基于K-means Bayes和AdaBoost-SVM的故障分类①
2022-08-04黄子扬周凌柯
黄子扬,周凌柯
(南京理工大学 自动化学院,南京 210014)
随着社会的发展和科技的进步,化工过程和设备变得更加复杂与多样化,故障诊断也成为了当代过程监控中的一项重要任务[1,2]. 近年来,由于信息技术的快速发展,使得工业过程中的数据可以大量采集并保存,因此基于数据驱动的故障诊断相关方法得到了学者们的广泛关注[3,4]. 除了基于数据驱动的方法外,基于数学模型的方法及基于知识的方法也都是常用方法. 然而基于数学模型的方法存在着模型建立难、诊断的结果直接受模型准确性影响等问题,因此在复杂系统中该类方法的使用受到限制; 基于知识的方法则需要大量的经验和专家知识来建立知识库,通用性差. 而基于数据驱动的方法直接对数据进行分析,能够规避上述两类方法存在的问题,因此目前在复杂系统中使用更多[5–7].
故障分类技术在数据挖掘和机器学习领域得到快速发展,但是大多数的分类方法均假设其训练集中的各类样本数相似或相等,当训练集呈现数据不平衡特征时,分类性能通常并不令人满意. 张剑飞等[8]指出不平衡数据的分类问题广泛出现在疾病诊断、垃圾邮件处理、信用卡检测等领域,但传统的机器学习算法在数据不平衡比过大时,分类效果会急剧下降. Japkowicz等[9]指出利用决策树处理不平衡数据时,训练过程会被多数类的样本主导,导致对少数类的样本识别率低.为了提高对不平衡数据的分类性能,目前常采用的方法主要包括两个方面: 数据层面和算法层面[10,11]. 在数据层面,为降低数据的不平衡比,通常会采取欠采样或过采样的方法改变训练样本的数量. Liu 等[12]提出了一种EasyEnsemble 的欠采样方法,该方法通过从多数类样本中有放回的随机采样出n个每个子集,使子集的样本数与少数类近似相等,并将各子集分别与少数类样本合并进行训练,从而达到保留多数类样本信息的目的. Chawla 等[13]提出了一种SMOTE (synthetic minority oversampling technique)的过采样方法,通过对少数类中的某个样本及其邻近样本进行叠加,产生人造样本来降低样本间的不平衡度. 虽然上述方法对部分场景下的不平衡数据问题具有一定的效果,但是它们仍有一些不足之处需要改进. 由此,更复杂的重采样技术被提出. 张天翼等[14]提出了一种改进SMOTE的重采样方法,通过将合成样本从一维空间扩展至更高维空间,使新样本更加多样化. 李忠智等[15]结合卷积神经网络和生成对抗网络,利用卷积神经网络从故障样本中提取训练特征后输入至对抗网络,并由解码器网络来生成新的故障样本. Chen 等[16]提出了一种Kmeans Bayes 方法,利用T 阈值K-means 在既不减少多数类样本也不增加少数类样本的前提下,提高对少数类故障的识别能力. 在算法层面,通常是对现有的分类算法进行修改,以增强对少数类的学习能力. 如代价敏感学习、集成算法等.
Bayes 和SVM 是故障诊断领域常用的两种方法.Lemnaru 等[17]指出Bayes 和SVM 使用的前提是不同类型样本的数据量近似相等,当数据不平衡严重时,这两种方法通常会表现出较差的分类性能. Zhang 等[18]将D-S 证据理论应用于多分类器实现故障监控,有效提高了分类性能. 本文主要研究数据不平衡的算法层面,同时考虑到单一方法在这种数据不平衡条件下的局限性,提出了一种基于多分类器融合的故障分类方法. 选择K-means Bayes 作为分类模型1,AdaBoost-SVM作为分类模型2,并利用D-S 证据理论将二者的分类结果进行融合,进一步提升分类性能. 将该方法运用在Tennessee Eastman (TE)数据集上,经仿真和实验证明了所提方法的有效性及可行性.
1 K-means Bayes 算法
1.1 Naive Bayes
Naive Bayes 是一种基于贝叶斯定理和条件独立性假设的分类方法[19]. 给定一组训练数据T={(x1,y1),(x2,y2),···,(xN,yN)},其中,N为训练样本总数,xi=为每一个样本数据,yi={C1,C2,···,Ck}为各样本数据对应的标签,对于一个测试样本x,Bayes分类器将后验概率P(Y=Ck|X=x)最大的类作为x的类输出:

