基于注意力机制的前方道路场景识别算法
2022-08-03李学伟张同宇乐海丰
温 爽,李学伟,张同宇,乐海丰
(1.北京联合大学 城市轨道交通与物流学院,北京 100101;2.北京交通大学 经济管理学院,北京 100044;3.北京联合大学 北京市信息服务工程重点实验室,北京 100101)
0 引言
由于我国机动车的保有量不断上升,而路网的建设相对缓慢,容易引起交通拥堵和安全事故[1],通过深度学习技术进行辅助驾驶成为学术界的热点话题[2]。近年来,深度学习作为一种新兴的图像处理算法,由于其具有识别精度高、泛化性能强的特点而受到广泛关注[3-4]。随着计算机性能和图像算法的发展,高性能计算机、图像加速计算单元等硬件条件的提高为深度学习提供了坚实的基础,使用深度学习方法提取图像的特征已成为计算机视觉领域的研究热点[5-6]。随着深度学习领域研究的不断深入,卷积神经网络已在多个领域得到应用,主要有图像分类、人脸识别、目标检测和无人驾驶等领域[7]。基于深度学习的任务逐渐增多,图像分类任务和目标检测任务作为计算机图像处理中常见的工作任务,也在不断促进识别技术的进步,相比于传统机器学习方法而言,深度学习方法的准确性和实用性得到有效提升[8-9]。
在图像分类任务中,卷积神经网络(Convolutional Neural Network,CNN)被广泛使用,使用二维卷积计算能够提取到图像的空间信息。基于ImageNet数据集举办的图像分类大赛ILSVRC产生较大影响[10]。随着计算技术的发展和图像数量的不断增长,各研究机构按照实际任务需求整理出各类数据集,用于解决图像分类问题的算法模型也在不断更新[11-12]。在大部分领域中,计算机的图像分类精度已取得良好效果[13]。
目前,单标签的图像分类问题可以分为以下3类:跨物种语义级别的图像分类、细粒度图像分类和实例级图像分类。跨物种语义级别的图像分类用于区别不同类别的对象,常见的分类场景有猫狗分类、果蔬分类等。在物种级别的分类任务中,由于目标对象所属的物种或者类别不同,通常其外表特征和图像语义差别较大,整体呈现出同种类别间对象差异小、不同类别间对象差异大的特征,所以可直接使用分类器对图像特征进行分类[14]。子类的细粒度图像分类一般属于同物种对象间的图像分类任务,如不同鸟类、不同花卉、不同犬类的分类等[15]。由于同种类物体通常呈现出类间差异小、难分类的特征,通用方法准确率较低,所以细粒度分类任务需要针对数据进行特殊处理。实例级图像分类需要区分不同的实例,典型的任务有人脸识别。人脸识别需要根据不同个体的人脸特征进行精准分类来识别人的身份,从而达到考勤和身份认证等功能。
道路场景识别情况较为复杂,介于跨物种语义级别的图像分类和细粒度图像分类之间,对网络实时性有一定要求。本文在研究目前主流的图像特征提取网络LeNet5[16]、ResNet[17]和VGG[18]的基础上,提出基于注意力机制的前方道路场景识别方法,提高道路场景识别的准确率,用于在行驶过程中识别道路岔口,预防与路口车辆或行人发生碰撞。
1 算法改进
1.1 ResNet残差模块
综合考虑前方道路场景图像识别的难度和对实时性的要求,本文对ResNet18网络进行改进,在尽可能不降低算法推理速度的条件下,提高识别的准确率。ResNet18通过堆叠多个残差模块构建(见图1),残差块之间有一个跳跃的残差连接,可以使网络在训练阶段避免由于网络过深出现梯度弥散而制约模型训练的精度。

图1 ResNet残差结构图Fig.1 Residual Structure Diagram of ResNet
1.2 改进后的网络模型
基于注意力机制改进的道路场景分类算法的设计分为3部分(见图2):对输入数据进行动态数据增强的预处理部分、基于空间注意力机制的特征提取网络和用于网络输出的分类器。输入数据为经过随机裁剪和Mixup混合后的增强图像,经特征提取骨干网络后得到512×7×7的特征图,最后使用全局平均池化和全连接输出分类结果。ResNet18的特征提取层主要包括5个卷积块,在网络中插入基于空间注意力机制的Attention模块(见图2虚线框部分),用于整合图像的空间信息,增强模型性能。
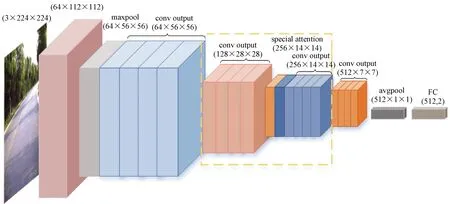
图2 改进ResNet18网络结构Fig.2 Optimized ResNet18 Network Structure
空间注意力模块结构如图3所示,将卷积块输出为256×14×14的特征图经过均值池化和最大值池化后获取两个二维特征向量,经过Concat拼接后进行卷积计算,得到一个二维空间注意力特征图,再将其与输入的特征图按元素相乘获得注意力模块输出结果。其中,普通卷积层使用ReLU作为激活函数,Attention模块中的卷积层使用Sigmoid作为激活函数。

