一种增强的多粒度特征融合语义匹配模型
2022-08-02尚福华蒋毅文曹茂俊
尚福华,蒋毅文,曹茂俊
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
文本语义匹配是目前自然语言处理领域中一个重要的任务分支,也是自然语言处理中重要的研究方向和研究热点,在信息检索、问答系统、机器翻译等任务中起到了核心作用。
正因为语义匹配的重要性,国内外许多学者都在语义匹配上作了许多研究。传统的匹配模型主要基于人工提取的特征以及基于统计机器学习的方法,如BM25模型、PLS、SMT模型、WTM模型等。这些模型主要解决文本表层的匹配问题[1],但难以捕捉文本所表达的深层含义。随着神经网络的火热发展,人们发现基于深度学习的模型在语义匹配任务中取得了更好的效果。因此关于语义匹配的研究热点已逐渐转移到深度学习语义匹配模型。庞亮等人[2]将目前的基于深度学习的语义匹配模型分为三种,第一种是基于单语义文档表达的,主要将待匹配的两个文本通过深度学习的方式表达成两个向量,再通过计算两个向量之间的相似度便可得到匹配度。如ARC-I、DSSM模型。第二种是基于多语义文档表达的,综合考虑文本的局部性表达(词粒度信息、短语粒度信息)和全局性表达(句粒度信息),通过这样多层级多粒度的匹配可以很好地弥补基于单语义文档表达的深度学习模型在压缩整个句子过程中的信息损失,而达到更好的效果。如MultiGranCNN、MV-LSTM等。第三种则是直接建模匹配模式的。这种模型从多角度提取文本间的深层交互信息,并认为对文本间的交互学习应该早于文本的表示学习之前,一方面是为了避免损失信息,另一方面通过这种方式能够得到更丰富的语义表示,利于后面的学习。典型模型有ARC-II、ABCNN、BiMPM、ESIM、DIIN等。Pair-CNN模型是文献[3]所提出的,利用CNN完成短文本的匹配任务。ABCNN[4]则是在此基础上加入注意力机制形成的。文献提出双向多视角匹配模型BIMPM[5]模型,对比了多种不同注意力机制的匹配策略。ESIM[6]模型本身是用于自然语言推理任务,但稍加改造后就能用于文本匹配等任务。
目前这些模型表现优异,但仍存在一定的不足。首先,这些模型大多是以词作为语义单元并基于静态词向量(Word2Vec、GloVe等)来获取句子表示,对于英语来说,它的最小语义单元是单词,因此适用于这样的方法。而中文语言显然更加复杂,中文分词、语义信息等要素直接影响了语义匹配的效果,而汉语中单个字也承载着一定的语义[7],因此只考虑词作为语义单元不一定能取得更好的效果,需要考虑多种语义单元在句子建模中的作用。