基于代码上下文相似度分析的代码问题修复推荐方法
2022-07-12吴毅坚沈立炜赵文耘
刘 霜 吴毅坚 沈立炜 赵文耘
1(复旦大学软件学院 上海 201203) 2(复旦大学计算机科学技术学院 上海 201203) 3(上海市数据科学重点实验室 上海 201203)
0 引 言
软件系统的开发过程中,不可避免会出现代码问题。在成千上万甚至百万行代码的大型项目中找到问题并修复是一件困难的事情,因此,研究人员多年来致力于代码问题自动修复技术的研究。代码问题自动修复是在没有人工干预的情况下自动修复软件问题。即对于不满足正确约束的程序,生成满足程序约束的补丁[1-2]。这种技术的基本目的是自动生成正确的补丁,消除软件程序中错误的补丁程序[3-4]。工业界也很关注代码问题自动修复技术,如Simfix、CBCD、PRECFIX[5]已步入应用。
本文介绍的推荐方法适用于代码静态分析检测到的问题(Issue)。静态分析检测到的问题一般有三类,包括编程错误、违反标准的编码、安全弱点,后面简称为代码问题。代码静态分析是一种通过在运行程序之前检查源代码进行调试的方法,通过针对一组(或多组)编码规则分析一组代码来完成,相关工具包括FindBugs、SonarQube、Helix QAC、Klocwork等。
静态分析尤其擅长发现编码问题,例如缓冲区溢出、内存泄漏和空指针。当程序开发人员碰到缓冲区溢出问题时,由于提示信息往往仅包括问题类型和位置,可能无法马上知道该如何修改。而同时,该类问题有很多历史修复,它们对应的问题类型、出问题的代码及问题的代码上下文可能是类似的,于是这些历史修复可作为推荐方案。然而如何进行方案推荐并不容易,首先,每种问题类型有着太多被正确修复过的源代码文件,难以判定这些源代码文件的历史修复中哪个或哪些是我们需要的;再者,每种问题类型有着太多的历史修复,修复方式也是多种多样,难以从如此多的历史修复中有效率地推荐出一个有效的方案;最后,面对一个曾经被正确修复过的源代码文件,难以找到它针对该问题的修复方式。
针对这些问题,本文提出一种基于代码上下文相似度分析的代码问题修复推荐方法。该方法首先收集历史版本中代码问题的修复案例,建立问题修复资源库,然后根据问题类型、问题代码及上下文、修复代码及上下文对修复案例进行聚类,对每种不同类型的问题建立修复模板,最后通过对有同类问题的目标代码及其上下文进行相似性分析,从而推荐具体的修复方式。基于上述方法,设计并实现一个基于代码上下文相似度分析的代码问题修复推荐工具。
1 本文方法
1.1 研究动机
众所周知,修复软件项目中的各种问题是一件非常困难且大量耗费时间精力的事情。据统计,修复软件问题的时间占软件维护时间成本的35.6%[6],软件成本的绝大多数被认为是软件维护成本。开发人员花在修复问题上的时间占全部开发时间一半左右[7]。
