基于BP-LSTM双输入网络的大钩载荷与转盘扭矩预测
2022-06-29宋先知李根生曾义金郭慧娟胡志坚
宋先知, 朱 硕, 李根生, 曾义金, 郭慧娟, 胡志坚
(1.中国石油大学(北京)石油工程学院,北京 102249; 2.中国石油大学(北京)油气资源与探测国家重点实验室, 北京 102249; 3.中国石化石油工程技术研究院,北京 100101; 4.中国石油集团工程技术研究院有限公司,北京 102206)
大钩载荷、转盘扭矩是钻井工程的重要参数指标,可用于钻井工况实时分析。因此通过对大钩载荷、转盘扭矩进行科学可靠的预测,能够降低钻井风险,保证钻井安全,提高钻井效率。目前大钩载荷、转盘扭矩的预测主要以理论分析为主,如常见的摩阻扭矩软杆模型[1]和刚杆模型[2],此外一些学者在此基础上针对不同情况建立了修正的摩阻扭矩模型[3-5]。Lesage等[6]利用软杆模型,结合实钻数据反演摩阻系数,以识别钻井异常情况。Brett等[7]将软杆模型应用于钻前设计、钻时监控与分析、钻后分析中。然而理论模型是在严格的假设条件基础上建立的,与钻井实际情况存在一定差距,导致理论模型预测精度有限。因此亟需一种能够提高计算效率、预测精度的大钩载荷、转盘扭矩预测方法。机器学习算法在解决非线性问题上的优秀表现,十分符合实际工程问题的需求。因此机器学习方法被广泛应用在井眼轨道优化[8]、导向智能决策[9]、地层特征识别[10]、岩性识别[11]、产量预测[12-13]、油田开发优化[14]等方面。其中BP神经网络作为经典的前馈神经网络,能够逼近任意复杂的函数关系。LSTM作为反馈神经网络的一种,尤其擅长处理序列信息,被广泛应用于自然语言处理[15]、语音识别[16]、机器翻译[17]、水文学[18]、金融[19]等领域。考虑到大钩载荷、转盘扭矩的影响参数复杂多样以及钻井过程的时序性,分别选用BP神经网络[20]与长短期记忆神经网络[21],根据两种网络的结构特点,利用BP网络处理非时序数据,LSTM网络处理时序数据,建立双输入网络架构。笔者基于BP神经网络、长短期记忆神经网络的理论基础与网络结构,建立BP-LSTM双输入网络模型,并分析双输入网络模型在大钩载荷、转盘扭矩预测中的应用效果。
1 原理与方法
1.1 BP与LSTM神经网络
简单BP网络神经元计算公式为
ht=f(whxt+bh).
(1)
简单循环神经网络隐藏层神经元计算公式为
ht=f(wh[ht-1,xt]+bh).
(2)
式中,xt为当前的输入;wh为隐藏层的权重矩阵;bh为隐藏层的偏置向量;f为激活函数;ht为当前的输出;ht-1为上一时刻的输出。
BP神经网络是一个静态网络,信息的传递是单向的,网络的输出只依赖于当前的输入,可以逼近任意复杂函数,但不会根据先前信息对之后的信息进行推断,不具备记忆能力。
循环神经网络(recurrent neural network,RNN),通过使用自反馈的神经元,使一个隐藏层神经元的信息可以传递到下一个隐藏层神经元,具有一定的记忆能力,在处理序列性问题方面优势明显。但由于RNN结构共享权重和偏置,梯度在反向传播过程中,不断连乘,使梯度会越来越大或越来越小,进而产生梯度爆炸或梯度消失问题[22]。Hochreiter等[23]通过在传统RNN网络结构的基础上进行改进,诞生了LSTM网络。
LSTM的神经元设计了输入门i、遗忘门f、输出门O、记忆单元C。LSTM依靠这些“门”的结构让信息有选择性地影响神经网络中每个时刻的状态。“门”结构使用sigmoid作为激活函数的全连接神经网络,会输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构,从而避免产生梯度爆炸或梯度消失问题。长短期记忆神经网络结构如图1所示。

