基于电子病历的重症老年患者急性肾损伤连续风险预测研究
2022-07-14邬金鸣孙海霞王嘉阳
邬金鸣 孙海霞 王嘉阳 钱 庆
(1.中国医学科学院/北京协和医学院医学信息研究所医学数据共享研究室,北京 100020; 2.中国医学科学院/北京协和医学院医学信息研究所医学智能计算研究室,北京 100020;3.中国医学科学院/北京协和医学院医学信息研究所,北京 100020)
急性肾损伤(acute kidney injury, AKI)是一种发病率高、病死率高、临床不良事件发生率高的危急重病症[1],在重症监护病房(intensive care unit,ICU)中全球发病率为5.7%~67%[2],病死率高达50%[3]。AKI发病群体日趋老龄化,随年龄增长, 人体肾脏结构和功能老化, AKI发生率也显著增加[4]。国内一项调查[5]显示, 60岁以上AKI患者占院内AKI总数的52.2%。
急性肾损伤临床实践指南(kidney disease improving global outcomes,KDIGO)[6]指出,相较于确诊AKI后再治疗,事先识别高风险患者,提前干预将优化预后结果。特别对于重症患者,进入ICU的最初几个小时是AKI诊疗的黄金时间,这段时间的诊断和用药可以影响AKI的发生和发展[7],早期干预可缩短ICU住院时间,降低病死率。理想情况下应实时检测和监控患者肾功能,以便发生AKI时即刻诊断,及时调整药物剂量和临床治疗。目前,AKI的诊断主要基于血清肌酐(serum creatinine,Scr)的上升或尿量的下降,但两者皆具有明显局限性,老年患者尿量常受利尿剂、尿路梗阻等因素影响,Scr也并非反映肾功能变化的敏感指标,因此可能导致延迟诊断[8]。
近年来,随着医院信息系统的快速发展,大量蕴含高价值信息的电子病历数据得以累积,机器学习等数据挖掘技术也愈发成熟,这为基于数据驱动的方法预测患者AKI风险提供了可能。AKI风险预测是指预测个体在未来某个时期发生发展AKI(或相关事件)的风险概率,即根据某个人群定义,例如ICU老年人群,针对某个预测目标,如AKI发病,设定特定的时间窗口,包括数据采集时间窗和预测时间窗,预测目标的发生概率。依此识别出高风险患者,可更好地对患者提供干预和护理,进而改善患者预后,特别是若在AKI的早期可逆转阶段能够及时发现,从而可预防其进展为肾衰竭以及避免后期需要的透析治疗[6]。
因此,本研究旨在基于电子病历,面向重症老年患者进行AKI连续风险预测,探索符合临床应用场景的早期连续动态预测框架的可行性,识别最早有效预测时间窗和数据采集策略,以促进机器学习在临床决策支持中的应用。具体为每隔6 h采集患者入ICU后的电子病历数据,分别基于当前单位时间数据和累积数据,利用逻辑回归(Logistic regression,LR)、随机森林(random forest, RF)、支持向量机(support vector machines,SVM)和轻量梯度提升机(light gradient boosting machine,LightGBM)4种经典机器方法建模连续预测重症老年患者未来48 h的AKI发病风险。
1 资料与方法
1.1 相关研究背景资料
1.1.1 面向不同人群的AKI预测研究
