知识图谱:一种系统性构建因果图的方法
2022-07-14白永梅孙华鸽
白永梅 孙华鸽 杜 建
(1.北京大学医学部医学技术研究院,北京 100191;2.北京大学健康医疗大数据国家研究院,北京 100191;3. 北京大学医学部公共卫生学院,北京 100191;4.墨尔本大学数学与统计学院,澳大利亚墨尔本 3010)
随机对照试验(randomized controlled trial,RCT)是流行病学研究中进行因果推断的金标准,但由于时间效率、设计/实施难度、伦理等问题,在无法实施RCT的情况下,需要使用观察性数据(如电子健康档案、队列或生物样本库)进行因果建模[1]。基于观察性研究揭示暴露-结局之间因果关系的重要前提是,识别与暴露-结局相关的所有协变量(包括混杂变量、中介变量、对撞变量、工具变量)以及变量之间的复杂路径关系,以在因果建模中更科学地进行变量调整。目前指导因果建模的主要工具是有向无环图(directed acyclic graphs,DAG,也称因果图)[2]。DAG可以使研究假设更加明确,最大限度识别混杂因素[3]。DAG侧重于确定因果推断中主要的偏倚来源——混杂偏倚[4]。科学的因果关系推断策略制定必须建立在对所研究问题涉及的先验知识体系的整体认识和把握基础之上,但目前DAG的绘制主要依赖研究者的文献检索结果和专家经验,对于同一研究问题要么不交代所基于的因果图,要么研究者各自绘制因果图,具有局部性,在不同的研究者之间存在异质性和非标准化,在一定程度上影响了因果推断的科学性以及干预措施的真实效果。流行病学研究领域也在呼吁要构建系统性、标准化、可共享的混杂因素全球知识库,并在观察性研究中报告所采用的因果图,以提高研究质量、透明性和可重复性[5]。使全球范围内分散的研究整合起来,为制定有效的健康干预策略提供高质量科学证据。为解决目前DAG绘制的局部性、异质性和非标准化问题,本文从跨学科角度,将因果图定义为研究问题涉及概念(头概念和尾概念)及其所有第三方变量之间的复杂知识图谱。科技文献是先验知识最直接的体现,由科技文献生成的知识图谱本身就是对知识之间复杂关系的可视化表示,其中包含大量已经被证实的科学机制。从科技文献中识别这些机制,将其转换成可计算的形式,可以为构造复杂问题的解决模型提供支撑。利用科学文献中的知识主张抽取并整合成因果图,可为系统性生成因果图提供新的思路。本文尝试综述流行病学、计算机科学、生物医学信息学领域对该问题的研究进展,以期引入跨学科视角,提高因果图的产生效率和使用价值,推动因果图在观察性研究因果建模和机制解释中的应用。
1 因果图的基本结构
因果推断属于一整套推理框架,可以与统计学、心理学、机器学习等研究模型相衔接。因果推断的方法主要分为两大流派:一种是基于估计方程的统计学方法,一种是基于图网络的计算机方法;第二种方法是通过图网络将不同研究之间进行连接,从而实现RCT研究的再利用[6]。1999年,Greenland等[7]提出了应用于流行病学研究的因果图方法,主要用于区分混杂因素。后期该理论衍生出DAG。
以疫苗(暴露)和不良反应事件(结局)为例,当“暴露”和“结局”之间的关系未经过控制该因素的RCT研究时,该因素与“暴露”和“结局”之间有以下3种关系[8]:(1)当该因素同时影响“暴露”和“结局”时,该因素可能是“暴露”和“结局”之间的混杂因素。(2)当“暴露”通过该因素影响“结局”时,该因素可能是中介变量。(3)当“暴露”和“结局”同时作用于该因素时,该因素可能是对撞因子(图1)。
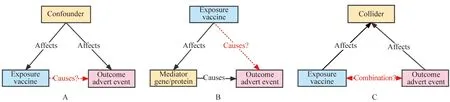
图1 因果图中的基本结构Fig.1 Basic structures in causal graphsA:confounder;B:mediator;C: collider.
