改进YOLOv4网络的煤矿井下行人检测算法
2022-08-30汝洪芳王珂硕王国新
汝洪芳, 王珂硕, 王国新
(黑龙江科技大学 电气与控制工程学院, 哈尔滨 150022)
0 引 言
传统矿业正在向智慧矿山转型,加速自动化和智能化的发展,但其安全性仍未得到很好保证。井下环境昏暗、矿洞复杂,工作人员易进入危险区域,煤矿井下开采运输设备存在视线盲区。目前,主要是通过人工倒班监控各工作点,判断是否有人误入危险区域。但是监控点多、监控显示器屏幕小,对工作人员要求比较高,长期容易疲倦、注意力不集中,不能及时觉察到危险的发生或对某些行为出现误判,因此,自动检测煤矿井下人员尤为有必要。
煤矿井下行人检测对提升其安全性有着重要意义。袁海娣等[1]使用Soft-NMS代替NMS,改进了Cascade R-CNN的井下行人检测算法,在自制井下行人数据集中获得了较好的检测准确率,但其运行速度较慢,未能满足实时检测的要求。韩江洪等[2]提出通过Faster R-CNN网络实现井下行人定位。魏力等[3]在特征提取网络中融入了通道注意力机制,增强了图像中行人的特征信息,抑制了不重要的背景信息,提高了在分辨率低和有遮挡情况下的检测性能。景亮等[4]改进了YOLOv3目标检测网络,结合双目相机获取目标的深度信息,提高了网络的检测性能和定位的准确率。目前,使用广泛的YOLOv4目标检测算法在井下行人检测中表现出了较高的准确性,由于网络模型及参数计算量大,使网络在使用时检测速度较低,未能达到实时检测的要求,不能很好地适用于离线设备。笔者通过轻量化YOLOv4深度学习神经网络,减小网络模型及其模型的计算成本,以提高网络的检测速度。
1 改进YOLOv4目标检测算法
1.1 YOLOv4目标检测算法
2020年,YOLOv4网络改进了YOLOv3[5],其检测速度及精度均优于YOLOv3网络。YOLOv4由CSPDarknet53网络、SPP特征增强模块、PANet路径聚合网络和YOLO head[6]四部分组成。
YOLOv4目标检测网络的检测原理为首先输入端读取视频信息获得图像,调整图像大小均为416×416。通过CSPDarknet53网络提取特征,分割图像得到三种尺寸的网格,大小分别为13×13、26×26和52×52,预测目标的位置及检测类别的条件概率。每个网格中含有3个尺寸的预测框,每个预测框中均含有预测框的位置信息、置信度及被检测目标种类的预测值。
1.2 GhostNet轻量化网络
GhostNet网络是使用较为广泛的轻量级神经网络[7],能够保证其较高准确率的同时,使卷积操作计算成本也较低。Ghost module生成特征映射的过程分为两步,如图1所示。第一步通过卷积操作得到初始特征图;第二步对初始特征图进行恒等映射或小波变换等线性变换获得剩余的特征图。减少了卷积核的数量,降低了模型的计算成本,得到参数量较少的模型,网络的性能基本不会受到影响。
GhostNet网络的基本单元为G-bneck模块,主要由两个Ghost module组成,第一个用来增加特征的通道数,第二个用来减少通道数,以保证Ghost特征与输入特征连接时不会出现通道数不匹配。此外,在个别G-bneck中第二个Ghost module前引入了SE注意力机制[8]。
1.3 ASPP特征增强方法
通常神经网络为增大感受野,会通过增加卷积层和池化层实现,但其同时也会增加网络的深度,甚至可能出现梯度消失,这样对特征传递不利。尤其是池化层越多,输出特征图的尺寸就会越小,越容易丢失特征信息,使后面的操作未能很好地发挥作用,导致网络精度不能有明显提高。ASPP在SPP的基础上结合了空洞卷积[9],利用空洞卷积代替了SPP中的池化操作,与全局平均池化并联,得到新的增大感受野的模型,聚合多尺度特征信息,增强了模型识别不同大小的同一目标的能力。空洞卷积可以在不增加网络深度、池化操作、计算成本的同时,能够增大感受野[10]。通过在卷积层中引入扩张率,表示卷积核间零值的数量,在特征提取时实现跨像素提取。
