基于大数据建模的玉米淀粉糖工艺参数预测系统开发
2022-08-08李义刘颖慰都健赵优赵国兴佟毅
*李义 刘颖慰 都健 赵优 赵国兴 佟毅*
(1.中粮生物科技股份有限公司 安徽 233000 2.中粮营养健康研究院有限公司 北京 102200 3.大连理工大学化工学院 辽宁 116024)
传统制造业正面临着数字化挑战。在玉米深加工制备淀粉糖工艺研究中,过滤工段的压差是考察淀粉糖化液质量的重要指标,位于过滤工段上游的单元操作都会影响淀粉糖化液生产的质量。然而由于实际工况下很多过程参数无法实时获取,且各类参数间存在强烈的非线性关系,因此传统的机理模型或多元线性回归模型无法准确关联各个参数间的相互作用关系做出准确预测。随着测量技术和DCS管理系统的广泛普及,工业中积累了大量数据,而物联网、互联网以及云计算等技术的发展为大数据的开发提供了可靠的保障[1-2]。
大数据技术在工业生产中的应用也得到越来越多的关注,大数据的应用场景根据开发程度大致可分三个阶段:一是数据库的建立,包括历史数据的采集存储,实时数据的记录监测;二是大数据分析模型的建立,按照输入输出的形式,建立关联规则分析模型、无监督的分类分析模型或有监督的回归预测模型;三是基于建立的分析模型及其组合,应用于实际工业场景的分析任务中,工艺参数优化、产量预测、故障检测和诊断等[3]。其中大数据分析模型直接关系到大数据应用的实际效果,数据分析建模方法众多,针对不同的工业过程及分析任务,适用的方法常常不止一种。
在工艺优化方面,Li等[4]针对玻璃镀膜工艺建模问题,采用决策树模型,在现有的工艺参数下预测产品质量;Liu等[5]用关联规则分析了钢铁制造工艺过程中化学成分(如碳、锰、磷、硫等)的含量、出钢温度和轧制速度对产品机械性能的影响。肖溱鸽[6]对工艺参数与能耗间的影响规律进行分析,基于车间历史数据开展了多元统计技术和聚类分析;薛百里等[7]采用神经网络预测生产工时,分析了工艺过程中的影响因素及其影响程度大小;骆自超等[8]使用改进的谱聚类算法,研究缸盖铸造模具点偏差对燃烧室容积的影响大小。在故障检测方面,罗洪波等[9]用神经网络对数据仓库的数据进行建模,分析汽车售后的潜在故障。在化工过程当中大数据技术同样有着广泛的应用,尤其在过程控制方面。陈燕斌等[10]为镇海炼化乙烯装置的裂解、分离和加氢单元提供了智能优化控制方案,对装置历史的原料属性数据进行智能聚类,利用模拟软件得到不同工况下的操作数据,并利用神经网络建立代理模型实现优化,并将模型输出作为控制方案。吴亚平等[11]对精馏塔建立根据参数与控制目标的相关系数进行筛选,选取强相关特征作为模型输入构建模型,根据优化对象建立优化目标,根据精馏塔控制要求设置优化器约束条件,设计梯度优化策略,实现了对精馏塔多输入多输出变量的实时调控。此外,由于基于纯数据构建的模型常常面临鲁棒性和外延性不强的缺点,越来越多的研究者开始建立机理与数据融合的模型,Jiang等[12]针对基因表达模型,通过训练单隐藏层神经网络拟合描述新生RNA分子消除过程的有效时间倾向方程,实现了对时间延迟化学主反应的近似,解决了非马尔科夫模型求解困难的问题,同时该模型具有良好的外延性,能够有效地研究更为复杂的基因调控非马尔科夫模型。
