基于注意力机制的多任务3D CNN-BLSTM 情感语音识别
2022-08-29陈志刚万永菁
姜 特, 陈志刚, 万永菁
(华东理工大学信息科学与工程学院,上海 200237)
语音交互是人与人之间最直接、高效的沟通方式之一。语音中包含着丰富的情感信息,而情感在语音交互中起着至关重要的作用。语音情感识别是指计算机对人类情感语音的感知和理解过程的模拟,即自动识别出语音信号的情感状态[1]。语音情感识别在教育、医疗、服务产业、车载驾驶系统等各个领域已得到了广泛的应用。
语音情感识别系统主要包括以下几个要素:声学特征参数、情感分类模型和情感语料库。其中常用的声学特征有梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC )、振幅、过零率、基音频率、共振峰、短时能量等[2]。此外,基于短时傅里叶方法的语音频谱图可以表征信号的时频变化信息,已成为当前语音情感识别研究的一种趋势。
传统的机器学习方法,例如高斯混合模型、隐马尔科夫模型和支持向量机,在之前的研究中被广泛地用于对提取出的特征进行分类[3-5]。目前,深度神经网络技术在语音情感识别方面也取得了一定的进展,例如卷积神经网络(CNN)和递归神经网络(RNN)[6-7]。2015 年, Lee 等[7]提出了一种具有双向长短期记忆(BLSTM)模型的学习方法,考虑到远距离上下文效应和情感标签表达的不确定性,该系统对语音情感识别的准确率达到了63.89%。2017 年,Satt 等[8]提出了一种基于卷积神经网络-长短期记忆网络(CNN-LSTM)组合的高复杂度模型,直接应用于频谱图,获得了较高的识别精度,同时也限制了延迟。2019 年,胡婷婷等[9]提出通过加入注意力机制来改进LSTM 模型,相比于单LSTM模型,准确率达到57%。2021 年,薛艳飞等[10]提出了一种基于多任务学习的语音情感识别方法,引入语言语种识别作为辅助任务,将在离散情感语料库上的准确率提高到75.38%。目前,这些方法在语音情感识别中的准确率较低且参数提取时存在损失和失真的情况。
本文在前人研究的基础上提出了一种基于注意力机制的多任务三维卷积神经网络和双向长短期记忆网络相结合的情感语音识别方法(3D CNN-BLSTM)。该模型基于Mel 谱图、SPC 声纹图和LPC 声纹图构建具有三维时空特征的多谱特征融合组图作为输入信号,将专注语音情感突出时段的注意力机制融入3D卷积网络建模中,并采用集说话人情感识别与说话人性别于一体的多任务模式进行训练,通过共享网络参数学习共享特征,从而得到更高的分类准确率。