1.4 深度可分离卷积
深度可分离卷积可以有效减少模型的计算量和参数量[11],分为逐通道卷积和逐点卷积两步[12]。虽然深度可分离卷积的操作步骤有所增加,但其整体的计算量将会减少。
通常用参数量P表示深度学习网络模型的大小,即模型的空间复杂度。使用普通卷积和深度可分离卷积的参数计算量分别为
Pc=k2×Ci×Co,
(1)
Pd=k2×Ci+Ci×Co,
(2)
式中:Pc—— 普通卷积操作的参数计算量;
Pd—— 深度可分离卷积操作的参数计算量;
k—— 卷积核的尺寸;
Ci—— 输入特征通道数;
Co—— 输出特征通道数。
由式(1)和(2)可知,深度可分离卷积的参数计算量的普通卷积为
(3)
采用浮点数运算量FLOPs表示网络模型的时间复杂程度,关系着目标检测算法的检测速度。使用普通卷积和深度可分离卷积的浮点数运算量为
Fc=k2×Ci×Co×ho×wo,
(4)
Fd=(k2+Co)×Ci×ho×wo,
(5)
式中:Fc—— 普通卷积的浮点数运算量;
Fd—— 深度可分离卷积的浮点数运算量;
ho—— 输出特征高度值;
wo—— 输出特征宽度值。
由卷积操作的浮点数计算量式(4)和(5)可知,深度可分离卷积的浮点数运算量为
1.5 改进YOLOv4网络结构
利用轻量型网络GhostNet替换原网络的主干特征提取网络CSPDarkNet53,提高行人检测的速率。在GhostNet替换CSPDarknet53网络时,首先,将GhostNet中最后的卷积层、平均池化层及全连接层删除,其次,找到与原网络提取有效特征的宽和高相同的特征层,即在第6、第10和第15层时提取特征,最后,为避免通道不匹配问题,设置通道数[13]。以416×416×3的输入图像为例,尺寸分别为52×52×40 、26×26×112和13×13×160的特征进行进一步特征增强。对原网络中SPP结构替换ASPP结构,增大网络的感受野,减小遮挡对行人检测的影响。ASPP选择膨胀系数r分别为1、3、5,卷积核大小为3×3的空洞卷积,其结构如图2所示。
ASPP结构对主干网络提取出来的特征图,同时进行卷积和池化操作。通过1×1普通卷积得到原始大小的感受野,通过3×3空洞卷积扩大感受野,根据膨胀系数的不同决定感受野大小的不同,利用全局平均池化得到全局特征信息。以上操作输出相同大小特征图并联接,经1×1卷积和BN层进行一次上采样,输出经ASPP结构处理的特征图,学习不同大小目标的特征,提高目标检测的准确率,降低漏检率。
为进一步减少网络的参数量,在网络中使用深度可分离卷积,使网络在不影响整体效果的同时,降低网络的计算成本。将改进后的网络命名为G-A-YOLOv4,其网络结构如图3所示。各模块内部结构如图4所示。
2 实验结果与分析
2.1 数据集建立
目前,矿井下还未公开的数据集,需要自制井下行人数据集。网络训练的数据集来源于鹤岗益新煤矿的监控视频,有泵房环境的视频7段,共3 h 46 min。
通过OpenCV截取单帧图像,每25帧截取一张图像,对其进行筛选,最后得到含有行人且可用的图像2 045张,按7∶2∶1的比例分为训练集、测试集和验证集。运用labelImg标签标注软件标注图像,将行人部分框选出,标注为“person”,如图5所示。
标注后生成与图像相对应的XML文件,该文件包含网络训练所需要的关键信息:图像的名称、储存的位置、标注目标的类别及标注目标在图像中的坐标。网络训练时,需要提前通过Python程序将目标的类别和坐标提取出来,保存至文本中,以供网络训练使用。在训练时需要将数据集存放在三个文件夹下,分别为用来存放井下含有行人的图像文件、XML文件,以及划分训练集、验证集和测试集后生成的文本文件。