以上研究大多将大数据技术应用于单个生产车间或单元,或集中在某一类具体反应过程中,对于长流程的复杂工艺系统进行整体性数据分析相关工作还比较少,上述工作在面对输入参数较多的场景时,可能会出现模型训练时间过长、难以筛选出对于目标参数影响最强的变量等问题。同时在化工领域,大数据技术的应用对象多为自动化程度较高的石油化工系统,对于食品或生物工业这样存在较多间歇过程,且部分车间自动化程度较低的工业领域,仍有较大的探索空间。基于此,本文对大数据技术在食品工业中的应用进行研究,具体对象为淀粉和淀粉糖厂的生产工艺流程。由于该工艺过程线路较长,数据维度高,种类复杂,相互非线性强,且涉及生化反应的部分实验机理不十分明确,流程上下游数据之间难以建立机理关系式,故考虑采用纯数据的方法建模。根据工厂的实际操作情况,首先,采集企业长期积累的原料、产品分析检测数据和DCS系统记录的装置运行状态监测数据,建立数据库,并采用合适的数据挖掘算法快速准确地统计、分析、归纳出高质量数据;其次,基于数据预处理、降维分析、分类与聚类分析、相关性分析和预测分析等一系列机器学习理论构建系统输入与评价指标(过滤器压差)间的映射关系,搭建模拟系统,从而达到筛选出影响系统关键操作参数和系统准确预测的目的;进而将其应用于生产预测,指导生产管理。
2.模型构建
本文对玉米淀粉糖生产工艺中关键参数预测模型构建流程分为4步,如图1所示。第一步,从工厂数据库中提取需要进行大数据分析的原始数据,即围绕待分析工艺流程的所有相关数据。第二步,将提取出的原始数据通过数据清洗技术进行数据预处理。第三步,经数据预处理后,“干净规范”的数据通过神经网络构建基于历史数据的稳态模型,并进行多次训练和测试以满足预测精度。第四步,通过神经网络的权值分析法(Olden法)对训练的模型进行结果分析,最终形成新的知识积累。
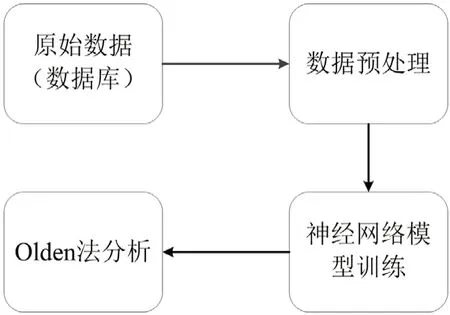
图1 模型构建流程
本文从工厂数据库中提取的原始数据信息包含工艺流程中582个检测位点,时间从2019年4月19日到7月29日共13761组样本点。其中主要位点为:温度、压力、流量、电流、液位、pH值和现场采集数据(加酶量、硅藻土用量、硫酸镁用量等)。
(1)数据预处理
从工厂采集的原始数据,不可避免的会因为现场情况或测量设备自身的问题存在噪声或异常值等,这些将导致原始数据在一定程度上偏离真实值。因而有必要对数据进行合理的预处理,从而有效提高数据分析的效率和分析结果的可靠性。针对从某厂采集的数据特性,本文针对所建立的数据库做出如下预处理工作。
①缺失值处理
由于现场检测故障、工厂停车检修等一系列问题的存在,导致所采集数据出现部分位点在某些时段缺失的问题。针对这种情况本文采取两种处理策略:在连续时段内缺失值较少的情景,依据前后时间段的数据取平均值进行补充;在连续时段内存在大量缺失值时,删除对应时段所有数据。
②特征选择
在工厂运作过程中,某些位点在全时段基本保持在稳定的数据区间,这样的位点在建模过程中贡献较小。因此,采用方差选择法,对数据进行归一化后,计算所有位点数据的方差大小,优先消除方差为0或方差较小的特征,其中判断方差大小采用设定阈值的方法,阈值设定标准为:根据阈值筛选后的特征重新训练数学模型,若模型训练效果没有明显变化,尽可能使阈值增大,阈值越大越能删除掉更多特征,本文经多次尝试后阈值定为0.02。这是因为在构建输入与输出关系模型时,某些基本保持不变或数据波动较小的位点数据起到的作用较小,因此在建模过程中不考虑这些位点作为输入变量,从而降低输入数据特征数。
③异常值处理
异常值的存在将极大影响模型的训练效率和精度,本文采用拉依达准则法和肖维勒法进行异常值的识别和处理。
A.拉依达准则法
用贝赛尔公式计算数据的标准偏差s,当某个可疑值xa与n个结果的平均值之差的绝对值≥3s时,判定xa为异常值[13],其中,n为数据的个数。
B.肖维勒法
该法通过规定一个置信水平,确定一个置信限度,凡是超过该限度的误差,就认为是异常值,从而予以剔除。如果某测量值与平均值之差的绝对值大于标准偏差与肖维勒系数之积,则该测量值被剔除[14],如式(1)、式(2)所示。