依据条件独立性假设,且每个连续变量x(j)均服从高斯分布:

对于样本x的分类结果为:

1.2 K-means Bayes
K-means Bayes 算法[16]的思想为: 在不改变原始数据集信息的情况下降低数据不平衡性对故障分类带来的影响. 算法步骤如算法1.

算法1. K-means 对多数类均分X=[x1,x2,···,xm]X*1)给定多数类样本,标准化得到 ;X*kµT=m/k 2)指定个聚类子集: 从 中随机选择个样本点作为初始聚类中心,并计算各子集的样本数;U={U1,···,Uk} U*={U∗1,···,U∗k}Ui k 3)设置2 个集合和,其中 存放原始样本数据,存放标准化后的数据;X∗x*µi U∗i U∗i 4)对 的各样本 ,计算与各聚类中心的距离,找出距离最近的 及对应的 ;U∗ini≤Tni≤Tx*x U∗iUini≥T Ui 5)判断 的样本数 是否 . 若,则将 和对应的分别分配至和 ,并转至4)对下一个样本进行计算; 若,则该样本将不再分至 ,并转至4)重新计算;U∗i 6)当所有样本完成分类后,计算各子集 的样本均值,并作为新的聚类中心 ,并判断各 与 是否相等; 若则算法终止输出结果,否则返回3)进行下一轮计算.µ′i µi µ′i µi=µ′i Ui
对于测试样本x,可利用式(3)预测其类别,再利用
式(4)转换成实际类别:

2 AdaBoost-SVM 算法
2.1 SVM
SVM (support vector machine)[20]是一种有监督的二分类模型,其思想是寻找到一个分离超平面,此超平面不仅能正确划分开正负实例点,还能使离超平面最近的点(支持向量)离超平面尽可能的远. 给定一组线性可分的训练数据集T={(x1,y1),···,(xN,yN)},其中xi∈X∈Rn,yi∈Y∈{+1,−1},则分离超平面为:

分类决策函数为:

为解决多分类问题,通常将多分类问题进行拆分并利用投票机制进行分类. 常用的拆分策略包括“一对多”和“一对一”,本文使用“一对一”策略,这样由少数类构成的子分类器的正类和负类可看成是平衡的,有利于提高分类性能. 由于可能存在子分类器对某些类的分类能力较差,影响最终的投票结果,因此引入AdaBoost分类器替换[21,22].
2.2 AdaBoost
AdaBoost (adapative boost)[23]是提升学习Boosting里的一种,其思想是通过反复学习得到一系列的弱分类器,并将这些弱分类器进行加权组合得到一个强分类器.