图1 长短期记忆神经网络结构Fig.1 Structure of long-short term memory neural network
遗忘门:
ft=σ(Wf[ht-1,xt]+bf).
(3)
输入门:
it=σ(Wi[ht-1,xt]+bi).
(4)
输出门:
Ot=σ(Wo[ht-1,xt]+bo).
(5)
式中,Wf为LSTM中遗忘门神经元的权重矩阵;bf为LSTM中遗忘门神经元的偏置向量;ft为LSTM中遗忘门神经元的输出;Wi为LSTM中输入门神经元的权重矩阵;bi为LSTM中输入门神经元的偏置向量;it为LSTM中输入门神经元的输出;Wo为LSTM中输出门神经元的权重矩阵;bo为LSTM中输出门神经元的偏置向量;Ot为LSTM中输出门神经元的输出;σ为sigmoid激活函数;
1.2 特征选择方法
尽管随着深度学习的发展,可避免人工提取特征的端到端的学习机制成为研究热点,但在进行神经网络训练时,适当对变量进行特征选择可简化模型,缩短训练时间,进而提高模型的泛化能力。特征选择方法可分为Filter(过滤法)、Wrapper(包装法)、Embedded(嵌入法)。本文中选择Filter法中相关系数法,分别选用Pearson相关系数和距离相关系数[24]进行相关性分析。
Pearson相关系数法用于分析各个变量对目标变量的线性相关性,其计算公式为
(6)
式中,cov(X,Y)为X,Y的协方差;D(X)为X的方差;D(Y)为Y的方差;ρXY为X,Y的Perason相关系数。
Pearson 相关系数只能度量变量间的线性相关性,并且须服从正态分布假设。距离相关系数弥补了 Pearson相关系数的不足,不仅能反映变量间的线性关系,也可以表示变量间的非线性关系,并且不需要任何的模型假设和参数条件。距离相关系数Rn(X,Y)的计算方法为
(7)

2 数据预处理
样本的质量由训练样本分布所能反映总体分布的程度决定,对神经网络模型的预测精度和泛化能力存在显著影响,因此合理的选择训练样本集对于提高网络模型的预测精度和泛化能力有重要意义。Partridg[25]对于BP网络的研究表明,样本质量对网络泛化能力的影响超过了网络结构本身的影响。训练样本对所研究问题的表征能力和合理的学习机制对改善神经网络模型的泛化能力至关重要。为了保证大钩载荷、转盘扭矩预测的效果,首先需要对原始训练样本进行整理、清洗以及特征选择,最终建立一个用于大钩载荷、转盘扭矩神经网络预测模型训练的优质数据集。
2.1 数据整理与清洗
训练样本由国内某油田提供的69口井的原始数据,包含综合录井数据、测斜数据、钻井液数据和钻具组合数据,参数种类60余种。经过数据获取、分井存储、数据拼接、数据清洗、按时间排序后,最终得到可用于训练的样本数据集。
2.2 相关性分析与特征选择
通过计算各个影响参数间的Pearson相关系数和距离相关系数分析各参数间的相关性。对Pearson相关系数取绝对值,用以表征各个变量之间线性相关的强度。
如图2、3所示,距离相关系数整体上均大于Pearson相关系数,说明地面工程参数与大钩载荷、转盘扭矩存在较强的非线性关系。
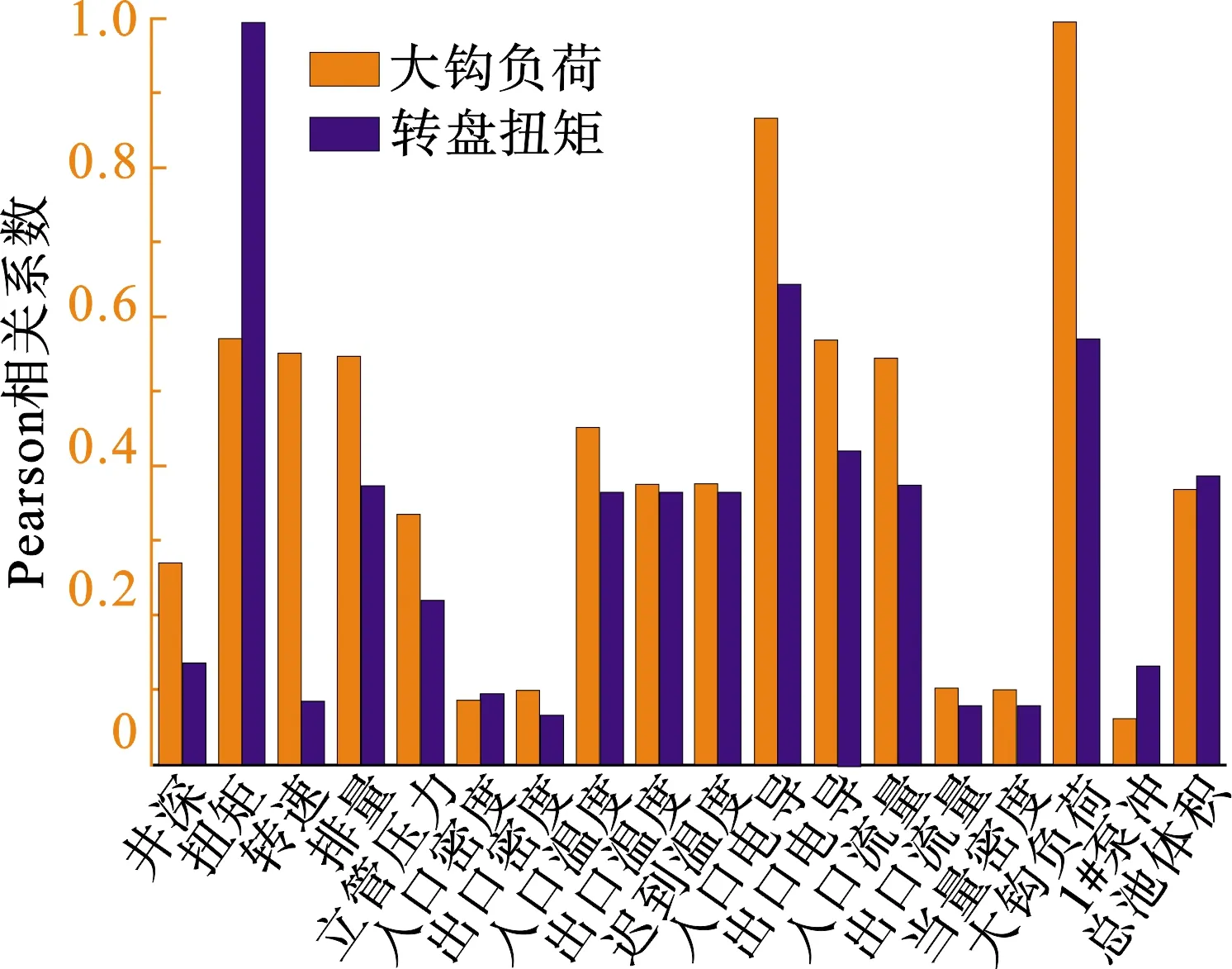
图2 Pearson相关系数Fig.2 Pearson correlation coefficient