此外静态词向量一旦训练完成,相同的词的向量表示是不会再随语境变化而变化的,因此这一类词向量难以解决一词多义问题[8],且不能表征词性等语法特征。因此如何获得更准确的句子嵌入表示仍是现在的研究重点。其次,模型在交互时往往都是在词级别上进行交互,如ESIM模型在提取文本的交互特征时只是基于词进行注意力交互,未能挖掘文本更深层的交互信息。而句子是具有一定的层级关系的,如果忽略了语言颗粒度对句子建模的影响,那么得到的交互信息也是不充分的。最后,一些模型通过使用多种注意力机制来提升模型效果,如BIMPM采用了四种注意力匹配策略来提取更多的信息,但是对于多种交互结果往往只是采用简单的concat方式。对于如何正确组合优化多种注意力信息考虑甚少。
针对以上问题,该文提出一种增强的多粒度特征融合语义匹配模型EMGFM。主要工作如下:
(1)为避免由于中文词边界模糊而带来的影响,同时考虑中文中单个字所包含的语义信息,该文将字向量与词向量进行混合使用,在字向量的获得上,利用BERT模型强大的语义表达能力获取中文字符向量,从而更好地表征字符的多义性,而词向量选用Word2Vec进行获取。最后将两种向量进行拼接得到增强的字符向量。(2)为解决只考虑词交互带来的交互特征单一问题,对文本的不同的粒度(字、词、句)进行注意力交互特征提取,因为不同粒度的信息提取关注重点各有不同,为了综合利用多种方法,最大程度上完全提取信息,设计了一种融合多种交互信息的方法。该方法利用注意力思想衡量每种交互信息的重要性,而且不会因为直接连接导致向量维度过高,可以有效减少模型计算的复杂性。并通过原始信息与融合后的信息进行点乘相减等操作来构造差异性,以达到语义增强的效果。(3)针对语义匹配提出了增强的多粒度特征融合语义匹配模型,实验结果表明,提出的方法能有效提升问句语义匹配的准确性。
1 增强的多粒度特征融合语义匹配模型
1.1 问题定义与分析
给定待匹配样本Sample={H,T,similarity},其中H、T为待匹配的两个短文本,similarity为两个文本之间的相似度,一般为0或者1。当similarity=1时表示两个文本语义相似,similarity=0则反之。该文的目标就是训练一个语义匹配模型M,使得对任意的两个句子,M能够合理给出其相似度的评判。
1.2 模型结构
整个模型结构如图1所示,模型主要包含编码层、交互层、语义组合层、输出层4个主要部分。
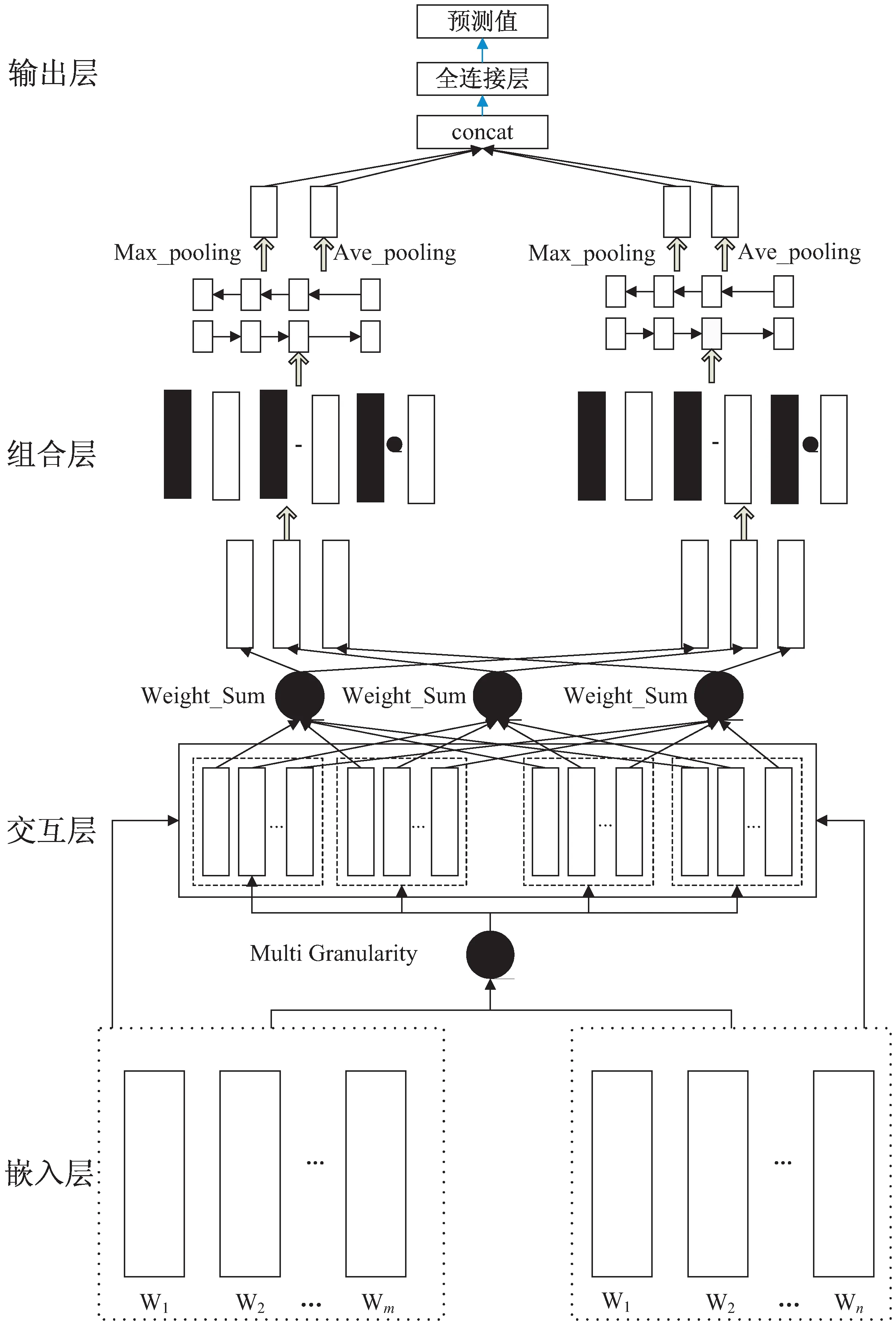
图1 模型结构
首先在嵌入层将待匹配的两段文本转换为文本向量,在交互层利用可分解注意力机制,从三种粒度(字、词、句)分别计算两段文本的注意力权重,从而得到两段文本在不同粒度下的注意力加权表示。然后对不同粒度下的注意力加权表示进行融合,并利用原始信息对其进行信息增强,最后经过平均池化和最大池化处理后传入一个多层感知机进行输出。
