基于深度学习和支持向量机的文本分类模型
2022-08-02管有庆
何 铠,管有庆,龚 锐
(南京邮电大学 物联网学院,江苏 南京 210003)
0 引 言
NLP(Natural Language Processing,自然语言处理)作为人工智能的子领域,其研究的重点在于实现人与计算机之间的信息交互,让计算机能够理解使用人类的语言[1]。自然语言作为人与人进行交流沟通的重要工具,常用的语言包括英语、汉语、俄语等。自然语言处理主要针对词语、段落或者篇章进行处理。主要使用的方法分为基于规则和基于统计两种。基于规则的方法是根据语言相关的规则人工对文本数据进行处理;基于统计的方法是通过大规模的数据集统计分析[2],最终实现对文本数据的处理。数据集的好坏对自然语言处理模型的性能有着很大影响。所以,拥有强大的数据支撑才可以更好地对文本进行进一步的处理和分析。基于中文的自然语言处理主要研究的内容包括分词、词性标注、词义消歧、文本分类和语言建模等,但由于机器学习的文本分类算法较为强调文本中特征词语的选取,且属于浅层学习方法,不能有效地继续深层挖掘分类信息[3],基于神经网络的深度学习算法应运而生。其中,基于深度学习的卷积神经网络模型,作为机器学习的一个重要分支,在文本分类领域取得了不错的效果。将CNN(Convolutional Neural Network,卷积神经网络)模型应用于文本分类,只需要将完成预处理的文本集导入输入层,通过模型训练,将自动生成特征词语,大大简化了特征词语的选取。随着自然语言处理技术的不断发展,文本分类算法的研究也取得了巨大的突破。文本分类由最初依靠人工进行规则提取的方式,转向基于机器学习的自动分类方式[4]。通过机器学习方法提取文本规则进行自动分类,将机器学习算法应用到文本分类领域中。例如支持向量机[5]、神经网络[6]和决策树[7]等机器学习领域的重要算法,在文本分类领域都得到了广泛的应用。已有的CNN-SVM(Support Vector Machine,支持向量机)的文本分类算法中,文献[8]将传统的卷积网络更改为5个平行放置的CNN模型进行训练,最后采用SVM分类器输出结果。而文献[9]的CNN网络采用一维卷积提取特征,将经过最大池化处理的特征通过一对多的SVM分类器得出结果。文献[10]中CNNSVM模型使用了一种特殊的卷积模块,通过一维卷积减少输入通道数、卷积核参数以及计算复杂度,与文献[9]相似,依然是构建SVM多分类器来获得分类结果。
