面向知识图谱的信息抽取技术综述①
2022-08-04赵肄江邹子维
姜 磊,刘 琦,赵肄江,袁 鹏,李 媛,邹子维
(湖南科技大学 计算机科学与工程学院,湘潭 411100)
随着信息时代的到来,数据呈爆发式的增长,如何从这些数据中通过智能技术自动提取出真正有价值的信息,尤为重要. 知识图谱[1]是一类知识表示,由实体、关系以及属性构成[2]. 实体又称为类或实例,是不依附于其他东西而存在的,比如人,机构等. 关系表示实体,实体属性之间的关系. 属性是用来描述实体的某种特征,比如身高,体重等. 知识图谱技术在数据分析、智能搜索、决策支持以及医疗健康等领域越来越发挥出主要的作用.
知识图谱的构建过程: 首先从数据源中提取出碎片化事实[3],然后对碎片化事实进行知识的融合,再经过知识加工后通过迭代更新建立基于知识的体系[4]. 显然,知识图谱的构建过程包括: 信息抽取(information extraction),知识融合,知识加工[5]等. 信息抽取作为知识图谱的主要组成,从数据源中抽取出实体和实体之间的关系等结构化信息[6]. 包括对实体、关系以及事件等方面的抽取[7]. 信息抽取的正确性对知识图谱的后续构建质量和效率产生影响.
信息抽取通常采用基于NLP 和文本挖掘的方法.在信息抽取研究的成果中我们发现当前的研究在提升信息抽取准确度的基础上主要围绕如何减少人工标注语料、人工提取特征以及人工构建模式展开. 这使得知识图谱中的信息抽取面对着3 个挑战: 第一,如何从需要构建知识图谱的领域语料中利用启发式的信息来发现语料中的隐含知识,从而在较少的人工标注中获得较高的准确度. 第二,如何解决已有知识图谱中部分不完整的实体、关系与事件信息所带来的噪声与语义漂移问题. 第三,如何在开放领域中利用现有的标注或加上较少的标注实现知识图谱在新信息中的完善与更新.
本文综述了知识图谱中信息抽取技术,详细地描述了近年来在实体、关系和事件抽取中的各项技术,探讨这些技术在解决上述3 大挑战的进展. 以便研究者能对信息抽取技术有一个全局认识,进而能厘清技术的发展趋势与方向. 期望研究者能从中汲取技术的精华和理念,进一步推动信息抽取技术的发展.
1 实体抽取
命名实体识别(named entity recognition,NER)是实体抽取的别称. 命名实体能在具有相似属性的一组事物中清楚的标识出一个事物. 它可以理解为有文本标识的实体,而实体(entity)是不依附于其他东西而存在的. 在现实世界中,实体通常分为3 大类7 小类.NER 是从文本中抽取实体信息元素. NER 主要有基于规则和字典的方法[8,9],基于监督学习的方法[10–13]和基于深度学习的方法. 近年来,越来越多的研究者开始关注基于深度学习的NER 方法.
1.1 基于深度学习的方法
近年来,基于深度学习的NER 模型逐渐占主导地位,与传统的机器学习相比,深度学习有助于自动发现隐藏的特征[14],进行特征抽取,使得泛化能力得到了提升. Hammerton 等人[15]是最早使用LSTM 来进行NER,该模型在序列建模上具有良好的表现.
深度学习在实体抽取领域取得较好效果后,研究人员开始在词汇级别上对其神经网络结构进行改进研究. Lample 等人[16]通过加入CRF 模块以优化标签序列输出,提出了BiLSTM-CRF 模型,在语料库上取得了比较高的F1 值. Ma 等人[17]在双向LSTM-CNNS结构上,添加了CRF 模块,提出BiLSTM-CNNs-CRF模型,模型能同时利用词和字符级表示. Luo 等人[18]提出了一种Att-BiLSTM-CRF 模型,该模型用于文档级实体识别,在数据集上取得的F1 值为91.14%.