为识别患者AKI发病风险以指导临床决策,诸多研究面向不同人群基于电子病历数据构建AKI预测模型。如Kristovic等[9]应用逻辑回归方法构建了心脏手术后患者AKI预测模型,且基于KDIGO标准[6]对不同AKI分期进行了预测,模型曲线下面积(area under curve,AUC)达到0.78;Lee等[10]应用7种机器学习方法与逻辑回归方法构建肝移植后AKI预测模型,对比发现梯度提升机(gradient boosting machine,GBM)实现最佳预测性能;Kate等[11]应用逻辑回归、支持向量机、决策树和朴素贝叶斯方法构建住院老年患者的AKI预测模型,发现逻辑回归效果最好,但AUC仅为0.66;Flechet等[12]应用随机森林方法开发面向成人ICU患者的在线AKI预测模型。
1.1.2 不同预测策略的AKI预测研究
现有研究的预测时间点多设置在AKI发病前n天,如Mohamadlou等[13]应用提升树(boosted ensembles of decision trees)方法在AKI发病前12、24、48、72 h进行预测。但该建模过程确定评估测试集时应用了未知的发病时间,不可避免地导致实验结果优于临床应用。相比之下将患者入院第n天作为预测节点较能符合临床应用场景,如Sanchez-Pinto等[14]应用重症儿童患者入ICU后的前12 h的数据进行AKI早期预测,Zimmerman等[15]、Sun等[16]、Li等[17]应用成年患者入ICU后的前24 h的数据预测未来48 h AKI发病风险。然而,更为符合临床应用需求的是不拘泥于固定时间点的连续动态预测,即指运用患者入院期间随时间更新的生命体征和实验室值等来连续预测患者AKI风险,如Chiofolo等[18]使用随机森林开发了AKI预测模型,用于输出ICU患者从入院到出院的连续AKI风险评分分数, 将应用视角转向了连续预测,当前该方面研究尚处于起步阶段。
1.1.3 现状分析
当前AKI预测研究具有以下两个特点:①现有研究与及时识别重症老年患者AKI风险的需求之间存在差距。现有研究[8,19-22]多集中在心脏手术患者,其他大型手术后患者[23-24](例如肝移植[25])、肾毒性药物患者[26-28]、妊娠后患者[29]等人群。目前心脏手术或肾毒性药物引起的AKI预测研究相对较多,重点关注ICU内特定年龄段的早期AKI风险预测的研究不足。尽管ICU人群特别是ICU老年患者具有较高AKI风险,但面向该人群的预测研究却较少,而且因为人群特异性,面向其他人群的AKI预测模型并不完全适用于ICU老年患者群体。②现有研究与不拘泥于固定时间点的连续动态预测需求之间存在差距。现有研究多关注模型预测性能的提高,未深入探讨其预测策略是否充分考虑临床需求。少有AKI预测研究重点关注随着时间推移和患者体征变化的AKI连续动态预测。不管是从临床应用角度还是实际病情变化追踪角度,随着患者病情体征变化的连续动态预测更符合实际临床应用的需求,也更符合预测逻辑。此外,根据KDIGO[6]的指导,大多数研究将预测时间节点设定于进入ICU后的48 h,并不能满足AKI临床诊断的早期预测需求。
1.2 研究资料
本研究采用重症监护医学信息数据库(Medical Information Mart for Intensive Care,MIMIC)-Ⅲ 数据[30],MIMIC-Ⅲ数据库是由麻省理工学院计算生理学实验室、哈佛医学院贝斯以色列女执事医学中心和飞利浦医疗联合开发的多参数重症监护数据库,包含了2001年至2012年来自贝斯以色列女执事医学中心46 000多位ICU患者的近6万份临床数据,包括患者详细人口学信息、生理生化检查、诊断信息、医疗干预记录等。MIMIC-Ⅲ结构规范,数据记录较为全面,具有开放性,已广泛应用于ICU相关疾病研究[31]。本研究应用2016年发布的MIMIC-Ⅲ v1.4版本。