该文提出一种将CNN与SVM分类算法进行结合的改进模型CNNSVM。该模型一方面使用SVM替换传统CNN中的softmax归一化函数实现模型的分类功能,以便解决原模型泛化能力不足的问题;另一方面,相比于传统CNN模型,CNNSVM模型增加了注意力机制[11],该机制的作用是对特征词语进行精炼,选取类别代表性更强的特征词语,以提升模型分类的准确度。
1 CNNSVM模型
CNN模型最初被应用于图像识别[12]和语音分析[13]领域。近年来,随着NLP技术的蓬勃发展,深度学习中的CNN模型越来越多地被应用于文本分类[14]和情感分析[15]领域。传统CNN模型一般是由输入层、卷积层、池化层、全连接层和输出层构成。其中,卷积层作为CNN模型中十分重要的一层,卷积层设计的成功与否将直接决定CNN模型的分类效果。CNN模型发展自神经网络,CNN与传统神经网络最明显的区别在于CNN模型中的卷积层和池化层。在传统神经网络模型中,相邻的两层隐藏层往往通过全连接的方式进行相连。这就会导致隐藏层与隐藏层之间的权重参数数量十分巨大,随着隐藏层中权值的不断更新,整个神经网络的运行速度也会受到很大的影响。为解决这一问题,CNN模型在传统神经网络模型的基础上,增加了卷积层与池化层。通过卷积层与池化层替代部分全连接层,并且依靠CNN模型特有的权值共享和局部感知野特性,达到简化模型的运算,提升模型训练效果的目的。
CNN模型最初被应用于图像识别领域,由于图像数据是由像素点矩阵构成,矩阵中的像素点具有稠密性,便于直接用于CNN模型进行训练。而在进行文本分类时,则需要将原本高维且稀疏的词语进行向量化,使之映射到低维且稠密的词向量空间中,才能进行模型训练。同时,传统CNN模型使用softmax层作为输出层,该层的本质是一层全连接层,作用是将特征词语通过线性组合的方式计算出不同类别的概率,最终实现分类。由于softmax层在针对非线性且稀疏的数据时,其分类效果不如基于传统机器学习的分类算法[16]。针对这一现象,提出了基于CNN模型与SVM分类器组合的CNNSVM模型。该模型使用基于有监督学习[17-18]的SVM分类器实现文本分类,CNN模型实现特征词语的选取,从而达到简化特征提取的目的。
除此之外,CNNSVM模型相比于传统CNN模型还增加了注意力机制[19]。注意力机制源于人类感官的研究,听觉、视觉、触觉和味觉都存在注意力。在通过感官进行信息处理时,人类往往会选择性地屏蔽掉一些不重要可以忽略的信息,而将更多的注意力投入在认为是重要的信息上。该技术在RNN(Recurrent Neural Networks,循环神经网络)和图像领域已经有了较为成熟的应用,在文本分类领域的应用还在探索阶段。
1.1 网络模型结构
CNNSVM模型在传统CNN模型的池化层之后,增加注意力层,该层的主要作用是进一步提升特征词语的选取,通过更新特征词语的权重,从而选取出更具有类别区分能力的特征词语。CNNSVM模型的具体结构图如图1所示。

