基于注意力机制与端到端的中文文本纠错方法
2022-07-12王匆匆张仰森黄改娟
王匆匆 张仰森 黄改娟
(北京信息科技大学智能信息处理研究所 北京 100101) (网络文化与数字传播北京市重点实验室 北京 100101)
0 引 言
中文语句的自动纠错任务目前主要围绕着字词错误、搭配错误、语法及语义错误方面展开研究[1]。虽然语义错误的纠错普遍需要语义搭配知识库,但是语义搭配知识的提取方法普遍从语法搭配的角度或语句的表面层次提取搭配知识,进而不能从表述形式较为复杂的中文句子中提取出准确的语义搭配知识,这种现象造成了知识库在全面性、准确性和灵活性没有达到文本纠错的目的[2]。如果从语义搭配知识库角度解决中文文本语义纠错问题,那么文本错误检测就相当于基于知识库对文本内容的合理性进行打分,文本纠错相当于基于知识库和待检测语句的上下文对错误的文本内容进行推理所产生可接受纠错结果。基于知识库和推理的方法看似完美,可是这种方法对于机器处理文本纠错问题而言可行性较低。原因在于如果将具有语义推理能力的知识图谱所存储的语义知识库应用到中文语句的推理中,正确的文本会满足推理过程,而对错误文本的纠错建议生成会受到知识容量和质量的限制,尤其是面对中文文本的数据量大的现象,这将会存在纠错模型缺乏大量训练数据的问题。鉴于上述分析,本文认为文本纠错任务需要从大规模的中文语料中学习出一套纠错机制,于是提出了一种基于注意力机制与端到端的中文文本纠错方法。
在文本纠错模型的选取层面,基于深度学习的自然语言处理模型目前主要从循环神经网络向词语位置编码加语句内容的方向转变[4],端到端学习的思想已经被广泛利用到机器翻译、智能问答等领域[5]。本文将端到端的思想和方法应用到中文文本的自动纠错工作中,使用基于词语位置编码向量加语句内容向量的模型生成中间语句的语义向量,然后对语义向量进行解码生成纠错后的句子。在语义向量的编码与解码过程中,本文使用了注意力机制发现文本词语的潜在依赖关系及语义特征,避免了循环神经网络及其变体只将两个单向的隐藏节点合并输出所引起的语义关系弱及单项语义编码的问题。如表1所示,文本纠错任务的特点是训练语料中原语句与目标语句之间的词语重复率达到80%之上,即纠错后的句子复制了许多原句子中正确的部分。鉴于此,本文通过增加一个句子成分不改变的机制使端到端的纠错模型更加贴近纠错任务的场景。另外,本文基于大规模无标注的中文语料提出一种平行纠错语料的构建方法,为解决缺乏纠错语料的问题提供了一种思路。

表1 训练语料中原语句与目标语句包含字的重复率
本文的主要贡献有以下三方面:① 提出了一个用于文本纠错神经网络架构,该架构能够直接从待校对语句中复制原本正确的词语和超出词典范围的词语;② 使用大规模非标注数据预训练了基于复制机制的纠错模型,缓解了文本纠错工作缺乏语料的问题;③ 在NLPCC2018的中文纠错测试集上取得最好的结果。
1 相关工作
1.1 基于深度学习的中文文本纠错方法
