基于Retina-GAN的视网膜图像血管分割①
2022-08-04侯松辰张俊虎
侯松辰,张俊虎
(青岛科技大学 信息科学技术学院,青岛 266061)
眼科专业人士往往将手工分割后的视网膜眼底图像作为眼科疾病的诊断依据,从血管的病变情况观察到一些病症[1]. 然而血管的手工标注工作对于眼科医生来说费时费力,处理不及时还有可能耽误病人的病情,自动高效的血管分割不仅缓解相关专业人员的压力,也有助于患者早发现早治疗,因此实现智能的血管分割在疾病识别和预防方面有重要意义.
早期许多研究利用计算机视觉、有监督或无监督的机器学习算法来实现眼底图像的血管分割. 如高向军[2],王爱华[3]早期提出的形态学分割方法,Chaudhuri等人[4]的匹配滤波方法等无监督算法,以及Wang 等人[5]提出的基于卷积神经网络的方法等有监督算法. 伴随深度学习算法研究的深入,众多学者在提高血管分割性能方面的研究愈发深入,使用深度学习架构的研究获得了比现有方法更好的性能,比如,Fu 等人[6]提出的基于深度学习与条件随机场的分割方法,吴晨玥等人[7]对于卷积神经网络的改进,Rammy 等人[8]提出的基于块的条件生成对抗网络分割方法以及钟文煜等人[9]对改进的U-Net 方法等血管分割算法. 这些基于深度学习的算法与以往算法相比展现了极大优势,尤其是生成对抗网络,在对于血管分割的问题上,准确率等指标都可以看出明显提升.
当前分割仍存在问题: (1)眼底血管错综复杂导致分割结果中各类评价指标还有进步空间; (2)对于血管细微分支类别的准确率还有待优化. 为了尝试解决这个问题. 本文提出了将RU-Net 网络作为生成器部分的GAN 改进版模型,并添加了一种Attention 机制,应用在生成器部分,使分割区域更明确,提高分割的准确度和特异度; 判别器选择卷积神经网络. 在对数据集的预处理上,本文使用了自动色彩均衡ACE 算法[10],并与其他预处理方式的实验结果比对,对DRIVE 数据集通过翻转、旋转角度、均匀切割等操作将数据集扩充至3 840 张,实验显示,本文的模型展现了更好的性能.
1 基于深度学习的Retina-GAN 模型整体网络架构
本文将生成对抗网络(generative adversarial network,GAN)与RU-Net 结合并添加一种Attention 机制,构成Retina-GAN 视网膜血管分割模型,如图1 所示,Retina-GAN 由3 个部分组成:
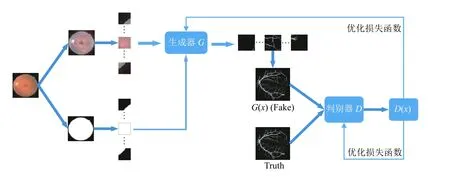
图1 Retina-GAN 模型整体架构
(1)图像预处理阶段,采用自动色彩均衡(ACE),加强图像对比度,对图像阈值分割得到掩膜图像,扩充数据集,每张图像分成16 个patch;
(2)生成器部分,该部分采用RU-Net 网络[11],添加Retina-Attention 机制,将模型关注区域锁定在有效视网膜区域,生成的patch 进行重组;
(3)判别器部分,采用卷积神经网络对生成的图像进行判别,继而优化损失函数.
1.1 生成对抗网络GAN
GAN 在被Goodfellow 等人[12]提出后迅速发展,并广泛应用于图像合成、样式转换、图像分类、语义分割等领域. 此外,GAN 在医学图像处理中也崭露头角,如解剖学图像精准采样、检测前列腺癌细胞病变等. 学者们基于GAN 模型又提出了多种扩展网络模型,如Conditional GANs[13]、Wasserstein GAN[14]、Pix2Pix[15]、DCGAN[16]等.
在本文的架构中,生成器(generator,G)担任着生成眼底血管分割图的角色,它的输入是任意一张眼底图像z,G通过z生成的视网膜血管图像,记为G(z). 判别器(discriminator,D)则担任着判别血管图片是否真实的角色,以专家手工标注的血管图像为标准. 判别器的输入是血管分割图像x,输出D(x)是图像x为专家标注真实图片的概率,输出越倾向0,图片就越虚假,输出越倾向1,图像越真实.