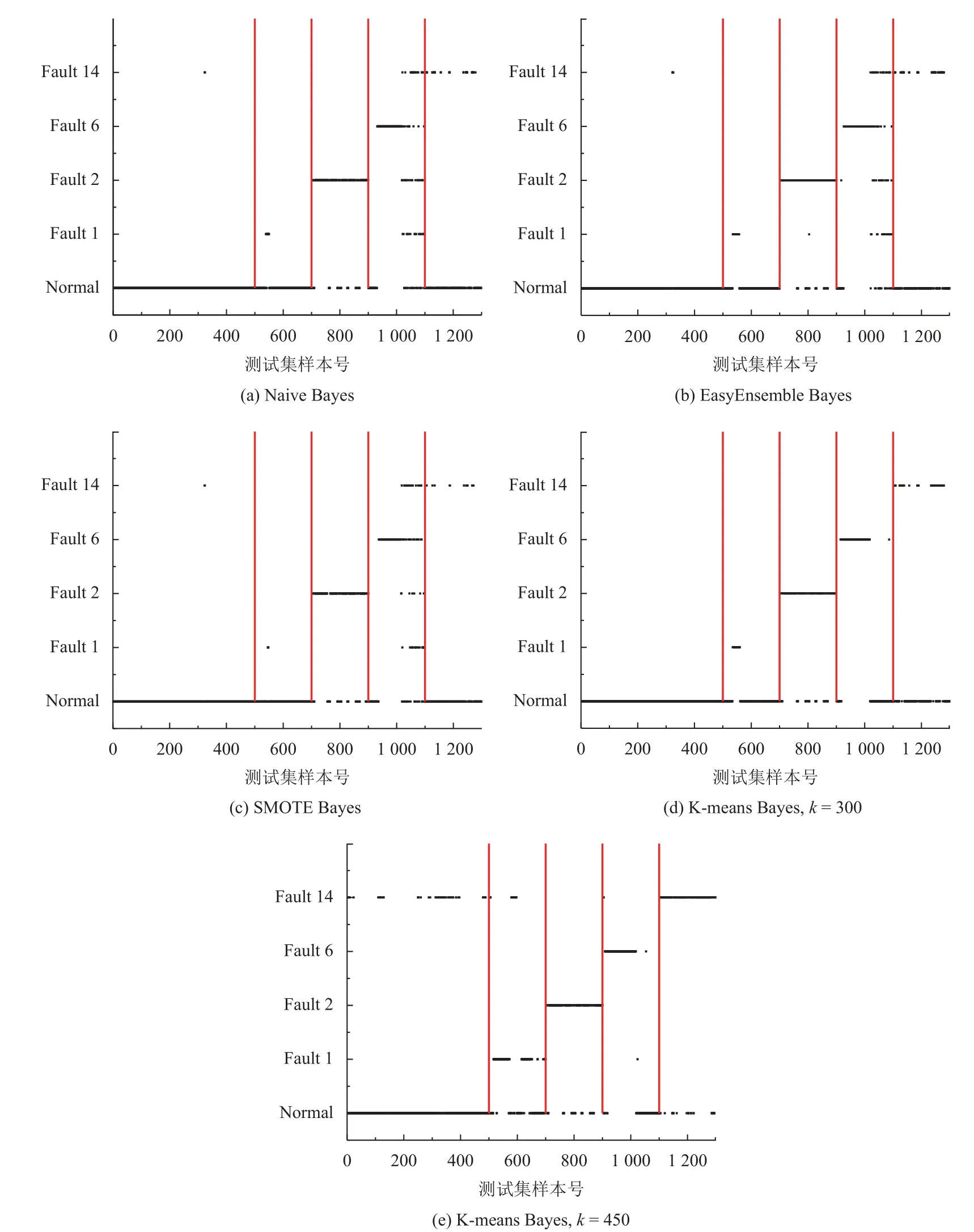
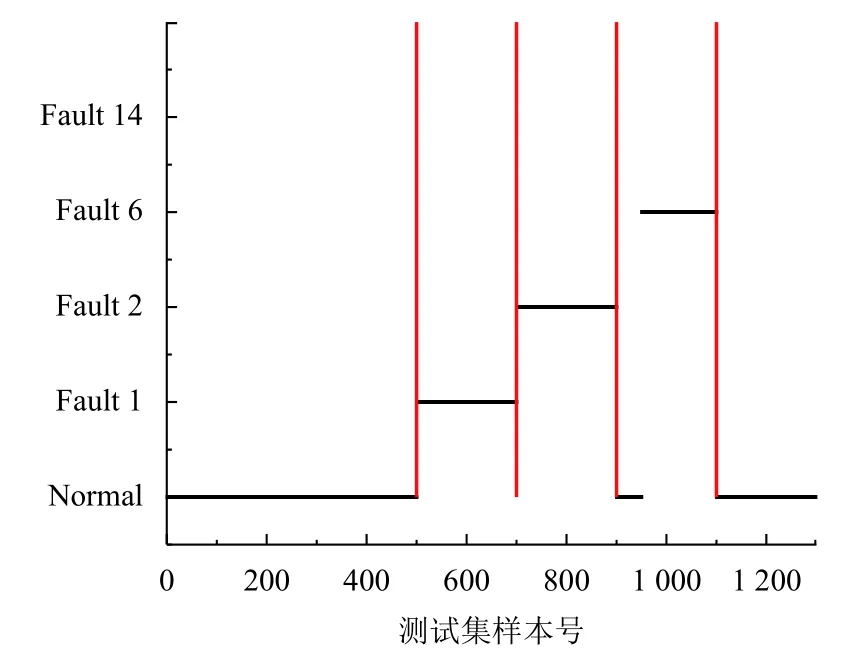
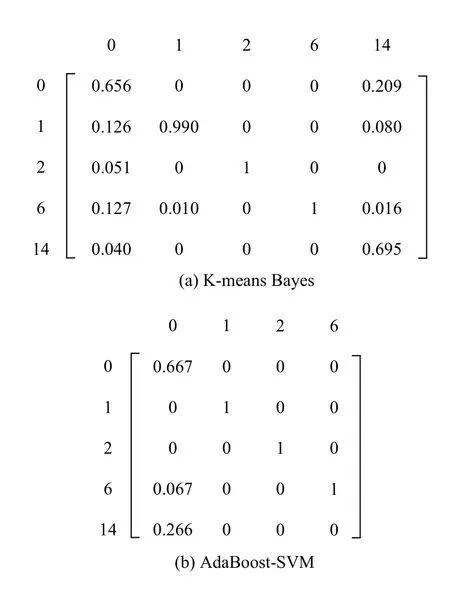
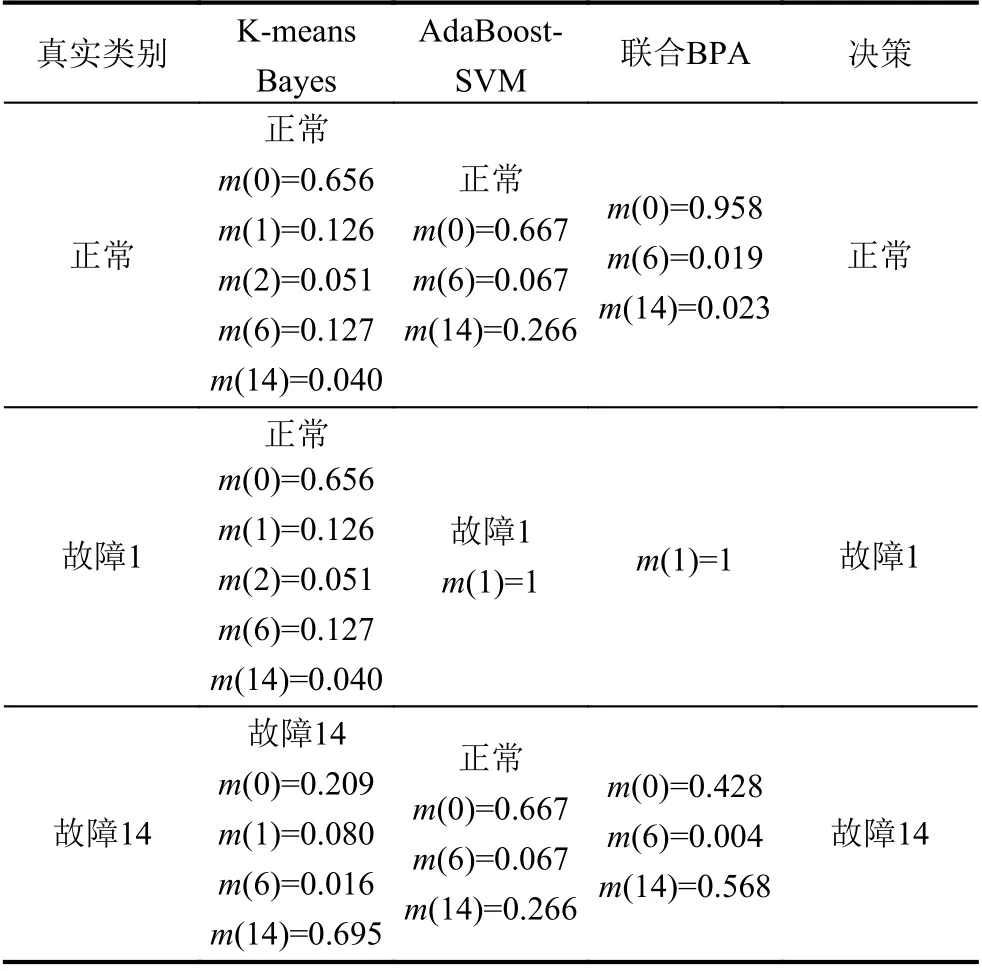
算法2. AdaBoost-SVM 1)设置每个子分类器的最低分类正确率;Accmin N=C2n 2)根据类别总数n 构建SVM 子分类器,其中子分类器总数为;3)对各SVM 子分类器进行训练,其中核函数选择径向基核函数(RBF),并利用网格法和三折交叉验证法进行参数寻优,选择合适的惩罚参数C 及核参数g;4)对训练好的分类器在相应的测试集上进行分类,计算各子分类器的实际正确率;Accreal 如果能设计出一种在任何情况下都具有良好泛化性能的分类器,那么单一分类器就已经能够满足需要.然而实际采集到的数据存在着噪声点、异常等问题,使得上述的单一分类器难以实现. 因此考虑创建一个故障分类系统,该系统中存在两个及以上的分类器,并希望其分类性能优于其中任意单一分类器. 当某个分类器在识别时发生错误,其他分类器可以纠正该分类器的错误. 图1 展示了一种基于D-S 证据理论的故障分类框架. 该框架主要分为两个部分: 利用训练数据进行离线建模、利用建立好的模型对数据进行在线分类. 具体来说,本系统的实施主要包括3 个步骤: 1)分类器构建;2)计算各分类器的融合矩阵; 3)利用D-S 证据理论进行决策融合. 图1 基于D-S 证据理论的故障分类框架 为了进行D-S 证据理论融合,应计算出各分类器的融合矩阵[18]. 假设样本类别集合T={F1,F2,···,Fn},其中第i个类别称为Fi,i=1,2,···,n,n为所有类别的总数. 