1.1 混杂变量
来自电子健康病历(electronic health records,EHR)和公开数据库的临床和治疗数据为临床和流行病学研究带来了新的机会,但由于数据库存在的局限性,使其研究容易产生偏倚,混杂偏倚是最常见的偏倚类别(63.2%)[9]。在医学研究当中,混淆变量在很大程度上威胁着结论的可靠性,在DAG构建后,通过后门准则来判断explore和outcome之间的关系,其中“explore→outcome”为前门路径,“explore←confounder→outcome”为后门路径,常采用协变量校正、分层、匹配等方法来控制混杂,在阻断所有后门路径后,前门路径不成立,则证明confounder存在[10]。传统统计模型分析时,常通过自变量之间的共线性来进行变量相关性筛选,但往往根据自变量对结果变量的影响程度来确定自变量纳入排除的情况,整个判断过程是无向的。而DAG中可以清晰地看到所有潜在的混杂变量、通过关系的指向排除collider变量,为模型调整提供清晰的指引。
2021年Malec等[11]的研究通过从文献中提取的结构化的医学知识——三元组构建知识图谱,以发现潜在的“混杂因素”,将“候选”混杂因素合并到统计和因果图模型当中,利用已有的知识衍生发现“因果关系”,根据发现的新增混杂因素调整原有的Logistic回归模型中的变量,比较变量调整前后的模型可解释性,即通过相关研究中的数据假设检验和已经报道的效应值来进行验证。
1.2 中介变量
中介变量往往反映了作用机制。例如“药物对心脏病发作的预防作用是由它对血压水平的调节来介导的”。“介导”一词往往是中间变量的提示词和触发词。这句话其实编码了一个简单的因果模型:“药物→血压→心脏病发作”。在这个例子中,药物降低了血压水平,进而降低了心脏病发作的风险。所以,可以从医学文本中抽取因果主张。链式结构(图1B所表示的结构)中可能存在工具变量(instrumental variable,IV),IV指在链式结构中与随机扰动项不相关、与结局变量不相关,但可以通过影响explore来影响outcome的变量[12]。
1.3 封闭式发型和开放式发现
在因果主张的抽取过程中,基于文献的知识发现(literature-based discovery, LBD)将独立在文献中的知识通过逻辑关系进行连接,最后达到发现“未被发现的已知知识”的目的,如一组文献报告了A和B的关系,另一组完全不同的文献报告了B和C的关系,则提示A和C可能存在相关关系,这样的发现是有待验证的新知识[13-14],在判断A和C的关系是否独立于条件B的时候,通常采用D-分离来检验A和C关系的独立性。在“斯旺森雷诺氏病-鱼油”关系抽取示例中,雷诺氏病是起始术语,血液黏度、血小板聚集和血管反应性是连接术语,鱼油是目标术语[14]。