1 基于3D CNN-BLSTM 的语音情感识别模型
1.1 基于语音声纹图的谱特征提取
在语音情感识别领域的研究中,特征参数的提取尤为重要。Mel 谱图可以有效地结合语音的时域和频域特性,将语音信号在时域上频谱的变化情况直观地表现出来,并且符合人耳的听觉特性,相对于传统特征作为输入的模型来说具有天然的优势[11]。SPC 特征可以提取出语音中的谱包络信息,使其不受基频的影响[12]。LPC 特征可以通过过去若干个采样点的线性组合来逼近原始或未来的语音波形,预测语音信号,能够很好地表征出语音的共振峰频率和带宽信息[13]。为了更加有效地提取出语音中的情感信息,将以上3 种特征声纹图沿通道方向堆叠,丰富了语音信号中的特征,而且可以利用其对应位置之间的关系,提取其时空特性。本文使用Mel 谱图、SPC 声纹图和LPC 声纹图构建具有三维时空特征的多谱特征融合组图作为语音情感识别模型的输入。
将语音的最大长度设置为3.5 s(所有语音的平均时长加上标准差),即将较长的语音在3.5 s 处剪切,较短的语音填充零。接下来,将长度为800 的汉宁窗应用于语音信号。采样率设置为16 000 Hz。语音信号的时域波形图和其Mel 谱图、SPC 声纹图和LPC 声纹图如图1 所示(图中颜色尺寸(振幅)转换为分贝,见右侧数据条)。其中帧数fn=800 ,帧移inc=400 ,Mel 谱图、SPC 和LPC 的大小分别为128×300 、 5 12×300 、 2 0×300 ,再通过重采样的方式将大小统一为 1 28×300 ,组成三维声纹图。
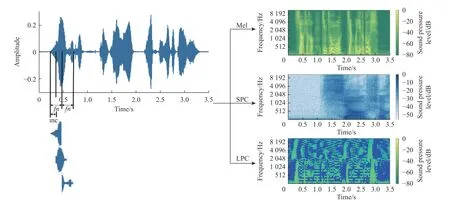
图1 时域波形图和Mel 谱图、SPC 声纹图、LPC 声纹图对比Fig. 1 Comparison of time domain waveform with Mel spectrogram, SPC voice print and LPC voice print
将同一句语音“小时候听祖母讲过一个故事”分别用生气(Anger)、害怕(Fear)、开心(Happy)、中性(Neutral)、悲伤(Sad)、惊讶(Surprise)6 种情绪的Mel 谱图、SPC 声纹图和LPC 声纹图进行对比,结果如图2 所示(图中颜色尺寸(振幅)转换为分贝,见下方数据条)。
