TidyYOLOv4-SPP3实时精细无人驾驶目标检测算法研究
2022-07-18刘新潮严英甘海云
刘新潮,严英,甘海云
(1.天津职业技术师范大学 汽车与交通学院,天津 300222;2.智能车路协同与安全技术国家地方联合工程研究中心,天津 300084)
无人驾驶融合多项检测技术是一种新兴的高科技创新,其中视觉检测是保证实时性和准确性的基础,视觉不仅具有较高的稳定性还可以保障行驶交通环境中的物体进行准确实时的检测.但随着城市地区车辆的饱和形成了更多复杂的交通场景,如交通拥堵、违规停车与违规超车等.在这些复杂动态环境下无人驾驶的视觉检测策略则需要更有效、更准确地分析场景的动态与静态区域.一般来说,障碍物的目标检测主要是寻找目标的位置,分析目标的特征,在密集的动态障碍物中准确进行识别.检测设备一般是固定在无人驾驶车辆上,根据拍摄距离的远近获取不同尺寸的特征和视角,这对于复杂的交通而言,障碍物越多识别距离越远越难捕捉到有效的特征信息.随着计算硬件和视觉算法的进步,无人驾驶视觉在城市交通环境物体的检测效果有了很大改善,但仅限于障碍物相对稀疏的场景或行驶速度要求较低的城市路径.
为了提高无人驾驶在城市交通环境的目标检测精度,宋艳艳等人[1]利用残差结构的思想,将深层结构的特征与浅层结构的特征进行上采样融合,并利用K-means算法聚类获取合适的检测框从而提高目标的检测精度.崔艳鹏等人[2]提出了一种超分辨率进行的重建来增强特征细节的提取,然后使用维度聚类重新生成预选框,减缓了检测速度.本文选取检测精度与速度比较平衡的YOLOv4[3]目标检测算法,通过在其检测头前增加空间金字塔模块来提高特征提取效果,由于特征提取效果的提升会降低检测速度,本文提出一种深度模型剪枝的策略,通过修剪冗余的网络结构来提升检测效率.为验证优化策略的有效性选择了开源数据集VOC2012进行验证.
1 相关工作
机器视觉对图像的解析主要分为三类:分类、检测与分割,与分类不同的是目标检测除了解析类别信息外,还要检测目标的位置信息,因此处理过程更加繁琐.传统的目标检测算法大多是基于滑动窗口的思想来处理目标信息,具有处理过程复杂与适用性差的缺点.随着硬件的升级,在深度学习的基础上已发展出结构简单、运行高效的目标检测算法.其中包括R-CNN[4]、Faster R-CNN[5]、SPP-Net[6]、RetinaNet[7]、SSD[8]、YOLO[9]、YOLOv2[10]、YOLOv3[11]、YOLOv4[1]等目标检测器.
这些深层目标检测算法主要分为两类:一类是由候选区域、手工特征提取与分类器组成的两级目标检测算法,两阶段的目标检测算法学习一种目标检测器需要CNN提取选择性搜索产生的特征建议.使用该方法的检测器一般使用卷积神经网络来调用这些区域,而R-CNN系列可能是两级目标检测器中最有效的系列之一.虽然检测精度先进,但与一级检测方法相比两级目标检测器的实时性较差.YOLO家族的出现使单级目标检测器的精度开始接近两级目标检测器的精度,同时依然拥有很高的实时性,经过一系列的发展提出了YOLOv2、YOLOv3甚至是YOLOv4,进一步提高了模型的性能.YOLOv4通过shortcut connections、upsampling和concatenation可以获取三种不同尺度的特征图.YOLOv4使用了很多先进的思想来提高准确性,在检测小物体方面也有了很高的提升.因此本文选用YOLOv4目标检测算法作为本优化策略的基础网络模型,经过优化后结合剪枝策略学习一个更“精细”的目标检测模型,即TidyYOLOv4-SPP3,来实现无人驾驶目标检测算法在复杂城市交通中对前方目标的实时精准检测.
2 网络
2.1 网络优化
本文在YOLOv4算法的基础上添加空间金字塔模块[6](SPP)来加强深层特征的提取.现实样本中往往会存在很多不同的特征尺度,为了保证具有固定大小的样本,通常有两种处理方式:第一种,对原图像进行裁剪,裁剪后必然会有相关的特征被修剪掉,特征提取在一定程度上也会受到影响.第二种,将原始图像进行缩放,得到的图像变得畸形失真,在一定程度上也会影响特征的提取.而SPP可以让网络模型输入任意尺寸的图片,而且还可以保证输出固定大小图片.SPP网络层分别使用了(4×4)、(2×2)、(1×1)三种大小不同的空间金字塔池化层来提取特征.将一张特征图输到不同的空间金字塔池化层中进行最大池化处理.输入一张任意尺寸的图片转换成一个固定尺寸的21维特征图,输出的特征图为(16+4+1)×256的大小,因此就解决了输入图像大小不一致的问题.在YOLOv4上借鉴这一思想,在其Neck上加入空间金字塔网络结构,如图1所示的4个maxpool层,其内核大小分别为(1×1)、(5×5)、(9×9)、(13×13),进一步为多尺度检测做铺垫,增加网络结构的鲁棒性,减少过拟合,提高模型的性能.

