面向大数据技术的《机器学习》数据分析与处理方法*
2022-06-24白振豪赵锦荣
赵 婕,白振豪,赵锦荣
(太原学院智能与自动化系,山西 太原 030032)
《机器学习》是智能科学与技术专业的核心课程,要求学生掌握模拟人类的学习机制,从原始数据中获取隐藏的有效信息的方法。随着大数据技术的发展,机器学习朝着智能化数据分析与处理的方向发展,结合新知识和社会实际需求变化,学生需要深入了解机器学习的发展动态[1-2]。
1 机器学习算法
1.1 传统机器学习算法
传统机器学习算法可以分为三大类:监督学习、无监督学习和增强学习[3]。其中,监督学习需要对训练集目标进行数据标注,标记输入数据的输出值,其学习任务是实现具体数据的分类或回归。无监督学习无需对训练集目标进行数据标注,其输入数据不需要预先标记输出值,实现的学习任务是聚类或预测。增强学习采用反馈式交互学习方式,与外部环境进行不断地交互试错来获取最佳学习策略,其学习任务是得到具有最大累积回报的决策。从数据处理过程来看,监督学习和非监督学习主要侧重于数据分析,增强学习更多地应用于解决决策问题。传统机器学习算法的分类情况如表1所示。

表1 传统机器学习算法分类
1.2 大数据技术与机器学习
传统机器学习算法进行数据处理时,会将所有的数据进行完全加载使用。但是,随着大数据时代的来临,数据集的规模不断扩大,传统的机器学习数据处理方法已经不能满足大数据的特性,而大数据的特性成为改进机器学习算法的关键因素。
大数据具有五大特点,通常称为大数据5 V特性,其具体描述如下:
1)大量化(Volume):数据分析量巨大,计量单位从TB到PB,甚至达到EB规模;
2)多样性(Variety):大数据类型多样化,除结构化数据外,还包含非结构化数据和半结构化数据;
3)价值化(Value):海量数据的分析和挖掘具有巨大的商业价值,而相应的数据价值密度变低,因为价值密度与数据量的大小构成反比例关系。
4)时效性(Velocity):根据大数据的生成速度,需要在一定的时间限度内及时完成数据处理操作,具有较高的时效性要求。
5)真实性(Veracity):大数据的内容来源于社会生产和日常生活等现实世界,数据可能存在不确定性和不完备性,在大数据处理过程中需要确保数据的准确性和可信度。
大数据的5 V特性给机器学习带来了挑战,针对上述大数据的特点,对传统机器学习算法的改进成为该领域的研究热点,广大研究学者致力于开发满足大数据特性的可扩展的并行智能学习方法[4]。目前,较为典型的基于大数据技术的机器学习方法如表2所示。
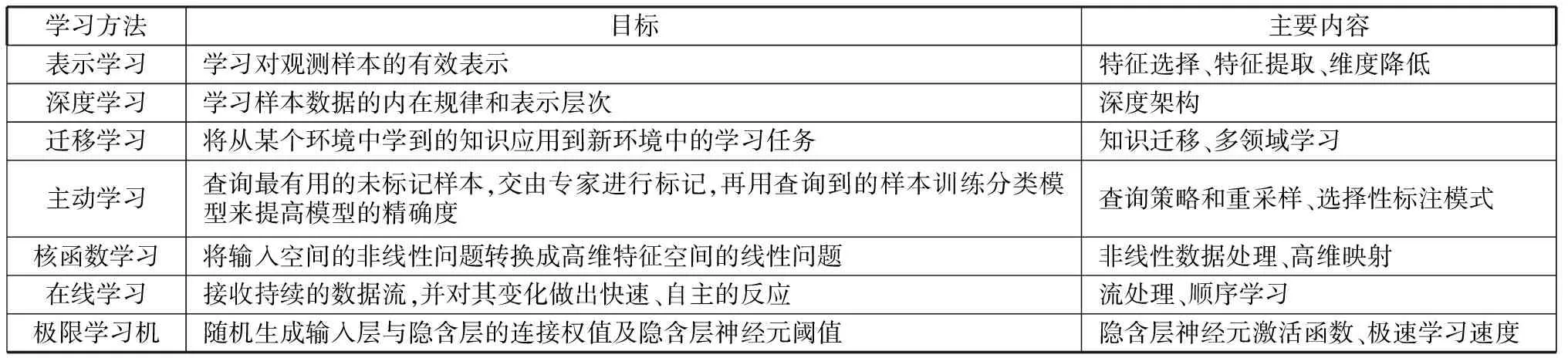
表2 基于大数据技术的机器学习方法