静态代码分析是在软件开发的早期,即运行程序之前(例如,在编码和单元测试之间)进行的。静态代码分析可以尽早发现问题。静态代码分析可以通过创建自动反馈循环来支持DevOps。开发人员将及早知道他们的代码中是否存在问题,此时解决这些问题将更加容易。静态分析相比于动态分析更容易发现编码错误,因为某些编码错误可能不会在单元测试期间发生。因此,静态代码分析(特别是在需要遵守行业标准的情况下)有不少优势。
目前学术界进行问题修复的前提基于两个假设,测试用例的充分性假设(测试用例是否完全反映程序的正确性)和被修复代码的高质量假设[26],因此通过测试不总是等于完成修复,存在精确性不够高的问题。很多问题修复技术只针对某种类型的问题设计了修复算法。很多修复技术耗时长,计算资源消耗多。
针对自动修复技术存在的各种问题,以及需要人工确认的局限性,在工程上,我们可以采用修复方式推荐的策略来帮助程序开发人员更快更好地理解并修复代码问题。因此本文提出基于代码上下文相似度分析的代码问题修复推荐方法,这是一种问题修复的通用技术,它无须基于两个假设,生成的推荐方法能够尽量避免引入其他的问题,且通过问题类型、问题代码及上下文和修复代码及上下文聚类方法提高了推荐效果及问题修复效率。
1.2 方法概述
基于代码上下文相似度分析的代码问题修复推荐方法过程,主要包括以下两个步骤。
(1) 问题修复案例(case)的归类和存储。图1展示了该步骤,首先通过静态分析工具(如FindBugs)获取问题版本的问题类型、问题代码及上下文,通过diff分析获取修复版本的修复代码及上下文,这些信息作为一条修复案例。然后根据问题类型、问题代码及上下文、修复代码及上下文对修复案例进行聚类。最后,将修复案例抽象化,形成修复模板。将修复案例及模板存储起来,作为问题修复资源库。
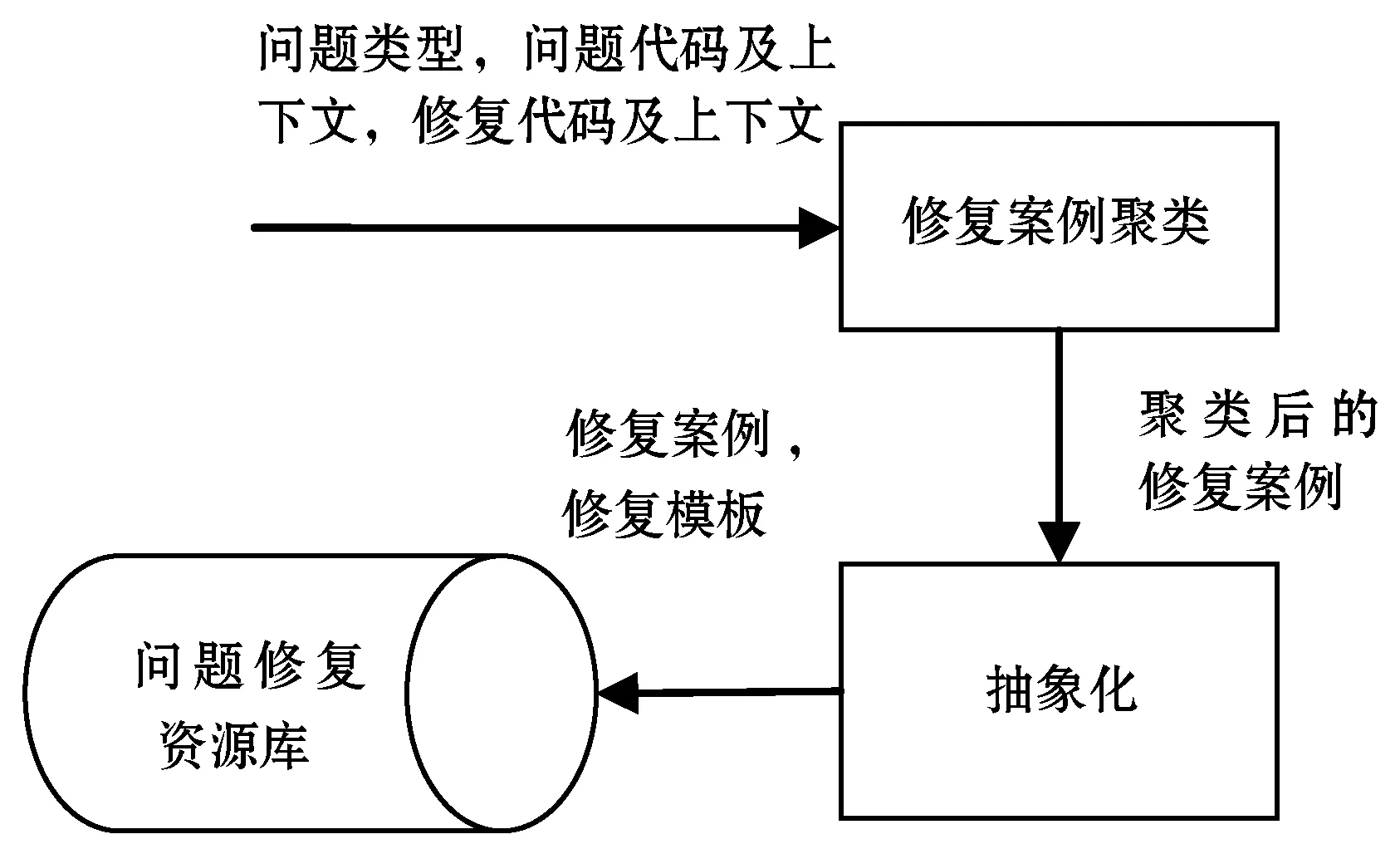
图1 问题修复案例的归类和存储
(2) 代码问题修复推荐。图2展示了该步骤,以目标问题类型、问题代码及其上下文代码为输入,结合问题修复资源库中相应类型的问题代码及其上下文的相似度匹配,进行问题修复案例推荐。本文提出基于代码上下文相似度分析的代码问题修复推荐方法,对输入问题及其上下文代码进行Token化后的文本相似度分析,找出相似度最高的几种修复方式,为用户进行问题修复推荐。
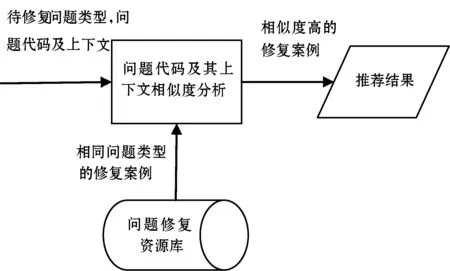
图2 代码问题修复推荐
1.3 代码问题修复推荐方法的设计与实现
1.3.1问题修复案例的归类和存储
通过解析静态分析工具(如FindBugs)的结果文件,得到问题版本的问题类型、问题代码及上下文。通过diff分析得到解决版本的修复代码及上下文。本文将每个历史已解决问题的类型、问题代码及上下文、修复代码及上下文构造为一个修复案例,将它们保存在问题修复资源库。
