为发现Bug 数量,B3为有效Bug 数量,B4为测试人员等级。本文选取直接相关因素,仅构造了一层相关层次结构,因而计算较为简单。根据Santy 的1-9 标度方法及相关资料数据[22],得出A 相对于B 的判断矩阵U,表示为:

2.2.4 信誉度指标权重向量计算
为判断层次分析法是否符合逻辑,需要对判断矩阵U进行一致性检验。根据一致性检验步骤可以得出,U 的最大特征值λmax=4.223 0,将λmax代入式(3)可得CI=0.074 3,RI=0.90,将计算结果代入式(4)可得CR=0.082 6<0.1,说明U 具有满意一致性,对应的特征向量即为其权重向量。U的最大特征值对应的特征向量W=[0.833 8 0.203 5 0.499 8 0.116 7],该向量经归一化处理后可得=[0.504 2 0.123 0 0.302 2 0.070 6]。归一化后的向量称为权向量,可以看出在计算众包测试人员信誉度时按时交稿任务数量最重要,其次为有效Bug 数量,再次为Bug 数量,最后为众包测试人员等级,具体权重如表3所示。
根据权向量的计算结果可以得到众包测试人员信誉度影响因素指标模型,表示为:

2.2.5 信誉度影响因素权重的应用
测试用户信誉度N0可表示为:

Table 3 Credit impact indexes and their weight value表3 信誉度影响指标及其权重值

该式是对信誉度各影响因素的归一化处理,其中N表示测试用户当前指标值,Nmax为该指标的最大值,Nmin为该指标的最小值。
根据表3 中的权重构建众包测试人员客观信誉度计算模型,表示为:

式中,Ci为信誉度计算模型中第i 个影响指标的赋值,本文采用10 分制,则Ci=10 ×N0;Wi为第i 个影响指标的权重。将赋值分别乘以权重并求和,所得分数即为众包测试人员客观信誉度值。
2.3 复合信誉度计算模型
综合分析主观和客观影响因素,众包测试人员复合信誉度Z最终表示为:

式中,V表示众包测试人员主观信誉度值,A表示众包测试人员客观信誉度值;α、β 分别表示其对应权重,且α+β=1,其值可以根据用户个人需要设定。
3 实验方法与结果分析
数据提取自某开放式网络授课系统的实验结果[23],将学生在亚马逊众包平台完成的1 000 道测试题得分作为初始信誉度评分,再通过发布新任务更新学生的信誉度。实验在初始信誉度数据的基础上进行相应扩展并模拟出众包测试社区中3 种典型众包测试人员TS1、TS2、TS3,其中TS1 为优秀型,TS2 为一般型,TS3 为恶意型。为验证人为恶意评分对众包测试人员信誉度的影响,实验模拟了一批发包方对TS1 和TS2 进行恶意差评,对TS3 进行好评,评分为10 分制,模拟众包测试人员数量为50 人,信誉值计算次数分别为10 次和20 次。在计算客观信誉值时,参考众包测试人员信誉度模拟相应数值,要求偏差不能过大。
为验证本文模型的优越性,分别对基于发包方评分的模型和本文复合模型进行信誉度计算。其中基于发包方评分的模型信誉度计算以网络授课系统实验中学生的信誉度为基础,仅根据新发包方的评分更新迭代众包测试人员的信誉度。图2 为仅基于发包方评分计算出的众包测试人员信誉值,可以看出,恶意评分对众包测试人员的信誉值影响较大。从图2(a)可以看出,TS2 一般型人员在恶意差评下迭代10 次的信誉值与TS3 恶意型人员在故意好评下迭代10 次的用户信誉度值重叠。由图2(b)可以看出,当迭代20 次时,TS3 恶意型人员的信誉值甚至高过了TS1 优秀型人员,这明显与实际情况不符。基于发包方评分的模型受恶意评价影响严重,评价结果不够合理。

Fig.2 Credibility values of different types of personnel under the employer's scoring model图2 不同类型人员在发包方评分模型下的信誉值
图3 为基于本文复合模型计算出的众包测试人员信誉值。在同样的恶意评价下,可靠置信区间的计算排除了大部分恶意评价,只有一小部分与众包测试人员历史评分相近的评分被保留代入计算,因此对主观信誉度值影响不大。由于客观信誉度不受主观评分影响,只与众包测试人员本身的行为有关,使得综合信誉度几乎不受恶意评分的影响。由图3 可以看出,无论是迭代10 次还是20 次,不同类型测试人员的信誉值均可以保持平稳,说明复合模型可根据测试人员实际行为对其信誉度作出有效评估。

Fig.3 Credibility values of different types of personnel under the compound models图3 不同类型人员在复合模型下的信誉值
4 结语
本文提出一种基于将主客观因素相结合的移动应用众包测试人员信誉度复合计算模型,该模型通过发包方对测试人员的主观评分以及评分可靠置信区间的计算迭代更新测试人员的主观信誉度值,根据众包测试人员行为计算其客观信誉度值,最后将两者结合,根据各自权重综合计算出最终信誉度。该模型既排除了主观因素的恶意评分,并对主观信誉度进行实时更新,又考虑了众包测试人员行为因素,使得评价结果合理性得以保证。
目前复合信誉度模型还存在一定缺陷。首先,评分可靠置信区间的计算会阻挡真实的跳崖式下降或上升的评分,影响众包测试人员主观信誉度的真实性;其次,目前考察的客观信誉度影响因素不够完善。下一步将结合发包方评分参考价值度增强众包测试人员主观信誉度的真实性,并进一步完善影响因素模型,对众包测试人员信誉度进行扩展性研究。
