一种延误航班旅客动态成行需求量预测算法
2022-07-20景一真赵耀帅傅之凤
景一真,赵耀帅,傅之凤,吴 格
(1. 北京交通大学计算机与信息技术学院,北京 100044;2. 北京交通大学交通数据分析与挖掘北京市重点实验室,北京 100044;3. 中国民航信息网络股份有限公司民航旅客服务智能化应用技术重点实验室,北京 100105)
1 引言
在机场大面积延误场景下,航空公司需要为受影响的航班制定恢复方案。然而该场景下旅客可以选择改乘其它航班、换乘其它交通工具或取消行程。并且由于民航业允许旅客无需即时完成退票或改签操作,这就导致航空公司根本无法掌握延误发生后随时间动态变化的真实旅客成行需求量,即各个时间点仍在机场内等待该航班的旅客数量。如果仍然按照原始需求量制定恢复方案,则会使得航班恢复后上座率比预期大幅降低,从而造成有限民航资源的浪费。因此如何实现延误航班旅客动态成行需求量的准确预测是亟需解决的问题。
针对交通领域的需求量预测,已有诸多学者开展了相关研究。然而目前尚未有人专门针对延误航班的旅客成行需求量预测这一任务开展工作。不过从文献[2-5]可以看出,由于近年来机器学习快速发展,利用相关回归预测模型可以实现较为准确的需求量预测,例如XGBoost、LSTM等。这些方法本质上都是在寻找特征与真实目标值之间的映射关系,然而由于该任务应用场景的限制,航空公司无法获得除实际起飞时间之外的其它时间点的真实旅客需求量,即缺少这些方法所需的真实拟合目标值,导致预测准确度难以保证。此外,这些方法需要将航班视为一个整体来进行需求量的预测,也忽视了旅客个体所包含的大量信息。
因此为了解决延误航班动态成行需求量预测问题,本文从旅客个体角度出发提出一个两阶段预测算法框架,一是旅客是否会流失预测阶段,二是会流失旅客的具体流失时间预测阶段,最后通过在任意时间点上将这些旅客个体行为整合至航班的方式来实现动态成行需求量的预测。其中,旅客是否流失预测阶段可以建模为一般的分类任务,而流失时间预测阶段是该算法框架中的设计难点,因为其在实现过程中面临两个实际数据问题:一是大部分旅客在得知航班延误后集中进行退票或改签,这导致旅客流失时间分布极不均衡;二是真实的旅客流失时间无法获取,只能将旅客退票或改签的操作时间近似视为旅客流失时间,这导致该时间存在一定的模糊性。针对上述两个挑战,本文在该阶段提出了一种基于随机森林(Random Forest, RF)和标记分布学习(Label Distribution Learning,LDL)的流失时间预测模型LDL-RF,该模型利用标记分布学习实现数据重用,从而缓解了数据分布不均的问题并弱化了流失时间的模糊性。
通过大量仿真验证,本文提出的算法框架能够实现更加准确的旅客动态成行需求量预测,且LDL-RF模型可以在一定程度上缓解由实际数据问题给预测效果带来的负面影响。
2 问题定义


(1)
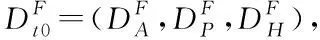
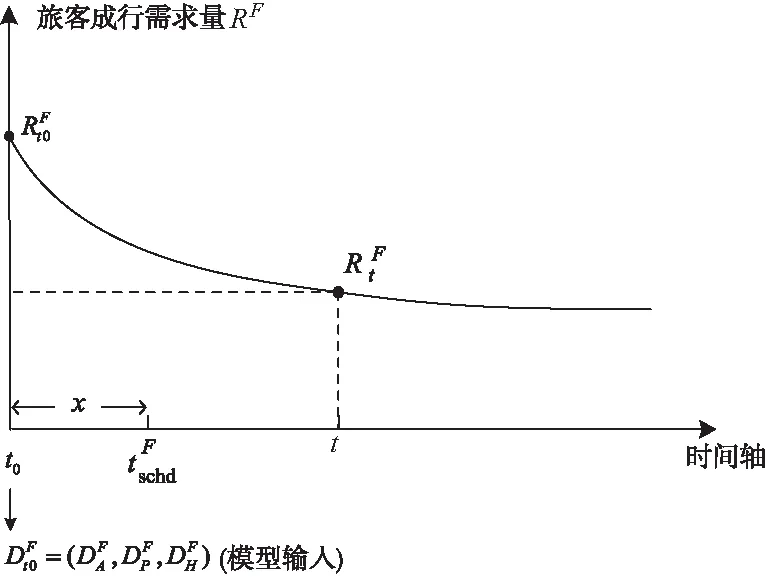
图1 模型输入输出以及时间关系示意图