图1 CNNSVM模型结构示意图
输入层:使用训练集中不同类别的文本作为输入,进行CNN模型训练。在将文本导入输入层之前,需要针对文本进行预处理操作。预处理操作包括分词、去停顿词和词语向量化处理。不同于机器学习文本分类常常使用独热编码[20]进行词语向量化,CNN模型使用基于Word2vec工具的CBOW[21](Continuous Bag-of-Words,连续词袋)模型进行词语向量化。
卷积层:是CNN模型中十分重要的一层,主要通过局部感知和权值共享两个特性来完成特征词语的选取工作。
池化层:主要工作是对卷积后的数据进行降维,从而实现特征的进一步提取。使用池化函数调整这一层的输出,从维数较高的特征词向量中提取成维数较低的文本特征向量,来替代网络在该位置的输出。常见的池化方式有最大池化和平均池化,即提取局部特征向量的平均值和最大值。
1.1.1 注意力层
注意力机制源于人类视觉,通过视觉对图像进行全局扫描,人类往往会选择性地屏蔽掉一些不重要可以忽略的信息,而将更多的注意力投入在认为是重要的信息上,也称为注意力焦点。深度学习中的注意力机制本质上与人类的选择性视觉注意力机制类似,主要目的是将有限的注意力资源投入到对当前任务更为重要和关键的信息上。在文本分类的应用环境下,可以理解为将更多的权重赋值在对文本类别区分有影响的特征词语或句子上。同时,对于类别区分意义较小的特征词语或句子可以减少其权重。
在CNNSVM模型中,卷积层与池化层通过对输入层词向量的训练,完成特征词语的初步提取与降维工作。在池化层之后加入注意力层,可以更好地对特征词语进行提炼,提取对类别区分能力更强的特征词语。同时,减少类别区分能力较弱的特征词语,简化模型的参数。注意力机制的原理基于“编码器-解码器”结构,类似于计算机数据结构中的“键-值”结构。“编码器-解码器”结构如图2所示。
在图2中,输入数据X={x1,x2,…,xn},输出数据Y={y1,y2,…,yn},s1,s2,…,sn表示解码器的隐藏状态。将编码过程设为En,解码过程设为De。其中输入数据X在完成编码后变为中间语义Mid。编码过程可以表示为:

图2 “编码器-解码器”结构
Mid=En(x1,x2,…,xn)
(1)
解码过程实际是将中间语义Mid解码,可以表示为:
yn=De(y1,y2,…,yn-1,Mid)
(2)