式中,ωn为肖维勒系数;n为数据点个数。
(2)神经网络模型
在进行预处理后,得到“干净”的数据,可用于进行神经网络模型的训练。神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。因为其构建输入和输出复杂关系的优良特性而得到广泛的应用[15]。本文采用BP神经网络模型构建位点数据和选择评价指标之间的映射关系,用于进一步的分析和研究。
如图2所示为一个BP神经网络的结构图。BP神经网络被称为“误差逆传播算法”。随着误差逆传播训练的不断进行,网络对输入模式响应的正确率也将不断提高[16]。

图2 神经网络结构示意图
神经网络中隐层神经元的数目与实际问题的复杂程度、输入和输出层的神经元数以及对期望误差的设定有着直接的联系。隐层神经元的个数常采用经验公式(3)估算。

式中,l为隐含层神经元个数;n为输出层神经元个数;m为输入层神经元个数;a为1~10之间的调节常数。
神经网络模型的训练效果采用复相关系数R来衡量,复相关系数R的计算公式如式(4)所示:

(3)Olden方法
Olden方法是一种用于评估各个输入变量对输出变量影响程度的方法,也被称为连接权值法(Connection Weight Approach)。Olden等人通过对比分析结合神经网络对输入变量及输出变量贡献程度的九种方法进行了评估,证明了Olden方法在准确性和精度方面均优于其他方法[17]。因此本文基于Olden方法结合神经网络评估操作参数对过滤器压差的影响程度。对于一个有两个隐含层j1、j2,且隐含层节点数分别为L1、L2的神经网络结构来说,输入变量对于输出变量影响程度的计算方法如式(5)所示。

式中,Oip为输入变量xi对yp的敏感性指标值,Oip的绝对值越大,该变量对应的控制位点的影响程度越大;wij为输入变量xi对中间隐含层j1的权值;v'j1j2为中间隐含层j1对中间隐含层j2的权值;v''j2p为中间隐含层j2对输出层yp的权值。
3.淀粉糖车间过滤器压差预测建模
某玉米淀粉和淀粉糖厂工艺生产路线如图3所示,玉米经过上料、清洗、浸渍、胚芽分离、精磨、纤维洗涤筛分、麸质分离等复杂的操作单元后经淀粉精制、液糖化、异构化等过程后进入过滤单元,过滤单元包含4个板框式过滤器,每个过滤器依据生产情况交替进行工作。该工艺流程线路长,且变量间的非线性关系较强,位于上游的操作单元都可能会对下游单元中的参数产生影响,因此仅凭工程经验和传统的机理模型很难将影响过滤压差的关键位点全面有效地筛选出来。因此本文基于第1节构建的方法论框架进行过滤工段压差的预测,根据历史数据建立数据驱动的稳态模型,再根据现有数据实现过滤压差的预测,应用该预测模型可进一步进行压差的优化及控制。但是由于神经网络训练过程随机性大,每次训练过程中位点的权值变化大,且输入维度高导致了训练时间长,为了提高模型训练效率和相同位点出现频次,提出了两步神经网络预测法、聚类分析结合神经网络预测法和Lasso回归分析结合神经网络预测法。从582个输入变量中筛选出对过滤压差影响较为显著关键控制位点。