表1 模型输入信息对应的具体特征
3 旅客动态成行需求量预测算法
考虑到需求量是由该航班上所有旅客个体组合而成,如果能够掌握每个旅客的流失情况,便能计算得到该航班任意时刻的旅客成行需求量。因此,本文提出从旅客个体行为预测角度出发,将需求量预测模型M
建模成一个两阶段预测模型,完整的算法框架及流程如图2所示。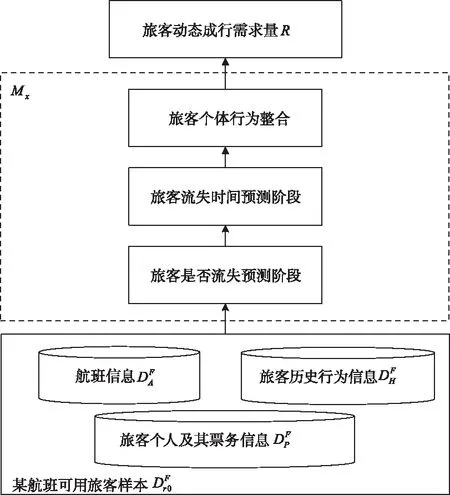
图2 旅客动态成行需求量预测算法流程图
3.1 旅客是否流失预测阶段
这一阶段用于预测某航班上有哪些旅客会在等待航班过程中流失。本文利用随机森林模型来实现这一预测目标:以训练集中的所有旅客信息作为样本特征,如表1所示,以旅客最终是否流失作为样本类别,依据随机森林生成算法,生成可用于预测待测旅客是否流失的随机森林二分类模型。
3.2 旅客流失时间预测阶段

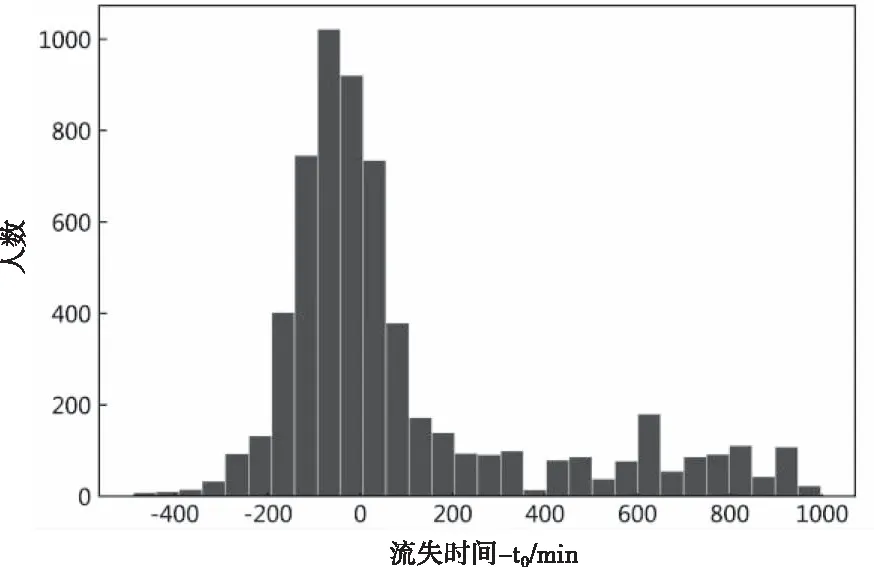
图3 旅客流失时间与预测起始时间t0 (x=0)时间差值分布
3.
2.
1 流失时间分布的生成
假设预测终止时间为t,本文将预测起始时间t到预测终止时间t这一时间段,以10分钟为间隔,划分为T个时间区间[0,10)、[10,20)、…、[t-t-10,t-t),每个时间区间对应一个标记。需要注意的是,时间区间内各值为相对t时间点的分钟数。然后将每一旅客样本对应的相对流失时间(流失时间相对t时间点的分钟数差值)基于高斯分布转换为T个时间区间上的标记分布,具体计算如式(2)所示:

(2)


图4 流失时间α3对应的标记分布
这样虽然将流失时间这一实值变量转换为多个区间损失了一小部分精度,但一个旅客样本可以被多个时间区间重复使用,不仅可以弥补某些时间区间样本太少的问题,同时也可以缓解流失时间模糊性所带来的负面影响。
3.
2.
2LDL
-RF
模型的训练和预测本文提出的LDL
-RF
模型是一个可输出预测流失时间对应标记分布的随机森林。LDL
-RF
采用启发式的方法来生成随机森林,具体为遍历所有特征及其所有可能切分点中寻找满足式(3)条件的第m个特征和其取值s,并分别作为最优切分特征和最优切分点来拆分输入空间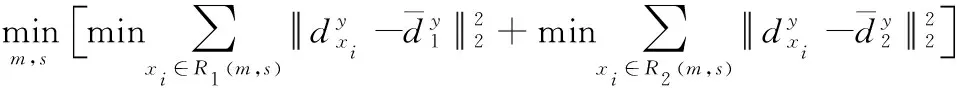
(3)
其中R(m,s)和R(m,s)是利用切分特征m和切分点s将输入空间拆分出的两个区域,如式(4)和(5)所示
R
(m
,s
)={x
|x
()n
≤s
}(4)
R
(m
,s
)={x
|x
()>s
}(5)


(6)

(7)
接着对每个区域重复上述划分过程,直到满足一颗决策树的停止条件。并依此方法生成K
颗决策树,组成LDL
-RF
模型。整个输入空间被LDL
-RF
中的第k个决策树划分为Q个子区域,于是LDL
-RF
模型可表示为式(8)
(8)
其中I(·)为指示函数,满足括号内条件则值为1,否则为0。


(9)