数据纳入标准:① 年龄≥60岁;② 入ICU初始血清肌酐测量值<4 mg/dL;③ ICU入住时间≥72 h;④入ICU诊断中没有终末期肾病。本研究利用的研究信息不含有使受试者的身份被直接识别或通过与其相关的识别物识别的信息,属于免除伦理审查。作为历史性研究可免除研究对象知情同意。
1.3 数据采集
本研究设计3个实验目标:① 探索以6 h为单位预测重症老年患者在未来48 h的AKI发病风险;② 探索现有模型可实现何种程度的早期预测;③ 比较各预测模型基于当前单位时间窗内数据和历史累积数据的AKI预测效果。
针对实验目标①和②,以Tomašev等[32]基于美国老兵数据库的AKI连续预测研究为参考,将1 d以6 h为单位进行划分,预测任务的数据采集窗设置为[0, 6 h]、[6 h, 12 h]、[12 h, 18 h]、[18 h, 24 h]……其中0是指入ICU时间。提前48至72 h预测AKI事件[33],本研究将预测时间窗设为预测点之后的48 h,并以6 h为单位应用移动滑窗法持续推进,如图1所示。
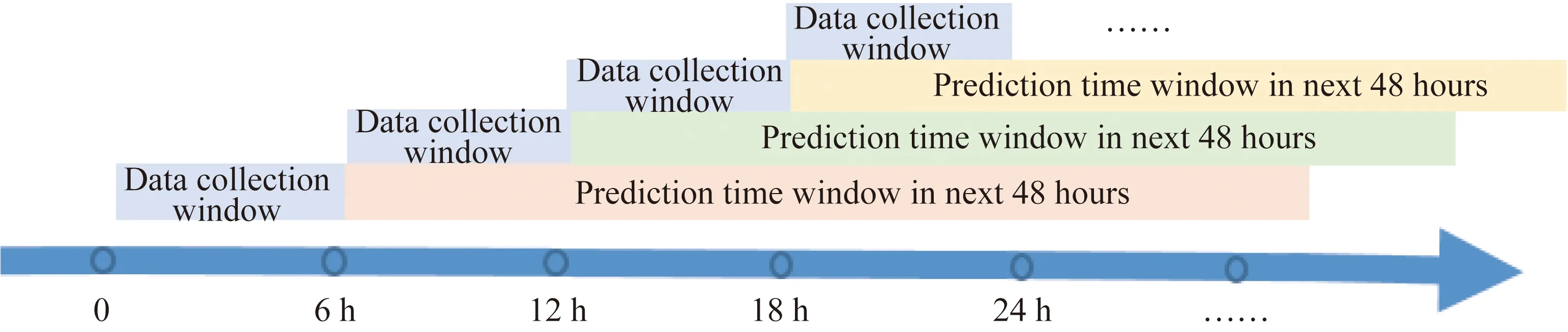
图1 第1种数据采集时间窗:当前数据Fig.1 The first data collection window: current data
针对实验目标③,对比既有数据采集时间窗[6 n h, 6(n+1) h](n≥0),另设数据采集时间窗[0, 6(n+1) h],如[0, 6 h]、[0, 12 h]、[0, 18 h]、[0, 24 h] (n≥0),如图2所示。比较相同模型在n取值相同的情况下(如[6 h, 12 h]和[0, 12 h])的预测效果差异。
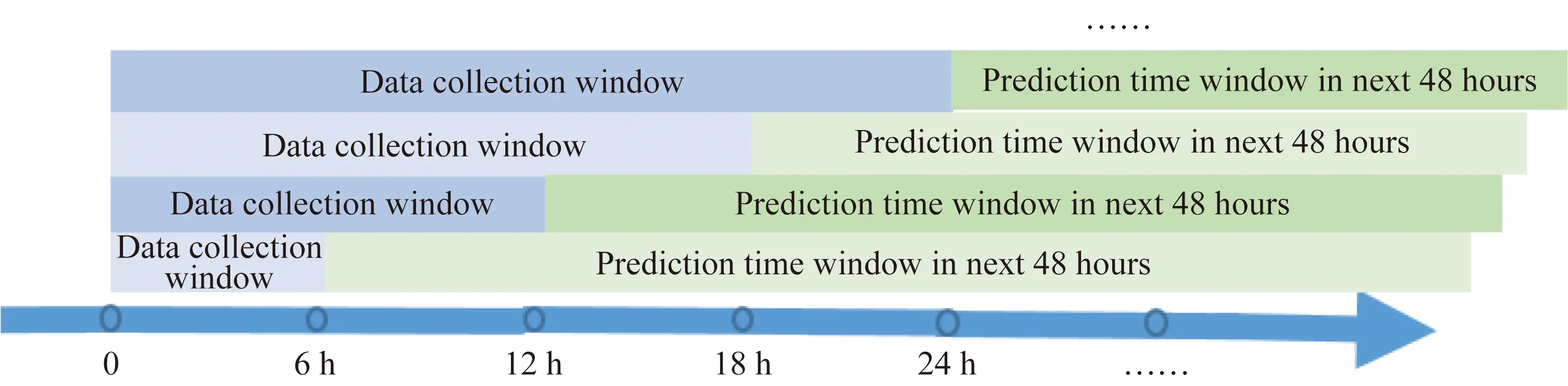
图2 第2种数据采集时间窗:累积数据Fig.2 The second method of data collection window: accumulated data
1.4 AKI定义
当前,KDIGO[6]被用作国际急性肾损伤判断共识,本研究遵循该标准将AKI定义为以下任一情况:①Scr 48 h内升高达≥ 0.3 mg/dL (>26.5 μmol/L);②Scr在7 d内升高基础值的≥1.5倍;③尿量<0.5 mL·kg-1·h-1,持续6 h。本研究定义结局指标时,将当前单位时间内的患者Scr最小值作为基线数值,判断未来48 h之内Scr最大值与基线值之差是否≥ 0.3 mg/dL (> 26.5 μmol/L),或是否大于基线值的1.5倍。鉴于每个患者可能多次出入ICU,但并不一定每次都发生AKI,本研究将ICU病程记录分为AKI组和非AKI组,而非直接对患者分组[15]。
1.5 预测变量
依据KDIGO标准[6]及研究同类,本研究选取31个预测变量,包括:①人口学信息:包括年龄、性别;②生理指标:包括心率平均值/最大值(min-1)、收缩压最小值/平均值(mmHg,1 mmHg=0.133 kPa)、舒张压平均值/最大值(mmHg)、体温最大值(℃)、血氧饱和度最小值/平均值(%)、尿量平均值(mL);③常用的实验室检查:包括白细胞计数最大值/最小值(μL-1)、血清肌酐最小值/最大值(mg/dL)、血红蛋白最小值/最大值(g/dL)、血小板计数最小值(μL-1)、碳酸氢盐最大值/最小值(mg/dL)、血清钙最小值(mg/dL)、血清钾最大值(mg/dL)、尿素氮最大值(mg/dL) 