2.2 实验环境
文中使用Pytorch深度学习框架,在自制的井下数据集上训练网络,以及测试网络模型。深度学习网络的训练与测试均使用服务器进行,其操作系统为ubuntu20.4,CPU处理器为Intel(R) Xeon(R) Gold 622R CPU @2.9GHZ×64,运行内存为187.6 GB,GPU处理器为Tesla T4×4,运行环境为Anaconda3,编译环境为Python3.9。
2.3 评价标准
实验中运用αmAP作为评价指标。αmAP为多类检测模型中所有类别平均准确率的平均值,αmAP的值越大越接近于1,表示模型识别定位的准确率越高,其计算公式为
式中:αmAP——目标检测任务中所有类别平均准确率的平均值;
C——目标检测任务中目标类别的个数;
Pek——各类检测目标的平均准率。
Pek的值由P-R曲线下的面积计算而得,P-R曲线是指准确率P和召回率R的代数关系曲线,准确率P为检测模型预测正确的部分占所有预测结果为正样本的比例。召回率R是检测模型预测判断正确的部分占所有正样本中的比例[13]。准确率和召回率的计算公式为
式中:P——网络模型的准确率;
R——网络模型的召回率;
TP——网络模型正确检测的样本数量;
FP——网络模型误检的样本数量;
FN——网络模型漏检的样本数量。
在实际应用中,深度学习模型需要达到实时性的要求,因此,需要评价其检测速度进行,常用的评价方法有通过处理单张图片所需要的时间评价检测速度,也可以采用每秒可检测帧的数量来作为评价标准,文中选择后者进行评价模型的检测速度。
FPS为每秒画面传输帧数,一般情况下电影的FPS为24 fps、电视为30 fps、液晶显示器为60 fps。为使画面流畅,FPS一般需要保持在30 fps以上。在深度学习中,FPS可以表示模型每秒检测的帧的数量,能够直观的表述模型的实时性,FPS值越大,每秒能够检测的帧数量越多,实时性越好。
2.4 实验结果与分析
对改进后的网络进行验证及分析,将实验中网络的学习率设置为0.001,EPOCH设置为70,根据显存大小,将Batch Size设为128。网络训练过程中可以通过损失函数的迭代情况来确定网络训练的收敛程度,如图6所示。
图6a为网络在训练集上损失函数Loss的迭代曲线,图6b为网络在验证集上损失函数Val-Loss的迭代曲线。由此可知,G-A-YOLOv4网络比YOLOv4网络的收敛速度更快,收敛后的Loss值更低,收敛性更好。
G-A-YOLOv4网络与YOLOv4网络训练70个EPOCH后得到网络模型的性能如表1所示。其中,αmAP表示网络模型的准确率,Pa为模型的参数量代表网络模型的大小,F为网络模型的检测速度。由表1可知,改进后的网络准确度有所下降,G-A-YOLOv4降低了0.6%,检测速度较原网络有所提高,G-A-YOLOv4提高了7 fps,网络模型大小有所降低,G-A-YOLOv4降低了84 MB。达到文中对改进后网络的要求,实现在损失较少准确度的前提下减小网络模型大小,提高检测速度,使网络满足实时性的要求。
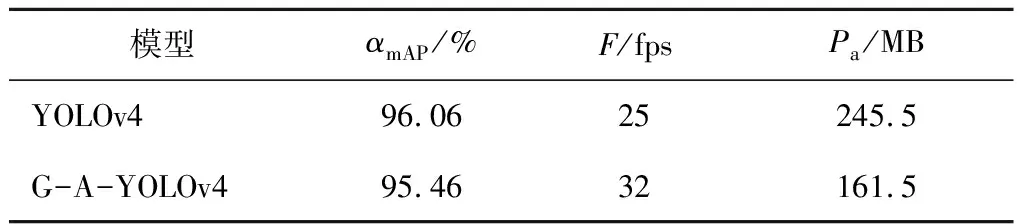
表1 训练70个EPOCH后网络的性能
3 结 论
(1)轻量型网络GhostNet替换YOLOv4网络中主干提取网络,ASPP模块代替SPP增强特征,将网络中的卷积均使用深度可分离卷积进行操作,在损失较少精度的前提下有效减小网络模型的大小,从而提高了网络的检测速度。
(2)采用自制的井下行人数据集在进行训练后得到最终收敛的网络模型,其准确度与原网络相当,仅损失0.6%的准确度,但模型大小较原网络有明显减小,减小84 MB,其检测速度明显提高了7 fps,达到32 fps,能够满足井下行人检测的实时性的要求。