上述模型偏重于词或字符的特征提取,无法动态的表征上下文语境中的一词多义. 为了改善这问题,Devlin 等人[19]提出了BERT 模型,该模型可以使上下文语境或语义中的词得到充分的表征. Souza 等人[20]将BERT-CRF 模型应用于葡萄牙NER任务上,获得了新的最佳F1 值. 谢腾等人[21]提出一种BERT- BiLSTMCRF 模型,该模型在两个语料库上进行实验,得到的F1 值分别是94.65%和95.67%. 在文献[19]的基础上,百度推出了ERNIE 模型[22],该模型是通过加强BERT的masking 来获取知识. 实验表明,在5 项NER 任务上,ERNIE 刷新了榜单. 微软提出了一种多任务的训练方式的MT-DNN 模型[23],该模型比BERT 更加稳定,泛化能力更好. 由卡内基梅隆大学提出的XLNet 模型[24]是一种通用的自回归预训练模型,该模型解决了BERT在预训练时加入[MASK]的token,从而导致pretrain和finetune 在训练数据上的差异. Liu 等人[25]对BERT的预训练进行了仔细的评估,提出了一种能更好地训练BERT 的方法,称为RoBERTa 模型,该模型比BERT之后的所有psot-BERT 模型的效果好. Joshi 等人[26]提出一种SpanBERT 模型,模型旨在更清晰的预测和表达文本跨度,不再通过随机标记而是通过屏蔽连续的随机跨度来使得BERT 得到扩展. 谷歌提出了ALBERT模型[27],该模型在BERT 模型的基础上,减小了两种参数量,通过两个参数稍减技术克服了扩展预训练模型面临的主要障碍,使得训练更加稳定.
近几年,在基于深度学习的方法上加入注意力机制[28],迁移学习[29],对抗学习[30],远程监督[9]等热门研究技术也是NER 中的一个研究热潮.
2 关系抽取
关系抽取(relation extraction,RE)旨根据实体之间的上下文语境来确定语义关系,它为许多下游任务提供了基础支持,比如文本理解中,为了理解复杂的语句,识别语句中的实体对之间的关系是至关重要的.在问答系统中,关系抽取所得到的实体间的关系实例可以作为背景知识支撑问题的问答. 在NLP 领域中,关系抽取最重要的应用是构建知识图谱.
2.1 基于深度学习的方法
传统的关系分类模型需要耗费大量的人力去设计特征,而且很多隐性特征也难以定义. 因此传统方法在大规模关系抽取任务中效果不佳. 基于深度学习的关系抽取能够自动学习有效特征. 有监督的关系抽取方法是深度学习方法中的一个主要方法,在解决人工特征选择和特征提取误差传播等问题上有不错的效果.流水线学习和联合学习是有监督的关系抽取方法主要的两种类别. 基于深度学习的关系抽取的另一个主要方法是远程监督的方法,其利用已知知识库信息以减少人工处理.
2.1.1 流水线学习
流水线学习方法中的关系抽取是在实体抽取完成的基础上进行的,因此关系抽取结果的好坏与实体抽取的结果有直接关联. 主要采用的方法是CNNs 和RNNs.其中CNNs 有利于识别目标的结构特征. RNNs 有利于识别序列[31].
Wang 等人[32]提出了一种新的结构块驱动卷积神经学习新型轻量级关系提取方法. 在两个数据集上进行实验,验证了该方法的有效性. Lin 等人[33]将注意力机制引入句子级中,提出了一种纯文本的实体关系抽取方法,该方法动态地降低噪声对句子的影响,有效地提高了跨语言的一致性和互补性. 深度学习模型在受到有限的标记实例的限制时,可以借助于合适的网络结构来获得良好的性能. 如Lin 等人[34]提出了一个自训练的框架内具有多个语义异构嵌入的循环神经网络.
随着不断的改进和完善CNNs 和RNNs,使它们产生了许多的变体,如双向长短期记忆网络(Bi-LSTM).Xiao 等人[35]提出了一种能从原始句子中提取信息进行关系分类的递阶递归神经网络模型. Xu 等人[36]提出了神经网络SDP-LSTM 模型,该模型对句子中两个实体之间的关系进行分类.
随着GCN 在NLP 领域的应用,GCN 也被应用到关系抽取的研究中. Schlichtkrull 等人[37]提出的RGCNs 模型,是一种关系图卷积网络. Zhang 等人[38]提出了一种图卷积网络的扩展方法来对实体关系进行抽取. 在数据集上取得的最佳结果F1 为68.2%. 优于现有的基于序列和依赖关系的神经模型. Zhu 等人[39]提出的GP-GNNS 模型,是一种新的带生成参数的图神经网络,该模型可以通过多跳关系推理来发现更精确的关系. 在跨句子的n元关系中检测出n个实体之间的关系. 典型的方法是将输入制定为文档图,集成各种句内和句间依赖关系,但是这种模型可能会使重要的信息在分割过程中丢失,因此,Song 等人[40]提出了一种Graph-State LSTM 模型,来改进这个问题. 为了有效地利用相关信息和忽略不相关信息,Guo 等人[41]提出了注意力机制图卷积网络(AGGCNs),一种直接以完全依赖树为输入的模型.