图1 空间金字塔池化结构图
YOLOv4在针对检测精度与实时性上对YOLO算法做出不断的优化.首先YOLOv4在Darknet-53[11]的基础上添加Mish[12]函数和借鉴CSP-Net[13]的思想构建一种新的主干网,即CSPDarknet53,除此之外在Neck部分还增添了SPP[6]和PAN[14]优化特征的提取.在检测头部分依然遵循YOLOv3的思想,以三种不同比例的预测包围盒,通过建立不同比例的要素地图来探测不同尺寸的物体.检测头的每一个网格都会分配到三个不同的锚盒来预测三个检测,其中包含4个边界框的偏移、1个置信度和C类的预测.检测头由公式N×N×(3×(4+1+C))得出张量的形状,其中的N×N表示为卷积层输出特征图的大小.
因此,经过一系列的优化,YOLOv4比YOLO系列的其他网络检测效果更好.为了更进一步优化网络特征的提取能力,在YOLOv4三个检测头前的第5与第6个卷积层之间融入SPP模块来加强特征提取,组合成YOLOv4-SPP3.如图2所示.

图2 YOLOv4-SPP3架构简图
2.2 网络剪枝
由于网络在训练过程中不能保证每一部分的权重都可以起到重要的作用,为了获得更紧凑和有效的检测模型,实验制定剪枝策略修剪目标检测模型的冗余架构来减少运行资源消耗,提升检测效率.在YOLO v4-SPP3优化网络的基础上进行模型精简,通过图3网络修剪的迭代过程来获取高效网络的检测模型TidyYOLOv4-SPP3.
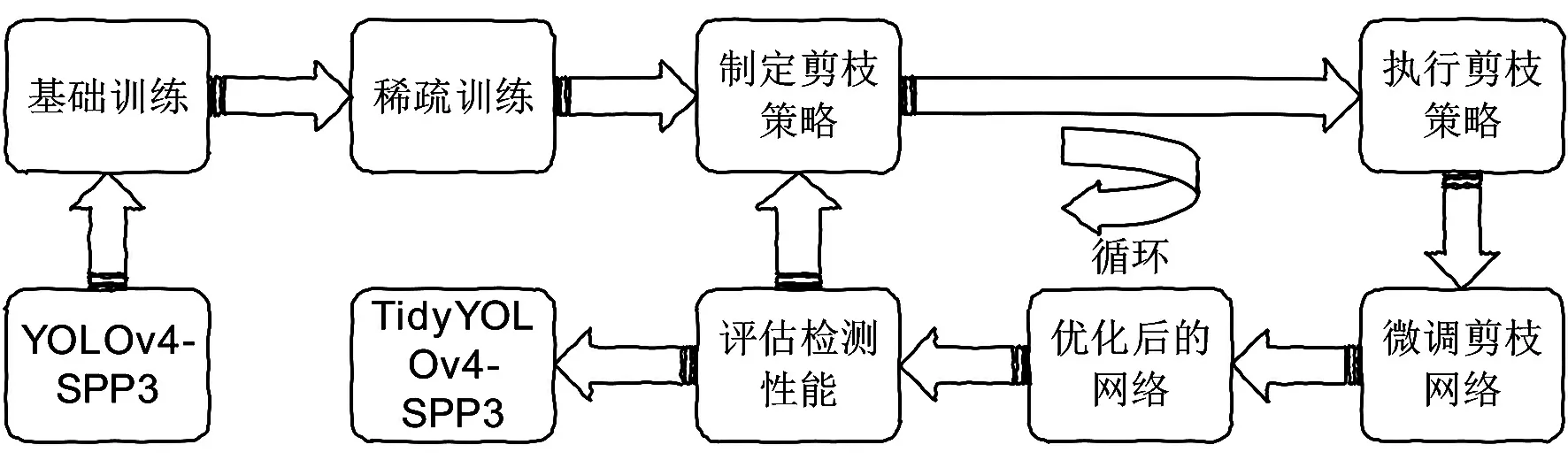
图3 TidyYOLOv4-SPP3的迭代过程
深层模型的信道稀疏训练方便后期剪枝策略对通道和网络层的修剪,实验向每一个channel加入一个比例因子,用其绝对值辨别修剪通道中不重要的部分.主要是依赖卷积层后一层的BN层(不包含检测头)来加强泛化能力和提升收敛速度.BN层用小批量统计来归一化深层特征,如式(1).
(1)

为了在试验中有效识别channel的重要性,借助BN层的比例因子γ来权衡channel的有效性.训练权重与比例因子进行联合训练,之后对γ因子进行L1 正则化[15-16]. 最 后 channel稀疏训练
辨别channel的重要性.如式(2)所示.
(2)
式中:η是用来调节Tloss(网络中训练参数的损失)和Χ(·)(比例因子的惩罚),Χ(γ)=|γ|为L1正则化,然后借用次梯度法[17]来优化非光滑L1惩罚项.
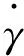
