基于项目特征与用户兴趣模糊性的推荐算法
2022-09-22黄向春赵芬霞安建业
黄向春,赵芬霞,安建业
(天津商业大学理学院 天津 300134)
0 引言
随着大数据时代到来,各种数据信息快速增长。在面临海量数据时,用户通常需要花费大量时间寻找感兴趣的信息,信息过载已成为互联网发展不得不面对的挑战。
为此,推荐系统应运而生。该系统通过收集用户历史信息或行为数据建立用户或项目特征模型,预测用户感兴趣的信息然后推荐给用户。如果电商网站能将用户感兴趣的产品准确推荐给用户,不仅能够增加电商网站的销量,还能提升用户对网站设计的满意度,产生巨大的商业价值[1]。
根据推荐策略不同,推荐系统可分为基于内容的推荐、基于知识的推荐、基于规则的推荐、协同过滤的推荐、混合推荐等。其中,协同过滤推荐是目前发展最成熟、应用最广泛的个性化推荐技术[2-6]。该类系统通过寻找与目标用户兴趣相似的“邻居”,给目标用户推荐可能感兴趣的信息,系统整体设计较为简单,仅基于统计的机器学习算法就能够取得较好推荐效果。
然而,协同过滤推荐算法的推荐效果严重依赖于用户的历史偏好信息,当该类信息无法被收集或信息量过少时,会造成数据稀疏程度较高。此时,项目评价信息的真实性和有效性将无法得到保证[7],协同过滤算法的推荐效果也会相应降低。
1 相关研究
目前,为解决项目评分矩阵稀疏性问题的方法种类较多。例如,Ma[8]首先提出将SVD 矩阵分解应用于协同过滤推荐,在Netflix Prize 数据集上的实验结果表明,该算法推荐准确率相较于基准算法具有一定的提升,且推荐结果稳定性较强。Goldberg 等[9]利用主成分分析降维技术构建推荐算法,并将其成功应用于“笑话”推荐上,实践结果表明算法效果较好。李红梅等[10]提出一种改进LSH 的协同过滤算法,该算法有效克服评分数据的高维稀疏问题。然而,上述算法并未考虑项目特征或用户偏好的模糊性问题。
为此,Zhang 等[11]使用三角模糊数描述用户对项目的综合评价,根据三角形面积和中点衡量三角模糊数的相似度,确定用户相似度,提升相似度计算的准确率。然而,三角模糊数中隶属度的最大值只对应一个点,灵活性低于梯形模糊数,可扩展性较差。吴毅涛等[12]借鉴年龄模糊模型,将满意度映射到原始评分上,通过梯形模糊相似度计算策略衡量用户相似度提升推荐效果[13-15],同时证明模糊相似度是余弦相似度在模糊域上的扩展,实验结果表明该算法的预测精度优于基于三角模糊数的协同过滤算法。然而,该模型的结构相对固定,无法随数据集和用户的改变自动调整。Wu等[16]在文献[9]的基础上,根据评分分布情况自动生成个性化梯形模糊评分模型,基于模糊相似度和模糊评分预测评分提升推荐质量,实验结果表明该算法的预测误差更低。王森等[17]构建一种新的梯形模糊评分模型,通过融合基于模糊评分的项目相似度和基于标签隶属度的项目相似度形成新的项目相似度,进一步提升了推荐准确率。