同种问题可能有多种不同的修复方式,但修复资源库中针对同种问题的修复案例所采用的修复方式可能会存在较多重复,所以需要对同种问题类型中的修复案例根据修复方式进行聚类。具体对于某种问题的所有修复案例,其聚类方法是:首先,对于每个修复案例,将其问题代码及上下文、修复代码及上下文进行分词,这里主要按空格和调用符进行划分,接着采用词袋模型将这些分词构建为词频向量。最后对词频向量进行加权处理,以提升其中关键字的权重。最终每个修复案例被表示为一个加权的特征向量,其形式为:D=D(T1,W1;T2,W2;…;Tn,Wn),其中:T为分词;W为权重;n为词汇空间的大小,其由该问题所有修复案例的分词种类数决定。最后使用凝聚层次聚类算法对这些特征向量进行聚类,聚为一类的案例本文认为有着相同的修复方式。
图3展示了一个NP_NULL_ON_SOME_PATH问题类型的修复案例,其中:(a)展示的是问题修复前的代码段,①②是问题代码(FindBugs结果解析出的),其他的都是上下文代码;(b)展示的是问题修复后的代码段,①是修复代码(问题代码及上下文修复前后的diff),其他的都是上下文代码。上下文代码会用来计算代码相似度,从而提高推荐效果。具有相似上下文的代码问题会在推荐结果里排序更高。经过分词,统计出每个词语的出现次数,构建其词频向量为:
{if,4;_injectableValues,4;null,4;return,4;findInjectableValue,2;valueId,3;this,4;forProperty,3;beanInstance,2;throw,2;new,2;IllegalStateException,2;No,1;injectableValues,1;configured,1;can,1;not,1;inject,1;value,1;with,1;id,1;}


图3 NP_NULL_ON_SOME_PATH修复案例- 修复前后代码段
虽然词袋模型没有考虑词在代码中的顺序,但其简单高效,并且经过加权处理,在有限的修复案例中可以达到良好的效果。
使用上述修复案例聚类算法,发现每种代码问题的修复方式一般分为一种或多种,例如NP_NULL_ON_SOME_PATH问题的修复方式一般有五种,且模式较为固定。
1) 对可能为空的变量进行null值判断的操作加上else分支,可能出现异常的操作放在else分支中运行。
2) 先判断变量是否为null值,如果为空直接抛异常。
3) 原问题代码中没有if-else语句的,在修复代码中添加if-else,在if语句中对变量进行null值判断,可能出现异常的语句在else分支中运行。
4) 先判断变量是否为null值,如果为空直接进行return操作。
5) 在变量赋值的语句中,变赋值为null为赋值一个实例。
图3(b)展示了NP_NULL_ON_SOME_PATH问题修复案例的修复后代码段,该案例使用了第二种修复方式,即先判断变量是否为null值,如果为空直接抛异常的方式进行修复。