图3 空间注意力模块结构Fig.3 Spatial Attention Module Structure
2 实验
2.1 实验环境
在实验过程中,服务器设备采用Ubuntu 20.04系统,深度学习框架为PyTorch 1.7.1,CPU为Xeon(R) Gold 6230R,内存为128 G,GPU为NVIDIA GeForce 3090×2,搭建PyTorch 1.7.1深度学习环境。PyTorch是开源的神经网络框架,在图像向量计算中针对GPU进行加速,极大地降低了图像算法的编程门槛,成为研究人员目前首选的深度学习框架。基于深度学习的图像分类流程主要包括3个部分,分别是数据准备、模型学习和测试验证。
2.2 数据集
本文的实验数据集采集自北京市的多条街道,我们将采集好的视频进行分帧后转换成图片,筛选质量较好的图片作为数据集的图片来源,包括路口和路段图像共1 551张,样例如图4所示。由于采集设备的不同导致数据差异较大,为了提升模型训练效果,对通过不同设备采集得到的图像进行统一裁剪、色彩均衡等预处理。

图4 道路场景图像数据集样例Fig.4 Dataset Example of Road Scene Image
为了防止训练过程中的过拟合导致模型泛化性能差,需要对数据集图像进行数据增强处理。根据目标任务和已有的先验知识,采用随机图像平移、水平翻转等方式处理图像,保证在目标特征不变的情况下对数据集进行扩充。增强后的数据集共有6 000张图像,随机打乱数据集顺序,并按照70%、10%、20%的比例划分为训练集、验证集和测试集。其中,训练数据在模型训练阶段用于迭代更新模型参数,验证数据用于监控模型的训练效果,测试数据用于评估模型最终的性能。
2.3 对比实验
将路段、路口照片分开后随机打乱顺序,并按比例划分数据集。模型输入图像采用经缩放后大小固定的RGB图像,缩放方法为双线性插值法。在训练和推理阶段使用不同的采样策略:在模型训练时使用随机缩放和随机裁剪,在推理验证时则使用缩放和中心裁剪策略,以提升数据多样性。在训练的初始阶段,学习率为0.001,正则化项衰减系数为0.000 1;在训练时,使用随机梯度下降法优化,每迭代50次进行一次学习率衰减,衰减系数为0.9,使模型参数进一步收敛。使用LeNet5、VGG16、ResNet18和改进的ResNet18等模型分别对场景分类数据集进行训练验证,控制试验变量,保证除模型外的其他条件均相同,训练阶段的训练损失曲线和验证准确率分别如图5和图6所示。

图5 多个模型在道路场景数据集上训练损失曲线图Fig.5 Training Loss Curve on Road Scene Dataset from Multiple Models
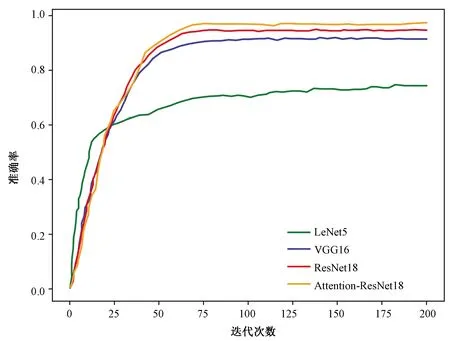
图6 多个模型在道路场景数据集上验证准确率曲线图Fig.6 Verification Accuracy Curve on Road Scene Dataset from Multiple Models
3 实验结果分析
分类准确率通常用于评估模型的好坏,准确率越高,表明分类器分类的效果越好。分类准确率的计算方法为
(1)
式中:A为准确率;Tp(True positives)为被正确划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);Tn(True negatives)为被正确划分为负例的个数,即实际为负例且被分类器划分为负例的实例数;N为分类的总样本数量。本实验将路口样本作为正例,路段样本作为负例。
在模型训练阶段结束后,对场景识别数据集中的路口和路段图像进行分类,使用3个基础模型和改进后的ResNet18模型在道路场景数据集的测试集上进行测试,测试数据均为所有模型迭代训练200次后的测试结果。模型的测试结果如表1所示。

表1 模型的测试准确率统计Table 1 Test Accuracy Statistics of Models
结合图6和表1可以看出,LeNet5由于模型结构简单,在训练前期更容易拟合数据,然而随着迭代次数的增加开始达到模型拟合上限。与VGG16和ResNet18的训练结果对比可以发现,LeNet5对于该组数据的拟合程度较低。测试结果与验证结果一致,其中,ResNet18相较于VGG16获得了更好的实验效果。由于相对于VGG16,ResNet18的参数较少,且其残差结构在训练时更容易拟合数据,所以,我们基于注意力机制对ResNet18进行了改进。最终实验效果显示,改进后的Attention-ResNet18在准确率上提升了1.2%。
4 结束语
本文使用基于注意力机制的改进卷积神经网络模型对道路场景分类进行了分析、测试和研究。由于行驶车辆对前方道路场景识别的实时性要求较高,本文对比分析了多种主流深度学习算法,对网络规模较小的ResNet18模型进行改进,并加入空间注意力模块进行优化,提高了图像识别的准确率,从而提升模型分类效果。实验结果表明,在复杂交通路况下,基于注意力机制改进后的ResNet18模型在道路场景数据集上的识别准确率达到91.5%。实验对3种经典的卷积神经网络模型和基于注意力机制改进的模型进行对比讨论,并分析了模型结构与数据预测的相关内容,我们后续将不断优化方法,达到在实际场景下辅助驾驶的效果。