1.2.1 编码层
(1)BERT预训练模型。
BERT是一个语言表征模型(language representation model)[9],基于多层Transform实现,通过Transform结构获取到字符向量可以充分利用上下文信息,更能表达多义性。因此,选用BERT预训练模型来获取文本的字向量表示。
(2)输入表示。
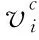
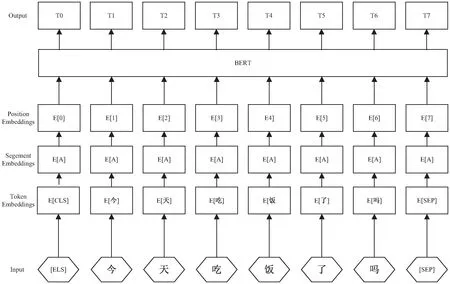
图2 BERT输入表示
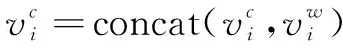
(1)
经过上述操作,最终将输入的句子A、B嵌入表示为:
(2)
(3)
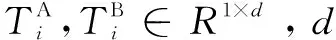
1.2.2 交互层
大量的实验证明在句子特征提取完成后才进行句子之间的交互,势必会浪费一些特征信息,而对待匹配的文本先进行交互再进行后续学习会取得更好的效果,并且更丰富的语义交互能为后续网络学习带来更多信息,匹配效果更好。如吴少洪等人[10]从不同的方面提取文本更深层的交互信息,取得了不错的效果。受这些工作的启发,增加更细粒度的文本交互,旨在获得更丰富的语义交互信息。
(1)可分解注意力机制。
综上所述,该文在将特征向量送入后续网络之前,参考可分解注意力机制[11]的做法,对句子进行不同粒度的对齐,使得句子间的关系特征得以保留。以下先介绍可分解注意力的计算过程:
Step1:首先对句子A、B中的每个词,通过F函数计算它们的注意力权重矩阵eij,F函数选用的是向量的点积。
(4)
Step2:使用注意力权重矩阵对句子a、b中的每个词进行注意力加权求和。
(5)
(6)
(2)字粒度的交互。
通过1.2.1的操作即可将输入的两个句子A和B各自转化为m*n的嵌入矩阵EA、EB,其中m为句子的字数,n为字向量的维度。因为BERT是基于字的模型,因此输出即是每个字的字向量,因此可直接对其进行字粒度的交互,使用上文提及的注意力交互方式可得到关于句子A和B的基于字粒度的交互矩阵CIA、CIB。
(3)短语粒度的交互。
大量实验证明长短语级别和短语级别的特征对句子的建模十分关键,CNN因其独特的网络结构在捕捉句子的局部特征上具有天然优势。参考文献[12]中的做法,该文在抽取局部特征时兼顾不同数量字组成的短语,选择二元(two-gram)、三元(tri-gram)进行特征提取。具体做法如下:
Step1:不同长度短语特征提取。
将1.2.1得到的句子嵌入矩阵A、B分别输入卷积神经网络进行卷积操作,卷积核的宽度与字嵌入维度一致。为保证卷积操作前后维度保持一致以便于后续网络学习,对A、B进行零向量填充后再进行卷积,以二元提取特征为例,卷积核的高度设置为2,得到的卷积结果可以表示为:
Two_CA=two_gram_CNN(A)
(7)
Two_CB=two_gram_CNN(B)
(8)
其中,CA∈Rla×1×K,CB∈Rlb×1×K,la、lb分别为句子A、B的长度,K为卷积核的数目。
Step2:提取交互信息。
对Two_CA、Two_CB进行注意力交互计算,分别得到文本A、B关于不同长度短语粒度的特征提取矩阵Two_CA、Two_CB、Tri_CA、Tri_CB。
(4)句子粒度的交互。
注意力机制能突出每个句子语义特征最明显的部分[13],该文应用注意力机制来捕捉文本的上下文信息特征,最基本的注意力机制主要分为两种,一种是由Bahdanau[14]提出的加法注意力机制,另外一种是由Luong[15]提出的乘法注意力机制。
该文对编码层输出采用Bahdanau提出的加法注意力机制,具体计算主要分为以下三步:
Step1:将query和每个key进行计算得到注意力得分score,以某个时间步输出ht为例,计算注意力得分at:
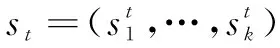
(9)
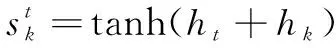
(10)
Step2:使用一个SoftMax函数对这些权重进行归一化,如下式所示:
(11)
Step3:将权重和相应的键值value进行加权求和得到最后的attention,如下式所示:
(12)
目前在NLP研究中,key和value常常都是同一个,即key=value。在文中,key和value取值为编码层的字向量输出,通过上述计算得到基于注意力加权的表示SA_A、SA_B,再将SA_A、SA_B经过注意力交互计算即可得到句子A、B关于句子粒度交互的特征矩阵sen_A、sen_B。
1.2.3 组合层
在实际模型中,经常会将不同的特征组合起来一同使用,全面获取信息,来达到提升模型性能的目的,然而大多数模型在组合不同的语义信息时都使用了简单的concat方式,使得维度过大,模型计算量变大,无法有效衡量各种语义信息的重要性。该文创新性提出一种融合注意力方法来解决这个问题,具体内容如下文所述:
(1)聚合交互信息。
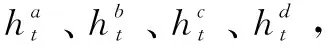