传统的机器学习方法不能直接从数据中自动挖掘出有判别力的信息,表示学习利用算法学习数据的有效表示,能够合理高效地将高维数据特征表示出来。当数据来自不同的特征空间,具有不同的分布时,迁移学习能够利用预先学到的知识较快地解决新环境中的问题。在数据处理过程中经常会遇到规模庞大、未标注的数据集,由于数据量巨大,采用手工标注方式较难完成数据的准确标注,这种情况下,主动学习能够利用少量的标注样本获取高精度的训练模型。对于非线性数据处理,核函数学习能够提供强大的计算能力。如果为了达到较高的数据时效性要求,可以采用在线学习和极限学习机进行实时数据处理。
2 基于大数据的智能信息处理方法
学习系统能否快速地执行算法,依赖于数据处理的速度。依据数据处理任务所面临的不同的大数据特性,采用不同的机器学习算法,并且将其与大数据处理方法相结合。为了提高大数据处理的有效性,在机器学习中可以融入智能信息处理方法[5-6]。在机器学习算法中,适用于大数据的智能信息处理方法主要有:1)统计学习法;2)凸优化法;3)随机近似法;4)异常序列检测法。如图1所示,前三种信息处理方法应用于大数据分析,第四种用于决策机制。
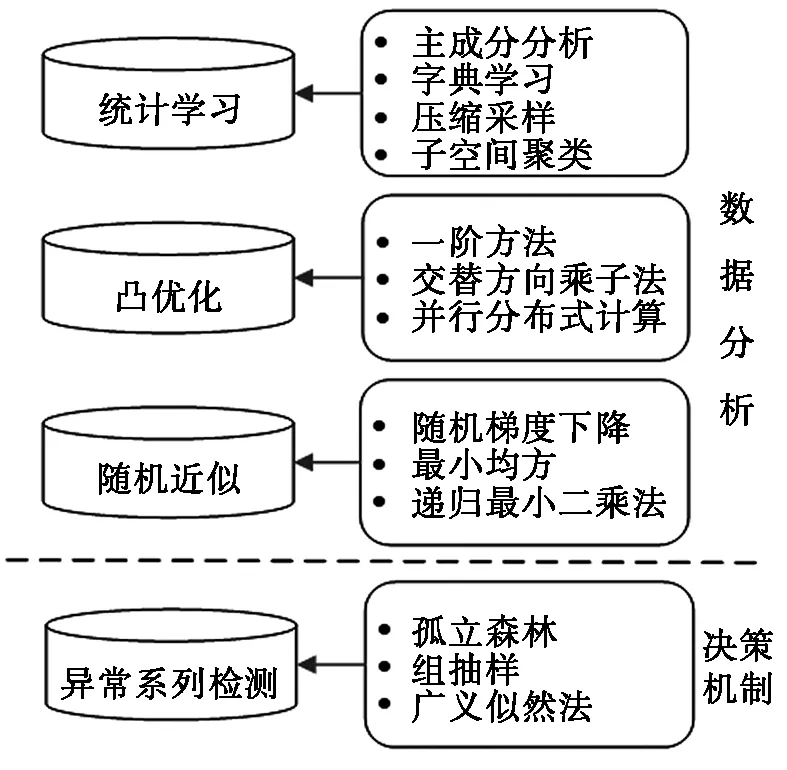
图1 基于大数据的智能信息处理方法
2.1 统计学习法
统计学习法是利用统计学方法进行数据分析,构建概率统计模型对数据进行本质推断或预测其未来发展趋势。传统的统计学习方法主要处理结构化数据。大数据时代背景下的统计学习法,不仅要分析处理样本容量巨大的数据,还要在较短时间内对不同类型的融合数据进行准实时地推断与预测。大数据拓展了统计学的研究内涵,面对大容量、异常或缺失值、实时约束和云存储等问题,使得统计学习的研究范式从参数估计的不确定性转为模型选择的不确定性,聚焦于数据的自适应性和稀疏技术[7]。
2.2 凸优化法
凸优化法是一种使用较为广泛的信息处理方法。在对大数据进行分析和处理时,由于数据量巨大,无法根据大数据的上下文信息进行局部优化求解。因此,基于大数据的凸优化法需要对传统的凸优化算法进行改进,其目的是解决大数据凸优化求解过程中的计算和存储等瓶颈问题。假设大数据优化问题的目标数学公式为:
(1)
其中f和g是凸函数。为了获得最优解x*,可以采用一阶方法通过目标的一阶预测信息求出数值解,还可以通过使用近端映射原理处理含有非光滑项的函数。常采用的一阶方法有Nesterov加速梯度法、加速近端梯度法等。
交替方向乘子法(Alternating Direction Method of Multipliers,简称ADMM)可以解决等式约束的优化问题,其目标公式为:
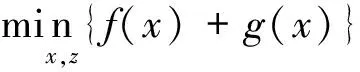
s.t.Ax+Bz=c.