修复案例聚类完成后,对其进行抽象化处理,形成修复模板。抽象处理过程为:将变量名按其出现的次序替换为MYM1、MYM2等;将基本数据类型分别初始化为其默认值;对于自定义的函数按其出现顺序统一替换为f1、f2等;所有操作符、关键字保持不变;去掉注释和多余的空行,统一缩进。本文认为每个修复案例抽象化后都是一个修复模板。一个修复模板包括问题类型、问题代码及上下文(抽象化的)、修复代码及上下文(抽象化的)。
1.3.2代码问题修复推荐
本文提出的基于代码上下文相似度分析的代码问题修复推荐算法基于问题类型、问题代码及其上下文的文本相似度(基于编辑距离),能够为用户推荐与其问题最为相似的修复方式。问题类型指根据代码静态分析结果得到代码问题的类型。问题代码指根据代码静态分析得到的具体问题代码行。问题代码上下文指根据代码静态分析得到的与具体问题行相关的上下文代码,它是根据具体问题类型的具体特点得到的、与问题发生原因紧密联系的代码内容。以上所需可以通过代码静态分析的结果文件得到(例如通过分析FindBugs结果文件)。该算法将目标问题代码及其上下文与资源库中的相同问题类型的问题记录的问题代码及其上下文进行(基于有限自动机的Token化后的)文本相似度匹配,选择相似度高的、历史出现次数多的修复方式进行推荐。
2 实 验
2.1 工具实现
基于本文方法,研发了基于代码上下文相似度分析的代码问题修复推荐工具。问题推荐工具可分析目标项目内的已修复问题的修复方式并对其进行聚类和建模,构建问题修复资源库,然后根据目标问题代码及其上下文匹配资源库内的问题修复记录,选择相似度高的进行修复推荐。
2.2 实验评价
实验选取Github上的高星开源项目作为实验对象,代码问题修复资源库则选择本文资源库进行实验。本文根据实验目的分别设置不同的实验,分析了工具的聚类效果及推荐效果的有效性,并且对本文代码问题修复推荐方法的局限性进行说明,最后将本文工具与“Nopol”进行对比。
2.2.1聚类效果的有效性评估
在基于代码相似度分析的问题修复推荐方法中,使用问题代码及其上下文聚类、问题修复方式聚类方法进行了优化,提高了推荐的效果。本实验选取了Github上的高星开源项目的50条历史修复案例,用聚类方法对其进行聚类操作,对其实验结果进行评估,验证其正确性、有效性。
这50条历史修复案例分为七种问题类型,其中第一、第二、第五种问题类型只有一条修复案例,无须进行聚类,将其剔除。剩余47条历史修复案例的聚类实验结果如图4所示。

图4 聚类实验结果
47条修复案例分为4种问题类型。图4展示了每种问题类型的案例条数。只有同种问题类型的案例才能进行聚类。如问题类型三的20条修复案例,通过修复案例聚类将该20条修复案例聚为了4类,即该类型的代码问题历史上有4种修复方式。其余问题类型的聚类以此类推。
本文挑选了6位具有程序开发研究背景和经验的硕士生,其中4位每人负责一种问题类型,对聚类结果的正确性进行人工验证,其余2位对原始的47条修复案例分别进行人工分析归类。针对聚类效果评估实验,参与者得到的信息包括50条修复案例的问题类型、问题代码及上下文代码、提交日期、修复方式代码及上下文等。他们可以访问修复推荐系统,了解聚类方法的主要功能和流程,可以看到该方法的数据模型和源码,也可以查看聚类方法的中间信息及结果信息。