流水线方法使得关系抽取能得到实体抽取的有用信息,从而提升了关系抽取的效果. 但该方法也会产生错误传播,使得没有关系的两个实体之间出现关系.
2.1.2 联合学习
为了避免流水线学习中存在的问题,联合抽取将实体和关系放在同一模型中共同抽取. 联合学习主要有两种类别: 参数共享和标注策略.
参数共享是指模型通过共享编码层产生的共享参数来彼此依赖,最后通过训练得到全局参数[32]. Zheng等人[42]提出了一种用BiLSTM-ED 模块对实体进行提取和用于关系分类的CNN 模块组成的一种混合型神经网络模型,在BiLSTM-ED 模块中获得的实体的上下文信息进一步传递到CNN 模块以改进关系分类.Miwa 等人[43]提出的模型同样是通过参数共享来联合学习,F1 达到了84.4%. 上述模型实际还是分别提取实体和关系,通过参数共享机制相关联. 这会出现没有关系的实体对信息. 针对这个问题,Zheng 等人[44]提出了将联合提取任务转换为标注问题. 直接提取实体及其关系,无需分别识别实体和关系. 取得了不错的效果.对于之前的模型没有考虑实体关系重叠问题,Bekoulis等人[45]将联合抽取问题看作一个multi-head selection(多头选择)问题,以此来解决重叠问题. Bekoulis 等人[46]将对抗学习加入到文献[45]的模型中,使得模型中的词嵌入的质量更好,性能得到显著提高.
基于神经网络的联合学习除了共享参数和标注策略之外,Nayak 等人[47]通过编解码架构的设计来实现联合提取实体和关系. Li 等人[48]将实体关系联合抽取的任务当作一个多轮问答问题来处理. Wei 等人[49]设计了一种层次二进制标记框架. Sun 等人[50]提出一种首先识别实体跨度,然后对实体类型和关系类型执行联合推理. Fu 等人[51]提出了一个端到端的关系提取模型GraphRel,它使用图卷积网络(GCNS)来联合学习命名实体和关系. 这些方法都取得了较好的结果.
2.1.3 远程监督的方法
在文本中,如果实体之间存在某种关联,那么就会以某种形式表现出这种关联. 在这种前提下,基于远程监督的方法,首先从文本中抽取出存在关系的实体对句子,然后将句子作为训练数据放入模型中进行关系抽取.
采用知识图谱和文本对齐方式来自动提取训练数据,减少了人工标注. 但是,这些数据中会引入大量的噪声,从而引起语义漂移现象. 为了减少语义漂移现象的出现,Ji 等人提出了APCNNs 模型[52],它在句子级别引入attention mechanism. APCNNs 模型有可能会出现包含同一实体对的所有样例句子都含有大量噪声的情况. 针对这一问题,Feng 等人提出了基于强化学习的关系分类模型CNN-RL[53],该模型能有效地处理数据中的噪声,并在句子层次上取得了较好的关系分类性能.远程监督能够自动生成大量用于关系提取的训练样本.然而,会带来两个主要的问题: 不平衡的训练数据和训练数据中出现噪声,使得获取到的数据集准确率较低,影响整个关系抽取模型的性能. 因此,有较大的提升空间[54].
2.2 基于开放领域的方法
基于开放领域的关系抽取方法,在大规模非限定类型的语料库中结合语形和语义特征自动进行关系抽取,减少了人工标注成本. TextRunner 开放信息抽取原型系统是一个面向开放领域的信息抽取框架(OIE),实体关系能够自动进行抽取,但F1 的值不太理想. 在OIE 的基础上,Wu 等人提出了WOE 系统[55],F1 的值比TextRunner 的F1 提高了18%–34%,但是该系统在速度方面出现了不足. Nakashole 等人提出了PATTY系统[56],用于表示实体之间二元关系的文本模式,这些模式在语义上被分类并构建成一个分类体系. 该模型可以处理Web 规模的语料库中的关系抽取. Mausam等人[57]提出了一种系统,该系统解决了OIE 系统仅以动词为主的关系抽取和忽略了上下文这两个限制,有效地改善了F1 的值. TextRunner、WOE、PATTY、OLLIE 系统都属于二元的开放式关系抽取. KrakeN[58]是由Akbik 等人提出的一个多元关系抽取系统. 该系统是一种高精度OIE 框架,比现有的OIE 更能完整地捕获每个句子中的多元关系,但容易受到噪声和不合法的文本的影响.