微调:剪枝策略对模型进行修剪之后,通常进行微调操作来提升模型性能的暂时衰减,深层模型的修剪对检测精度有很大的影响.因此,微调对恢复模型检测性能有着至关重要的作用.微调的具体方法是对相同条件下的该网络重新进行训练.
检测性能的评估:网络模型执行完剪枝策略后得到新的检测模型,需要对其检测性能进行评估,判断是否达到了所需要的实验要求或者是达到了最佳的检测状态.
3 实验
在YOLOv4的基础上经过一系列优化,优化出符合检测城市道路中物体的目标检测算法TidyYOLOv4-SPP3.经过以下实验来验证算法的有效性.
3.1 实验环境
实验过程中需要配置深度学习框架来满足TidyYOLOv4-SPP3的运行.
运行环境:中央处理器/GHz(Inter Xeon E5-2603),内存/GB(16),GPU(Tesla P4,8GB),GPU加速库(CUDA10.0,CUDNN7.0),深度学习框架(PyTorch),操作系统(Ubuntu 16.04).
3.2 数据集
为了验证优化算法的有效性,选用VOC2012作为本次实验的数据集,VOC2012是从现实的场景中获取的20个类别的数据集,分别为人、鸟、猫、牛、狗、羊、飞机、自行车、船、公交车、小轿车、摩托车、火车、杯子、椅子、餐桌、沙发、电视包,该数据集中总共包含17 125张图片,其中大多数的类别符合城市道路上出现的类别,因此选用此数据集来验证算法的有效性.本文的所有算法模型都是在该数据集上学习的,并在验证集上进行评估.其中训练集包 含13 700 张 图 片、 验 证 集包含1 713张图片、 测 试 集 包 含1 712张图片.
3.3 模型训练
基础训练:优化后的YOLOv4-SPP3模型首先需要进行100个迭代,初始学习率为0.001,在训练总数为70%和90%时,分别除以10.权重衰减设置为0.000 5,动量参数为0.9.
稀疏训练:基础模型训练完成100个迭代之后,为了促进网络剪枝的进行,又完成了300个迭代的稀疏训练.学习率不同选择不同的惩罚因子,本实验设置的学习率为0.01,因此惩罚因子选择了比较适宜的0.000 1进行训练,其他设置保持与基础训练相同的参数.
3.4 性能指标
用以下指标来分析优化模型的性能:①mAP(平均精度);②Total BFLOPS(浮点数);③Inference time(推理每张图片所消耗的时间);④Parameters(模型参数);⑤Volume(权重空间).
4 实验结果分析
由表1实验结果分析基础模型,采用不同优化策略学习模型的实验结果,来选取最优的目标检测模型(YOLOv4-SPP3-X,SPP3表示在YOLOv4的基础上添加了3个空间金字塔池化,X表示修剪X%).