实验发现,验证类型三、类型四、类型六的硕士生表示他们认为系统的聚类结果是正确的,即聚类方法对这三种问题类型的聚类类别个数以及每一类的修复案例划分是正确的。验证类型七的硕士研究生表示这7个修复案例应聚为4类而不是聚类所得的3类。即实验结果中的问题类型七的三种修复方式中的第1类(图4中标有星号的类别)应该聚为两类。这两类中的2种修复方式的代码非常类似,但是他认为划分为2种修复方式更为精确,其余两类的聚类结果正确。其余2位实验参与者中的第一位的人工聚类结果与工具的聚类结果是相同的,第二位参与者的人工聚类结果与工具的聚类结果稍有差异,差异也是问题类型七中的第一类(图4中标有星号的类别)修复方式的划分,他认为该类划分为两类更为合适,其余类别的划分数量及每个类别中的修复案例与工具的聚类结果一致。
设置对比实验以验证问题聚类能有效提高对目标问题修复推荐的效果。本实验挑选了2组具有程序开发经验的硕士生,每组4人,2组参与者的程序开发能力相当。从平台上随机选择8个未修复且有推荐结果的问题,分配给2组的参与者,每人2个问题。第一组参与者根据聚类后的推荐修复案例结果进行问题修复,第二组参与者根据不聚类的推荐修复案例结果进行问题修复,分别记录每位参与者对每个问题进行出错原因排查、选定修复案例、问题修复所用的时间。最终每个问题都在正常时间内被修复。实验发现,第一组参与者的平均问题出错原因排查时间为1 min,平均选定修复案例时间为1 min,平均问题修复使用时间为3.2 min。第二组参与者的平均问题出错原因排查时间为2 min,平均选定修复案例时间为3.6 min,平均问题修复使用时间为7.8 min。从上述结果可知,问题聚类能有效提高对目标问题修复推荐的效果。
由实验结果可知,本文的聚类结果基本正确,聚类方法较为合理,聚类效果较为有效。
2.2.2推荐方法的有效性评估
本实验从Github上随机选择4个高质量项目中的23个待修复问题作为目标问题,使用自己的历史修复记录资源库中的问题修复案例对工具进行有效性评估,工具中添加了来自Github的217个Java软件项目,分析了这些项目近一年来的57 752个问题修复案例。选中的4个项目中有一个项目是平台中的,随机选择该项目中的4个至今没有被修复的问题作为目标问题。其余3个项目不曾添加到平台中,从这3个项目中随机选择19个至今未修复的问题作为目标问题。本实验认为对于一个待修复问题,推荐出的能够帮助开发人员较快地理解并修复问题的修复案例叫作有参考价值的修复案例。
下面通过一个具体实例来说明怎样叫做有参考价值的修复案例。
图5展示了一个目标问题的代码段,①为问题代码行。实验要求在不寻求其他任何帮助的情况下,仅依靠为它推荐出的代码问题修复结果对问题进行修复。

图5 目标问题代码