由图2 可以看出,由于Angry、Happy、Surprise属于高亢情感,体现在Mel 谱图上的变化比较明显,所以声纹比较清晰;Fear、Neutral、Sad 属于低迷情感,语音波形平缓,起伏较低,体现在Mel 谱图上声纹比较模糊。LPC 声纹图可以很好地表征出语音的共振峰频率和带宽信息,不同情感语音发音的共振峰位置不同,相对于Fear、Neutral、Sad 这些低迷情感,Angry、Happy、Surprise 的共振峰频率略微升高且动态范围更大。SPC 声纹图可以提取出语音中的谱包络信息,谱包络能够反映出语音的音质和发声器官的各种相关参数从而表现出不同的情感,Happy、Fear、Sad 情感中谱包络信息更明显,而Angry、Neutral、Surprise 情感中谱包络信息比较模糊。由于Mel 谱图、LPC 声纹图和SPC 声纹图在这6 种情感中的表现不同,因此提取这3 种特征能够更好地将语音中的情感信息提取出来。
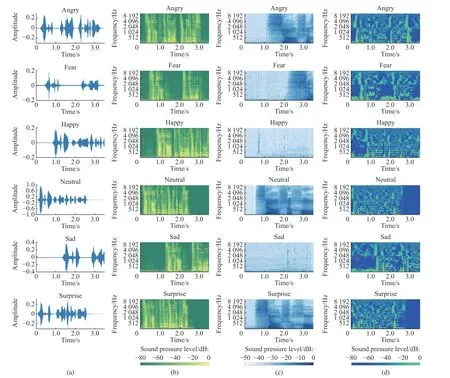
图2 6 种情感的时域波形图(a)、Mel 谱图(b)、SPC 声纹图(c)和LPC 声纹图(d)对比Fig. 2 Comparison of time domain waveform (a), Mel (b), SPC voice print (c) and LPC voice print (d) of six emotions
1.2 自注意力3D CNN-BLSTM
将多谱特征融合组图特征表示为X={x1,x2,···,xL} ,作为3D CNN 的输入,其中xi∈Rf×c;L为时间(帧)长度;f为重采样统一后的大小;c为通道数。为了有效地对输入特征X进行训练,使用基于注意力机制的多任务3D CNN-BLSTM 网络。如图3 所示,该网络主要由四部分组成,包括两层CNN 网络(一层为3D CNN,一层为2D CNN 网络)、两层BLSTM 网络、自注意力网络和多任务层。
1.2.1 改进的三维卷积与二维卷积结合的神经网络
为了更好地学习到多谱特征融合组图中3 个通道对应位置之间的关系,将二维卷积拓展到三维卷积。卷积层包括64 个 3 ×5×2 的卷积核,步长为1,Dropout 层速率设置为0.5。
由于输入的多谱特征融合组图的通道数是3,经过一次三维卷积后沿通道方向的维度变成2,再经过一次最大池化操作,沿通道方向的维度变成1,然后将其输出的 6 3×148×1 维的特征重塑为 6 3×148 维的特征输入到二维卷积中,再进行最大池化操作,池化大小为2×2。