基于开放域的关系抽取在二元关系抽取上的准确率和正确率有待于提高,在挖掘隐藏信息方面的提升,有助于关系的抽取. 面向开放域的关系抽取方法在性能上存在不足,这给研究者留下了研究空间.
3 事件抽取
事件抽取(event extraction,EE)被定义为从文本中提取出对人类有用的信息事件,并以结构化的形式表示出来. 例如从“李华1922 年出生于湖南长沙”文本中抽取出事件{类型: 出生,人物: 李华,时间: 1922 年,出生地: 湖南长沙}. 事件抽取主要的任务包括从文本中发现触发词和从文本中识别出元素扮演的角色. 如图1和表1 所示.

图1 事件抽取结构分析

表1 事件抽取任务
事件抽取中,基于模式匹配的方法通过模式匹配算法进行事件抽取,主要的模型有ExDisco,GenPAM等. 模式匹配方法在特定领域能取得很好的性能,但移植性差,在跨领域进行事件抽取时,需要重新构建.
在机器学习方法中,事件抽取问题转换成了分类问题. 常见的分类算法有SVM,ME 等. 基于机器学习的事件抽取方法移植性能好,但是需要依赖大规模的知识库,否则可能会出现数据稀疏问题. 另外,特征选取也是一个重要因素. 怎样解决这两个因素,成为了机器学习方法在事件抽取研究中的重要方向.
基于深度学习的事件抽取模型主要有动态多池卷积神经网络(DMCNN)[59],该模型能够从单词的连续及其广义表示中自动学习隐藏特征表示,解决了人工设计特征、可扩展性差以及依赖复杂NLP 工具等问题.Nguyen 等人[60]提出了一种双向循环神经网络的联合框架(JRNN),该模型与DMCNN 相比,JRNN 避免了误差累计传播导致模型性能下降的问题,可以同时抽取出所有的事件信息,使用从整体结构中学到的全局特征来提升局部信息的预测能力. Chen 等人[61]提出了一个具有门控多级注意力机制的分层和偏置标记网络框架,该框架解决了仅利用词或者句子信息,忽略了篇章信息的问题.
对信息抽取中的实体抽取,关系抽取和事件抽取的不断研究,部分学者开始进行多任务联合学习的研究,多任务联合学习解决了各任务独立学习时忽略了依存关系问题. Lee 等人[62]提出了一个新颖的共指解析系统,它可以跨文档的联合实体和事件,使用迭代方式构建实体和事件提及的集群,用线性回归来建模集群合并操作. Barhom 等人[63]受文献[62]的启示,提出了一种跨文档共指解析的神经架构模型ECB+用来联合建模实体和事件共指. 它的结果优于文献[62]提出的模型. Xi 等人[64]提出了一种BERD 模型,该模型通过结合实体上下文的参数角色来预测生成参数角色,从而提升隐式参数分布模式中更准确的事件. Han 等人[65]提出了一种Neural SSVM 模型,该模型通过将事件和关系共享上下文嵌入来使事件的表示得到改进. Han等人[66]进一步提出了一个以概率领域知识构建分布约束来增强深层神经网络框架. Tang 等人[67]提出了一种用于事件关系抽取的多层知识投影网络(MKPNet),可以有效地利用多层话语知识进行事件关系的抽取.
事件抽取一般从属于实体、关系才有明显的意义,所以目前一般采用联合学习的方式结合实体、关系抽取所获得的信息来进一步指导事件的抽取.
4 信息抽取的研究趋势
NER、RE 与EE 是知识图谱信息抽取的3 个子任务. 图2 与图3 是我们针对2015–2020 年NLP 领域的两个顶级会议ACL 和EMNLP 上的信息抽取各子任务的论文数量的统计. 从图中可以看出信息抽取3 个子任务的研究热度逐年上升.