文献[6]结合HowNet义原知识库与中文语料库,使用双层LSTM网络构建语义搭配关系错误预测模型,然后基于词语之间的互信息、词语义原之间的聚合度提供纠错建议。基于LSTM网络的语义纠错模型会将错误信息与前面信息参与语义计算,这影响语义错误检测模型学习待检测句子全局信息的能力。文献[6]的纠错模型仅仅从词语义原和语句层面上获取的纠错建议,没有完全符合待检测句子的语境。文献[7]提出了基于易混淆词语集与序列标注任务的中文文本纠错算法,通过引入待校对词语上下文和基于易混淆词集的纠错词集的方法对语义错误进行自动纠错。由于该方法受限于训练语料数量较少,不能对语句进行语义表征层面上的纠错。文献[8]使用基于RNN和端到端模型的机器翻译模型对中文语句中的错别字进行纠错,实验表明基于单纯基于RNN的神经机器翻译模型处理文本纠错的效果较差,仍需要结合N-gram模型,主要原因在于基于RNN的自然语言处理模型的梯度消失和词语依赖强度弱的问题,本质上该模型仍是一个马尔可夫决策模型。目前的注意力机制能够发现中文词语之间的依存关系,改善自动纠错效果。
文献[9]主要通过5-gram评分选取五个小模型所产生文本纠错的最优结果作为纠错建议。文献[10]使用了基于规则的统计模型、基于统计机器翻译纠错模型和基于LSTM的翻译模型,将两个基于字与词的统计机器翻译纠错结果和四个神经机器翻译的结果分别进行低级合并,最后将基于规则、统计和神经网络的结果通过冲突算法对多个纠错结果进行高级结合得到纠错结果。文献[11]使用的是基于卷积神经网络的端到端纠错模型,通过卷积神经网络计算循环神经网络产生的语义编码向量的注意力然后解码出纠错结果。这三种纠错模型都通过使用一个更大的中文语言模型取得了较好的结果
1.2 基于统计方法和神经网络的英文文本纠错
早期的英文文本纠错建立了具体的错误类型分类,然后将错误类型的分类进行融合,并建立了相应的语法纠正方法,之后文本的语法错误纠正利用了统计机器翻译模型与大规模的纠错语料取得良好效果。文献[12-13]指出了错误分类与机器翻译方法的弊端,统计机器翻译(SMT)模型虽然能够记住一些短语所在的纠错语句,但是不能生成一些从未被训练的文本内容。目前基于神经机器翻译的校对方法在英文语法错误校对任务中展现出强大的语法错误校对能力。文献[14]针对语法错误检测建立了一个基于神经网络的序列标注模型,该模型对词语的正误进行标注,然后使用标注结果的特征,重新排列Nbest假设。文献[15]提出了一个协调词语与字母级别信息的混合神经网络模型。文献[16]使用了一个多层卷积的端到端模型,该纠错模型超越了所有之前基于神经网络与统计方法的纠错系统。而文献[17]则是基于序列到序列的架构和推理机制纠错语法错误。文献[18]尝试使用RNN与Transformer端到端模型并取得了更好的纠错结果。
2 方法设计
2.1 基于复制机制的纠错模型