图3 玉米淀粉与淀粉糖生产工艺流程图
(1)两步神经网络预测(T-ANN)法
①一步预测(O-ANN)法
本文基于MATLAB建立神经网络,首先直接以清洗后数据作为输入,直接进行神经网络训练,通过对神经网络模型的拟合效果进行敏感性分析确定各项超参数,最终确定设置层数为两层、参考公式(3)两层神经元个数分别设置为30个和10个,以tansig作为激活函数,利用MATLAB软件进行模型训练,结果截图如图4所示,其中训练集、测试集和验证集的复相关系数R均大于0.99。由于该法输入维度过多,容易导致过拟合且每次运行获得的权值排名靠前的位号随机性大,难以确定关键控制位点。
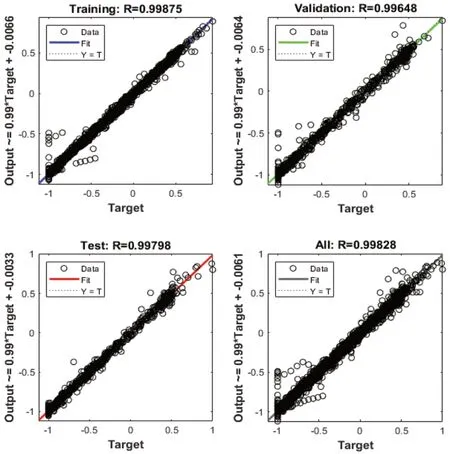
图4 以1#板框过滤器压差为例的模型预测效果图
②两步预测(T-ANN)法
本文在O-ANN法的基础上提出两步神经网络预测(T-ANN)法,解决O-ANN法单次回归随机性大、模型输入变量过多而易受无关变量影响的弊端,计算流程如图5所示。原始数据经过预处理和一步预测之后,通过Olden法获得对过滤器压差影响较大的100个位点。以这100个位点作为输入重新构建神经网络,并采集权值较大的前20个位点作为关键控制位点。

图5 T-ANN法流程图
以1#过滤器压差为例,T-ANN法中第二次神经网络建模训练结果的MATLAB截图如图6所示。
图6中可知,两步神经网络方法筛选出来的100个位点经过再次训练,训练集、测试集和验证集的复相关系数R均大于0.99,表明拟合情况较好,该方法能够实现输入数据降维的功能,但其最大的问题在于训练过程中仍然需要用到全部的输入位点,即第一次筛选时的训练时间仍然较长,限制了模型的总体训练速度。且该方法在输入参数降维时没有摆脱神经网络模型在赋予神经元权值时的随机性问题,因此还需要建立从数据本身出发筛选特征位点的方法。本文中考虑采用聚类分析和LASSO回归的方法进一步筛选输入位点,并对其进行比较。

图6 T-ANN法中1#过滤器压差的模型预测效果图
(2)聚类分析结合神经网络预测(C-ANN)法
①聚类分析
聚类(Clustering)是一种寻找数据之间内在结构的技术,通常又被称为无监督学习,与监督学习不同的是,在簇中那些表示数据类别的分类或者分组信息是没有的。数据之间的相似性是通过定义一个距离或者相似性系数来判别的[18]。聚类分析种类较多,其中本文中采用K-平均(K-means)算法[19]。其相似性系数的计算如式(6)所示:

其中,x为簇内样本;u为簇的中心;E为相似度系数,其值越小,说明簇内样本距离越小,相似度越高。
②聚类分析结合权值分析预测模型的建立
以预处理后的位点为输入,分别以四个板框过滤器的压差为输出,利用神经网络建模训练,得出582个位点的训练权值。这些位点对应实际过程中记录的参数,由于部分参数之间的联系较为紧密,呈现一定的相关性,其对于输出参数的影响也较为类似。因此本文利用K-means算法对这些位点数据进行聚类分析,目的是将不同的输入变量分类,本文的分类方式将以某一位点在全部运行时间上的数据作为一个样本,聚类结果为在全部时间上的数据表现相似的位点集,分类方式根据数据间的平均相对距离进行分类。为确定类别的个数,本文采用拐点法,在不同k值(类别数量)计算簇内离差平方和(SSE),随着簇数量增加,簇中样本量会越来越少,导致目标数值SSE越来越小,此时可视化k-SSE图像,关注斜率的变化,当斜率开始趋于0时,则认为此时达到的点就是寻找的目标点,记录此时“拐点”所对应的k值。样本聚类误差平方和的计算公式如式(7)所示。

