乙醇偶合制备C4烯烃的生产参数研究
2022-08-30王桂旭杨曾欣
王桂旭,杨曾欣
(西安电子科技大学 电子工程学院,西安 710126)
C4烯烃的生产一般通过化石能源的裂解、馏分得到,其依赖于石油资源,会造成对环境的严重污染。随着有机化工技术的发展,C4烯烃也可以通过乙醇偶合反应制得,而乙醇资源更为便宜与丰富,对环境污染更小,有更高的经济价值。
本文根据2021年全国大学生数学建模大赛B题的数据,研究催化剂组合与温度对乙醇转化率、C4烯烃选择性的影响关系,并以C4烯烃收率为优化目标,计算最佳的生产参数。
1 模型准备
为了定量分析问题,首先提取“催化剂组合”中蕴含的数字信息,并作出符号标记,见表1。然后提取乙醇转化率、C4烯烃选择性,删除其余无关的特征。最后针对特殊催化剂组合A11,因为与其他组合相比,没有催化剂载体HAP,并且数据量只有一组,所以暂时删除此组。

表1 变量的符号标记
其中,Co/SiO2与HAP质量比,C4烯烃收率满足以下数量关系:

2 模型建立与求解
2.1 岭回归模型
为了探索各个因变量对乙醇转化率、C4烯烃选择性的影响关系,可以通过岭回归线性模型(Ridge Regression)分别对两者进行回归分析。模型可表示为:

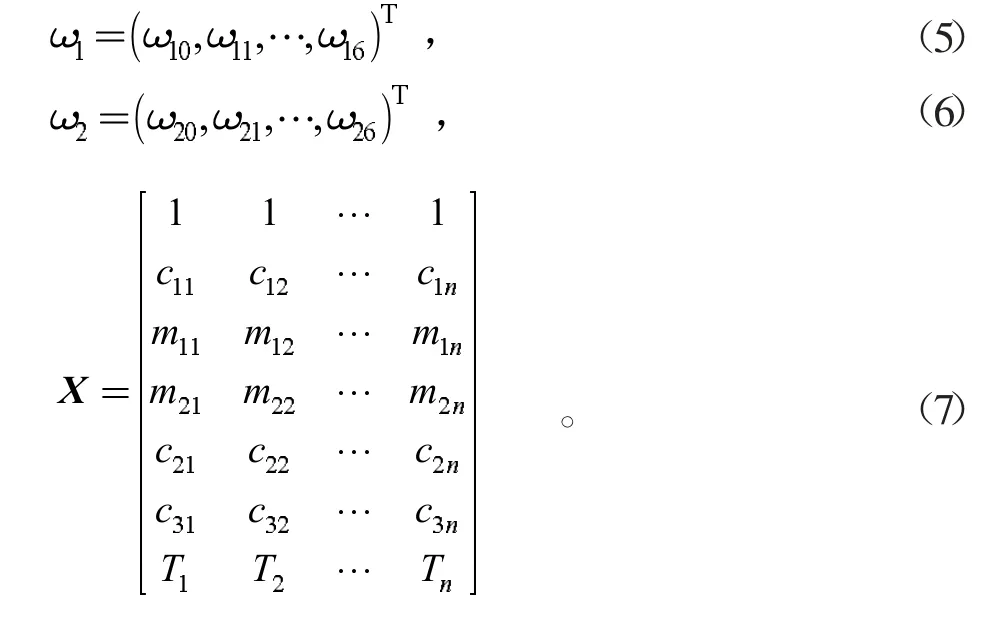
回归系数可通过式(8)、式(9)得到。
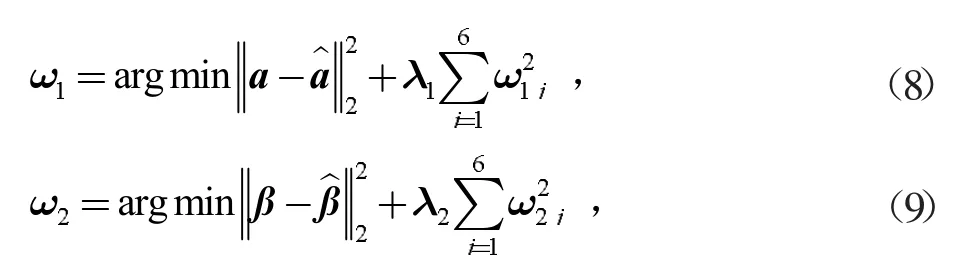
式中:向量α、β分别代表乙醇转化率与C4烯烃选择性的真实值,正则化系数λ1、λ2代表L2正则化强度,其值越大,模型的稳健性越好,不容易受到共线性变量的影响。
2.1.1 判断共线性
为了检查模型是否受到共线性变量的影响,正则化系数λ1、λ2可以先设置一个较小值,如10-3。先对数据进行分割,一部分作训练集,另一部分作测试集,然后对训练集进行岭回归分析,得到两者的决定系数分别为。由于各个变量间的范围、量纲不同,需要对回归系数进行归一化,可将变量的回归系数乘以变量对应的标准差。