基于神经网络的机器翻译模型在文本纠错任务上已经取得了实质上的提升[18]。翻译模型通过将待检测句子作为源句子并将文本纠错后的语句作为目标句子,学习了源句子到目标句子之间的对应关系。本文将中文文本纠错任务当作是一个翻译工作。具体而言,本文研究的目标是让神经网络学习平行纠错语料的正误语义对应关系,并将错误语句翻译成正确语句。但是不同于传统的机器翻译任务,中文纠错任务不但包含了多种错误类型,而且使用的纠错平行语料中会存在语料稀疏的问题。传统的中文纠错任务主要处理冗余、缺字、用字不当和位置错误四种错误类型,本文没有具体区分各种错误类型,而是使用了两种注意力机制,即编码解码注意力机制和复制注意力机制学习纠错任务。纠错模型的基础架构使用了基于注意力机制的Transformer[4]架构,它包含了多个对输入的源句子进行编码的模块。其中每个模块都是用了多头自注意力机制从原句子中获取带有词语位置信息的语义向量,然后通过前向传播层输出语义向量的隐藏状态。基础模型的解码器也是使用了多模块、多头注意力机制,使用前向传播网络对隐藏状态进行解码。
基础架构的目标是预测在一个序列y1,y2,…,yT在t位置的字,在给定源句子x1,x2,…,xN的前提下:
(1)
(2)
pt(w)=softmax(Ltrght)
(3)
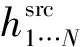
(4)
文献[19]在文本摘要任务上和文献[20]在语义解析任务上证明了复制机制是有效的,因此本文添加了在文本纠错上的复制机制,增强了纠错模型从源句子复制正确词语的能力。
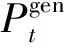
(5)

图1 复制机制架构
该架构通过目标隐藏状态的概率分布作为一个基础模型。在源句子上的复制因子是通过计算一个新的注意力分布,该注意力分布是基于编码的隐藏状态与当前解码的隐藏状态计算得出的,复制的注意力也是用相应的编码与解码机制。
(6)
(7)
(8)

(9)

2.2 预训练降噪自动编码器
当缺乏大量训练数据时,预训练在很多任务中被证明是非常有用的。因此,本文使用了部分预训练的方法在参数初始化的时候从输入中抽取特征[21]。考虑到BERT模型使用了一个预训练双向Transformer模型在当前许多NLP任务中取得了最优表现,它预测了15%被遮住的单字,而不是重建整个输入句子,并降噪了随机抽取的15%的字符,在随机抽取的15%词语中,其中80%被替换为MASK,10%被替换为随机的词,10%没有被改变。受BERT的和自动降噪编码方法的启发,本文在降噪非标注的大规模中文语料的基础上预训练基于复制机制的纠错模型。实验对含有错误的句子的数据生成步骤如下:(1) 删除一个字符的概率为10%;(2) 增加一个字符的概率为10%;(3) 使用字典中任意一个字符替换字概率为10%;(4) 重新排列字的顺序,通过对每个原始字的位置编码增加一个标准差为0.5的正态分布权重,然后将新的位置编码从小到大排序,提取出原始位置编码列表的索引位置作乱序后的字排列。
使用上述的文本错误生成方法所产生的错误句子与原句子配对,这在某种程度上可以算作一条纠错语料,因为该错误语句与人为错误语句都是由字的增、删、替换和重新排列操作所造成的。