、血糖最大值(mg/dL)、凝血酶原时间最小值/最大值(s)、肾小球滤过率估算值(estimated glomerular filtration rate,eGFR)、国际标准化比值最小值/最大值(international normalized ratio,INR);④相关干预:是否进行机械通气。
本研究选择预测变量时未考虑慢性合并症(如糖尿病),因为对于患有多种病症的重症患者,当前的实验室检测或生命体征值相比慢性病对预测AKI的作用更明显[11]。此外,Ataei等[34]指出中性粒细胞明胶酶相关脂质运载蛋白(neutrophil gelatinase-associated lipocalin, NGAL)和胱抑素C(cystatin C)是AKI的早期预测指标,且支持更准确、敏感的预测,因MIMIC-Ⅲ数据中暂无相关记录,故未采用。
1.6 数据处理
1.6.1 缺失值处理
由于Scr值和尿量是判断AKI最重要的指标,本研究首先排除Scr值和尿量缺失的所有数据。若一条信息中,各项指标的缺失项大于50%,则认为本条数据信息量不足,进行删除。患者数据是基于不定期测量,一天中并非每6 h都有新测值,但预测模型以固定的6 h间隔持续推进。未有新测量值的变量取前一单位时间窗中的对应值,若仍缺失,则应用基于链式方程的多重插补(multivariate imputation by chained equations,MICE)方法处理。本研究优先选择前值填充,是因医学数据缺失值一般为非随机缺失,当患者某些指标正常或趋于稳定时便不再测量,因而前值更能代表当前状态。
1.6.2 数据转换
将文本类型数据转换成数值类型,如女性、男性分别用1、2表示。在数值类型数据中,不同的生理生化指标的范围跨度不同,建模前对其进行归一化处理,加快运算速度,提高模型表现。电子病历是含有时间属性的时态数据,本研究采用最近值(most recent)方法处理连续型时态数据,即取数据采集时间窗中离预测点最近的值作为特征取值;采用汇聚[35](aggregated)方法处理离散型时态数据,即如表示机械通气与否的二分类变量中,在数据采集窗口中的任何一个时间段进行了机械通气,该变量取为1,否则取为0。
1.6.3 平衡性处理
本数据的自然特性决定了非AKI患者的比例要高于AKI患者的比例,在不同的时间窗采集数据集中,AKI和非AKI的比例约为1∶3。严重失衡的样本会导致机器学习过程中采集到更多非AKI的特性,并在最终预测时倾向于将AKI预测为非AKI患者。为了避免样本失衡导致的误分类,本实验采用训练集划分模型集成方法解决数据不平衡问题,即将训练集中非AKI组样本有放回抽样为3份,每一份与所有AKI样本组合成3个新平衡训练集,将其分别用于训练不同分类算法。最后每种分类算法相应得到3个训练模型,其结果由3个模型的平均加权确定。
1.7 预测建模
尽管有研究[27]利用了许多不同的机器学习、深度学习方法进行AKI预测研究,深度学习在预测能力方面并未展示出绝对优势。因此本研究选用了3个AKI预测研究中常见且预测能力优秀、鲁棒性高的机器学习模型, LR、RF、SVM,以及一个新型基于树形结构的梯度提升框架LightGBM[36]。