对生成器G和判别器D的训练过程就是令G生成的眼底图像G(z)越来越逼真,使D难以判断图像是否为真实的眼底图像. 在训练过程中,G和D逐渐趋向动态平衡. 这个过程最理想的状态就是在D和G不断优化的同时,G生成的眼底图像G(z)越来越真实,令D难以判定其真假性. 对G,D的训练过程如式(1)[12].

其中,x为真实眼底图像,符合pdata(x)分布,z是输入到G的噪声,符合pz(z)先验分布,如高斯分布,G生成的眼底图像用G(z)表示.D(x)是D判断x是否真实的概率,不难得出,D(G(z))就是G(z)是否真实的概率. 对于G而言,式(1)越小越好,对于D而言,式(1)越大越好.
2 视网膜眼底图像预处理
实验选择DRIVE 公开数据集,DRIVE 由40 张彩色视网膜图像组成以及对应的专家手工分割图像组成.
对图像的预处理选择了自动色彩均衡ACE,通过对ACE 处理过的图像水平、垂直翻转,旋转角度,平均分割等方式将DRIVE 数据集扩充至3820 张128×128的图像.
ACE 是由Gatta 等人[10]提出的,并由Rizzi 等人[17]以及Getreuer 等人[18]进一步优化. ACE 模仿人类视觉系统模型来对色彩校正和增强. 文献[17]依据Retinex理论提出了ACE,ACE 能够对自适应滤波进行局部的调整,使图像的对比度、亮度和色彩能够自适应局部或者是非线性特征的情况. 它需要两个阶段. 第一视觉编码阶段恢复场景区域的外观,第二显示映射阶段将过滤后的图像的值归一化. 如式(2)[10]、式(3)所示,一阶段从输入像素Ic(p)计算Rc(p),二阶段从Rc(p)计算增强输出图像Oc(p),在一阶段,输出图像R在色度和空间调整后被创建,创建后每个p都要依据图像的内容再次计算. 输出图像R中的每个像素分别为每个通道c计算.

其中,p和j为两个像素点,Ic(p)−Ic(j)表示2 个点的亮度差,d(p,j)是距离度量函数,r(·)为亮度表现函数,且为奇函数,式(2)的作用是调整局部图像的对比度.r(·)的作用是依照局部内容动态放缩范围,比如放大细微的差异,rmax表示r(·)的最大值,Rc(p)为中间结果.
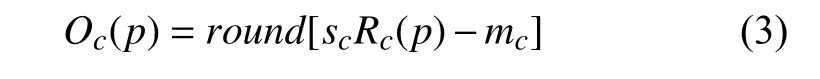
对于输出图像Oc(p),sc为线段[(mc,0),(Mc,255)]的斜率,mc=minpRc(p),Mc=maxpRc(p). 使用ACE 的增强结果如图2(b)所示.
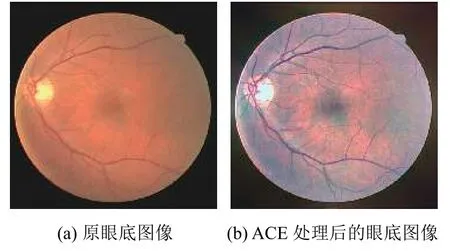
图2 使用ACE 的增强结果
3 基于Retina-Attention 机制优化的生成器
对于生成器部分,本文引用了RU-Net 结构,并添加了一种Attention 机制对RU-Net 进行优化,将其称为Retina-Attention 机制.
3.1 RU-Net
Alom 等人被RCNN,U-Net 以及深度残差模型所启发,提出了基于U-Net 的RCNN[19]模型RU-Net[11],这种方法结合了这3 种模型的优势,如图3. 与U-Net模型相比,所提出的模型有3 方面的差异. RU-Net 由卷积编码和解码单元两部分组成,在编码单元以及解码单元中,常规前卷积层被使用循环卷积层RCL 和带有残差单元的RCL 所取代. RCL 单元其本身能包含高效的特征积累方法,带有RCL 的单元对模型的深入建设大有裨益.