2.3 预训练解码器
在NLP任务中,预训练模型能够提升下游任务的表现,如Word2Vec[22]、GloVe[23]和ELMo[24]等。借鉴文献[25]的方法,本文预训练了基于复制机制的端到端纠错模型的解码器。首先,使用预训练参数初始化纠错模型的解码器,然后随机初始化其他参数。因为在编码器与解码器之间使用了连续的字嵌入,除了编码器、编码与解码间的注意力和复制注意力之间的参数,其余的参数都能被预训练。
3 实验与结果分析
3.1 数据集
本文使用了2016年—2018年的CGED中文语法错误诊断数据集、SIGHAN2014、SIGHAN2015、NLPCC2018语法纠错数据集、LANG-8和中文维基百科作为并行训练语料,将NLPCC2018的中文语法错误纠错任务测试集作为测试语料。表2和表3列出了本文使用的数据集信息。
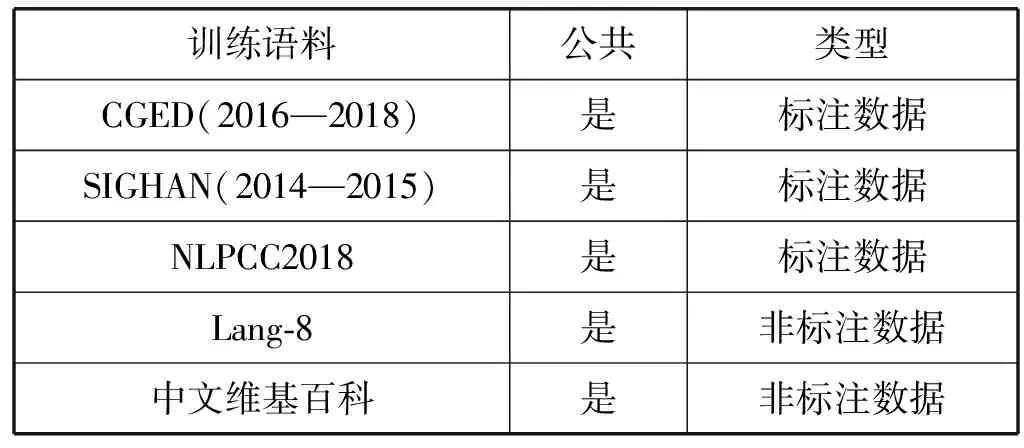
表2 训练语料

表3 测试语料
3.2 模型参数
本文在公共的端到端工具Fairseq上使用了已经实现的Transformer模型,并将字嵌入和隐藏层维度设为512,编码器与解码器层数为6,注意力模块为8。在内部的层次前向传播网络使用了4 096维度。设置Dropout为0.2,这个模型总共有97 MB的参数。
在优化神经网络方面,使用Nesterovs[26]加速梯度下降法,学习率为0.002,衰减率为0.5,动量为0.99,最小学习率为0.000 4。
本文也使用了加权极大似然估计方法缩放平衡因子Λ以改变词的损失[18]。训练文本纠错模型和预训练模型的区别在于,当预训练降噪自编码模型时设置Λ=3,纠错时Λ∈[1,1.8],在解码时,设置beamsize为12。
3.3 评价指标
文本纠错任务的目标是改正句子中的错误字,模型将错误语句的编辑与标准编辑集合的匹配程度作为评价依据。评价指标包括准确率(Precision)、召回率(Recall)及F0.5。假设e是模型对错误文本纠错建议的集合,ge是该错误文本的标准的纠错建议集合,具体的计算方式如下:
(10)
(11)
(12)
式中:|ei∩gei|表示模型针对句子纠错建议集合与标准纠错建议集合的匹配数量。gi表示句子i中的全部错误组成的集合,具体计算式为:
|ei∩gei|={e∈ei|∃g∈gi,match(e,g)}
(13)
语法纠错任务选择F0.5作为评价指标而非F1值的原因在于,对于模型纠正的错误中,纠错的准确性大于纠错建议数量,所以将准确率的权重定为召回率的两倍大小,以期得到一个更加优质的纠错模型。
3.4 多任务学习
多任务学习主要通过联合训练多种相关的任务解决问题,实验证明多任务学习在许多任务中都有优势,如计算机视觉[27-28]与NLP[29-30]任务。本文探索了两种不同的任务对于语法纠错模型以提高其表现。
3.4.1字级别的标注任务