图3 距离相关系数Fig.3 Distance correlation coefficient
此外,在钻进某一段的过程中,该井段的钻井液体系、钻具组合、钻头类型已确定,不会随时间变化。但在钻进不同井段时会采用不同的钻井液体系、钻具组合、钻头类型,也会对大钩载荷、转盘扭矩产生影响。本文中利用BP神经网络刻画钻井液体系、钻具组合、钻头类型与大钩载荷、转盘扭矩间的复杂的非线性映射关系。综合以上分析,最终得到21种可量化的输入特征,分别为井深、井斜、方位角、大钩载荷、转盘扭矩、转盘转速、立管压力、入口密度、出口密度、入口温度、出口温度、迟到温度、入口电导、出口电导、入口流量、出口流量、排量、当量密度、泵冲1、泵冲2、总池体积。3种定性的输入特征,分别为钻井液体系、钻具组合、钻头类型。
2.3 数据归一化
将数据集分为时序数据和非时序数据两部分,其中非时序数据为类别参数,作为BP网络的输入。时序数据为可量化的参数,作为LSTM网络的输入。
2.3.1 量化参数的归一化
对数据进行归一化,可消除不同变量量纲的影响,避免过大的数值在训练过程中引发数值问题,同时也可加快梯度下降算法求最优解的速度。目前在数据标准化方法的选择上,并没有通用的法则可以遵循。考虑到钻井工程参数很少有极端的极大极小值以及钻井设备能力的限制,参数的最大和最小值可以事先设定或统计分析得到,因此本文中采用极值归一化方法对综合录井数据、测斜数据进行归一化,
(8)