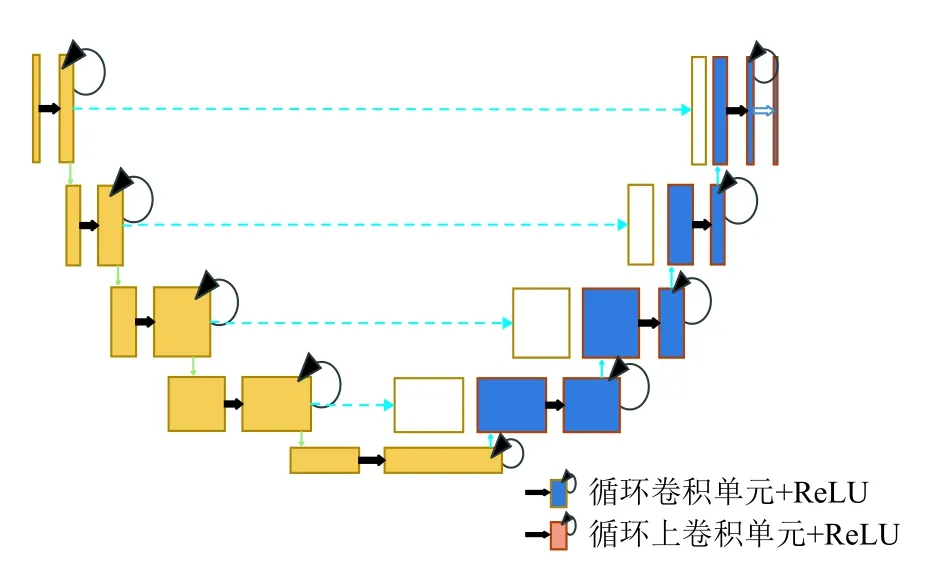
图3 RU-Net 体系结构[11]
其中,RCL 通过RCNN 的离散时间步长进行的.顾及残差RCNN (RRCNN)块的第l层中的xl输入样本和RCL 中第k个feature map 上的输入样本中位于(i,j)的一个像素,并假设网络Ol ijk(t)在时间步长t时的输出,可以表示为式(4)[11]:
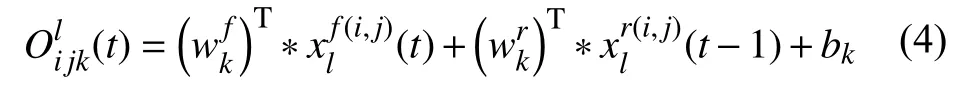
(t)是标准卷积层的输入,(t−1)为第l层RCL 的输入.wkf是k的标准卷积层权值,wrk是k的RCL 权值,bk是偏差. RCL 的输出则被送入标准ReLU激活函数f,表示为式(5)[11]:
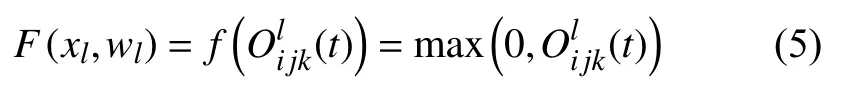
F(xl,wl)表示RCNN 单元第l层的输出.F(xl,wl)的输出被用作RU-Net 模型的卷积编码和解码单元的下采样层和上采样层. RCNN 单元的最终输出通过残差单元,假设RRCNN 块的输出为xl,可通过式(6)计算:
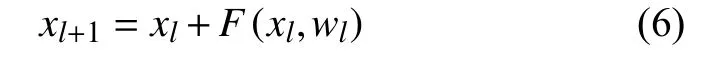
RU-Net 在视网膜图像血管分割上取得了非常不错的分割效果,准确率达到0.9528,灵敏度0.7747,特异度0.9770,本文提出的模型意在对RU-Net 加以改进,使其作为GAN 的生成器部分进一步提高分割效果,由此,本文提出在RU-Net 中添加一种Attention 机制.
3.2 Retina-Attention 机制
我们平日所说的注意力是一个神经生理学的概念,它表示人类认真观察事务的时候能有多专注[20]. 在图像语义分割领域中,Attention 机制通过学习获得一个对于目标图像的特征权重分布,比如我们重点关注的特征的权重相对较高,而不关心的特征权重则相对较低,这个权重分布被加到原图的特征上,为随后的任务提供参考,使其更多地关注重点特征,放弃一些不重要的特征,这样能够显著提高效率.