运用交叉验证对训练集重复计算5次,可以得到回归系数的变化范围,如图1所示。
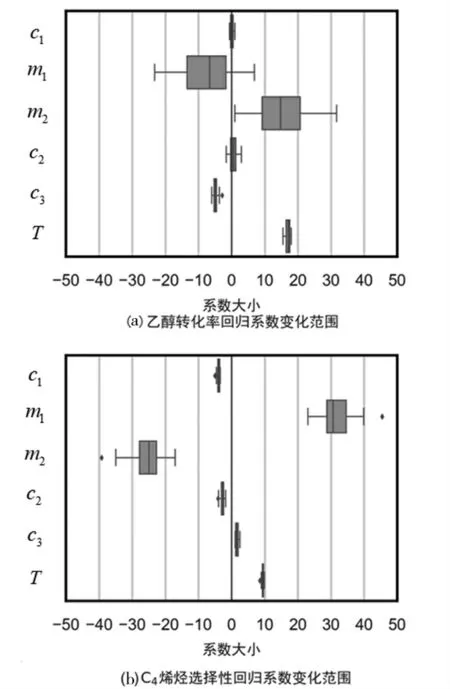
图1 回归系数变化范围
由图1中可以看出,m1、m2的回归系数变化范围较大,存在一定程度的相关关系,即m1、m2共线性。由式(1)知Co/SiO2与HAP质量比与Co/SiO2质量、HAP质量存在关系,因此剔除回归变量c2,对训练集重新进行回归,检验回归系数的变化范围,如图2所示。
在图2中,m1、m2的回归系数变化范围相较图1更小,说明剔除共线性变量c2后,模型的稳健性更好。

图2 排除共线性后的回归系数变化范围
2.1.2 优化正则化系数
在一定范围内对正则化系数进行穷举搜索,使用留一法(leave-One-Out)进行交叉验证,即在训练集中每次只校验1个数据,训练其余所有数据,得到每个系数每次训练的均方误差(Mean Squared Error,MSE),再计算其均值得到每个系数对应的均方误差。再筛选出最小均方误差,其对应于最优正则化系数。最后,得到λ1=3.852 1,λ2=11.189 5,乙醇转化率、C4烯烃选择性的回归系数如图3和图4所示。
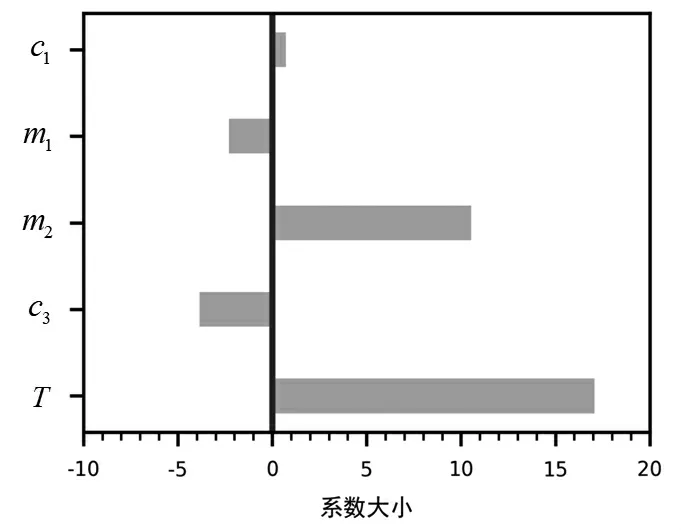
图3 乙醇转化率的回归系数

图4 C4烯烃选择性的回归系数
比较各变量标准化回归系数的大小,可以发现温度、载体HAP质量与乙醇转化率呈强正相关,而催化剂Co/SiO2质量、乙醇浓度与其呈负相关。同理,温度、催化剂Co/SiO2质量与C4烯烃选择性呈强正相关,而Co负载量、载体HAP质量与其呈负相关。其中,温度对乙醇转化率与C4烯烃选择性的变化是一致的,温度越高,两者的值都越大;而Co负载量、催化剂Co/SiO2、载体HAP的质量与乙醇含量在两者的变化是相反的。并且温度的标准化回归系数是最大的,说明对两者的影响程度也是最大的,因此在合适的调节范围内,应尽可能使反应温度达到最大。
2.2 多层感知机
为了优化生产参数,提高C4烯烃收率,需要对乙醇转化率与C4烯烃选择性作出更精确的预测。一般的线性回归模型无法适应复杂的模式,可解释的方差如前面3.1所述,只能达到70%左右,应该使用非线性模型,如多层感知机(Multilayer Perceptron),对生产结果进行回归。
2.2.1 网络结构
多层感知机模型利用全连接网络发现复杂的模式,网络的层数、神经元个数越多,探索复杂模式的能力越强大。在相邻两层网络中,后一层网络的输出与前一层的输入满足