分类器总个数为N,其中第k个分类器的融合矩阵表示为FMk,k=1,2,···,N. 则FMk可表示如式(7). 其中FMk的行代表真实类别F1,F2,···,Fn,列代表由该分类器预测出的类别F1,F2,···,Fn,元素Nikj表示由该分类器预测类别为Fj而真实类别为Fi的样本数之和. 因此对于每个分类器的融合矩阵FMk而言,矩阵的每列之和为定值1. 1)计算分类器对某个样本x的预测类别为Fj时对应Fi的基本概率分配(BPA): 2)依据D-S 融合规则计算联合BPA 值: 3)选择最大的联合BPA 值所对应的类别Fi作为最终决策: 本文所提到算法均以TE 过程数据为基础. TE 过程由伊斯曼化学公司所创建,该仿真模型在真实化工过程基础上构建[24]. 其工艺流图如图2. 该过程通过4 种气态反应物(A、C、D、E)和惰性成分B 生成产品G、H 及副产品F. TE 数据可由开源的Simulink 代码生成,数据集共包括41 个测量变量和11 个控制变量,数据除正常类型外还包括21 种不同类型的故障,本文所使用的故障类型如表1. 部分仿真结果如图3. 表1 TE 过程故障 图2 TE 过程流程图 图3 Bayes 相关算法仿真结果 图3(a)为利用Naive Bayes 进行故障分类的结果,测试集的分类正确率为62.1%,可以看出该方法在这种不平衡数据下的分类能力较差; 图3(b)为利用EasyEnsemble Bayes 的分类结果,通过EasyEnsemble将正常类样本有放回的抽取15 组,每组10 个样本并分别与故障样本组合,最终的分类正确率为65.4%,与Naive Bayes 相比略有提升,但故障1 和故障14 的识别率依然较低,说明EasyEnsemble 方法并不能完全解决数据稀缺性带来的问题; 图3(c)为利用SMOTE Bayes 的分类结果,通过SMOTE 为每个少数类增加10 个合成样本,在一定程度上弥补了少数类样本的稀缺性. 