近年,众多学者将Attention 机制与深度学习的结合研究中不断探索,使二者相得益彰,其中,提取掩膜(mask)成为一个很好的手段. 掩膜给图像添加一层新的权重,使图像中的重点变得突出,然后通过学习和训练,让深度神经网络在后续工作中继承关注新图片中的重点或者说我们感兴趣的区域,注意力由此而来.
受Self-Attention[21]的启发,我们需要注意的仅是含有有效视网膜信息的图像,或者说是含有血管信息的图像,在本文中也就是圆形内部的信息这部分是我们的感兴趣区域(ROI). 由此本文在生成器部分添加了一种Attention 机制,将其命名为Retina-Attention,整体结构如图4 所示.

图4 Retina-Attention 结构
该机制分为两个步骤:
(1)提取掩膜,通过二值分割将ROI 区域与无关背景区别开来,如图5.
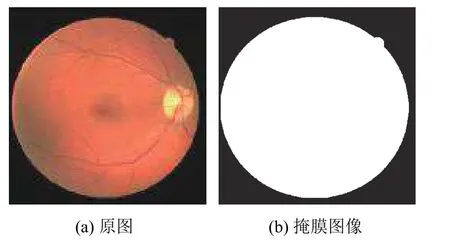
图5 提取掩膜
(2)将掩膜与RU-Net 的倒数第2 层特征映射进行相乘,如图4 中长箭头所示. 如式(7)所示:
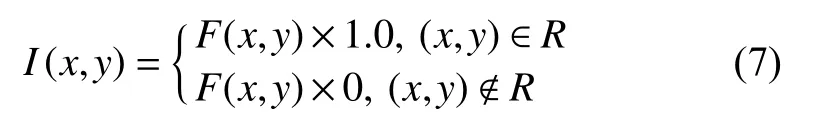
其中,R表示ROI (感兴趣区域),也就是我们注意力要关注的区域,F表示特征. 这个Attention 机制的作用就是让G只关注眼底图像中有信息的视网膜区域(圆形内部的区域),放弃没有有效信息的噪声背景(圆形外黑色区域),这样做能有效提高分割效率,防止G生成不必要的信息来占用D的效率. 提取掩膜有时由于提取之后信息量太少从而导致分类器网络层数堆叠大大减少的问题,采用这种掩膜与RU-Net 中的残差网络结合的方式对当前网络层的信息加上掩膜,同时也能够把上一层的信息传递下来,可以有效防止提取信息量较少问题的发生.
4 判别器部分
为了区别G(z)与真实值,判别器D设计成简单的卷积神经网络并且运用全局平均池化层(global average pooling,GAP),选择GAP 的原因是GAP 能够削减参数数量,有助于给模型训练提速.
由于G(z)是基于块的,所以在输入D之前需要先进行重组再输入. 关于输入图像,正样本是经过ACE处理后的眼底图像和专家手工分割图的组合,负样本是经过ACE 处理后的眼底图像和G(z)组合,通道数设置成2.
样本进入判别器时,卷积提取特征设置成步长2,大小3×3,激活函数选用ReLU,选取批标准化提高训练进度,然后设置步长1,大小3×3 的卷积提取特征,如图6 所示,此时分辨率没有改变,继而通过2×2 的max-pooling 使分辨率下降,特征提取多次后,通道数为512. 最后采用Sigmoid 函数,配合GAP 连接全连接层,得到D(x).
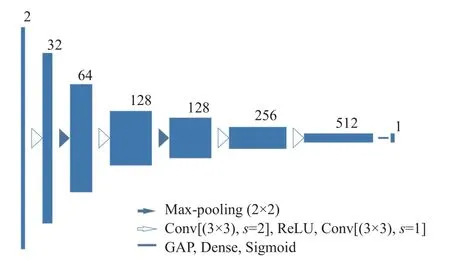
图6 判别器部分
5 实验结果
5.1 数据集设置
为了展示Retina-GAN 的性能,我们在DRIVE 数据集上进行了实验. 对于DRIVE 数据集的处理在第2 节中已经做了一些介绍,选择其一半图像作为训练集,另外一半样本作为测试集. DRIVE 图像原始像素为565×584. 为了开发一个方形数据集,我们将图像压缩为512×512 像素再进行扩充到3840 张. 在这个模型实现中,我们考虑了从DRIVE 扩充数据集中随机选择一半图像的patch 用于训练,其余的patch 用于验证,每个patch 的大小都是128×128.