其中,k是聚类数量;p是样本;Ch是第h个聚类的样本集;mh是第h个聚类的中心点。k越大,SSE越小,说明样本聚合程度越高。k-SSE图像如图7所示:

图7 聚类分析样本聚类误差平方和SSE随k值变化趋势图
从图中可以看出,在k=10之后,样本聚类误差平方和SSE的值基本不再下降,斜率趋近为0,故将k=10记为“拐点”,将输入数据的特征分为10类。依据Olden连接权值法计算出的权值,在每一类中,选择该类中权值绝对值较大的位点作为后续模型训练的输入位点,对模型进行训练。由于分类后不同类包含的参数个数不同,从中选出的输入位点数也不相同。
10类中数目最多的类别包含517个特征,数目最少的类别包含7个特征参数,不同类别之间包含的特征参数差距较大,为保证每一类均能过取到且尽量涵盖足够数量的特征参数,不同类别中选出的参数数量依据类别的数量比例进行划分。类别为“1、2、3、4、6、8、9”的类分别包含7、9、10、12、17、25、30个参数,从中选择1个参数作为输入,即权值绝对值最大的特征;类别“5”“0”中分别包含48、62个特征,考虑类别中参数个数每增加30个,就从中多选择1个参数,故分别选出2、3个参数作为输入。类别为“7”的类有342个参数,考虑到该类占据了半数以上的参数数量,本文尽可能对其取到较多的参数,故选择其中权值最高的20个参数作为特征变量输入。共计选出32个参数作为模型训练的输入,以1#板框压差过滤器为例,以其压差作为输出变量构建模型,模型训练结果的MATLAB截图如图8所示。图中训练集、测试集和验证集的复相关系数R在0.99以上,说明这32个输入参数能够很好地预测过滤器压差。

图8 C-ANN法中1#过滤器压差的模型预测效果图
(3)Lasso回归分析结合神经网络预测(L-ANN)法
①Lasso回归分析
Lasso(Least absolute shrinkage and selection operator)是一种处理具有复共线性数据的有偏估计。引入该模型的目的是有效的对存在多重共线性的特征进行筛选,减少数据维度,保留能够准确代表输入数据特征的特征向量[20]。其定义式如下:

其中,λ为非负正则参数,控制着模型的复杂程度。λ越大,对特征较多的线性模型惩罚力度就越大,从而获取一个特征较少的模型,本模型选取λ=0.01,其中,β为L1正则范数惩罚项。
②Lasso回归分析结合权值分析预测模型建立
分别以1#、2#、3#和4#作为目标经过Lasso回归处理后,对应的输入特征变量分别减少到41、70、64和54个,分别以这些参数作为输入变量,训练神经网络,以1#过滤器为例,其训练结果的MATLAB结果截图如图9所示。其训练集、测试集和验证集的复相关系数R均在0.99以上。