(1)LR:一种对数线性模型。多元Logistic 回归中一个事件发生的对数概率为:log[p(x)/1-p(x)]=β0+β1X1+…+βpXp,则事件发生的概率为:p(X)=eβ0+β1X1+···+βpXp/(1+eβ0+β1X1+···+βpXp)[37]。
(2)SVM:一种二分类模型,基本模型是定义在特征空间上的间隔最大的线性分类器。支持向量机可以形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题,支持向量机的学习算法是求解凸二次规划的最优化算法[38]。
(3)RF:是一个树型分类器{h(x,βk),k=1…}的集合。其中基分类器h(x,βx)是用分类与回归树(classification and regression tree,CART)算法构建的未剪枝的分类回归树, 输出采用简单多数投票法[39]。
(4)LightGBM:其思想是利用弱分类器迭代训练得到最优模型,并采用梯度提升算法减少结构分数的计算量,在此基础上,采用基于直方图的算法选择分割点,并且使用leaf-wise 策略替代level-wise 分裂子节点,可简化计算并提高准确率[37]。
LR、SVM和RF模型采用Python工具包Scikit-learn运算,LightGBM应用LightGBM 工具包建模预测。不同时间窗设定收集的数据都被随机拆分成80%的训练集和20%的测试集。为保证数据可靠性,采用五折交叉验证评价模型性能,评价指标选择AUC、精确性(precision)、召回率(recall),评价指标值越大,表征模型的预测性能越好。
2 结果
2.1 纳入数据
共1 1261条ICU诊疗记录符合纳入标准。本实验数据中,患者人口统计学信息完整,而某些生理指标和实验室检查记录存在缺失。在患者进入ICU前期,各项指标都会被密切监测,患者体征平稳之后医生会根据患者情况筛选某些重要指标继续监测或对某些指标的测量逐渐稀疏甚至停止监控与病情相关性低的指标,因此随着时间推移,数据中会出现越来越多的缺失值。故在不同数据采集时间窗中,数据缺失情况不同。本研究删除了缺失值50%以上的诊疗记录,最终不同数据窗下训练模型所用的记录数不同。对于每个数据采集时间窗内采集的ICU诊疗记录,依据患者在未来48 h内是否会发生AKI分为AKI组以及非AKI组,详见表1。
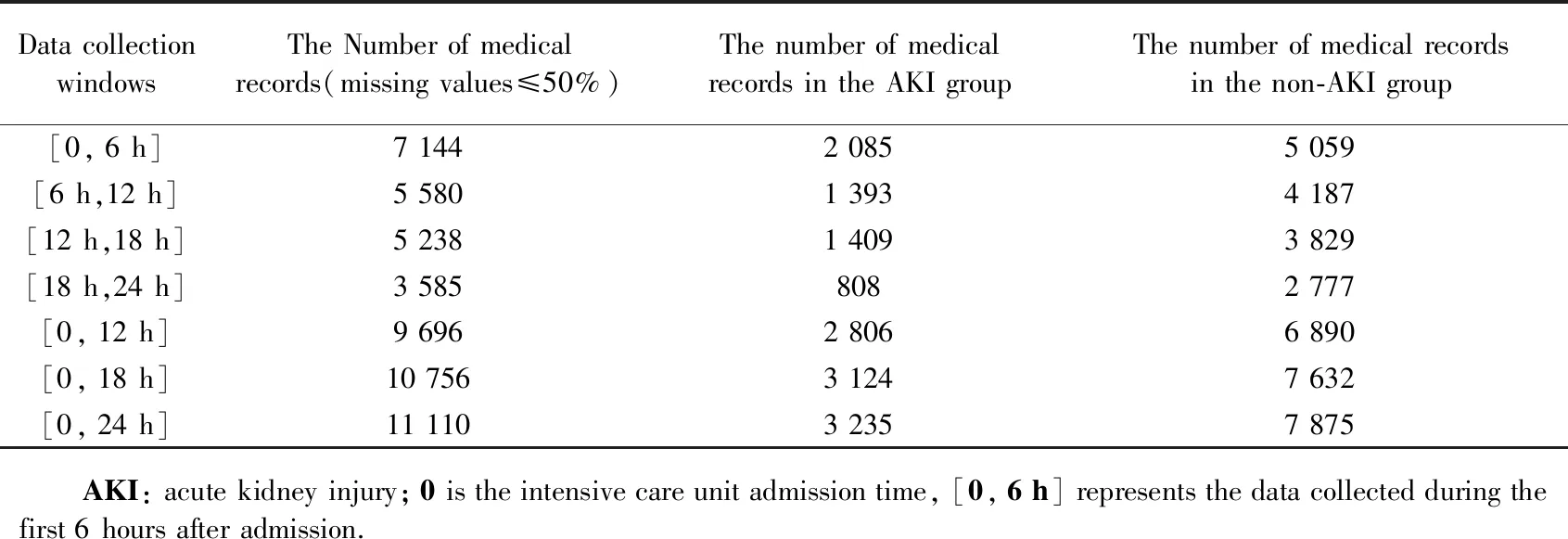
表1 不同数据采集窗中诊疗记录数Tab. 1 Number of medical records in different data collection windows
2.2 预测结果
表2和表3分别展示了[6n h, 6(n+1) h](n=0,1,2,3)数据采集窗下,4种预测模型的AUC值以及精确度/召回率值。表4和表5分别展示了[0, 6(n+1) h] (n=0,1,2,3)数据采集窗下,各预测模型的性能评价指标。为了更直观地对比不同数据采集窗下的各模型预测效果,本研究选择受试者工作特征(receiver operating characteristic,ROC)曲线进行可视化展示,直观评估分类器预测能力。AUC即为ROC曲线到x轴之间的面积,ROC曲线下面包含的面积越大则表明预测效果越好。图3~6分别对比了LightGBM、RF、SVM和LR中应用当前单位时间数据与应用累积数据进行预测的性能差异。蓝色曲线代表模型基于当前6 h数据的预测效果,橙色曲线代表模型使用累积前6n h数据的预测效果。