5.2 实验设置
实验选择Adam 梯度下降方式,动量项系数为默认值,学习率设为0.0005,每训练一次G,随后训练D,交替训练. 关于硬件,CPU 选择英特尔i7 处理器,GPU 为英伟达GTX 1080.
模型训练步骤如下:
(1)将专家手工分割图像输入D进行训练;
(2)把DRIVE 中的眼底图像和掩膜输入G得到G(z),再把G(z)与经过ACE 处理后的眼底图像标记为负样本输入到D进行训练;
(3)训练G,得到G(z)后再输入D中继续训练. 反向传播的过程中D的参数没有更新,只传递误差,G的参数要更新和优化;
步骤(1)–(3)迭代训练,令G(z)对于D而言能够以假乱真.
5.3 评价指标
进行定量分析时,选择使用准确性(accuracy,Acc)、灵敏度(sensitivity,Sen)以及特异性(specificity,Spe)这3 个性能指标. 具体计算公式如下:

TP代表血管被正确分类为血管的像素点数,FP代表背景被误分为血管的像素点数,TN代表背景被正确分类为背景的像素点数,FN代表血管被误分为背景的像素点数.
5.4 实验结果
该方法展现了更精准的分割效果,图7 分别为专家手工标注以及训练迭代1000 次,2000 次,4000 次的效果,方框里为血管的细节分支部分,随着迭代次数的增多,血管的分支和细微部分逐渐详细.
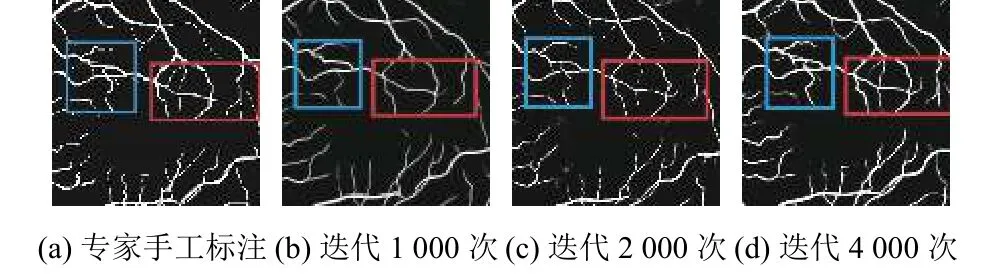
图7 血管细节图