本文工具为该目标问题推荐出两条修复案例,其中第一条更为相似。图6以及图7展示了为该问题推荐的第一条修复案例。其中,图6展示的是问题代码段,①为问题代码行,其余部分为上下文代码行。我们把该问题代码段与目标问题代码段进行比较,可以看出,这两段问题代码发生错误的原因一致,且代码非常相似,仅变量名不同,Token化后相似度很高,经过推荐算法的计算,此记录作为目标问题的推荐结果很合适。图7展示了推荐报告中的修复方式代码段,①为修复代码行,根据该推荐结果,无须寻求其他任何帮助,很容易对目标问题进行修复,具有很高的参考价值。

图6 问题修复推荐报告-问题代码段

图7 问题修复推荐报告-修复方式代码段
本实验挑选了4位具有程序开发经验的硕士生,让他们分别对4个项目中的目标问题的推荐结果的有效性进行评估。实验认为,如果在3小时内修复推荐系统能够推荐出修复案例、参与者完成问题修复、修复后的程序能够通过FindBugs检测,就认为该目标问题被成功修复(其中参与者进行问题修复的过程不能超过15 min)。其中任何一项不能通过则认为目标问题没有被成功修复。
本文认为精确率是所有被成功修复的目标问题数目除以所有成功生成推荐结果的目标问题数目。
表1展示了23个目标问题的推荐结果信息,参与者自己操作推荐系统获取推荐结果,对于成功生成推荐结果的目标问题,参与者从所有的推荐修复案例中选出一个最具有参考价值的修复案例,根据该修复案例对目标问题进行修复,将修复后的程序进行静态分析。最终经过实验验证,工具对23个目标问题中的20个成功生成了推荐修复案例,这20个修复案例与目标问题上下文匹配,是同种类型的问题。参与者对选定的最具有参考价值的20个修复案例进行评估,认为这20个选定的修复案例中17个是有效的、有参考价值的。即被成功修复的目标问题数目为17,所有成功生成推荐结果的目标问题数目为20,本文工具的精确率为85%。
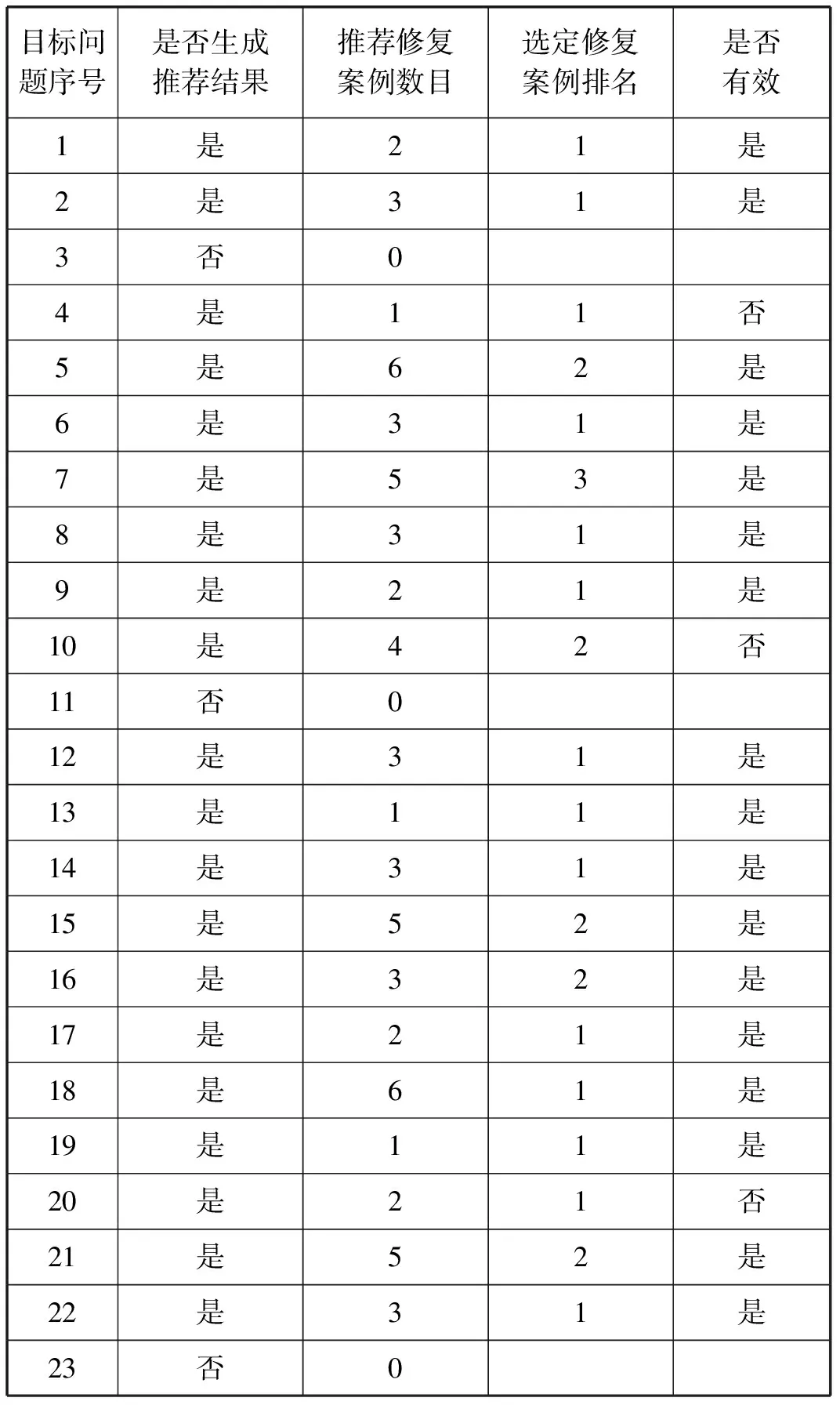
表1 目标问题推荐结果信息
设置对比实验以验证进行问题修复推荐是有效的,可以提升开发效率。本实验挑选了2组具有程序开发经验的硕士生,每组4人,2组参与者的程序开发能力相当。从平台上随机选择8个未修复问题,分配给2组的参与者,每人2个问题。第一组参与者根据问题修复推荐系统的推荐结果进行问题修复,第二组参与者没有推荐结果作为参考,分别记录每位参与者对每个问题进行修复所用的时间。最终所有问题都被修复。实验发现,第一组参与者的平均问题修复使用时间为3.7 min。第二组参与者的平均问题修复使用时间为16.2 min。从上述结果可知,问题修复推荐是有效的,可以提升开发效率。
上述两个实验说明本文问题推荐方法以及推荐工具在实际的应用中具有有效性。