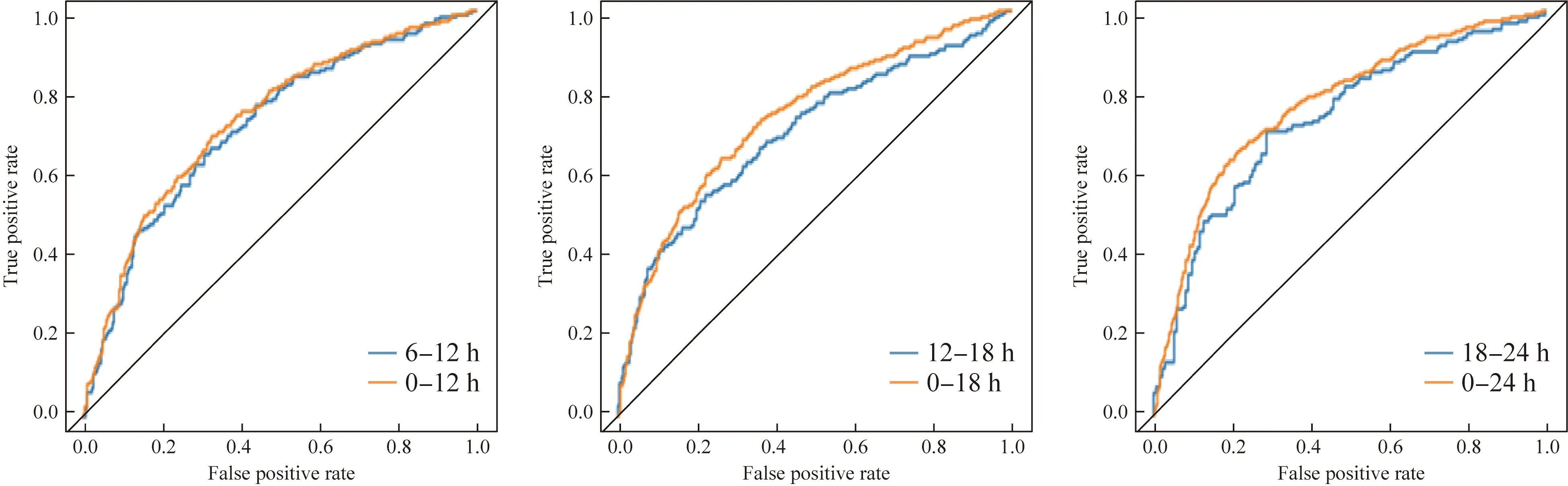
图3 LR在6个不同数据采集窗下的ROC曲线Fig.3 ROC curve of LR models in 6 different data collection windows
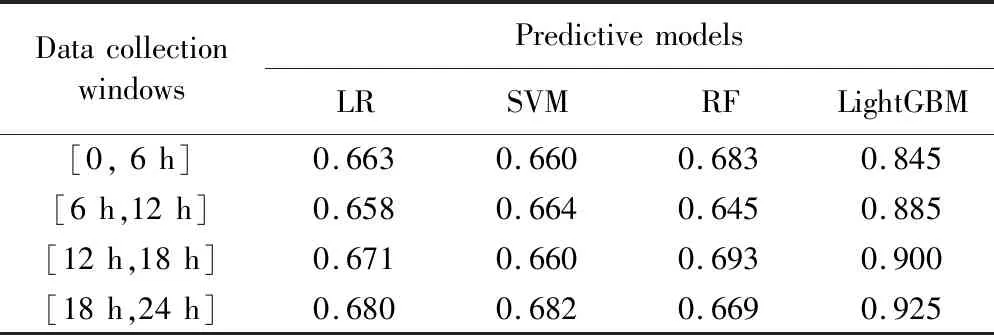
表2 [6n h, 6(n+1) h]数据采集窗下预测模型AUC值Tab. 2 AUC values of predictive models using data in time window [6n h, 6(n+1) h]
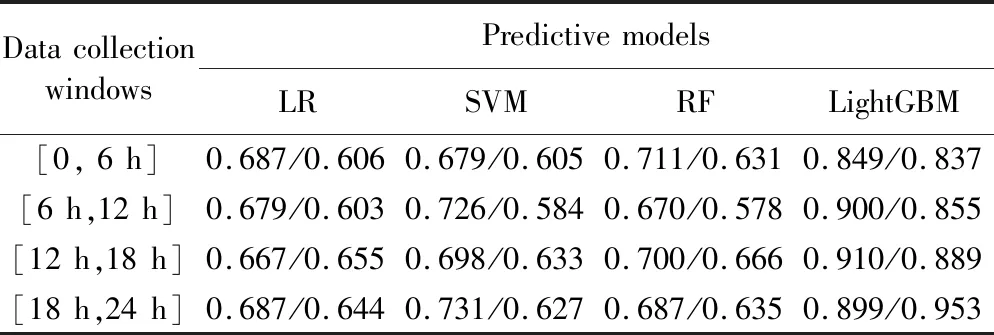
表3 [6n h, 6(n+1) h]数据采集窗下预测模型精确度/召回率值Tab. 3 Precision/recall values of predictive models using data in time window [6n h, 6(n+1) h]
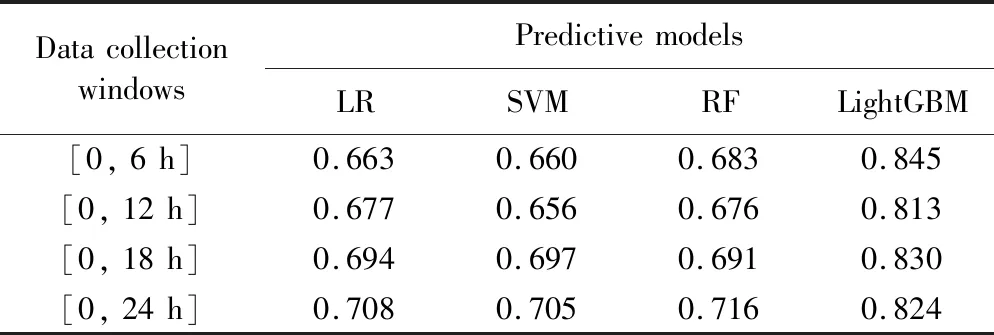
表4 [0, 6(n+1) h]数据采集窗下预测模型AUC值Tab. 4 AUC values of predictive models using data in time window [0, 6(n+1) h]
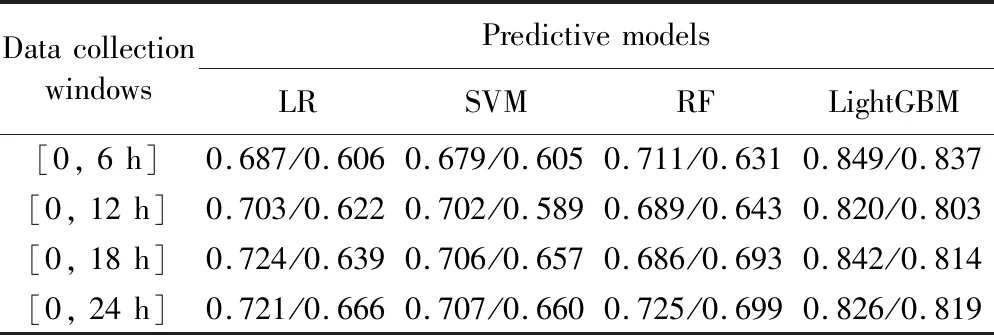
表5 [0, 6(n+1) h]数据采集窗下预测模型精确度/召回率值Tab. 5 Precision/recall values of predictive models using data in time window [0, 6(n+1) h]
针对实验目标①,即以6 h为单位预测重症老年患者在未来48 h的AKI发病风险,本研究应用LR、SVM、RF和LightGBM建模实现。在应用当前数据、累积数据的不同预测策略中,通过ROC曲线可以看出,LightGBM的预测效果明显优于另外3个模型,且性能良好,AUC值都达到了0.845以上,精确度和召回率分别达到了0.820、0.803以上。在基于当前数据预测时,即[6n h, 6(n+1)h],随时间窗的推移,LightGBM的预测效果持续提升,在[18 h,24 h]数据采集窗下得到最优预测效果,即在精确度/召回率为0.899/0.953的情况下AUC达0.925。实验结果表明应用LightGBM面向老年重症患者进行AKI连续风险预测具有一定可行性。在两种预测策略中,RF、SVM、LR的AUC在0.645~0.716之间,虽然随时间推移预测效果有所提升,但最好效果只是RF在精确度/召回率为0.725/0.699情况下AUC达到0.716,它们显示出了一定的预测能力但尚未达到在真实场景中应用的水平。此外,分析随时间推移模型预测效果有所提升的情况,可能潜在AKI患者的病情随时间推进愈发累积,此时生理指标或实验室检查值的预测性能增强。
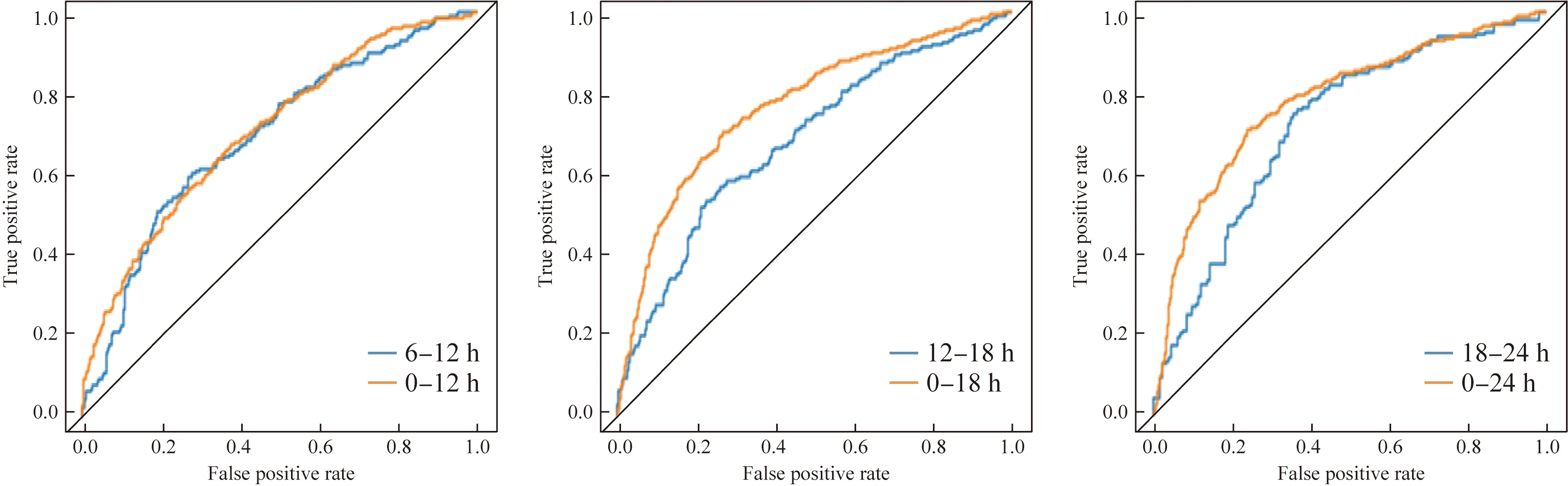
图4 SVM在6个不同数据采集窗下的ROC曲线Fig.4 ROC curve of SVM models in 6 different data collection windowsSVM: support vector machines;ROC:receiver operating characteristic.