1.2.2 BLSTM 循环神经网络(RNN)的自连接特性使其对序列数据上下文的依赖关系具有天然的描述能力[14],但传统的RNN 在训练时间跨度较长时会出现长期依赖问题,导致梯度消失。而LSTM 引入了细胞结构这一概念,对参数求偏导后的连乘操作改成连加的操作,通过遗忘门使梯度一直存在,克服了RNN 梯度消失的问题,在深层网络的情况下也可以记住之前的信息,因此可以处理和预测较长一段时间的有用信息[15]。
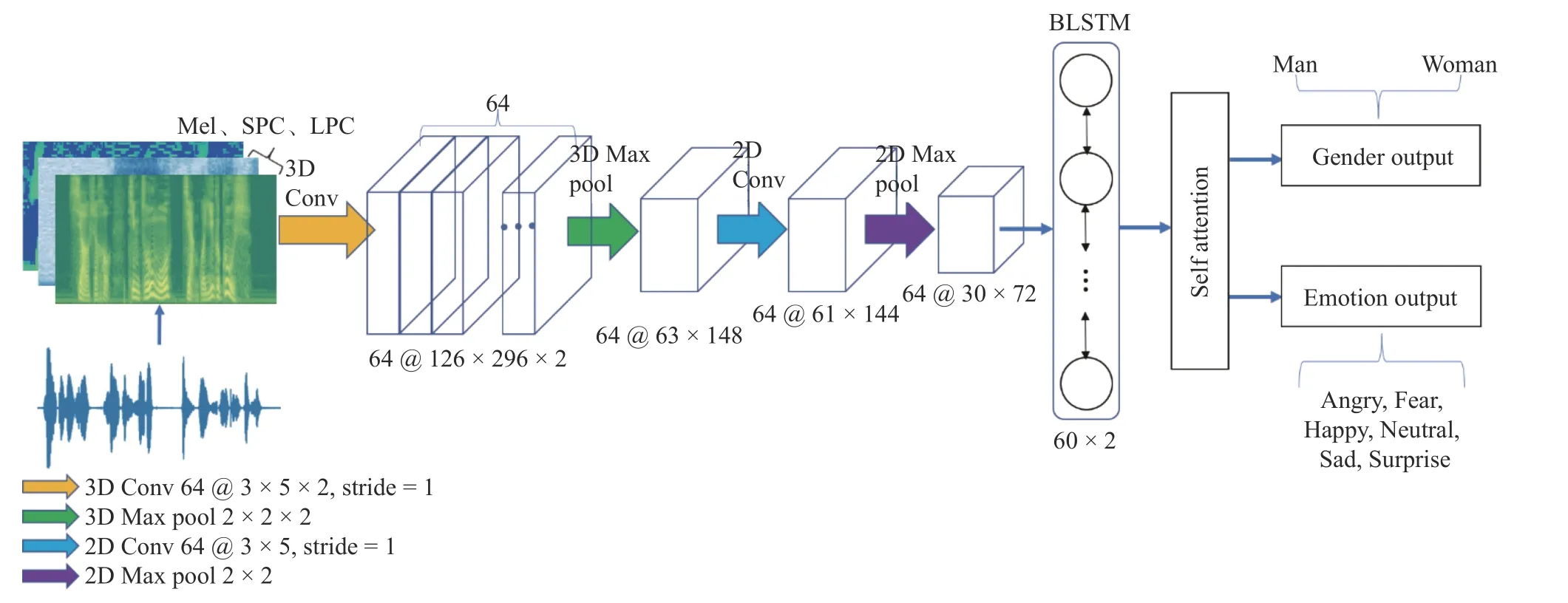
图3 语音情感识别系统流程图Fig. 3 Flowchart of speech emotion recognition system
在对语音情感识别问题的处理上,当前时刻的输出不仅和之前时刻的状态有关,还和未来的状态有关。BLSTM 由两个LSTM 上下叠加在一起组成,第1 层是从左边作为序列的起始输入,而第2 层是从右边作为序列的起始输入,输出由这两个LSTM 的状态共同决定。BLSTM 中前向LSTM 和后向LSTM在时刻t的表示如下:

在三维的CNN 操作后,将序列特征输入到双向的LSTM 中,每个方向包含60 个节点,可以得到一个120 维的序列。
1.2.3 注意力机制 注意力机制是根据某一种事物不同部分的重要程度来计算的一种算法,即为事物的关键部分分配更多的注意力,通过注意力概率分布的计算,对某一关键部分分配更大的权重[16]。本文对从情感语音中提取的特征加入注意力机制,使模型对BLSTM 网络输出的特征给予不同的关注度。
将BLSTM 层输出的隐藏层特征H={h1,h2,···,hL} 作为注意力层的输入,其中H∈RL×d,d为BLSTM隐藏层的大小。注意力机制的具体实现如下:
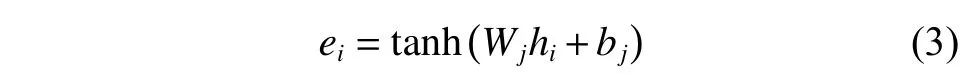

1.3 多任务学习
现实中的很多问题之间都存在着某些联系,为了寻找其中很多问题之间的关联信息,多任务学习的方法应运而生。多任务学习是迁移学习算法的一种,本质上是利用隐含在多个相关任务中的特定信息来提高泛化能力[17]。多任务学习通过结合共享层和属性依赖层从辅助任务中学习,从而提高语音情感识别的准确率。文献[18]已证明性别分类和情感分类具有音调和MFCC 等共同特征。本文通过多任务学习与情感分类任务共享有用信息,将性别分类作为辅助任务。考虑到男性和女性语音信号模式之间的差异,性别分类有助于识别其中的差异来提高语音情感识别的准确性。
考虑性别分类与情感分类之间的关系,将这两个任务融合在一个模型中完成,并行学习,结果相互影响。两个任务共享输入层和隐层的全部参数,同时通过两个输出层分别生成情感和性别分类准确率,并通过以下目标函数对模型进行优化:
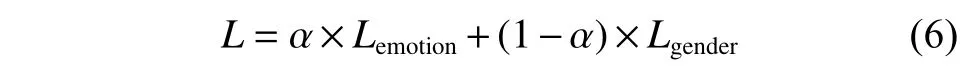
其中:Lemotion和Lgender分别是情感分类和性别分类的损失,直接将这两个任务的损失相加,通过对两个任务的损失配置不同的权重参数来调整每个任务的重要程度; α 为情感识别任务的权重。最后通过最小化目标函数来达到优化模型的目的。
2 实验及结果分析
2.1 实验环境
情感语音数据库的质量直接关系到语音情感识别的准确率。本文选用中国科学院自动化研究所录制的CASIA 汉语情感语料库进行实验。该语料库是由4 名专业人员(两男两女)在纯净录音环境下(信噪比约为35 dB)录制而成,涵盖了424 个汉语常用字音节,包括6 种情感,分别为生气(Anger)、害怕(Fear)、开心(Happy)、中性(Neutral)、悲伤(Sad)、惊讶(Surprise)。每个说话人每种情感有300 条相同文本的语句,共7 200 条语句[19]。
实验的硬件环境为Intel Core i7-7700K 的CPU和NVIDIA GeForce GTX 1 080 8G 的显卡,开发语言为Python,深度学习框架为PyTorch。
2.2 参数设置
本实验优化器采用Adam,学习率设置为0.001,batchsize 设置为100,epoch 设置为100,训练集和测试集的比例为5∶1。
在特征提取阶段,使用librosa[20]工具包对Mel谱图、LPC 参数进行提取,梅尔滤波器的个数设置为128,LPC 阶数选取20 阶,使用自适应加权谱内插STRAIGHT 模型对SPC 进行提取。将从语音信号中提取的 1 28×300×3 的多谱特征融合组图作为模型的输入。
将卷积层得到的 6 4×30×72 维的输出沿时间维度平铺并转置得到LSTM 网络的输入,维度为72×1 920,通过两层隐藏层节点数为60 的双向LSTM网络,然后通过自注意力头数为8 的注意力层和全连接层,最后得到情感和性别分类的准确率。
2.3 性能评估
为了验证本文模型的有效性,采用准确率(Accuracy)、召回率(Recall)、精确率(Precision)和F1值作为评价指标,对不同模型的实验效果进行评估。
2.3.1 数据准备 由于CASIA 汉语情感语料库是在纯净录音环境下进行录制的,所以模型在有噪音的环境下的判断结果并不准确。进行适当的数据增强,增加训练的数据量和噪声数据,提高模型的泛化能力和鲁棒性。使用audiomentations 工具包对语音信号进行增强,有以下4 种方式:
(1)AddGaussianNoise:随机添加高斯噪声。