然而,本文方法具有一定的局限性,由于本文方法是基于历史修复的,因此修复推荐的结果的质量依赖于修复资源库中所收集的项目的质量和数量。该方法仅针对静态分析,只能修复代码静态分析检测到的问题。由于该方法基于静态检测结果进行分析,因此FindBugs的误报漏报可能会对后续分析产生影响。由于目前仅使用FindBugs作为代码静态分析工具,只分析了Java项目,本文中的问题修复推荐方法目前仅适用于Java语言。
2.2.3与Nopol的区别
Nopol[8]是一种基于语义的问题修复工具,由于它也是代码问题修复方面的工具,可以对Java程序中的问题进行修复,且是近年来较新的工具,因此选择该工具进行比较。我们从输入输出、问题类型、精确率、误差几方面将本文方法与其进行对比。
输入输出:Nopol的输入是一个带有问题的程序以及相应的测试集合,输出是其生成的带有条件表达式的补丁。测试集合包含可通过的测试用例以及至少一个失败的测试用例。可通过的测试用例用以定义程序预期的行为;失败的测试用例用以定义要修复的问题。而本文工具的输入是一个有问题的程序,输出是与该问题最为相似的几条修复记录,包括问题代码及其上下文、修复方式代码及其上下文、问题类型等。
问题类型:Nopol可以修复的问题类型是if条件语句错误及前置条件错误,即针对条件语句问题进行修复。本文工具的问题修复方法是通用的。
精确率:根据Xuan等[8]对Nopol的实验可知,在得到的17个合成补丁中,有13个是正确的,而本文的实验结果表明,在得到推荐结果的20个目标问题中,17个被正确修复。
误差:在实践中,仅仅通过测试集合的补丁不一定是正确的,因为测试用例不一定能够正确地定义程序行为。因此,当测试集合的质量不足时,Nopol便无法保证能够生成正确的补丁。而文本方法无需测试集合的支持,避免了该种情况的发生,且给出的已修复程序通过了FindBugs的静态扫描,一定程度上避免了新问题的引入。
3 相关工作
代码问题修复在产业界可以辅助开发人员修复代码,提高代码质量,在学术界更是实现软件自动化的有效途径。由于其极大的产业意义和学术意义备受关注,越来越多的研究人员致力于问题修复技术的研究。
Genprog是早期的能够自动生成补丁的系统,该系统的研究人员提出,可在应用程序的其他位置找到补丁的代码[9-10],除了发现可以重用的代码存在于其他地方这一事实外,还发现了潜在的修复成分的上下文是有用的:通常,重用代码部分的上下文类似于被修复的部分的代码上下文[11-12]。生成候选补丁的一种方法是在原始程序上应用变异运算符。变异运算符潜在地通过它的抽象语法树表示形式或更粗粒度的表示形式(例如语句级或块级)操纵原始程序。较早的遗传改良方法在语句级别运行,并执行简单的删除/替换操作,例如删除现有语句或在同一源文件中用另一个语句替换现有语句[13-14]。最近的方法[15]在抽象语法树级别使用了更细粒度的运算符来生成更多组候选补丁。机器学习技术可以提高自动问题修复系统的效率。SequenceR[16]对源代码使用句到句学习,以生成单行补丁,它定义了一种神经网络体系结构,可与源代码很好地结合,并具有复制机制,该机制允许使用未包含在学习词汇中的token生成补丁,这些token来自正在修复的Java类的代码。