但利用这种方式对测试集的分类结果不理想,甚至低于Naive Bayes,且经实验仿真发现利用SMOTE分别为每个少数类依次增加20 个、30 个、40 个样本时,预测的准确率也几乎没有提升,其原因可能在于所使用的部分训练样本本身处于所在样本集的分布边缘,则由此及其相邻样本产生的人造样本也会处于这个边缘,且会越来越边缘化,从而使分类更加的困难; 图4(d)、图4(e)为利用K-means Bayes 的分类结果,当分类子集数k=450 时,与前几种方法相比正确率得到显著提升,预测的准确率达到了76.0%,但对故障1、6 的分类能力仍存在一定的缺陷. 图4 SVM 仿真结果 SVM 是一种经典的二分类学习算法,在使用SVM 之前,为解决多分类问题,本文选择“一对一”策略对多分类问题进行拆分,如表2 所示. 通过构建10 个子分类器,对测试集样本进行分类预测,正确率为70%,如图4 所示,且对故障1 和故障14 的分类能力差. 通过分析各SVM 子分类器的分类性能,发现C1、C4、C6、C7 及C10 这5 个子分类器对对应测试样本的分类能力差. 表2 SVM 子分类器 为克服上述5 个子分类器分类能力差的问题,本文利用AdaBoost 算法构建5 个强分类器,分别替代原SVM 的C1、C4、C6、C7 及C10 再重新进行预测,如图5 所示. AdaBoost-SVM 的最终预测正确率为80.7%,除故障14 外其余类型样本预测均比较准确,其原因为利用AdaBoost 构建的C4 分类器依然无法正确识别故障14 类型的样本. 