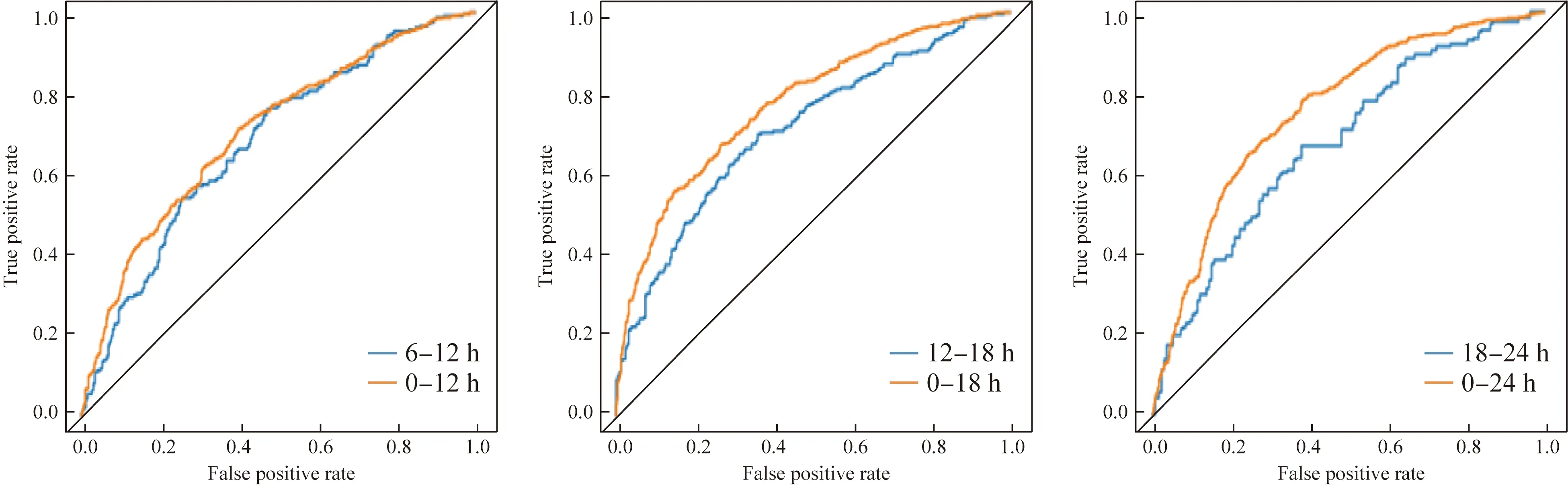
图5 RF在6个不同数据采集窗下的ROC曲线Fig.5 ROC curve of RF models in 6 different data collection windows RF: random forest;ROC:receiver operating characteristic.
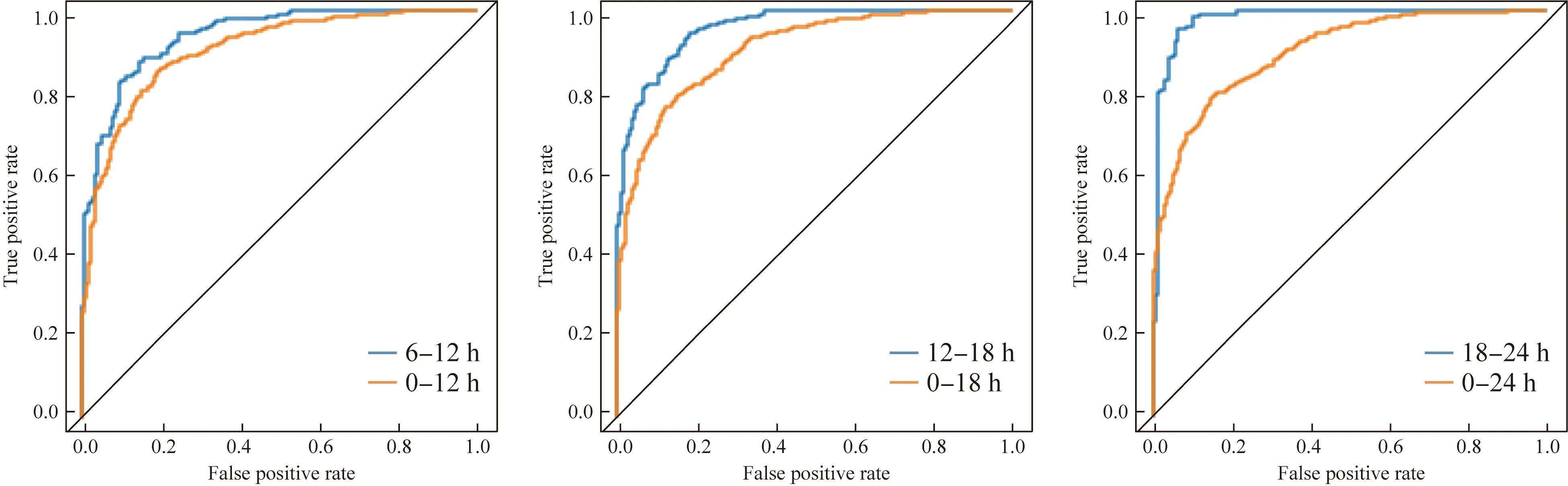
图6 LightGBM 在6个不同数据采集窗下的ROC曲线Fig.6 ROC curve of LightGBM models in 6 different data collection windows LightGBM:light gradient boosting machine;ROC:receiver operating characteristic.