2.3.2 类别参数的One-hot编码
对于钻井液体系、钻头类型、钻具组合变量,将钻井液体系[26]划分为低密度、普通、普通加重、高密度、超高密度钻井液;钻头类型划分为PDC、牙轮;钻具组合划分为钟摆、满眼、塔式钻具组合。并采用One-hot方法数字化。
2.4 数据集构造
2.4.1 输入输出序列构造
在模型训练过程中,LSTM的输入与BP神经网络的输入形式有所不同,LSTM网络中需要将时间序列数据转换为监督学习。
P1、P2、P3、…、P21分别表示时序数据中的21种变量,其中P1、P2表示大钩载荷、转盘扭矩。假设当前时刻为t,下一时刻为t+1,选取历史步长为5,则LSTM网络当前时刻t的输入为
对定性变量采用one-hot方法数字化,P22、P23、P24、…、P31分别表示低密度、普通、普通加重、高密度、超高密度钻井液、PDC、牙轮、钟摆、满眼、塔式钻具组合共10类,BP网络当前时刻t的输入为[P22,t、P23,t、P24,t、…、P31,t]。
此时模型的输出为下一时刻t+1的[P1,t+1]和[P2,t+1]。
2.4.2 评价指标
分别选取均方根误差Re和平均相对误差Ae作为大钩载荷、转盘扭矩预测的评价指标,表达式分别为
(9)
(10)
式中,ytrue和ypre分别为目标真实值和预测值;N为样本数量。
3 BP-LSTM网络模型结构设计
BP-LSTM双输入网络结构设计如图4所示。图4中BP神经网络,用以输入非时序性数据,输入参数经过One-hot数字化后种类为10种,分别为低密度、普通、普通加重、高密度、超高密度钻井液、钟摆、满眼、塔式钻具组合、PDC、牙轮钻头。LSTM网络用以输入时序性数据,选取历史时间步长为5,输入参数种类21种,分别为井深、井斜角、方位角、扭矩、转速、立管压力、入口密度、出口密度、入口温度、出口温度、迟到温度、入口电导、出口电导、入口流量、出口流量、排量、当量密度、大钩负荷、泵冲1、泵冲2、总池体积。
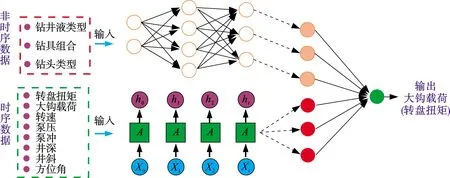
图4 BP-LSTM双输入网络结构Fig.4 Structure of BP-LSTM dual input network
4 BP-LSTM与LSTM模型对比
采用来自不同区块的60口井数据,对BP-LSTM与LSTM模型进行对比分析,BP-LSTM与LSTM网络结构参数与两种模型对比分析结果如表1所示。其中BP-LSTM所需参数为表1中参数1、2、3、4,LSTM所需参数为参数2、3、4。

表1 BP-LSTM与LSTM模型的测试结果
两类网络的钩载预测误差对比如图5所示。12个模型中有7个BP-LSTM钩载预测模型性能表现优于LSTM钩载预测模型,且最优模型是BP-LSTM钩载预测模型,对应的平均相对误差为1.20%。
两类网络的扭矩预测误差对比如图6所示。12个模型中有5个BP-LSTM扭矩预测模型性能表现优于LSTM扭矩预测模型。虽然最优模型是LSTM扭矩预测模型,对应相对误差为8.76%,但BP-LSTM扭矩预测模型中最优模型对应的相对误差为9.03%,两者差异并不大。
综合以上对比分析,验证了针对不同数据类型设计的BP-LSTM双输入网络架构的合理性与可靠性,虽然在扭矩预测模型中,部分BP-LSTM模型表现欠佳,但与表现较好的LSTM模型差异不大。此外,在训练BP-LSTM与LSTM两类模型时,需保证输入特征一致,对此在训练LSTM网络时强制将非时序数据(钻头、钻井液等)转换为时序数据,但钻井过程中,该类数据是不会随时间时时刻刻发生改变的,仅在不同开次时进行调整,因此为了仅使用LSTM网络而对该类数据进行时序数据转换是缺乏科学依据的,而BP-LSTM网络能够根据不同的数据类型进行适应性的学习,能够最大程度的学习数据的内在规律,进而提高模型的预测精度。

图5 两类网络的钩载预测误差对比Fig.5 Comparison of drag prediction error for different networks

图6 两类网络的转盘扭矩预测误差对比Fig.6 Comparison of torque prediction error for different networks
5 基于BP-LSTM网络的大钩载荷与转盘扭矩预测模型训练、测试与优选
5.1 不同区块的60口井
由于钻井现场数据搜集不易,数据量有限且十分宝贵,因此首先使用来自不同区块的全部60口钻井数据进行模型训练、测试和优选,其中41口井数据作为训练集,19口井的数据作为测试集。BP-LSTM双输入网络以LSTM网络为主,BP神经网络为辅,因此在训练优化时,主要对LSTM网络结构及参数进行优化,对于BP神经网络采用1层隐藏层(16个神经元)、1层输出层(8个神经元)的网络结构。
对于LSTM网络,设计3种不同的神经网络架构(分别为1层、2层、3层LSTM层),每种网络架构均设计4种参数组合,包括LSTM层数、神经元个数、Dropout、激活函数,共计12种网络模型,利用41口井的训练集进行网络模型的训练,19口井的测试集进行模型的测试,每个模型均训练120次。经模型训练与测试后,分别得到预测大钩载荷的12个模型和预测转盘扭矩的12个模型,网络模型的具体参数如表2所示。
综合相对误差、均方根误差、模型复杂度共3个指标对大钩载荷、转盘扭矩预测模型进行优选,结果如图7、8所示。
在大钩载荷预测模型方面,相对误差较小的有1.202%、1.21%,分别对应第1、第2个模型,对应的均方根误差分别为39.05和39.56 kN,两个模型的参数量均为7 553。综合分析以上3个指标,选择第1个模型作为大钩载荷的预测模型,其模型预测准确度最高、结构最简单。