3.2.3 旅客个体行为整合


(10)
4 仿真结果与分析
4.1 数据集
本文所用数据集由中国航信提供,具体是2016年12月大面积延误场景下的所有航班相关信息,包括1757架航班,218545位旅客。同时为了在不同数据情况下验证方法的有效性,本文从此数据中通过限制航空公司或机场提取了8个子数据集,具体信息如表2所示。
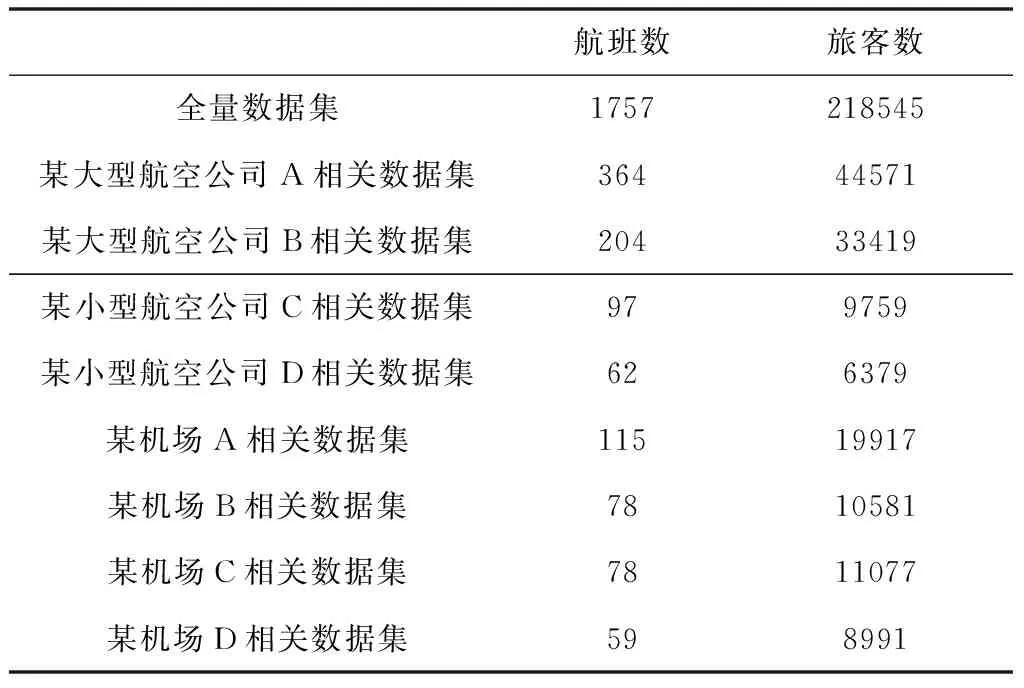
表2 数据集信息
4.2 评价指标
在实际数据中,每个时间点的真实旅客成行需求量是无法获取的,只能将该航班的真实乘坐人数作为实际起飞时间的真实旅客成行需求量。因此在实验当中,本文将模型在实际起飞时间的预测结果与真实旅客成行需求量作对比,即需求量预测评价指标为平均绝对误差(Mean Absolute Error, MAE),如式(11)所示
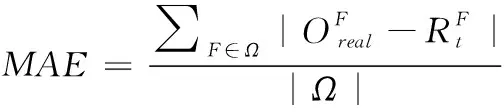
(11)

4.3 实验设置

4.4 实验结果分析
4.4.1 基于全量数据的对比实验
为了全面验证方法的有效性,本文将提前预测时长x分别设置为0,1,3,6小时,对应四种不同的预测起始时间。实验结果如图5所示,OurModel代表本文方法。在x相同的情况下,如x的值为0小时,本文方法的误差最小,仅为1.32,比另外三种方法中最好的RF还小2.1左右。随着x值的增大,如x的值为6小时,本文方法误差值上升到了5.44,但仍然小于所有基线方法。由此得知,本文方法能够实现更加准确的旅客动态成行需求量预测,而原因主要在于本文方法更为充分地利用了每位旅客个体的信息来实现需求量计算,而基线方法则是将航班视为一个整体,忽视了其中的旅客个体信息。
同时可以看出x的值越大,除OR外其它预测方法的误差也会随之变大,这是因为越早开始预测,所能获取到的旅客集合与最终成行旅客集合差别就越大,预测难度也就越大,所以这样的结果是符合实际场景的。