使用修复模板[17]是生成候选补丁的替代方法,用于修复特定类别的问题。也可以自动挖掘修复模板[18]用于生成补丁并对其进行验证。Osman等[19]提出的修复模式(patterns)获取方法是先自动地获取修改模式,然后手动地修改这些模式。他们的人工分析阶段对深入了解问题背后的原因至关重要。他们的更改粒度在单行代码级别,无须任何抽象就可以捕获所有更改。该研究包含的软件项目有717个。
代码问题修复技术有许多应用。在开发环境中,当开发人员遇到问题时,可以通过如单击按钮等操作来搜索补丁。当自动化到一定程度,IDE无须等待人工指示,主动在后台搜索潜在问题的解决方案。在持续集成服务器中,如果在持续集成过程中构建失败,则构建失败后可以立即搜索补丁[20]。实验表明,生成的补丁可以被开放源代码的开发人员接受并合并到代码库中[21]。系统运行时,当发生运行故障,可以搜索二进制补丁并在线应用。这种修复系统的一个示例是ClearView[22],它使用x86二进制补丁对x86代码进行修复。Itzal系统[20]与Clearview不同:修复搜索在运行时进行。而在生产中,所生产的补丁是源代码级别的。BikiniProxy[23]系统可以在线修复浏览器中发生的JavaScript错误。阿里巴巴为了解决内部面临的挑战和难题,提出了PRECFIX[5]方法,主要分为三步,首先从代码提交数据中提取“缺陷修复对”,然后将相似的“缺陷修复对”聚类,最后对聚类结果进行模板提取,这个缺陷检测和补丁推荐技术可以用于代码评审、全库离线扫描等。
然而,目前提出的问题修复方法还是存在很多问题,如精确率低、只能修复特定问题类型、对测试用例完备性的要求非常高、修复的耗时长、消耗的计算资源较多等。本文基于所提方法研发的基于代码相似度分析的代码问题修复方式推荐工具,是针对任意问题类型的,它不需要输入测试用例,聚类效果较好,推荐结果较为具有参考价值,能够提高程序开发人员修复问题的效率。
4 结 语
本文提出一种基于代码上下文相似度分析的代码问题修复推荐方法。该方法首先收集历史版本中代码问题的修复案例,建立问题修复资源库,然后根据问题类型、问题代码及上下文、修复代码及上下文对修复案例进行聚类,对每种不同类型的问题建立修复模板,最后通过对有同类问题的目标代码及其上下文进行相似性分析,从而推荐具体的修复方式。基于以上所述方法,设计并实现一个基于代码上下文相似度分析的代码问题修复推荐工具,并基于Github上的真实项目设置多组实验对聚类效果的有效性和推荐方法的有效性进行验证。
然而,本文方法的问题推荐目前是基于代码问题修复方式资源库的,因此资源库中修复案例的质量决定了修复推荐结果的质量。另外,该方法仅针对静态分析,因此只能修复代码静态分析检测到的问题,对于静态分析结果中可能产生的误报漏报需要进行进一步处理,因此在实际应用中代码问题修复推荐的能力受此影响,对此,我们需要继续进行研究。