然而,项目特征和用户兴趣均具有一定程度的模糊性。例如,对电影《战狼1》进行项目特征划分时,它的所属类别并非是绝对的、唯一的,多数观众认为它属于动作类、军事类、战争题材的电影,但也有一部分观众认为它是爱情类电影。为了综合所有观众的评价,设定《战狼1》隶属于动作类电影的程度为80%;隶属于军事类电影的程度为85%;隶属于爱情类电影的程度为20%。同理,用户对电影的喜爱程度也可按照此情况进行划分。通过综合考虑用户兴趣和项目相似度来计算推荐信任分,据此给出更为准确的推荐结果。
2 算法描述
2.1 模糊集和隶属函数
设在论域X上给定集值映射μA:X→[0,1],记作μA(x),即μA确定了X上的一个模糊集,记为A,μA(x)为x对A的隶属度,记为:A={(x,μA(x))|x∈X}。在模糊理论中,常见模糊集包括矩阵型、三角形、梯形、K 次抛物线型、高斯型、柯西型等。
2.2 项目特征隶属度矩阵
隶属度可用来描述项目对于不同类别的所属程度。例如,对项目Ij(j=1,2,…,N)而言,将项目所属类别定义在空间X={x1,x2,…,xK}中,Ij的隶属度函数可表示为μk(Ij)[18]。本文采用类高斯隶属函数[19]描述项目的特征模糊性。计算公式如式(1)所示:
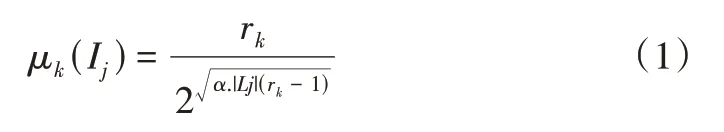
其中,N=|Lj|为项目Ij所对应项目特征属性的个数,rk(1 ≤rk≤|Lj|)为项目Ij属于第k个类别的秩,α一般设置为1.2[20],μk(Ij)是关于rk的递减函数,以电影数据集为例,排序靠前的类别可赋予高的隶属度,与电影无关的类别其隶属度可赋予0。
然而,不同电影之间相同的所属类别,由于所在位序存在不同,对应的隶属度也会不同[21]。例如,电影Toy Story(选自MovieLens 100K 数据集),类别有Adventure、Animation、Children′s,所属类别的秩依次为rk=1、2、3,这3 个类别在所有类别中的序号依次为3、4、5。根据式(1)计算电影Toy Story 对应类别的隶属程度分别为:μ3(Ij)=1、μ4(Ij)=0.536、μ5(Ij)=0.467、μk(Ij)=0,(k=1,2,6,7,···,19),k表示电影的类别序号,即电影Toy Story 属于Adventure、Animation、Children′s的隶属程度分别为1、0.536、0.467。
本文从MovieLens 100k 电影数据集中,选取用户5 的观影记录,观影记录所属类别的隶属度如表1所示。
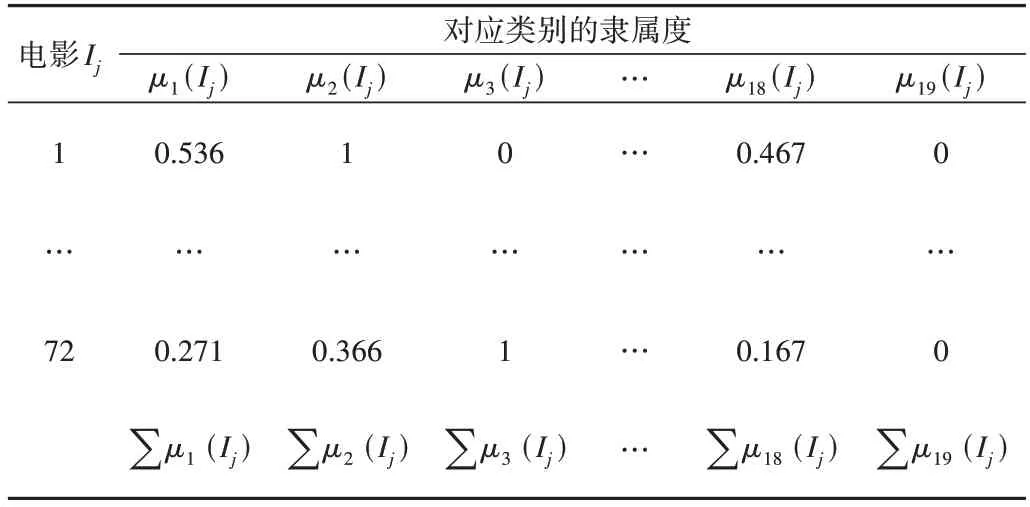
Table 1 Film category membership表1 电影类别隶属度
2.3 用户类别偏好矩阵
利用类高斯隶属度函数可构建项目特征隶属度矩阵UN×K,N、K分别表示项目总数和项目特征个数。将单个用户的项目特征隶属度矩阵按列相加,结果表示用户访问项目类别隶属程度的总和,总和越大表示用户对该类别项目的喜欢程度越高。基于此,生成该用户的类别偏好向量s[15]。s=(p1,p2,…,p19),将s归一化为s′=(s1,s2,…,s19),其中sk为:

最后,将所有用户的类别偏好向量作为行,构造用户类别偏好矩阵SM×K。其中,M表示用户个数,K为项目类别个数。