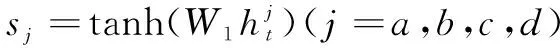
(13)
(14)
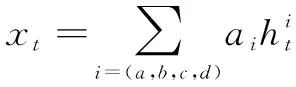
(15)
通过上述计算,得到句子A、B的聚合交互信息表示AG_A、AG_B。
(2)交互信息加强。
得到聚合交互信息表示后,使用下式进行信息增强,目的是为了构造与原有信息的差异性,便于网络后续学习。
eh_A =[EA,AG_A,EA-AG_A,EA⊙AG_A]
(16)
eh_B =[EB,AG_B,EB-AG_B,EB⊙AG_B]
(17)
其中,EA、EB分别为句子A、B的句嵌入原始矩阵,AG_A、AG_B分别为其聚合交互信息表示,eh_A、eh_B即为AG_A、AG_B经过信息增强后得到的结果。
(3)池化。
该文为最大限度保留上文提取到的特征,综合使用平均和最大两种方式来进行池化,并将两种pooling得到的向量concat起来。池化过程如下式所示:
(18)
(19)
V=[Va,ave,Va,max,Vb,ave,Vb,max]
(20)
其中,Va,i为增强信息经过BILSTM后每个时间步的输出。
1.2.4 输出层
通过池化得到的向量经过全连接层作最后分类输出,其计算公式如下式所示:
(21)
sim(A,B)=argmax(yi)
(22)
其中,yi是模型对应每个分类的输出值,argmax则是取最大输出值对应的类别值,sim(A,B)即为两个句子最终的相似度。
2 实验设计
2.1 数据集构造
实验数据来源于CCKS2018评测项目中的微众银行客户问句匹配大赛数据集,共包含182 478个句子对,测试集包含10 000个句子对。若句子对语义信息相同,则对应的标签为1,否则为0,训练集样本实例如表1所示。

表1 部分训练数据集样本
2.2 实验设置
实验选用的深度网络框架是tensorflow2.3,字向量模型选用的是BERT模型中预训练好的bert_zh_L-12_H-768_A-12模型,句子最大允许长度为样本集中所有样本的最大长度,batch大小设置为20,epoch设置为15,优化方式为Adam,损失函数选用的是多分类常用的交叉熵损失函数。静态词向量模型经由维基百科中文语料(1.42 G)训练而成,该语料包含342 624个词,维度为300。实验选用准确率来衡量模型的性能,准确率的计算如下式:

2.3 模型验证
为了验证提出模型的有效性,对照实验模型采用Siamese-LSTM、Siamese-CNN、ESIM、MatchPyramid。其中各模型最终评测结果如表2所示。

表2 各模型准确率比较
各模型在各批次的损失及准确率变化如图3、图4所示。