图2 ACL 会议中信息抽取子任务的论文数量
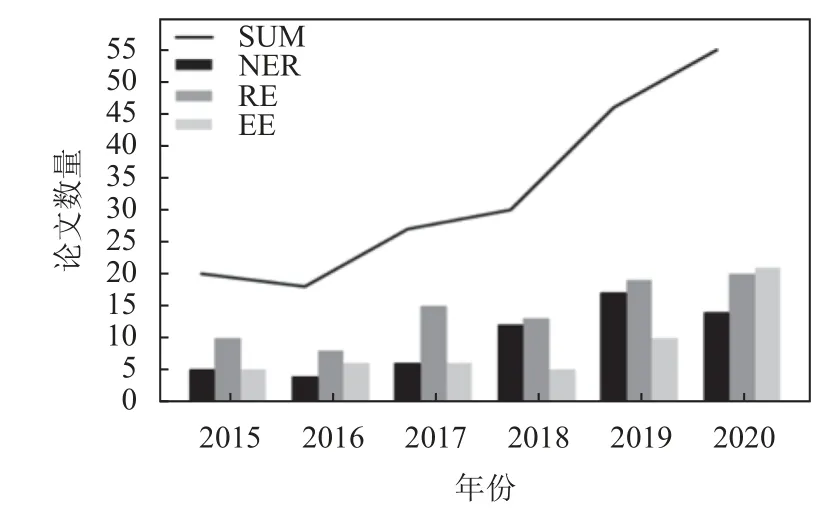
图3 EMNLP 会议中信息抽取子任务的论文数量
我们将知识图谱中信息抽取的主要技术整理成表2–表4. 如表2 所示,实体抽取开始于基于规则和字典的方法. 随后采用基于监督学习的方法进行研究,取得了大量研究成果. 但是该方法需要对语料进行大量的标注,研究的方法主要围绕如何降低人工标注的数量获得准确的抽取. 鉴于深度学习能够很好地发现隐藏特征,可以降低特征的人工抽取,所以目前大量的实体抽取的研究围绕深度学习展开. 它在当前的研究热点在于如何引入语言学的成就在词汇、句法、语义特征等方面来寻找合适的神经网络结构来提升实体抽取的能力.

表2 实体抽取研究发展趋势

表4 事件抽取研究发展趋势
如表3 所示,当前关系抽取的方法主要有4 种. 研究的趋势主要是采用各种技术来降低人工提取关系特征. 在这里主要分3 种: 一是利用深度学习方法具有的学习隐知识的能力,从词汇、句法结构、语句块以及引入图像处理方面的知识来改进深度学习中的神经网络的结构; 二是引入外部知识库中与待抽取关系中重叠知识来降低复杂度,主要采用增强学习来处理噪声与语义漂移; 第三就是采用监督学习以及启发式规则等方式对开放领域中新信息的汇入造成的新关系引入、旧关系的偏移进行研究.

表3 关系抽取研究发展趋势
事件抽取主要方法如表4 所示,主要分为基于模式匹配、机器学习、深度学习与联合学习的方法. 研究者仍然是围绕如何降低人工标注的工作量展开. 同时,为了利用实体抽取、关系抽取中获得的知识,现在将事件抽取与上述两个任务整合一起进行联合抽取已逐渐成为研究热点.
5 结束语
知识图谱构建过程中信息抽取是必不可少的环节.本文详细介绍了近年来信息抽取中实体抽取、关系抽取和事件抽取的技术进展,梳理了它们的发展趋势. 在应对减少人工干预信息抽取的3 大挑战中,目前的研究主要集中在针对领域语料采用深度学习进行. 它表现在利用句法结构、注意力机制等语言学知识和图像处理知识来寻找合适的神经网络结构以改进深度学习. 而在融合已有知识图谱中知识以及在开放领域中减少人工工作方面,目前的研究成果较少.因此,在知识图谱的信息抽取研究中继续进行深度学习的研究是一个重要方向. 而引入机器学习中的降噪技术结合信息抽取的特点做已有相似实体、关系与事件的融合是一个可行的有前景的方向. 另一个非常有前景的方向就是对开发领域中已有标注的语料结合新信息、新语料利用半监督学习的成果进行信息抽取的研究. 希望能有更多的学者就这两个方向展开研究取得成果.