由式(2)可以看出,在求解输出yn时需要使用中间语义Mid和前n-1项的输出值。并且在计算每项输出时,所使用的中间语义保持不变。那么,由于编码器和解码器使用中间语义Mid作为信息传递的唯一桥梁,便存在着两点弊端:首先,中间语义由输入序列计算而得,若输入序列中存在类别区分能力较弱或对文本分类无帮助的噪声词语时,会影响模型的分类能力。其次,由于y1的数值将对y2,y3,…,yn-1的求解产生影响,从而导致词语输入序列的先后顺序就显得尤为重要。
为弥补“编码器-解码器”框架中的两点不足,Bahdanau等人提出了基于注意力机制的“编码器-解码器”模型,结构如图3所示。
在图3中,X={x1,x2,…,xn}来代表输入数据,Y={y1,y2,…,yn}来代表输出数据。在增加了注意力机制的“编码器-解码器”模型中,不再使用统一不变的中间语义Mid,取而代之的是c1,c2,…,cn,n个不同的中间语义进行表示。cn的数值是由注意力权重对所有编码器的隐藏状态进行加权求和得到。其中,注意力机制的具体结构如图4所示。
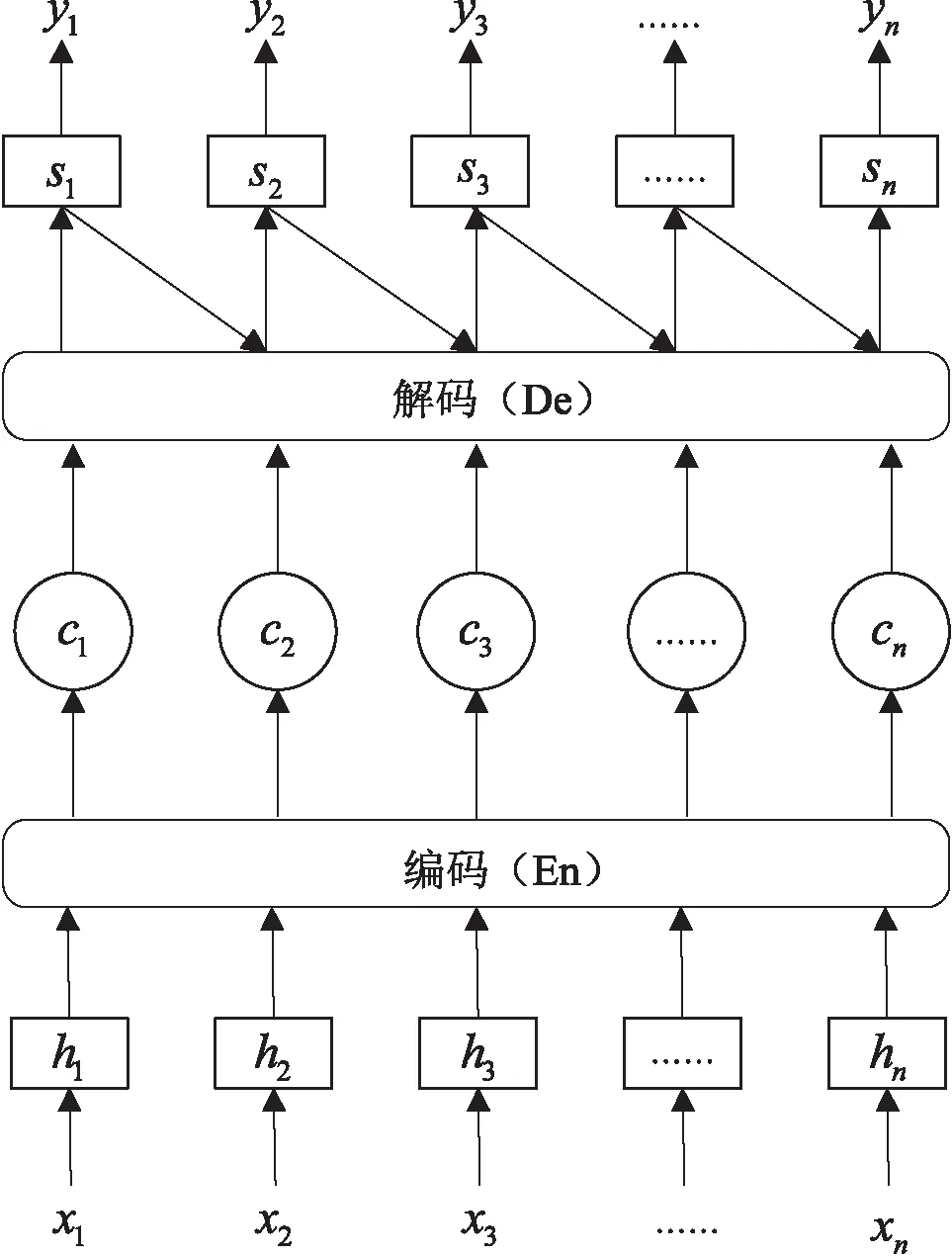
图3 基于注意力机制的“编码器-解码器”模型
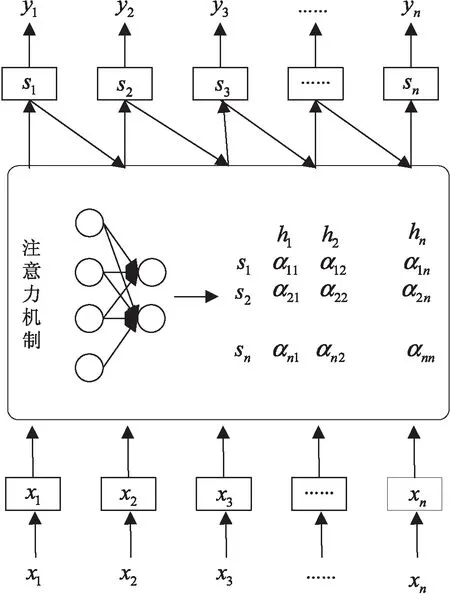
图4 注意力机制结构
图4中,每一个输入数据xj进行编码后将变成一一对应的编码器隐藏状态hj,注意力模块能够自动地学习权重αij。通过αij来体现编码器隐藏状态si与解码器隐藏状态hj之间的相关性。中间语义cj的数值是由注意力权重对所有编码器的隐藏状态进行加权求和得到的,假设输入序列的个数为n,那么计算cj的公式为:
(3)
注意力机制通过对输入数据的不断训练,调整αij的权重值,从而提高对类别区分能力较强的特征词语的权重,最终达到提升整体分类效果的目的。除此之外,通过减小不重要特征词语的权重,可以降低文本中非重要信息的影响力。
1.1.2 全连接层
全连接层采用全连接方式进行连接,即每个神经元都与上一层所有的神经元进行连接。由于采用全连接方式,所以全连接层涉及到的参数会非常多。在CNNSVM模型中,全连接层在注意力层之后,使用注意力层的输出作为输入。为了提升卷积神经网络的性能,全连接层一般选择ReLu函数作为激活函数。全连接层在模型中最主要的功能是起到“分类器”的作用,传统CNN模型将全连接层与softmax层结合完成分类。使用CNN模型进行文本分类时,由于输入数据为非线性且稀疏的词向量,针对这类数据,SVM相较于softmax层有着更好的分类效果。所以在CNNSVM模型中,使用SVM分类器对softmax层进行替换,实现最终的文本分类。CNNSVM模型的全连接层框架如图5所示。
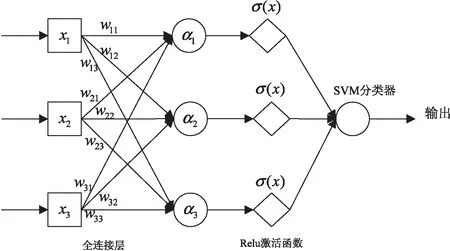
图5 全连接层结构示意图