LBD通过统一医学语言系统(Unified Medical Language System, UMLS)来实现,有两种主要模式:封闭式发现和开放式发现,也分别称为双节点搜索和单节点搜索[13]。在封闭式发现中,LBD 的目标是帮助解释起始词和目标词之间的假设联系。最终结果是一组连接术语,描述了起始术语和目标术语如何相关(例如血液黏度、血小板聚集和血管反应性)。在开放式发现中,LBD 有助于找到与起始术语隐含关联的新概念[15]。这些新的联系可以提供新的见解,例如治疗疾病或缓解症状的物质(例如鱼油),如图2所示。这两种范式不是排他性的,使用开放发现生成的假设可以使用封闭发现生成的假设来解释。此外,无论哪种情况,LBD 的最终目标都是相同的——从文献中隐含的知识中产生假设。Knowledge discovery是数据驱动的,是计算科学家的主要工作;Scientific discovery是实验驱动的,是实验科学家的主要工作。正如基于LBD得到的“斯旺森雷诺氏病-鱼油”的推断在临床研究中得到了验证。
在大规模LBD研究中,2019年Nordon等[16]提出通过自动构建医疗数据之间的图谱来进行间接因果关系的发现,其数据来源于2 700万篇PubMed的医学摘要和150万条电子病历记录(electronic medical record, EMR)数据分别构建网络图,通过EMR中每位患者的主要诊断根据国际疾病分类(International Classification of Diseases, ICD)生成的疾病“相关性”图谱,用来自文献(先验知识)的疾病共病因果图对EMR文本生成的图谱进行修剪,专家对两个图合并结果打分来判断其制作的图谱精度,研究者称该方法较其他研究而言精度显著提高。该团队的另一项研究[17]则通过因果图路径来进行候选药物的生成和优先排序,使用医疗记录和生物医学文献中的因果线索来确定潜在药物的新用途。
单节点搜索旨在帮助正在寻找新假设的研究者,双节点搜索能够帮助确定现有假设中最有可能的那个假设(图2)。
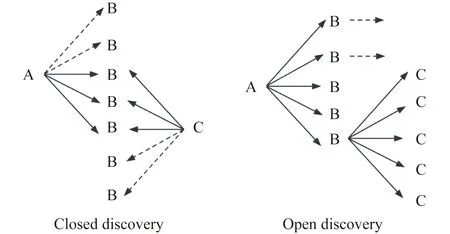
图2 封闭式发现和开放式发现Fig.2 Closed discovery and open discovery
双节点搜索策略的重要性体现在:(1)已经有了将A和C关联起来的假设(或初步实验发现),但没有任何已发表的文章对其进行了明确介绍,通过双节点搜索来探索两个实体之间的作用机制。
(2)在讨论A的文章集和讨论C的文章集之间进行双节点搜索,并寻找共有的B词,此时B词可能为A和C的中介变量。
(3)目的是对B词列表进行排序以找出最相关和最可能的链接,并研究A与C相关联的可能机制。
2 因果图的构建技术
2.1 NLP技术作为基础技术
自然语言处理(natural language processing, NLP)技术是基于以往研究[18]构建因果图必不可少的基础技术,核心在于从医学文本中生成结构化三元组。SemRep、集成网络和动态推理汇编器(integrated network and dynamical reasoning assembler, INDRA)等工具为医学文本关系的抽取提供了基础。SemRep使用语言学原理和UMLS的知识基础处理 PubMed 文章的摘要和题目,并从中提取语义关系。INDRA作为本文描述的方法和软件工具,描述了生物机制之间的关系,包含特定基因的所有已知信息,其类别遵循继承层次结构,所有语句类型都继承于父类语句[19]。