图5 AdaBoost-SVM 仿真结果 为进一步提高分类性能,使用本文提出的决策融合算法,选择K-means Bayes 和AdaBoost-SVM 的预测结果作为证据体计算融合矩阵,并进行D-S 融合,分类正确率达到93.1%,结果如图6、图7 所示. 图6 D-S 融合仿真结果 图7 两种方法的融合矩阵 在上述2 个融合矩阵中,矩阵的行表示数据的真实标签分类,列表示利用模型的预测分类,矩阵的每一列元素和为1. 由于AdaBoost-SVM 对所有测试样本均未分类到故障14,故融合矩阵中缺少预测为故障14 的列. 表3 展示了故障分类的部分信息融合过程,根据各分类器对某个测试样本的预测结果,选择对应的融合矩阵中的数据实现数据融合. 表3 故障分类部分信息融合 本文针对不平衡数据的故障分类问题,分别提出了K-means Bayes 和AdaBoost-SVM 的分类策略. 利用K-means 对多数类的样本划分为K个子集,在不丢失多数类样本信息的前提下降低了不平衡度,提高了Bayes 的分类准确率; 利用AdaBoost 对分类能力较差的SVM 子分类器进行替换,提高了SVM 的分类准确率; 再利用D-S 证据理论对二者的预测结果进行融合,得到更好的分类结果. 由基于TE 过程的仿真结果可知,本文提出的决策融合算法与单一的传统算法相比具有更好的故障分类性能.3 决策融合算法
3.1 故障分类框架

3.2 计算各分类器的融合矩阵

3.3 基于D-S 证据理论的决策融合


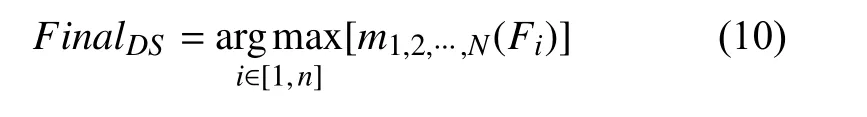
4 仿真实验
4.1 TE 过程


4.2 仿真结果及分析



5 结论与展望