表1 实验结果
从表1中可以看出,网络设置输入尺寸为864×864的YOLOv4与设置尺寸为416×416的YOLOv4-SPP3检测精度相当.当YOLOv4-SPP3也设置864×864的参数时,在mAP上比YOLOv4高出约5.5%,这说明在YOLOv4上添加SPP模块来优化模型是有效的.因此选用网络设置输入图片尺寸为864×864的YOLOv4-SPP3网络模型进行不同剪枝率的精简.
实验中对YOLOv4-SPP3进行不同程度的修剪,表2记录了YOLOv4-SPP3检测模型的压缩结果.从图4(a)中可以看出模型YOLOv4-SPP3的mAP随着剪枝率的提高呈加速降低的趋势.由图4(b)中可以看出模型参数都处于较小的空间,并且参数大小没有明显的区别.对比图4(c)中YOLOv4-SPP3-94、YOLOv4-SPP3-95、YOLOv4-SPP3-96的评价指标可知Total BFLOPS、Inference time(ms)、Volume(MB)随着剪枝率的升高成均匀下降的趋势,综合图4(a)与图4(b)的评价指标选择YOLOv4-SPP3-95作为本次实验得出的最终优化算法,即TidyYOLOv4-SPP3.

表2 模型压缩结果

(a)mAP

(b)Parameters

(c)Total BFLOPS、Inference time、Volume的性能指标图4 YOLOv4-SPP3修剪得出的评价指标对比
模型检测分析:如表1所示,YOLOv4-SPP3的检测指标最佳,但需要消耗更多的运行资源.因此优化出“精细”的TidyYOLOv4-SPP3检测模型来减少运行资源的消耗.YOLOv4-SPP3与TidyYOLOv4-SPP3相比其mAP没有明显的区别, 但是Total BFLOPS缩小约了293.82,Inference time减少了80.77 ms,Parameters减少了62.79 M,Volume减少了242.07 MB.为了证明TidyYOLOv4-SPP3模型的有效性进行了可视化检测如图5和图6,两个检测器都可以在该帧图片上精确的检测出感兴趣区域的对象.



图5 YOLOv4-SPP3检测效果



图6 TidyYOLOv4-SPP3检测效果
5 结论
本文提出了一种复杂城市交通道路中的视觉目标检测算法TidyYOLOv4-SPP3.实验在YOLOv4的三个检测头前添加SPP来提高网络的特征提取.结合层与通道的剪枝策略来修剪YOLOv4-SPP3,消除学习模型的冗余,精简更加有效的模型.通过L1稀疏正则化来施加通道比例因子,自动识别需要剪枝的部分,再进行修剪.根据这种方式在原模型YOLOv4的基础上优化出TidyYOLOv4-SPP模型.TidyYOLOv4-SPP3与YOLOv4相比,检测速度提高了76.38%,检测精度没有明显变化,优化模型的空间体积缩小了93.35%.由此判定TidyYOLOv4-SPP3比YOLOv4更适合应用在无人驾驶对复杂城市交通中障碍物的视觉检测.