式中:Xi+1表示第i+1输出;Xi表示第i层输入;Wi、bi分别是2层之间的权重矩阵与偏置向量;f(*)是激活函数,使用ReLU函数。根据3.1.2所述,温度对乙醇转化率与C4烯烃选择性的影响较为简单,而催化剂质量与乙醇含量对两者的影响比较复杂,不同的自变量对因变量的影响复杂度不同,因此考虑使用图5的网络结构,能将简单的特征与复杂的特征结合,共同输出给下一层网络。
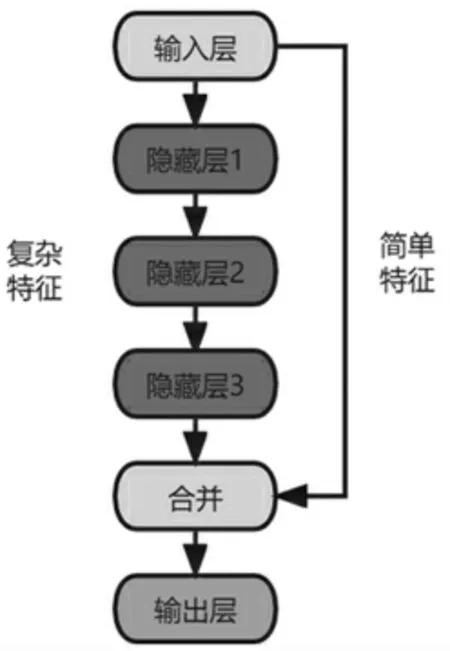
图5 多层感知机网络结构
2.2.2 训练神经网络
首先将数据集进行分割,划分为训练集(80%)、校验集(10%)与测试集(10%),并对数据进行归一化处理(均值为0,方差为1),即:

然后初始化网络结构,设置三层隐藏层,其神经元个数初始化分别为128,100,32;输出层神经元个数为2,即输出乙醇转化率与C4烯烃选择性2个指标。损失函数选择均方误差,评价指标选择决定系数,其表达式为:

同时,使用随机梯度下降法(Stochastic Gradient Descent)训练网络,设置初始学习率为0.001,如果校验集的损失函数值停滞下降的次数超过10次,学习率更新为原来的0.2倍;如果停滞次数超过20次,则结束训练,防止模型过拟合。训练的过程如图6和图7所示,经过178轮训练,在训练集上,loss减小到0.12,R2上升到82%。
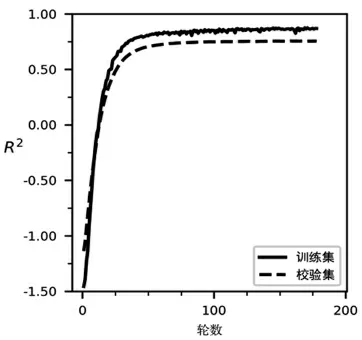
图6 决定系数R2的训练过程

图7 损失函数loss的训练过程
2.2.3 调整超参数
为了进一步提高模型的精度,需要调整初始的超参数,如学习率初始值、神经元个数。考虑到参数空间较大,本文通过k折交叉验证,以模型在校验集上的R2均值为评价指标,采用蒙特卡罗模拟法在一定范围内对超参数进行搜索。参数范围设定学习率初值在10-6~10-3,每个隐藏层神经元个数在5~200,最终得到最佳学习率为0.004 18,隐藏层神经元个数分别为172,159,127。在测试集上,模型对乙醇转化率与C4烯烃选择性的预测结果如图8所示。

图8 乙醇转化率与C4烯烃选择性的预测
模型在测试集上的R2=0.85,且由图8可知,对于α、β数值较小的样本,预测结果良好;对于α、β数值较大的样本,预测值与真实值存在一定偏差。
2.2.4 优化生产参数
多层感知机经过优化后,能根据生产参数准确预测乙醇转化率与C4烯烃选择性,再通过式(2)得到C4烯烃收率。为了保证预测的合理性,需要统计出原数据各变量的最小值与最大值,确保新的生产参数应该在其范围内。在温度不受限时,可以建立如下的优化模型