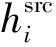
(14)
通过字级别的标注任务明显地增强了编码器关于输入字的正确性,也有助于解码器的识别。
3.4.2句子级别复制工作
句子级别的复制工作的动机是使模型在输入句子是正确的情况下加强纠错建议从输入句子复制字词的比例。训练时将同样数量的正确句子对与修改过的句子对送入模型。当输入正确句子时,移除了解码器对编码器的注意力向量。没有了编码解码之间的注意力,原本正确句子生成工作会变得很困难,但是经过模型的复制部分将会被正确的句子加强。
3.5 实验结果
表4对比了基于神经网络机器翻译的纠错模型、基于统计和神经机器翻译的纠错模型、序列到序列纠错模型及本文的模型用于中文语义纠错得到准确率、召回率与F0.5值。

表4 纠错模型对比实验结果(%)
本文的复制增强型架构在使用与训练参数的情况下相较神经机器翻译模型[9]准确率提升了7.24百分点,并超过了文献[10]方法1.48百分点,说明了本文复制增强性架构对比传统的Transformer在纠错任务上使用的复制注意力机制学习了文本的正确部分与错误部分的区分特征,并且本文模型在召回率比传统的LSTM的纠错模型提高了11.35百分点,表明了纠错模型中注意力机制的重要性,避免了LSTM的语义长期依赖较弱的弊端。文献[11]所提出的模型虽然架构较为原始,但是它们集成了四个纠错模型的结果并使用了字节对编码算法降低生词的困扰,在准确率上超过了本文复制增强型模型4.15百分点,表明了未登录词和适量的增加模型参数量对纠错任务的提升较明显。但是当使用降噪自动编码的方法后,模型学习了更多中文语料中的错误词语特征和纠错建议生成特征,在NLPCC2018数据集上的F0.5为42.64%,在召回率和准确率上都超过了文献[9]所提供的方法。综上,无论是传统的Transformer还是本文模型,都能在召回率上超过RNN及一系列变体网络,可见注意力机制和基于词语位置编码的语义编码模型是目前纠错任务不可缺少的一部分。
表5对比了基于复制机制和降噪自动编码Tansformer模型处理冗余、缺字、用字不当和位置错误四种错误类型的表现。实验数据集采用了具有错误类型标注的2016年—2018年的CGED中文语法错误诊断测试集。
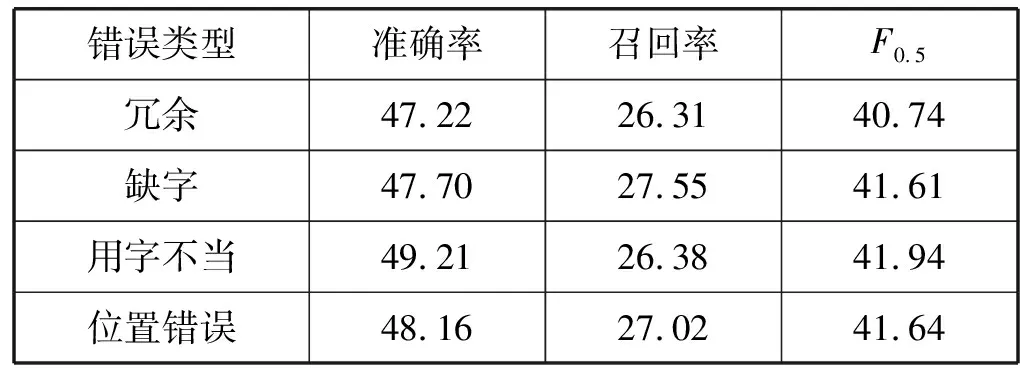
表5 四种错误类型实验结果(%)
从表5可知,本文模型处理用字不当和位置错误的准确率比另两种错误更高,但提升量均在2百分点以内。用字不当错误的准确率较高,可能是因为相较其他错误类型,该错误提供了较多的可被模型利用的错误信息。而冗余字的错误准确率最低,则可能是由于冗余字所提供的错误信息相较其他错误类型更加繁杂,干扰了模型的纠错准确率。此外,在召回率和F0.5值上,本文模型表现出较为平稳的实验数据。
3.6 消融实验
3.6.1复制机制消融实验结果