2.4 用户兴趣模型
由于用户对项目的评分受用户类别偏好的影响,因此对于两种不同类别的项目,相同的项目评分可能代表着不同的喜好程度。为此,通过用户类别偏好矩阵SM×K对用户评分矩阵RM×N进行修正。计算公式如下:
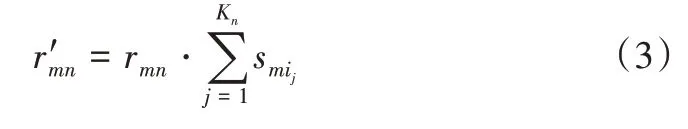
其中,r′mn为第m个用户对第n个项目修正后的评分,rmn为第m个用户对第n个项目的原始分,Kn为第n个项目所属项目类别的总数,设其所对应的类别序号依次为为第m个用户对第n个项目所属第ij类型的偏好程度,修正后的用户项目评分矩阵记为。通过用户类别偏好矩阵修正后的用户项目评分数据更离散化,能准确代表用户对项目的喜好程度。
然后,利用修正后的用户项目评分矩阵构建项目Ij的用户兴趣模型。在构造用户兴趣模型时,将用户对电影的兴趣分为非常喜欢、喜欢、不喜欢和非常不喜欢,由于要将修正后的评分均值作为用户喜欢和不喜欢的临界点,在多次实验测试后,选择将0.75 为临界点,构建的梯形隶属度函数如下:
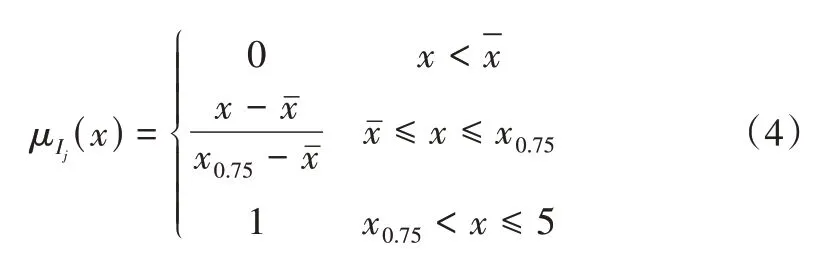
其中,x为用户u对项目的修正评分值,为用户u修正评分的均值,x0.75为用户u修正评分的0.75 分位数。电影数据用户的评分最高为5,因此x的上限设定为5,并定义用户喜欢的项目集合为
2.5 推荐信任分
经过多次实验比较后,本文选用cosine 余弦计算项目之间的相似度,即项目Ii和Ij的相似度计算公式为:
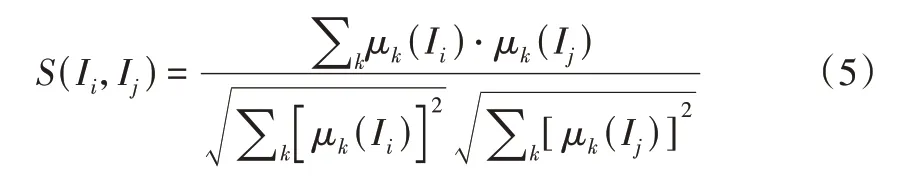
接下来,综合用户的兴趣和项目间的相似度计算推荐信任分,计算公式如式(6)所示:
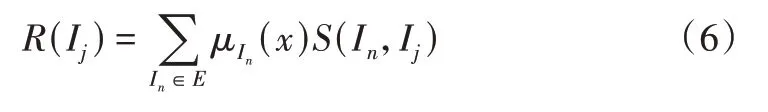
其中,μIn(x)为用户对项目In的喜欢程度,S(In,Ij)为In与要推荐项目Ij之间的相似度,推荐信任分R(Ij)表示用户喜好程度与相似程度的加权和,数值越高表示推荐信任分越高。
最后,根据R(Ij)大小产生Top -N 进行推荐。
3 实验结果与分析
3.1 数据集
MovieLens 100k 数据集包括943 个用户对1 682 部电影的10 万条评分数据,电影类别总共有19 种,分别为动作、冒险、动画等。每名用户至少对20 部、至多对737 部电影进行评分,评分为1-5的整数。
实验采用准确率(Precision)和召回率(Recall)作为系统评价指标,计算公式如式(7)、式(8)所示:

其中,用户u推荐的P个物品记为R(u),用户u在测试集上喜欢的物品集合为T(u)。
3.2 实验步骤
本文实验具体步骤如下:
步骤1:调用MovieLens 100k 数据集中的u.data 文件(用户电影评分数据),生成用户电影评分矩阵。
步骤2:输入数据集中的u.Item 文件(电影所属类别数据),根据公式(1)生成电影所属类别的隶属度矩阵。
步骤3:根据电影所属类别和用户的观影记录,根据公式(2)构建用户—电影类别偏好矩阵。