图5 四种提前预测时长x对应四种方法MAE指标比较
4.4.2 不同数据集下的对比实验
上述实验是在全量数据集上的进行,而为了进一步探究在不同场景下算法的有效性,分别从航空公司和机场两个维度划分数据集来进行对比。表3和表4展示的是四种方法在提前预测时长x值为0小时的情况下不同航空公司或机场的误差平均值和标准差,其中加粗数字是在该列中的最优结果。总体上看文中提出的方法表现都是最好的,特别是在面对一些小型航司,如航空公司D,XGBoost和RF甚至不如OR,表明在这种场景下传统的回归需求预测方法是不可行的,而文中的方法则可以稳定的得到更优的表现,在误差和标准差两个维度均远低于其它方法。由表4的误差可以看出文中的方法对于不同机场的航班动态需求预测同样表现最优。
综上所述,本文方法在不同数据集和不同预测场景下均能表现出优异而稳定的预测性能。
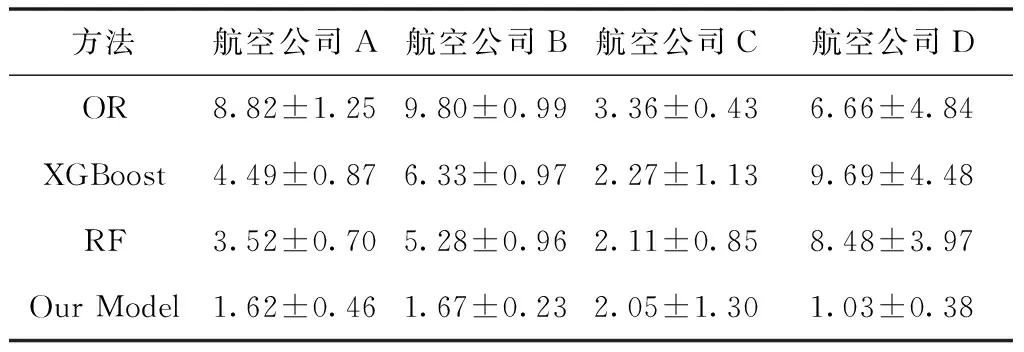
表3 提前预测时长x=0时四个航空公司对应四种方法MAE指标比较(平均值±标准差)
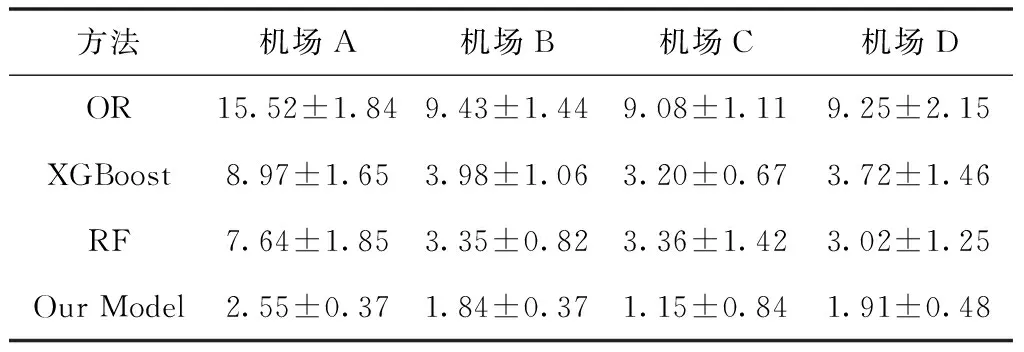
表4 提前预测时长x=0时四个机场对应四种方法MAE指标比较(平均值±标准差)
4.4.3 流失时间预测阶段使用不同模型的对比实验
为了验证本文在流失时间预测阶段提出LDL-RF这一模型的有效性,本文将该阶段中的LDL-RF替换为传统的随机森林分类和回归模型,并在提前预测时长x=0,1,3,6小时的情况下分别进行对比实验。由表5可以看出,在相同x的情况下,使用分类和回归模型的MAE指标均大于LDL-RF。由此可见,本文提出的LDL-RF模型通过将旅客样本在多个流失时间区间上重用的方式,在一定程度上解决了旅客流失时间分布极不均衡以及流失时间不准确的问题,从而改善了模型预测效果。

表5 四种提前预测时长x对应流失时间预测阶段使用不同模型MAE指标比较(平均值±标准差)
5 结束语
本文提出了一个两阶段预测算法框架,通过预测旅客个体是否会流失以及何时流失来获得未来任意时间点的旅客成行需求量。相比回归预测模型,本文方法的优势在于解决了该任务场景下旅客流失分布不均衡以及数据模糊的问题,同时也能够更加充分地利用旅客个体信息。最后在多个真实场景数据集上验证了算法框架以及流失时间预测算法的优越性和鲁棒性。未来工作可以进一步优化本文提出的预测框架,例如为旅客生成自适应的流失时间分布,从而进一步提升预测准确性。