图8 为在DRIVE 数据集上使用不同算法的效果;折线图9–图11 横坐标为测试集图片序号,纵坐标为指标对应的值,这些数据显示了Retina-GAN 在各个指标上均有提升. 这些数字表明,与GAN、U-Net、RU-Net等方法相比,本文设计的模型在训练和验证阶段提供更好的性能,在精确度、灵敏度均有提高. 证实了Retina-GAN 对任务分割的有效性.
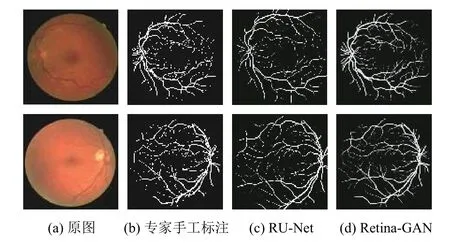
图8 实验结果
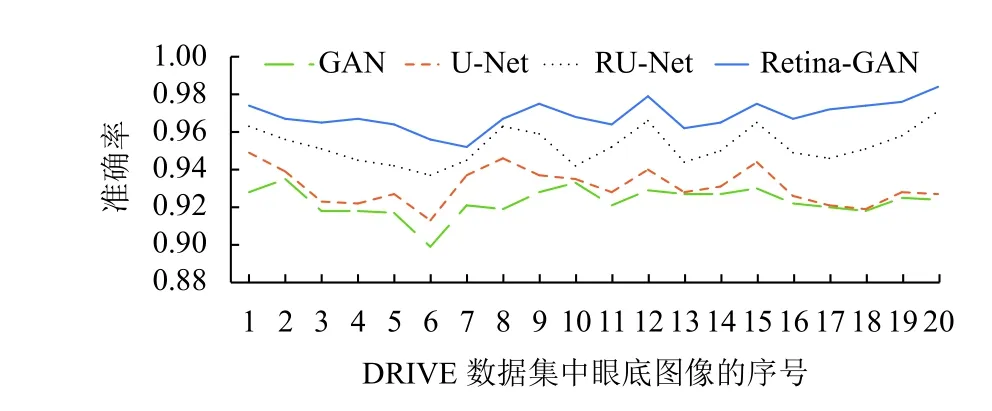
图9 多种方法在DRIVE 数据集上的准确率
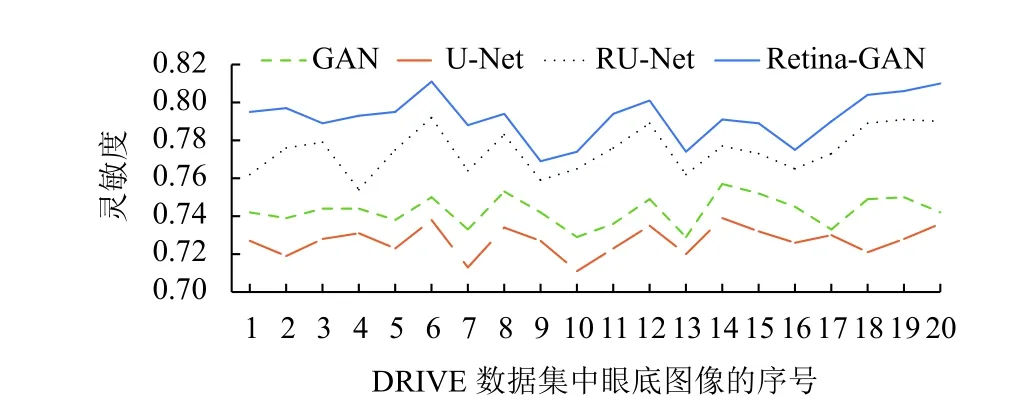
图10 多种方法在DRIVE 数据集上的灵敏度

图11 多种方法在DRIVE 数据集上的特异度
同时,预处理方面,为了与滕梓晴[22]和张天琦[23]使用的CLAHE 做比较,我们分别使用ACE 和CLAHE对DRIVE 数据集进行预处理,从表1 和表2 的数据可以看出,不管是GAN 还是Retina-GAN 上,ACE 的表现均优于CLAHE,实验效果更好.
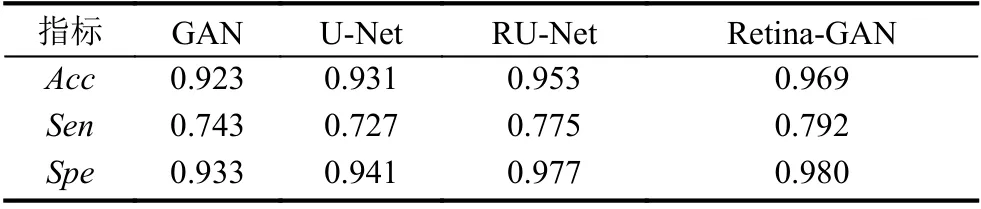
表1 多种方法在DRIVE 数据集上的实验结果
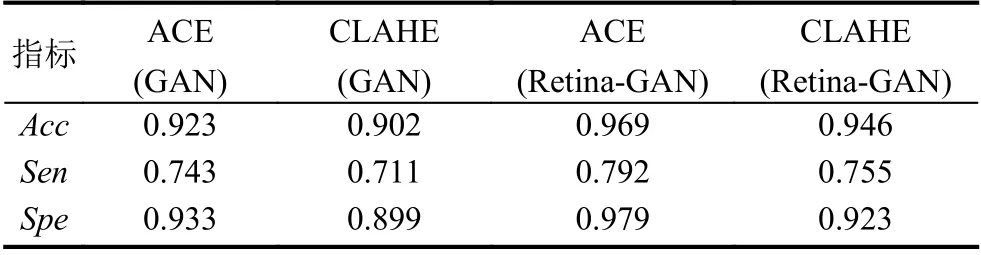
表2 ACE 和CLAHE 在不同算法上的表现
6 结束语
尽管通过实验证明了Retina-GAN 结构的效果在以往算法上有了提升,但对于灵敏度的指标还有很大提升空间,未来的工作将围绕在不影响准确率的情况下来优化灵敏度展开.