(2)TimeStretch:对时间维度调整,拉伸音频信号而不改变音调。
(3)PitchShift:在不改变速度的情况下对音调进行调整。
(4)Shift:在时间轴的滚动,时移变换。
在数据增强阶段,具体的参数设置如表1 所示。其中times 为倍数;semitones 为半音程。

表1 数据增强方法参数设置Table 1 Data augmentation method parameter setting
在相同条件下,使用本文模型通过不同的方式对语音进行数据增强,比较情感识别准确率的大小。共进行5 组对比实验,其中实验1 使用原始数据集在本文模型中进行训练,实验2~实验5 分别采用AddGaussianNoise、 TimeStretch、 PitchShift、 Shift 对语音信号进行数据增强。实验结果如表2 所示。
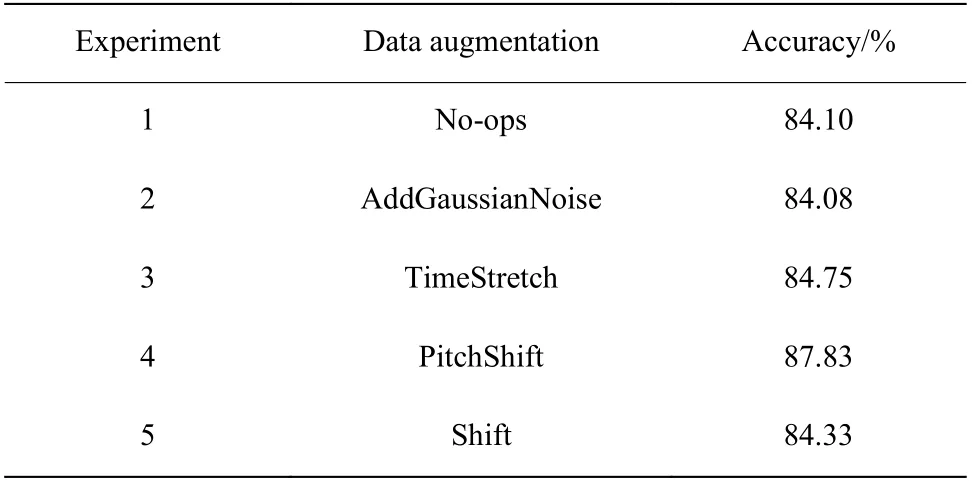
表2 数据增强对语音情感识别准确率的影响Table 2 Influence of the data augmentation on speech emotion recognition accuracy
由表2 可知,实验1 采用不进行数据增强的方式训练模型,识别准确率为84.10%;实验2 使用添加高斯噪声的方法与不进行数据增强的情感识别准确率相差不大,这是因为训练集与测试集同时添加噪声,只是提高了模型的泛化能力;实验3~实验5 所使用的数据增强的方法使得情感识别准确率有所提高,这是因为音频变速、音频变调和时间偏移的方法保持了语谱图中时域与频域的对应关系并且丰富了样本的多样性。
2.3.2 语音声纹图谱特征参数选择 在相同条件下,使用本文模型,通过输入不同的特征组合比较情感识别准确率的大小。将Mel 谱图、LPC 声纹图和SPC 声纹图3 种特征中的每一种特征及两两组合的特征输入到模型中,对比不同特征及组合特征对模型分类准确率产生的影响。其准确率、召回率、精确率和F1 值如表3 所示。
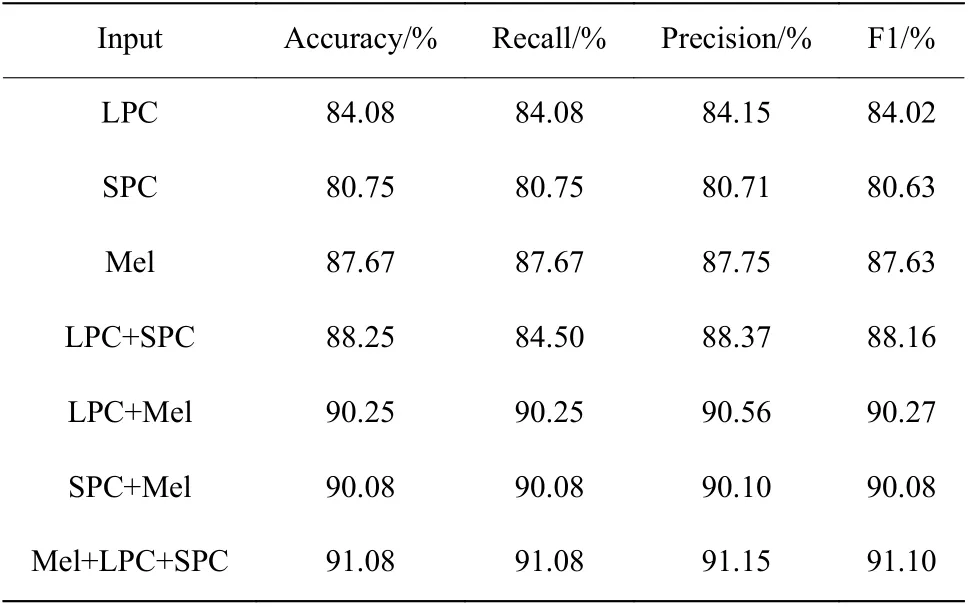
表3 输入不同声纹图的对比结果Table 3 Comparison results of different voiceprints
由表3 可知,输入3 种特征的组合能够更优秀地提取出语音信号中的情感信息,提高了算法的有效性。
2.3.3 评估方法 本文中多任务学习的两个任务分别为情感分类和性别分类,其目标函数如式(8)所示。通过尝试设置不同的权重值,可以得到不同的准确率,其结果如表4 所示。