笔者团队基于美国国立卫生研究院SemMedDB数据库研发了结构化医学知识体系平台,实现从文献内提取结构化医学知识,包含超过9 400万条三元组及超过2亿条支持语句等元数据。相比其他平台,能够实现:(1)实体中英文映射;(2)中间变量的查询;(3)响应速度快,查询用时较少;(4)可直接下载逗号分隔值(comma-separated values,CSV)格式的三元组。结构化医学知识体系平台当前可以实现4个方面的应用:(1)三元组检索,在搜索框中输入关键词,可返回与该关键词相关的所有结构化医学知识三元组(图3A);(2)三元组路径推断,依据输入的关键词X和Y,从结构化医学知识数据库中检索X作用于Y的路径中的中间元素Z,返回X-Z-Y这一医学知识路径相关的所有医学知识三元组(图3B);(3)依据输入的PubMed文章ID,返回从该篇文章标题和摘要中提取的所有结构化医学知识三元组(图3C);(4)三元组及相关句检索,依据输入关键词,返回包含该关键词的所有相关句以及结构化医学知识三元组(图3D)。
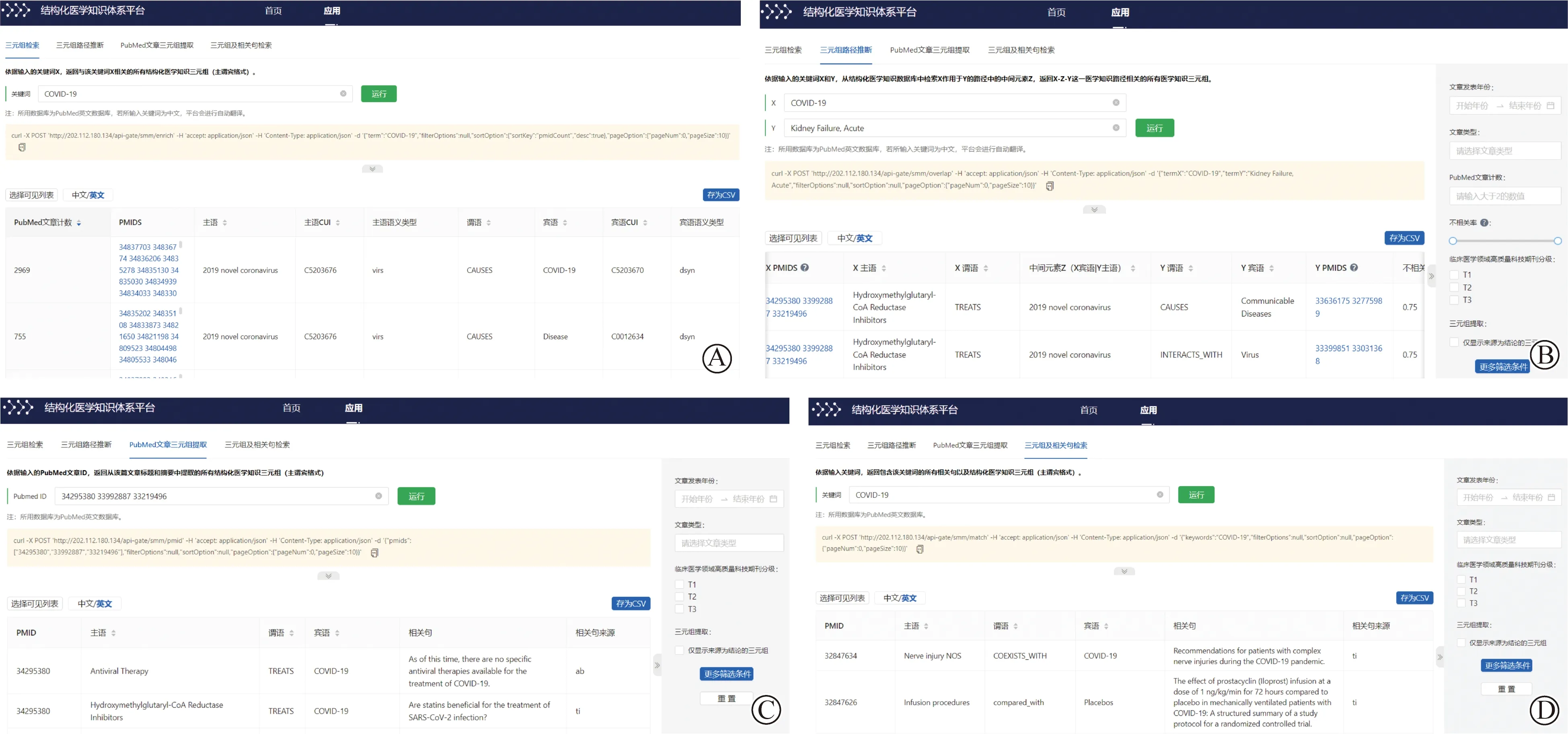
图3 结构化平台应用示例Fig.3 Examples of structured platform applications
2.2 将知识图谱转化为因果图
目前,因果推断(相对于相关性分析)是基于大数据的观察性研究的主要方法,因果图常通过DAG整合大量先验知识将复杂的因果关系可视化,已成为合理制定因果推断策略的重要工具。然而目前针对具体研究问题的因果图的构建主要依赖专家知识和经验,存在两个问题:一是仅从研究问题涉及的关键词出发的文献检索策略不同导致先验知识获取的召回率和准确率在不同的研究者之间存在异质性,无法反映从整个医学知识体系出发的系统性,无法实现标准化;二是目前构建的DAG多为浅层的变量之间的直接路径关系,无法反映变量之间复杂的间接路径关系。这引发了对系统化构建DAG的呼吁[20]。本文尝试从跨学科角度,将因果图定义为研究问题涉及概念(头概念和尾概念)及其所有第三方变量之间的复杂网络(图1),为系统化构建DAG提供新策略。
系统构建因果图的方法有两种:一是将知识图谱修剪为因果图。首先从医学文本中利用自然语言处理技术抽取“概念-关系-概念”三元组,然后将不同的医学文本生成的三元组整合起来,充分利用基于LBD进展,首先构建围绕特定问题的概念知识图谱,进而利用图算法(路径发现算法、D-分离等)将知识图谱修剪为因果图。二是将基于人群-干预/暴露-对照-结果(population-interventions/exposure-comparisons-outcomes,PI/ECO)框架的证据结论合成为因果图。通过文献检索和判读,将证据的结论转化为DAG,然后将多个证据的结论综合为集成的DAG,以系统构建根据已有证据确定纳入的变量以及变量之间的关系。
在医学研究[21]中,系统构建DAG分为以下几个步骤:(1)将每个研究的结论“映射”到DAG中;(2)利用若干因果推理原则,系统地评估这些DAG中的因果结构,并予以相应纠正;(3)生成的DAG将被合成为一个或多个“综合DAG”。当前可以进行知识可视化的工具非常多,通过这些工具可以将现有知识转化为知识图谱或图数据库,用于知识的查询、推理和可视化。如Neo4j、GraphDB、protégé、NetworkX包等。