图9 L-ANN法中1#过滤器压差的模型预测效果图
4.结果与分析
(1)关键位点机理分析
使用O-ANN法、T-ANN法、C-ANN法和L-ANN法分别对1#-4#板框过滤器的压差进行建模,利用Olden连接权值法计算得到各个输入参数分别对于1#-4#板框过滤器压差的权值结果。并分别根据权值依据绝对值大小降序排列,分别选择权值靠前的20个位点进行讨论。由于神经网络的训练具有随机性,对于每种筛选方法,其对应的四个板框过滤器分别选出的20个位点不完全相同。因此,本文考虑将每种方法对应1#-4#板框过滤器选出的4个位点集进行合并,这样每种方法筛选出的位点总数为80个,且很可能有重复出现的位点,可将这80个位点组成的位点集中出现次数较多的位点认为是影响过滤器压差的关键控制位点。这三种方法筛选的位点集里,出现次数大于两次的位点汇总在表1中,其中可凭借现有生产经验进行分析解释的位点在表1中以加粗标记,并用虚线框框出。从表中可以看出,T-ANN法找到的关键位点数量最多,同时和O-ANN法相比,L-ANN法和C-ANN法找到的位点出现的频次更多,说明其筛选出的关键位点对于过滤器压差的影响程度更大。

表1 不同方法中位号出现次数大于两次汇总表
对以上四种方法筛选出的位点分别结合其物理含义进行机理分析,其中部分位点较难用机理进行解释,原因是该模型基于纯数学理论筛选所找出的部分数据位点,其与输出位点的作用关系非常复杂,难以凭借现有的生产经验进行关联,后续可进行相应的实验验证进行确认。其余位点的物理意义及分析如下:
①与玉米浸泡效果相关的位点:如LEVEL1LIA_1401_1_4、LEVEL2LIA_1401_3_2(玉米浸泡罐液位)。分析:玉米浸泡过程中吸水体积膨胀,膨胀后体积约为原体积的154%~181%,引起浸泡罐液位变化,即液位反映浸泡效果,进而影响玉米淀粉质量,所以反映了该位点对过滤工段压差的影响。
②与研磨过程相关的位点:CURRENT1CIA_1520_1(三道磨电流)。分析:三道磨负责将淀粉纤维蛋白精磨,精磨效果将影响后续分离过程,尤其是过滤工段的压差。
③与淀粉乳流量相关的位点:FIQ1103(淀粉乳出流量)、新鲜水(t)累积、脱盐水(t)累积。分析:淀粉工段的淀粉乳产品在进入果糖工段时与部分新鲜水和脱盐水混合以调整其密度和黏度。其总流量的增加将造成过滤工段的负荷增加,因而对于过滤工段压差有较大影响。
④与蒸汽喷射器相关的位点:SD1109(喷射器B设定)、蒸汽累积量、TI1110_1(二喷维持管进温度)。分析:喷射液化法使用压力为390~588kPa的蒸汽,喷射产生的湍流使淀粉受热快而均匀,黏度下降快,使得液化更加均匀,提高系统过滤性,对于过滤工段压差有较大影响。
⑤与液化、糖化效果相关的位点:FIC1125(液化酶进流量)、TIC1114(pH值调节罐温度)、TI1113_5(液化柱温度测量)、FIQ2106(糖化酶进流量累计)、SIC2108.MV(糖化用酸泵频控制)、TI2103_4_2(糖化罐温度测量)。分析:液糖化的酶量、温度、pH值都将影响液糖化的效果。液糖化将大分子淀粉链打断,有利于降低过滤工段压差。
(2)模型性能比较分析
通过对以上预测模型结果的比较,与O-ANN法相比,TANN法、C-ANN法以及L-ANN法的拟合效果没有下降,但由于数据维度得到极大降低,在表1中可以发现,T-ANN法、CANN法以及L-ANN法训练同一位点出现在不同压差过滤器对应的位点集中的频次得到了增加,模型训练效率得到了提高,说明使用这三种方法能更有效地找到对于压差具有影响的关键位点。为分析本文提出的三种方法和传统方法(O-ANN法)在进行大数据建模时的预测精度和敏感性方面的性能,其中对数据的敏感度指标计算方式为:建立多个输入数据集,分别训练模型之后记录这些输入数据集对应的模型训练效果,效果好坏以复相关系数R的数值表示,计算这些数值随输入集改变的变化情况,以方差衡量其稳定性,也可以称作对输入数据集的敏感性。本文将所有工艺数据随机等分5组(G1-G5),然后利用这四种方法分别对5组数据进行建模、训练和预测。图10为四种方法的分组测试结果。进一步计算每一种方法不同数据集的复相关系数R之间的方差分别为:2.204×10-4、2.150×10-4、2.10×10-5、7.763×10-4。可以看到几种方法计算出的R之间的方差都比较小,但相对而言L-ANN法的方差最小,证明其对输入数据集的敏感性最低、模型训练的稳定性最高。