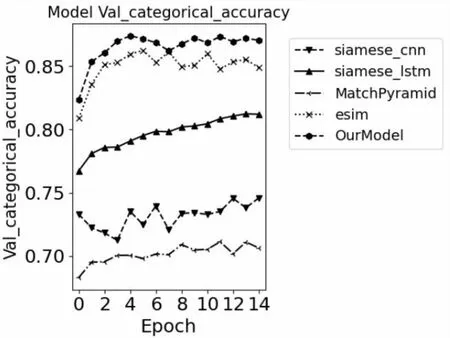
图3 各模型准确率对比
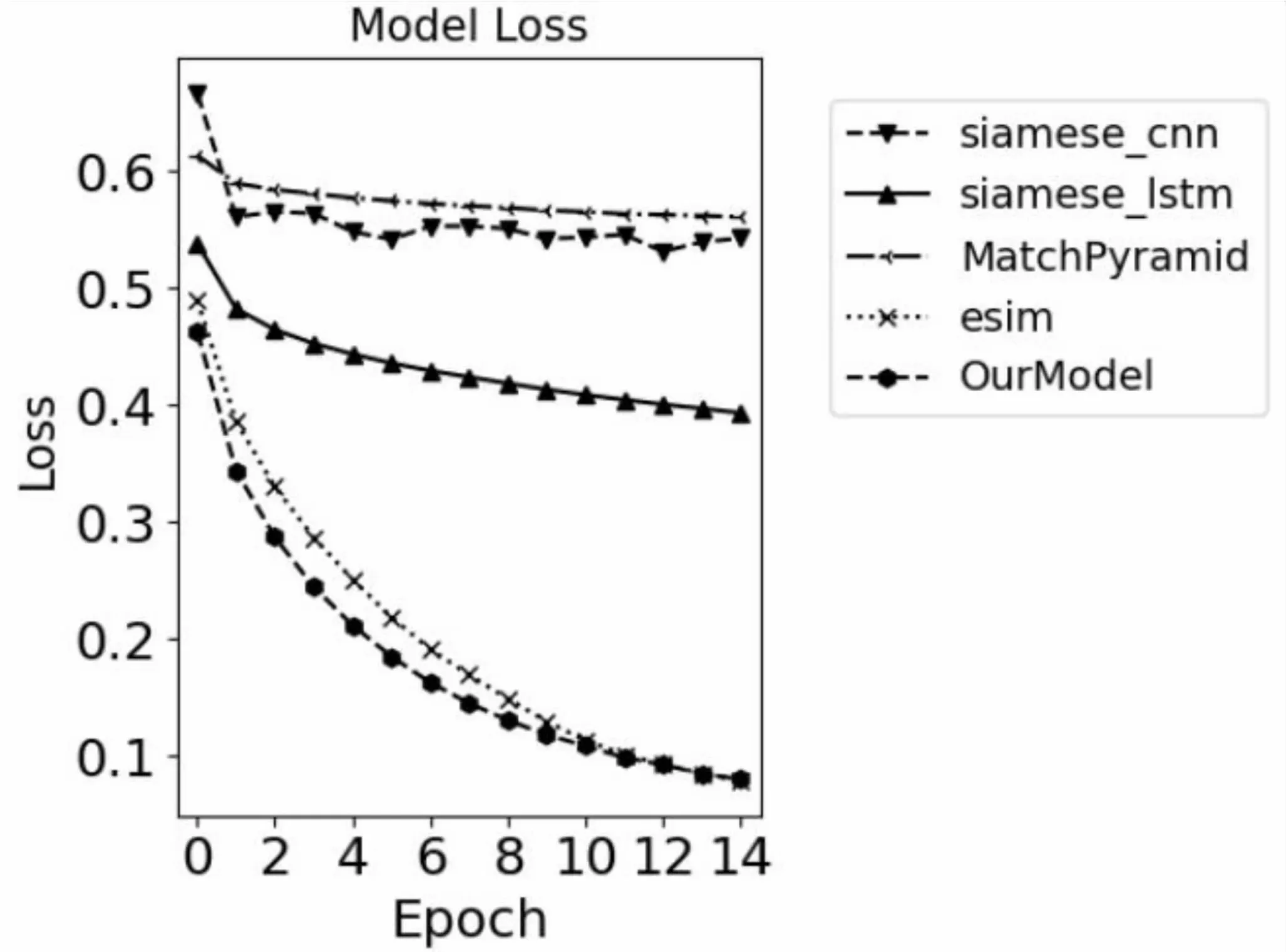
图4 各模型损失值对比
2.4 实验结果分析
从表2可以看出,该文提出的模型相较于其他传统文本匹配模型表现较好,取得了87%的准确率,相较于对比模型中表现最好的ESIM模型大约有2%的提升,其中直接建模匹配的模型要比直接表示型的模型效果要好,这是因为CNN、LSTM等仅从文本本身进行语义建模,而忽略了文本之间的联系。而基于LSTM的Siamese模型要比基于CNN的Siamese特征提取能力强,这是因为LSTM在文本等序列建模问题上有一定优势,具有长时记忆功能,能够捕捉文本的长程依赖。ESIM虽然在语义建模之前进行了注意力的交互以保留一些重要的文本特征值,并在后续中进行局部信息增强等操作来丰富语义信息,但总的来说ESIM只对词粒度进行了交互,而对中文来说考虑显然不够。从颗粒度特征提取来看,无论是CNN、LSTM还是ESIM都只是基于单一特征的提取,而该文提出的模型综合了多个粒度的交互信息,因而取得了更好的效果。
从图4可以看出,Siamese-CNN、Siamese-LSTM、MatchPyramid在训练过程中Loss下降缓慢并逐渐近于平缓,这也导致正确率无法得到有效提升。提出的模型在训练中的Loss虽然最终和ESIM趋向一致,但是模型在训练过程中的下降速度上表现出色,在更少的批次就能达到比较好的效果,这也验证了文中模型结构的优越性。
2.5 模型应用
将提出的模型最终应用于CIFLog大型软件平台开发知识问答中,首先建立软件平台开发知识图谱作为问答数据支撑,同时人工构建问句模板库,然后通过命名实体识别等技术对用户的问句进行处理后,使用文中模型找到相似度最高的模板以完成答案的检索。整体效果如图5、图6所示。
图5 用户进行提问

图6 模型应用问答效果
3 结束语
针对传统模型存在的不足提出了相应的改进。探寻了更细的语言颗粒度在中文语义交互中的作用,较好地解决了句子交互特征不充分的缺点。同时在组合层中使用注意力机制和构造差异性方法来对交互信息进行融合增强,在最大程度保留交互特征的同时降低了模型的参数计算量,有效地提升了模型的性能。但是,从模型对语言的适用性来看,实验是在中文数据集上进行验证,因此在以后的工作中将尝试在英文数据集上进行实验,以验证模型是否具有普适性。同时,在实际的应用场景如问答中,发现模型的计算时间稍长,这不利于体验。因此在以后的工作中,也将进一步优化模型的执行效率,同时还需研究更多情形下的细粒度特征抽取方法,以寻求更高性能的语义匹配模型。