基于国内外相关研究[22-24],本研究发现计算机科学的知识图谱和因果推断中的DAG结合起来的研究逐步兴起,通过分解因果图来消除混淆变量。在此基础上,通过统计学计算来进行因果推断,如倾向性评分(propensity score, PS)分配来均衡组间“混杂因素”的影响[22],差分法(difference in difference,DID)来比较暴露前后的差异[23],边际结构模型(marginal structural models,MSMs)允许在存在时间依赖性混杂的情况下估计时变暴露对结果的因果影响[24],2021年的研究[25]表明在连续性变量可以通过生成对抗去混杂(generative adversarial de-confounding, GAD)的算法来消除连续效果估计中的混杂因素。
3 因果图构建示例
EpiGraphDB(https://epigraphdb.org/)是一个由英国布里斯托大学综合流行病学研究所开发的图数据库,其中包含了众多生物医学和流行病学关系,与可被应用在健康数据科学中的分析平台[26]。当今,关于人类表型、风险因素、分子特征和治疗干预的丰富数据资源为健康科学提供了新的发展机遇,而如何更好地利用这些资源则需要不同数据集间的协调与整合。作为一个数据平台,EpiGraphDB中集成了因果、观察或遗传特征关系、文献挖掘获得的关系、生物学途径、蛋白质互作、药物靶标等资源,以支持风险因素、疾病关系等的数据挖掘。EpiGraphDB中包含了由文献证据构建的图谱常被应用在健康数据科学研究中。文献图谱的底层数据来源于美国国立卫生研究院的标准化语义数据库SemMedDB[27],该数据库中包含有PubMed中所有语句转化、映射出的语义三元组,即将自然语言标准化为主语-谓语-宾语的形式,并与UMLS标准词表对应,形成了可被应用于基于文献发现等方向的大型知识资源库。而EpiGraphDB中的文献图谱使用三元组作为节点,连接三元组所属的PubMed文献节点。查询时可通过直接搜索三元组中的主语或宾语,获得所有相关的三元组及有三元组出现过的PubMed文献,同时还可以限制谓语类型,获得更精确的查询结果。除了在网页上直接检索各个图谱中的数据,EpiGraphDB还提供API、R语言包、Cypher等检索方法。通过获取到的三元组,可以构建更有指向性的知识因果图等,用来辅助健康数据科学的研究。
因果图在医学研究[28-30]中主要以DAG为主,通过证据综合的方法来构建DAG可以将每个研究的结论都映射到DAG当中,通过网络图中基本结构的因果推断原则系统评价DAG中的结论,并予以适当纠正。如当前研究[31]通过DAG识别残疾和心电图结果之间的混杂变量,通过Logistic回归模型调整证明了统计学相关的因素为“混杂变量”。2021年的研究[32]发现,来自Scopus、Medline和Embase等数据库在1999-2017年间发表的出版物中,提及DAG和DAGitty的文献中有62%提供了DAG,48%报告了他们所提供的DAG的调整集。