(2)
其中Ax+Bz=c为等式约束。ADMM利用增广拉格朗日和对偶分解技术,将一个大问题分成两个子问题,缩小了问题规模,起到简化计算的作用。
2.3 随机近似法
大数据随机近似法利用采样、略图、摘要等技术,引入近似的允许误差,可以降低大数据的处理规模,提高大数据处理效率。
随机梯度下降法(Stochastic Gradient Descent,简称SGD)每次从训练集中随机抽出一组样本,训练后按梯度进行更新一次,使用目标函数的近似梯度来确定搜索方向。SGD在训练集足够大的情况下,通过随机均匀地选择样本而不是循环遍历数据的方式,可以获得更好的收敛速度。
假设L是每个样本的损失函数,f(x;Φ)表示一个关于x和参数Φ的函数,并且y表示x所对应的目标值,SGD的步骤如下所示:

随机梯度下降法(SGD)输入:学习率η和初始参数Φ输出:f(x;Φ)的全局最小近似值repeat1:从训练集中选择m个样本{x(1),…,x(n)},其中x(i)所对应的目标为y(i);2:梯度计算:g←▽Φ∑i L(f (x(i); Φ), y(i))/m;3:参数更新:Φ←Φ- ηg。until 达到收敛条件
2.4 异常序列检测法
随着数据规模的不断增大,在大数据应用环境中离群点学习算法的使用需求也随之增大,异常序列检测法用于大数据的决策机制,具有重要的实际应用价值。在工业生产、社会生活中,基于数据驱动的异常序列检测法可以自动准确地检测出系统的异常值,尽早发现系统的异常情况。例如,通过互联网服务器的流量监测,发现黑客攻击后的访问流量的显著变化;通过监测银行账户的高频异常转账行为,及时发出金融风险预警。
孤立森林(Isolation Forest,简称IF)定义异常样本为分布稀疏且距离高密度群体较远的数据点,具有线性时间复杂度,即其运行时间随输入数据量的增大呈线性增加的趋势,符合大数据的应用条件。IF采用递归随机分割数据集的策略,直到所有的样本点都孤立为止,使得异常点具有较短的路径。IF分为两个阶段,在第一阶段训练出t棵孤立树来组成孤立森林,具体步骤如下:
Step 1:从训练集中随机选择m个样本点作为样本子集,放入一棵孤立树的根节点;
Step 2:随机指定一个维度,在当前节点数据中随机选择一个分割点p,该分割点产生于当前节点数据中指定维度的最大值和最小值之间;
Step 3:以分割点p生成一个超平面,将当前节点数据空间划分为2个子空间,小于p的数据放入左子节点Tl,而大于等于p的数据放入右子节点Tr;
Step 4:在Tl和Tr中递归执行Step2和Step3,不断构造新叶子节点,直到叶子节点中只有一个数据而无法再继续分割,或者子节点已达到限定高度。
Step 5:循环执行Step1至Step4,直至生成t个孤立树为止。
在第二阶段,利用生成的随机森林评估测试数据。对于每一个数据点xi,令其遍历每一棵孤立树,计算xi在森林中的平均高度h(xi),对所有点的平均高度做归一化处理。异常分数s的计算公式如下:
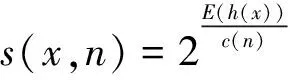
(3)
其中,h(x)为每棵树的高度;c(n)为给定样本数n时,路径长度的平均值,用来对样本x的路径长度h(x)进行标准化处理。
3 总结
在大数据时代,对数据的分析和处理技术提出了更高的要求,基于大数据技术的机器学习方法为当今的人工智能产业发展提供了有效的推动力量。通过研究面向大数据技术的机器学习数据分析与处理方法,拓宽学生的知识面和专业视野,为下一步实现符合社会实际需求的《机器学习》课程建设目标奠定了基础。