表2 不同网络的模型参数
在转盘扭矩预测模型方面,相对误差较小的为9.038%和9.159%,分别对应第1、第5个模型,对应的均方根误差分别为1.681 7和1.603 34 kN·m,模型的空间复杂度分别为7 553和15 873。综合以上3个指标,虽然第1个模型的均方根误差略大于第5个模型,但第1个模型的空间复杂度要远远低于第5个模型,为提高模型的迁移应用性能、降低过拟合的可能性,在保证预测准确度的同时,选择模型结构更为简单的第1个模型作为转盘扭矩的预测模型。

图7 大钩载荷与转盘扭矩预测误差对比Fig.7 Comparison of torque and drag prediction error

图8 网络模型空间复杂度Fig.8 Spatial complexity of network model
5.2 同一区块的15口井
考虑到区块与区块间的差异性,利用同一区块内的数据进行模型训练、测试与优选。采用中古区块的15口钻井数据集进行模型训练、测试与优选。与5.1节区别仅在于采用的数据集不同,其他方法均相同。其中12口油井进行训练,3口测试。同样的综合相对误差、均方根误差、模型复杂度共3个指标对大钩载荷、转盘扭矩预测模型进行优选。相对误差、均方根误差如表3所示。
对于均方根误差和平均相对误差两种评价指标,第5种参数组合下的钩载、扭矩预测模型的性能表现均最优,钩载、扭矩对应的均方根误差分别为38.79 kN和2.16 kN·m,平均相对误差分别为1.46%和18.9%。

表3 网络模型测试结果
综合以上分析,利用同一区块的15口井数据训练得到的预测模型,最优模型的参数组合为LSTM层两层、对应神经元个数32、Dropout为0.3、激活函数为tanh。此外可以发现采用15口油井数据训练测试得到的模型,其预测精度整体上均低于采用60口油井数据训练测试得到的模型。虽然通过划分区块消除了区块间的差异性,但模型性能并未提高,原因主要是训练神经网络需要一定数据量的保证,但同一区块内15口井的数据是不能充分训练神经网络模型的。但在大钩载荷预测模型方面,经过15口井数据训练后,预测钩载的相对误差为1.46%、均方根误差为38.79 kN,而经过60口井数据训练得到的模型,其预测钩载的相对误差为1.202%、均方根误差为39.05 kN。通过对比,可发现虽然训练钩载预测模型的数据量由60口减少至15口,但钩载预测模型的精度却未大幅降低,说明分区块训练是合理且有意义的。
5.3 结果分析
利用最优的BP-LSTM模型进行大钩载荷、转盘扭矩预测,结果如图9所示。通过与实测数据对比,大钩载荷预测的均方根误差为39.05 kN、相对误差为1.202%。转盘扭矩预测的均方根误差为1.627 4 kN·m、相对误差为9.038%。从图9中可看出,大钩载荷、转盘扭矩预测值的变化趋势与实际值的变化趋势基本吻合,且数值也较为接近。

图9 预测值与测量值对比Fig.9 Comparison of predicted and measured values
6 结束语
通过分析大钩载荷与转盘扭矩预测问题的特征(影响因素复杂多样、时间序列)与人工神经网络的技术特点,从多种人工神经网络中优选出BP神经网络与LSTM神经网络,设计了双输入网络架构,并建立了大钩载荷与转盘扭矩预测模型,实现了基于数据驱动的大钩载荷与转盘扭矩预测,与现场实测数据对比,大钩载荷、转盘扭矩预测的均方根误差分别为39.05 kN和1.627 4 kN·m,相对误差分别为1.202%和9.038%。虽然缺乏与物理模型的结合,但丰富了大钩载荷、转盘扭矩的预测方法,为大钩载荷、转盘扭矩预测提供了新的思路和方法,同时也是对智能钻井理论与方法的有效探索。