图10 四种方法的分组测试结果
表2汇总了本文提出的三种方法和原始方法的特征及优缺点。本文提出的三种预测模型在计算效率、降维效果、预测精度和对关键位点的筛选能力上各有优劣,但L-ANN法对数据集的敏感性最低,预测精度较高,且能筛选出更多的具有机理可解释性的关键位点。因此本文推荐使用L-ANN法进行工业大数据挖掘与分析。

表2 四种方法特征比较
(3)超参数设置对于模型性能的影响
以L-ANN法为例,对不同算法的隐含层数分析。由图11(a)可知,当隐含层为两层时,拟合效果已经达到相对较优的值,而再增加隐含层数时,R值几乎不变,因此确定最终的隐含层数为2层。神经网络隐含层节点数对于拟合效果的影响如图11(b)所示,当节点数增加到25时,拟合效果已经达到相对较优的值,再增加节点数时R值没有太大变化,考虑到节点数增加将导致模型训练时间上升,因此确定最终的隐含层节点数为25。
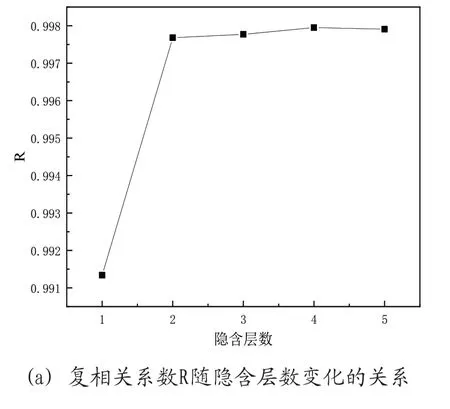

图11 隐含层数和节点数对拟合效果影响(以L-ANN法为例)
学习率是很重要的超参数,因为它以一种复杂的方式控制着模型的有效容量。如果学习率太高,损失函数将开始在某点来回震荡,不易收敛。如果学习率太小,模型收敛速度慢。通过对学习率的敏感性分析可知,学习率分别取值为0.1、0.01、0.001和0.0001时,模型均能收敛,不会发生较大震荡,因此为了提高模型收敛速率,取学习率的值为0.1即可。
5.结论
本文利用大数据技术对玉米深加工工艺进行建模研究。为实现数据降维,并减少因神经网络随机性导致的同样位点出现频次低的问题,分别使用了T-ANN法、C-ANN法及L-ANN法对玉米深加工工艺中过滤工段压差的预测模型,随后结合Olden权值连接法筛选出权值较大的20个控制位点。通过对结果进行分析可以得到如下结论:
(1)本文所提的三种神经网络建模方法均能够准确地关联玉米淀粉上游工段的工艺条件与过滤工段压差的关系,复相关系数R均在0.99以上,且能够有效减少输入数据维度,快速获取关键位点且保持模型拟合效果。
(2)通过对三种方法进行机理分析、敏感性分析以及超参数分析的比较,研究发现L-ANN法对数据集的敏感性最低,预测精度较高,且能筛选出更多的具有机理可解释性的关键位点。因此本文推荐使用L-ANN法进行工业大数据挖掘与分析。
(3)在工业大数据的神经网络建模过程中,超参数的设置对模型预测精度有一定影响,隐含层数过低、神经元节点数过低均会导致模型精度变差,但本例中隐含层数超过2之后模型预测精度基本不再提升,神经元节点数超过25之后模型预测精度基本不再提升,过多的隐含层和神经节点将导致模型训练速度变慢,对数字建模应用于工艺数据的实时预测不利。