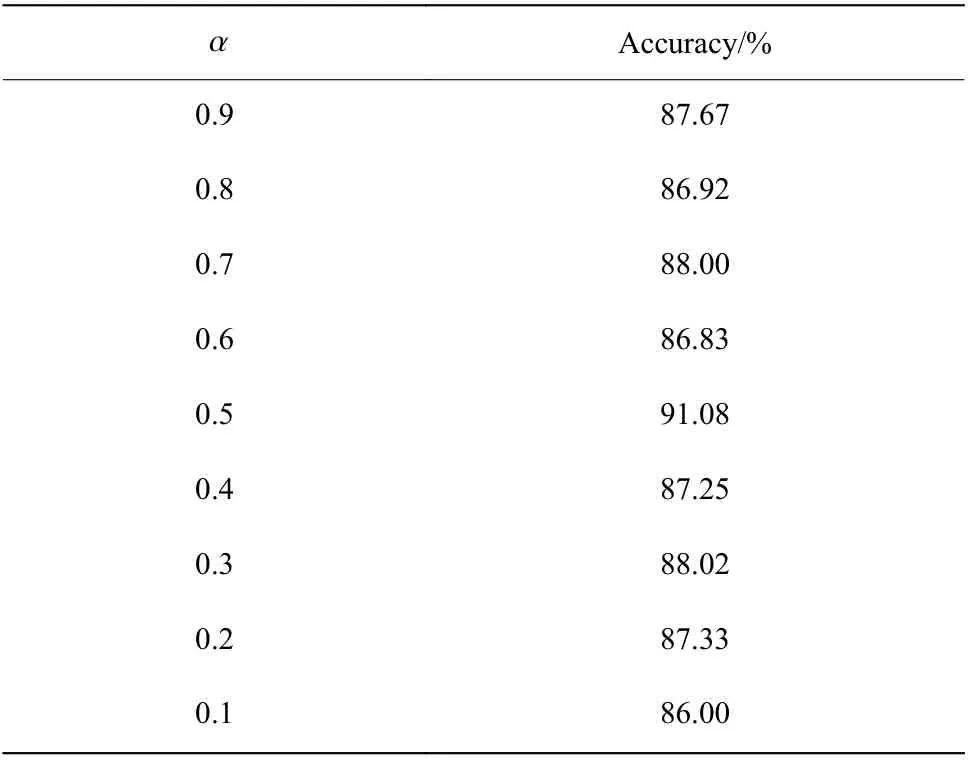
表4 不同α 值的情感分类准确率Table 4 Speech emotion recognition accuracy of different α values
由于本文的主要任务是对语音情感进行识别,因此对性别分类的准确率就不做赘述。表4 结果表明,当 α 设置过大时,性别分类对情感分类结果未起到辅助作用,情感分类准确率不是很高;当 α 设置过小时,模型更偏重于性别分类,因此语音情感识别准确率也不高;当 α 设置为0.5 时情感分类的准确性最高,这时语音情感分类和性别分类任务的权重比为1∶1。
2.3.4 实验结果分析 将文献[8]、文献[21]、文献[22]、文献[23]模型在CASIA 汉语情感语料库上的准确率进行对比,对比结果如表5 所示。
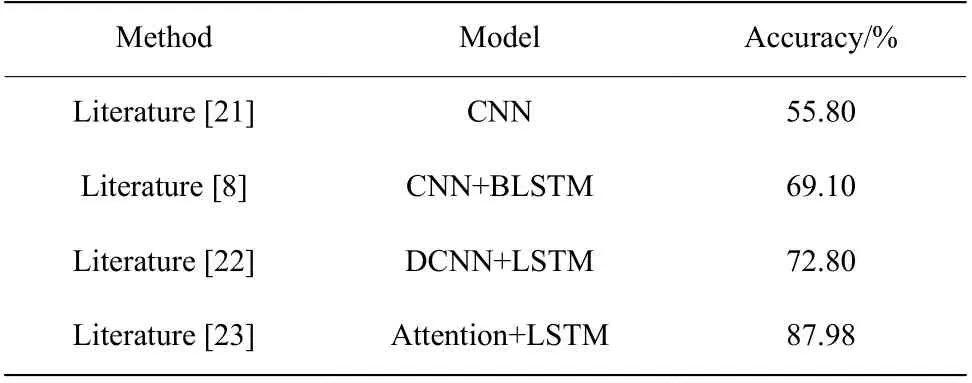
表5 在CASIA 汉语情感语料库上不同模型方法的准确率对比Table 5 Accuracy comparison of different models in CASIA Chinese sentiment corpus
本文的基线模型采用文献[8]提出的CNNBLSTM 模型,该模型是目前主流的语音情感模型。在该模型的基础上,对卷积层层数和卷积核的大小进行调整,并添加不同的方法,设计出5 种不同的模型:
(1)改进CNN-BLSTM 模型。将CNN-BLSTM模型进行改进,CNN 的层数设置为两层,卷积核的大小设置为 3 ×5 ,BLSTM 隐藏层节点数设置为60,并结合自注意力机制,对每帧情感特征给予不同的关注程度。
(2)3D CNN-BLSTM 模型。在CNN-BLSTM 模型的基础上,使用Mel 谱图、LPC 声纹图和SPC 声纹图特征,组成3 个通道的多谱特征融合组图代替原输入,并进行一次三维的卷积运算。
(3)CNN-BLSTM+multi-tasking 模型。在CNNBLSTM 模型的基础上,加入多任务学习,将情感分类和性别分类相结合。将说话人的情感识别作为主任务,说话人性别分类作为辅助任务,两个任务同时进行训练,通过共享网络参数学习共享特征。
(4)CNN-BLSTM+augmentaion 模型。在CNNBLSTM 模型的基础上,进行适当的数据增强,增加语音数据的多样性。
(5)3D CNN-BLSTM+ multi-tasking+ augmentaion模型。在CNN-BLSTM 模型的基础上,将模型(2)、(3)、(4)中的方法相结合,即为本文提出的基于注意力机制的多任务3D CNN-BLSTM 语音情感识别模型。