式中:g(*)代表多层感知机的回归函数。通过蒙特卡罗模拟法对生产参数进行反复搜索,不断缩小搜索范围,可以得到此时最佳生产参数,见表2。当温度不能超过350℃时,优化模型变成
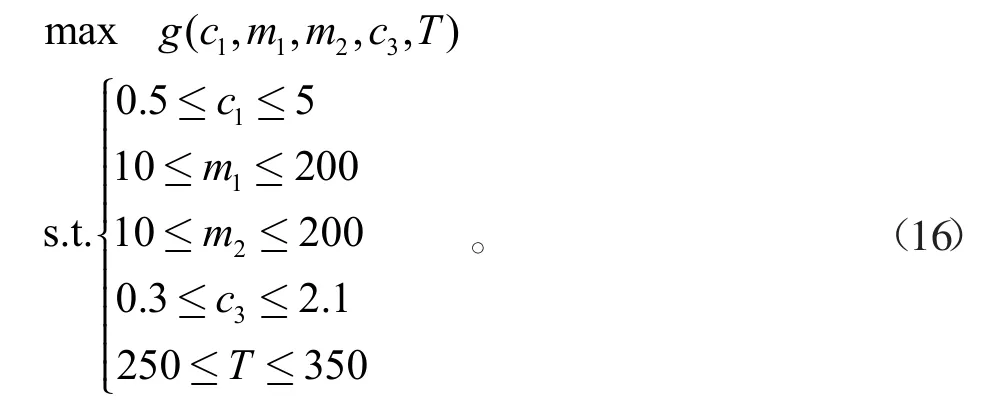

表2 温度不受限时的最佳参数
运用同样的方法,可得到温度受限时的最佳参数,见表3。

表3 温度不超过350℃时的最佳参数
其中,温度不受限时,最优生产参数可以使乙醇转化率达到99.03%,C4烯烃选择性达到58.09%,最大C4烯烃收率为57.52%;温度不超过350℃时,最优生产参数可以使乙醇转化率达到54.33%,C4烯烃选择性达到38.52%,最大C4烯烃收率为20.93%。并且,在2种情况下,Co/SiO2的质量、HAP的质量与温度均会达到上界,Co负载量会在温度不受限时达到上界,而乙醇含量会处于中间值,这说明适宜的乙醇含量才有利于C4烯烃的生成。
2.2.5 载体HAP的影响
由于模型最初删除了催化剂组合A11,导致实验结果全部包含载体HAP。为了分析载体对乙醇转化率、C4烯烃选择性的影响,让其余参数保持不变,预测载体HAP存在时两者的大小,结果如图9和图10所示。
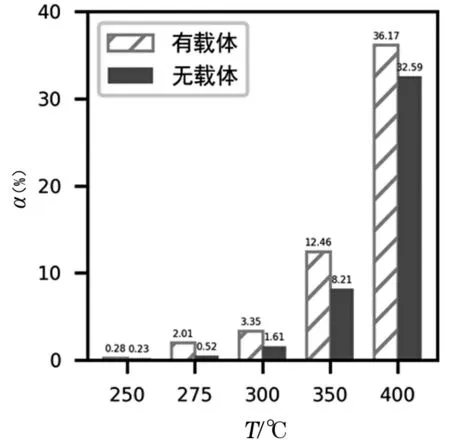
图9 载体HAP对乙醇转化率的影响
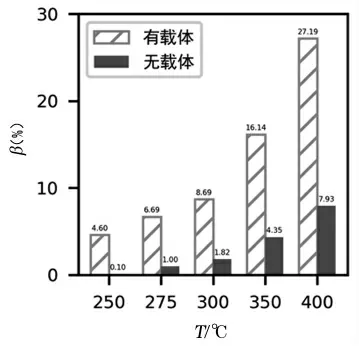
图10 载体HAP对C4烯烃选择性的影响
由图9和图10可以看到,在相同条件下,有载体HAP的转化率与选择性均比无载体时更大,尤其是C4烯烃选择性,差异更加明显。说明载体HAP能促进偶合反应,显著提高目标产物选择性,同时也肯定3.2.4中的含载体HAP的生产参数是最优的。
3 结论
通过岭回归与多层感知机模型,探索了乙醇偶合制备C4烯烃中生产参数对乙醇转化率与C4烯烃选择性的影响,在一定的范围内求解出最优的生产参数,使C4烯烃收率最大。通过比较载体HAP的有无以及对比温度不受限与受限的2种情况,发现载体HAP能提高C4烯烃选择性以及反应温度对生产收率有很大的影响。在实际生产中,应尽可能保持最大温度。