图5中,每一个神经元都与上一层神经进行连接。全连接层通过向前计算和反向传播的方式来不断更新权重系数W,使得模型达到预先设置的阈值。在全连接层中使用ReLu激活函数可以提高神经网络对模型的表达能力,解决线性不可分问题。
1.2 重要参数设置
1.2.1 词向量维度
在预处理阶段需要将文本数据集进行分词、去停用词和向量化处理。CNNSVM模型使用Word2vec工具中的CBOW(Continuous Bag-of-Words,连续词袋)模型进行词向量的训练,具体训练过程见1.2.2小节。在进行词向量训练时,确定词向量的十分重要。当词向量的维数过高时,会使系统的运算次数和运行时间增加;当词向量维数过低时,不能很好地体现词与词之间的近似关系和类别差异,影响模型进行文本分类的效果。在类似于百度百科词条和维基百科等量级较大的语料库中,词向量的维数常在300到500。在某些特定领域的语料中维数常在200以内。实验中,分别通过测试32、64、128和256维,研究词向量维数对精确率和训练时间的影响,从而能兼顾二者的维数进行实验。基于不同的词向量维度,实验结果如图6所示。

图6 词向量维度与分类精确率和模型训练时间的关系
从图6可以看出,随着词向量维度的增加,模型训练的精确度也在不断增加。同时,模型训练所需要的时间也在不断增加。通过精确率和训练耗时的斜率可以看出,当维度从64提升到128时,精确率增加了0.4%,但训练时间却增加了约69.3%,这样的代价并不合适。所以,在实验中需要根据不同数据集来选取合适的词向量维度。鉴于所用的数据集,当词向量度从64维提升到128维时准确率只是轻微提升,所以本实验中将词向量的维度选择为64维。
1.2.2 文本序列长度
模型所能输入的最大序列长度也将对模型时间的分类效果起到一定的影响作用。因此,在要针对文本序列的长度进行调整,以便CNNSVM优化模型能够更好地进行文本分类。当文本数据作为输入进入卷积神经网络模型进行训练时,需要先将文本长度与预先设置的最大长度进行比较。若文本长度大于预先设置的阈值,按阈值将文本分割成若干个文本,文本长度小于阈值时,需要使用空格字符进行填充。通过实验进行分析,确定最佳的阈值长度。具体实验结果如图7所示。

图7 确定最大文本序列长度
在图7中可以看出,最大文本序列长度过低,会导致模型无法捕捉足够的数据特征,精确率降低;当最大文本序列长度过大,会导致系统出现过拟合的情况,同时也会导致模型训练时间过长,精确率也会出现降低和不稳定的情况。综上,实验中将最大文本序列阈值设置为600。
1.2.3 模型中其他参数
在构建CNNSVM模型的过程中,除了确定词向量的维数和输入的最大文本序列长度外,还有许多参数需要预先设置,再次进行说明:
通过1.2.1和1.2.2节可以确定词向量维数为64,输入的最长序列长度为600。CNNSVM模型中,卷积核的长度为5,卷积核个数为256,卷积核宽度与词向量维数一致为64。实验使用的数据集包括训练集和测试集,文本种类为8。全连接层神经元个数为128。为防止模型出现过拟合,加入dropout层,其中dropout保留参数为0.5。过拟合是指模型过分依赖训练集中的特征数据,使用训练集进行测试时分类的准确率很高,但当运行新的数据集时,分类效果差别较大。
2 实验结果与分析
为评估该算法的性能,在相同数据集的情况下,使用传统CNN模型、CNN与NBC分类器结合的模型与该文提出的CNNSVM模型进行对比实验。通过精确率和召回率进行分析。
精确率是指正确分类的文本占所有文本的百分比,其定义如式(4)所示:
(4)
其中,TP表示分类正确的文本,(TP+FP)表示被正确分类的文本和被错误分类的文本。
召回率作为一项评估文本分类系统从数据集中分类成功度的指标,用来体现分类算法的完备性,数值越高代表算法的成功度越高。具体定义如式(5)所示:

(5)
其中,TP表示被正确分类的文本数量,FN表示应当被分到错误类别中的文本的数量。
实验是在安装了Windows10专业版操作系统,内存为16 GB,CPU主频为2.8 GHz的PC机上进行的。主要使用的软件环境是基于Python3.6.7内核和Pycharm 2018.12.5版本。具体实验结果如图8和图9所示。
图8和图9中,CNN-NBayes代表CNN模型与NBC分类器结合的文本分类模型。从精确率和召回率这两个指标来看,CNNSVM的结果相比于传统CNN模型和CNN与NBC分类器结合的模型要好一些。传统CNN模型的分类效果不如CNN-NBayes,但是相比于传统的机器学习分类算法来说,准确性要更好一些。原因在于基于卷积神经网络的分类模型可以更充分地对文本的特征进行提取,因而获得了更好的特征词向量,使得模型最终的分类效果有所提升。

图8 不同分类算法的精确率
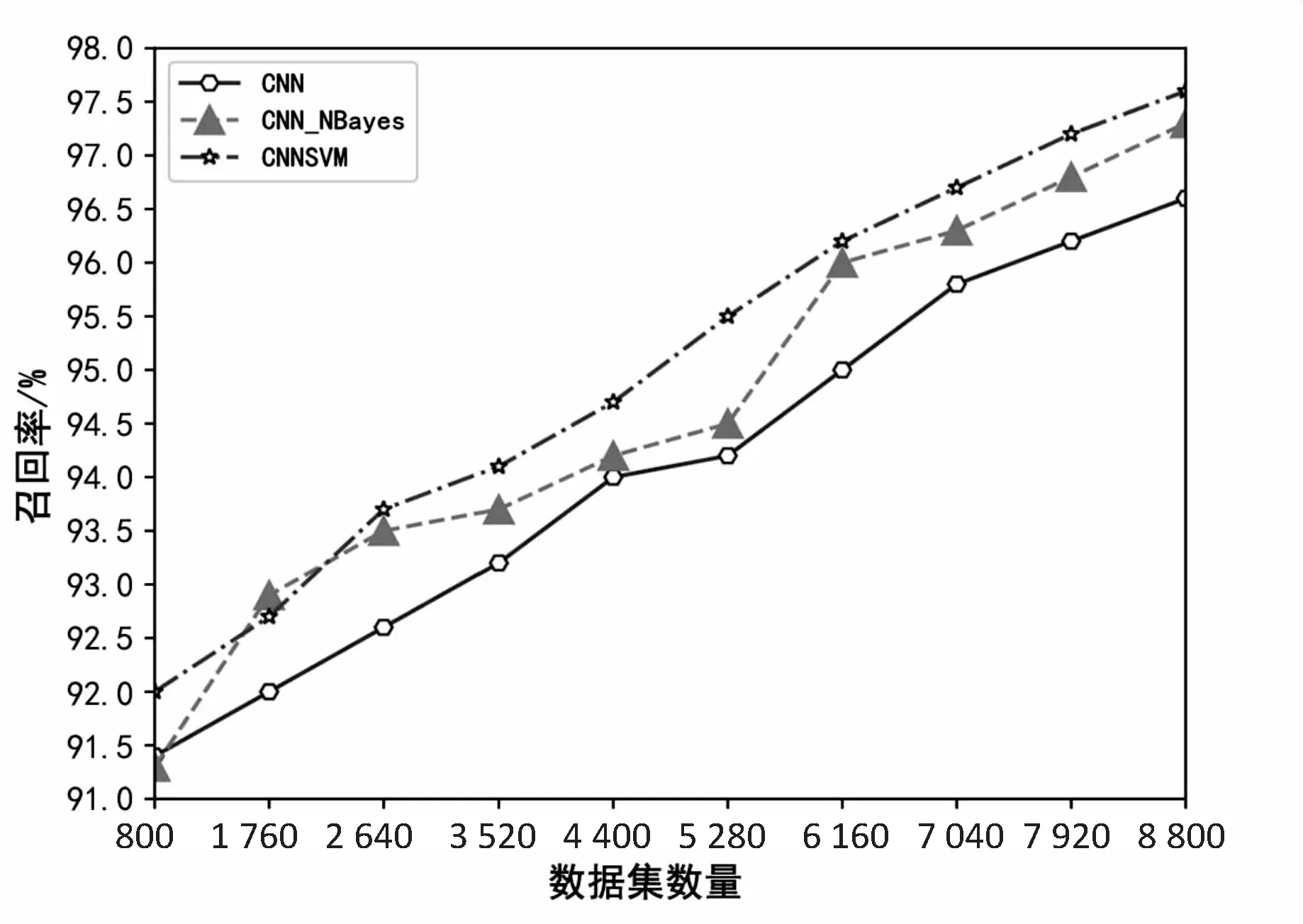
图9 不同分类算法的召回率
3 结束语
提出了一种基于CNN与SVM相结合的文本分类模型,即CNNSVM模型。该模型主要使用SVM分类器替换传统CNN中的softmax归一化函数实现模型的分类功能,以解决原模型泛化能力不足的问题。其次,相比于传统CNN模型,CNNSVM模型增加了注意力机制,提高了模型对特征词语的选取能力,同时也减少了模型参数数量。相比于传统CNN模型,提升了模型分类的准确性和运行效率。