采用5 种模型进行实验的准确率、召回率、精确率和F1 值如表6 所示。5 种模型的混淆矩阵如图4所示,其中右侧数据条表示识别概率的大小,颜色越深识别概率越大。

图4 不同模型的混淆矩阵比较Fig. 4 Confusion matrix comparison of different models

表6 5 种模型的对比结果Table 6 Comparison of five models
由图4(e)的混淆矩阵可知,本文模型对各个情感的识别率都较高,其中识别率最高的是中性语音,达到95%,最低的是悲伤语音,为87%。由表6 中的数据可以看出,相比于CNN-BLSTM 模型,这5 种模型的实验结果都要优于文献[8]中的模型。3D CNNBLSTM 模型因为能够学习到Mel 谱图、LPC 特征和SPC 特征的3 个通道对应位置之间的关系,准确率提高了1.00%。CNN-BLSTM+multi-tasking 模型考虑了男性和女性语音信号模式之间的差异,性别分类有助于识别到其中的不同来提高语音情感识别的准确性,准确率提升了2.67%。CNN-BLSTM+augmentation模型考虑了本实验数据库是在纯净录音环境下进行录制的,所以模型在有噪音的环境下的判断结果并不准确。进行适当的数据增强,增加数据的多样性,提高模型的泛化能力和鲁棒性,准确率提升了5.42%。最后由于上述实验在语音情感识别上的准确率都较基线模型有一定的提高,因此结合了以上3 种方法,使用3D CNN-BLSTM+ multi-tasking+ augmentation 方法,得到的准确率为91.08%,比基线模型提升了8.58%,召回率、精确率和F1 值也得到了很大的提升。由此可见,本文提出的基于注意力机制的多任务3D CNN-BLSTM 情感识别方法具有更好的泛化能力。
3 结 论
本文提出了一种基于注意力机制的多任务3D CNN-BLSTM 情感语音识别方法,沿通道方向将Mel 谱图、LPC 特征和SPC 特征堆叠,得到多谱特征融合组图作为CNN 的输入,提取更深的情感语音特征。连接双向LSTM 网络,充分提取了语音信号的上下文信息,将BLSTM 层的输出作为自注意力层的输入,计算权重后结合性别分类的多任务学习机制,两个输出层分别生成情感和性别分类准确率。实验结果表明,在CASIA 汉语情感语料库下,本文模型相比同类其他方法在语音情感识别上的效果更好,能够有效地提升情感语音识别的准确率。