近些年来多项研究基于“知识图谱”批量构建不同文献中得到的结论之间的联系。Riseberg等[30]将暴露为“金属混合物”、结局为“心脏代谢”的系统综述结果进行汇总,构建DAG来确定潜在的混杂因素,并通过统计学模型来进行调整。基于该研究进展,笔者团队通过SemRep工具进行了新型冠状病毒肺炎(COVID-19)相关三元组的提取,并导入Neo4j进行知识图谱构建,将不同文献的结论连接起来。通过查询“疫苗→不良反应事件”的路径,其中三元组源于“托珠单抗→抑制→C反应蛋白”来源于PMID号为32531257的出版物(图4),三元组“C反应蛋白→更易于发生→呼吸衰竭”源于PMID号为34102804、32628003的出版物,从而构成完整的托珠单抗和呼吸衰竭之间的路径,使托珠单抗、呼吸衰竭、停止生命三个实体之间形成包含中介因子的完整路径。
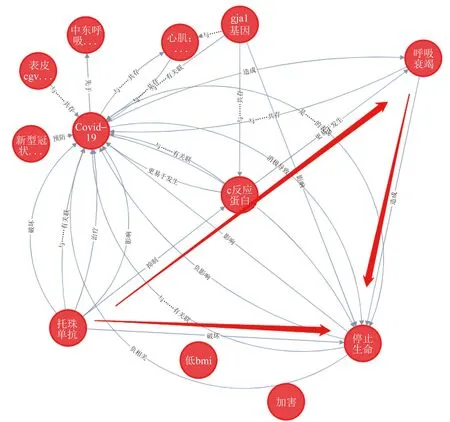
图4 因果图构建示例Fig.4 Example of causal graph construction
4 总结与展望
通过基于医学知识构建知识图谱的方法,极大提高了临床研究的二次利用率,相对于传统DAG构建或循证医学研究,因果图的构建极大提高了效率和信息召回率,且能够实现作用机制的建立和查询。
目前,LBD 是一个成熟的领域,具有不同的范式和系统设计,寻求自动化或半自动化的方式从现有文献中发现新的知识,可以在孤立的文献之间建立联系,增加跨学科信息共享。科学出版物的海量剧增凸显了LBD的重要性,它对加速知识获取和研究发展进程非常有益。
综上所述,与专家根据已有知识和经验构建DAG相比,通过信息学/数据科学系统基于LBD构建DAG主要分为以下几个步骤:(1)通过NLP技术来处理医学文本中已经存在的医学知识,将其结构化,在这个过程中可以使用超级叙词表来进行医学实体标准化映射;(2)通过计算机技术将结构化的医学知识转化为可视化、可查询的知识图谱和图数据库;(3)根据EMR、现有研究中的检验结果、设计RCT研究、专家审核、统计分析等方法来对知识图谱中的“路径查询”结果进行验证。
用图模型来高度概括因果关系可以实现既往研究的二次利用,建立研究之间的间接联系[4]。基于知识图谱构建因果图的相关研究仍然存在数据来源单一、多数据库融合性不足等问题。当构建图谱的数据来源局限于文献、EMR、数据库或临床试验时,所得到的医学实体之间的因果关系会存在召回率低、准确率低、仅表达相关性、可解释性差等缺点。数据库来源单一的情况则难以实现“基因-药物-临床研究-人群”多层面、可解释性强的因果推断路径构建。在今后的研究当中,可以考虑将不同层面的数据库作为信息来源,如“基因数据库”“临床试验数据库”“EMR”“出版物”等,通过自然语言处理技术构建医学实体之间的三元组,增强数据重复利用的价值,通过“基因-药物-临床研究-人群”等多层面的数据连接,来提高医学知识的可解释性。
利益冲突所有作者声明无利益冲突。
作者贡献声明白永梅:论文撰写、数据分析;孙华鸽:数据收集和抽取;杜建:研究设计和论文指导。