下面通过实验比较在文本纠错任务上本文的复制机制与自注意力机制对Transformer结构纠错结果的影响。如表6所示,复制增强型的模型将F0.5分数从29.91%提高到37.31%,增加了8.3百分点。提升的原因在于基础模型把超出字典的字预测成一个未登录标记UNK,但是在复制增强型模型上将未识别的字直接复制到所生成的句子中。
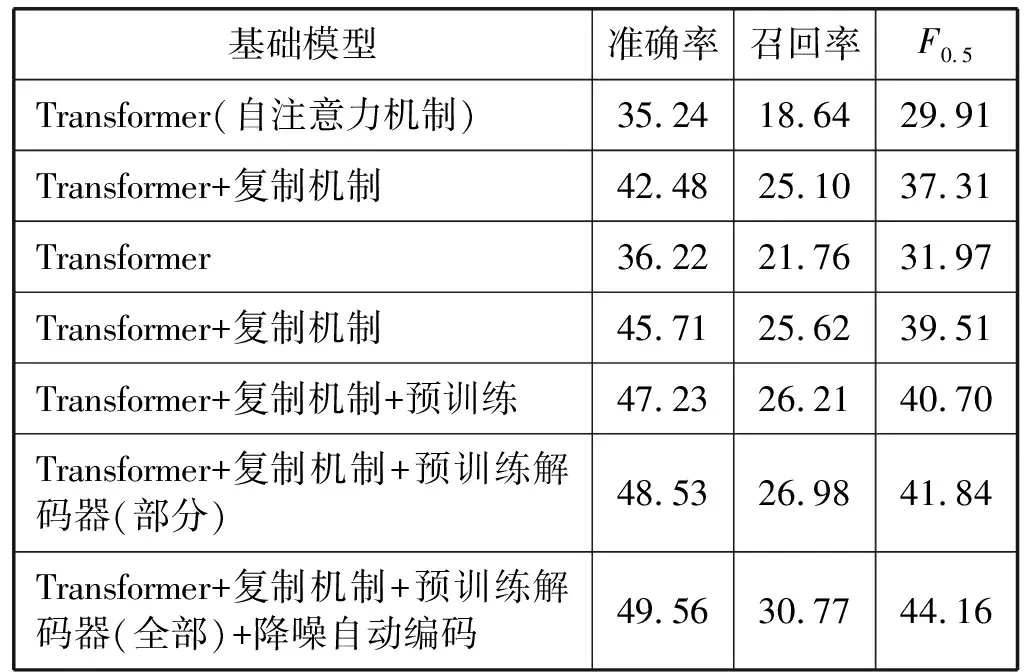
表6 消融实验结果(%)
复制机制被广泛用于处理未登录字,实验通过忽略所有的未登录字来验证复制是否真正地复制了那些不知道的字。从表6可知,即使忽略未登录字带来了提升,复制模型仍然相较于基础模型在F0.5分数上提升了7.54百分点,并且大多数是通过增加精确率提升的。
3.6.2预训练消融实验结果
从表6可知,通过预训练部分解码器,F0.5分数从40.70%提升到41.84%,相较于未预训练的方式提高了1.14百分点,当降噪自动编码器全部预训练参数时,模型F0.5分数从40.70%提升到49.56%。
为了进一步调查预训练参数的优势,本文展示了早期是否含有降噪解码预训练参数的性能改善情况在表7。结果显示,如果使用标注训练数据一轮后的参数微调模型,预训练模型F0.5分数比未预训练模型从25.32%提升到35.06%。即使没有微调,预训练模型可以得到F0.5分数为25.32%。这证明了预训练带给模型比随机参数更好的初始参数。
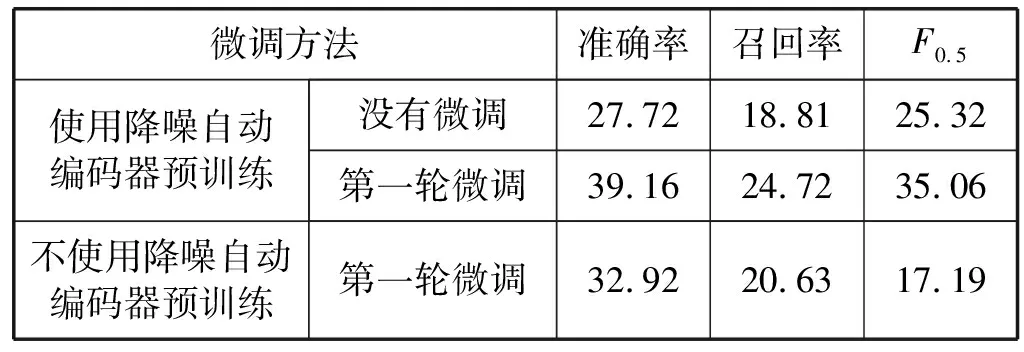
表7 NLPCC2018测试集预训练测试结果(%)
3.6.3句子级别的复制任务消融结果
为了证实增加句子级别的复制任务对正句子与错误句子的识别情况,本文创建了一个正确句子集通过挑选维基百科中的500个句子,挑选NLPCC2018测试集中的数据生成一个错误句子集。之后计算了两个测试集的平衡因子的平均值。在增加句子级别的复制工作中,复制因子对于正确句子集和错误句子集分别是0.44和0.45。通过增加句子级别的复制任务,平衡因子的值分别为0.81和0.57。这意味着81%的最终分数来自于正确的复制句子集,但在错误句子集上仅有57%的分数。因此,通过增加句子级别的复制工作,模型学习了如何区分正确句子与错误句子。
为了分析复制注意力与编码解码注意力的差异,图2和图3可视化了复制注意力分布和编码解码注意力分布。复制注意力的权重更加偏向于下一个字,使语句顺序变得准确。而编码解码注意力更加偏向于其他字,例如,相近的字或者句子的尾部。正如文献[30]所解释的,这意味着生成部分试图去发现更长距离的依赖关系并且更加关注于全局信息。通过从自动生成工作中分离复制工作,模型的生成部分能够聚焦于创造性的工作。

图2 复制注意力分布

图3 编码解码注意力分布
4 结 语
本文对于中文文本纠错任务提出了一种基于复制机制的纠错架构,通过直接复制未改变的词语和超出所输入原句子的词典的词语提升了端到端模型的能力,并使用大规模非标注的数据和降噪自动编码器完全预训练了复制机制的架构。此外,在多任务学习方面引入了两个额外的任务。实验结果表明,本文方法超过了其他中文文本纠错方法。