步骤4:通过用户—电影类别偏好矩阵,根据公式(3)对用户电影评分矩阵进行评分修正。
步骤5:基于修正后的评分,根据公式(4)获得用户喜欢的项目集合E。
步骤6:从数据集中随机抽取100 个用户作为样本,将单个用户修正后的电影评分划分为训练集和测试集,训练集的大小依次为5、15、25、35、45、55,剩余样本作为测试集。
步骤7:通过用户兴趣模型确定每个用户感兴趣的项目个数,并通过式(5)、式(6)计算测试集的电影推荐信任分。
步骤8:根据推荐信任分产生Top -N,计算推荐的准确率(Precision)及召回率(Recall)。
3.3 实验结果
本文提出的基于项目特征与用户兴趣模糊性的推荐算法(Based on the fuzziness of item features and user interest method,FIUM)分别选择了5、15、25、35、45、55 的训练集个数,推荐Top-5的准确率如图1所示。
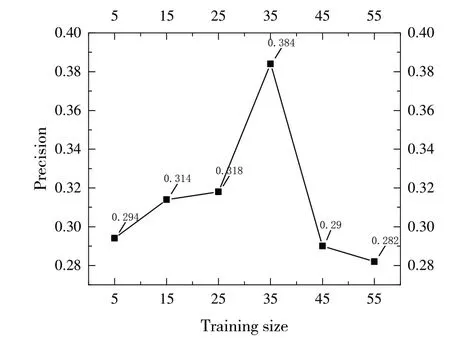
Fig.1 Accuracy of FIUM algorithm图1 FIUM算法准确率
由图1 可见,随着训练集数目增加,推荐准确率先增加再减少,最后趋于稳定,表明一旦训练集的数目足够代表用户兴趣时,增加训练集的个数将不再提高推荐准确率。
接下来,将FIUM 与基于用户的协同过滤推荐算法(User-based-CF,UCF)和基于项目的协同过滤推荐算法(Item-based-CF,ICF)进行比较。设定UCF 的邻居个数与ICF 相似项目个数K为9,FIUM 的训练集个数同样设置为9,N取1-300,算法的Top -N 推荐准确率及召回率分别如图2、图3所示。

Fig.2 Comparison of accuracy between FIUM and UCF and ICF图2 FIUM与UCF和ICF准确率比较
实验结果表明,随着推荐数目增多,相较于UCF 和ICF,FIUM 算法平均准确率分别提高39.66%和5.74%;平均召回率分别提高36.68%和158.76%。当推荐数目大于10 时,FIUM 的准确率明显高于UCF 算法;当推荐数目大于100时,FIUM 算法召回率明显高于ICF 算法的召回率。
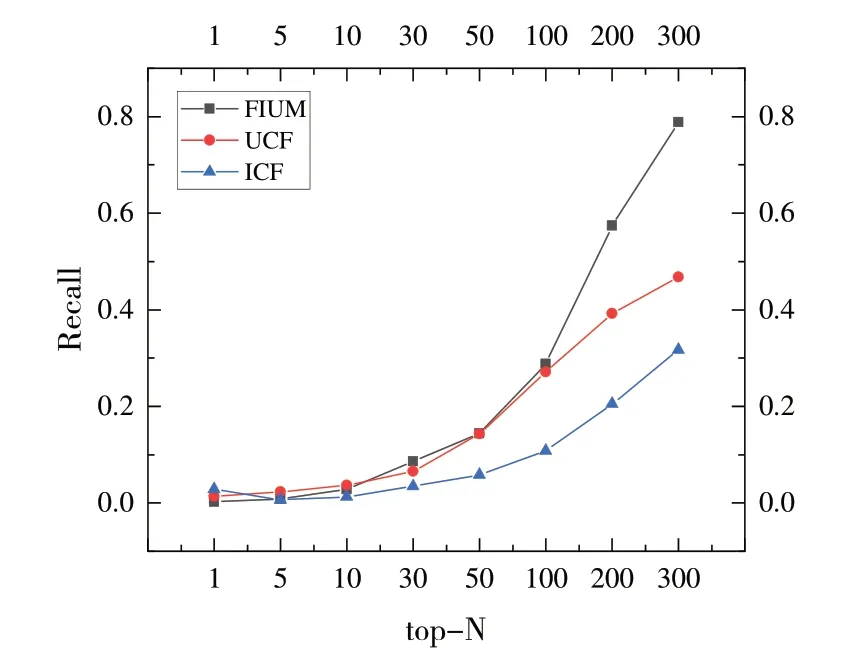
Fig.3 Comparison of recall between FIUM and UCF and ICF图3 FIUM与UCF和ICF召回率比较
4 结语
本文提出了基于项目特征和用户兴趣模糊性的推荐算法,并与基于用户和基于项目的协同过滤算法进行比较。实验结果表明,该算法的召回率和推荐准确率相较于比较模型均有所提升。
然而,该算法需要计算用户感兴趣的项目与各个项目之间的相似度,在面对海量项目推荐时,计算量较大,会导致系统推荐效率降低。并且,MovieLens 观影数据除了以上常规数据外,还含有导演信息、演员信息、时间等信息,现阶段还未将其充分利用。下一步,将尝试对此类信息进行模糊化或直接加入用户兴趣模型中来提高推荐准确率及召回率。