针对实验目标②,即探索现有模型可实现何种程度的早期预测。实验显示仅用患者入ICU后的第1个6 h数据进行预测时,LightGBM依然在精确度/召回率为0.849/0.837的情况下达到了0.845的AUC,即LightGBM的预测能力和准确度在此场景下表现较好,甚至高于其应用[0, 12 h]、[0, 18 h]、[0, 24 h]数据所获得的AUC。ICU老年患者发生AKI非常普遍,越早预测越能为临床医师争取宝贵时间及时进行临床干预,本研究表明利用患者入ICU后的前6 h数据进行AKI早期预测切实可行,而当前研究多采用入ICU后的前24 h数据进行预测且AUC为0.57~0.92[15-17],利用LightGBM可以将观察时间窗缩减为原来的四分之一就可以达到0.845的AUC。
针对实验目标③,比较各预测模型基于当前数据和累积数据的AKI预测效果。LightGBM预测模型,基于累积数据预测结果的AUC值、准确率、精确度等评估指标均低于基于当前数据预测结果。实验结果表明,并非收集数据越多越好,可能当前单位时间内的测量值更能代表或预示患者的状态,而加入历史累积数据可能产生预测噪声。但在RF、SVM、LR模型中,基于累积数据预测结果比应用当前数据的预测效果好,AUC、精确度和召回率均有所提升。这提示不同模型对数据的接收能力和适用性不同,在选择模型分析数据时应考虑此差异性。
3 讨论
在数据收集方面,选取了6 h作为数据收集的变化时间窗,但ICU患者的各项生理指标会随着时间的推移和病情的发展不断地变化。针对实验目标①,下一步工作将探索实现更小时间间隔的连续预测,同样每次采集6 h数据,但以更短时间间隔移动滑窗推进,如每隔3 h、1 h、15 min进行1次预测,甚至探索实时计算预测以更好支持临床决策。针对实验目标②,在[6n h, 6(n+1) h]数据采集窗下,LightGBM、SVM及LR均表明随移动滑窗推进,预测效果越好,且各模型的AUC在[18 h,24 h]数据采集窗中表现最高。本研究中数据采集窗的设置局限于入ICU第1天,可能一些重要指标的测量会放置在一天中最后1个单位时间里,导致[18 h,24 h]窗口预测效果最好。笔者将在下步研究中探索模型在 [24 h, 30 h]、[30 h, 36 h]、 [36 h,42 h]等窗口中的预测性能。未来工作也将向前压缩数据采集窗,如探索ICU前3个小时、前1个小时数据是否胜任AKI早期预测任务。
患者在ICU期间的用药、手术等事件也会对AKI的发生和预测产生影响,本实验中并未做深入研究。由于未使用非结构化数据,预测变量里没有考虑患者其他慢性病或者诊疗手段带来的影响。MIMIC-Ⅲ的时间跨度为12年,12年间诊疗方法和记录习惯都可能产生变化,利用大时间跨度的数据拥有大数据量优势的同时可能会导致数据缺乏时间维度上的一致性。
本研究应用最近值、汇聚方法处理电子病历中时态数据,本质上采用了单一值形式,即将单个特征值作为含有时间信息的特征的取值,并未将时态信息纳入到风险决策中,未考虑时间的前后联系。下步工作将考虑基于时序(temporal)方法[35]处理时序数据,即通过堆叠多个测量点值,或通过模型将前后时间的状态关联起来。另外,循环神经网络(recurrent neural network, RNN)模型是一类用于处理序列数据的神经网络,不同于前馈神经网络,其可利用内部记忆来处理任意时序的输入序列,下步研究将基于RNN开展AKI的连续预测。
本研究基于MIMIC-Ⅲ电子病历运用4种机器学习方法探索了重症老年患者早期AKI连续风险预测,分别基于以6 h为单位的当前数据和累积数据持续推进,连续预测患者在未来48 h的AKI发病情况。实验结果表明,应用LightGBM进行老年重症患者AKI连续风险预测具有一定可行性,RF、SVM、LR模型在连续预测中展现了相应的预测能力但尚未达到在真实场景中应用的水平。应用患者入ICU后的前6 h数据进行AKI早期预测切实可行,对比传统的24 h预测大大延长了医生治疗的反应时间。此外,研究显示不同模型对数据的接收能力和适用性不同,LightGBM青睐于当前数据,其他3种模型青睐于累积数据。
利益冲突所有作者均声明不存在利益冲突。
作者贡献声明钱庆: 提出研究思路,设计研究方案;孙海霞:设计研究方案,论文修改;邬金鸣:分析数据、论文撰写与修改;王嘉阳:数据采集与实验、数据分析。
