共词网络视角下的图书情报学术论文研究方法演化*
2022-06-17熊回香叶佳鑫
孟 璇,熊回香,叶佳鑫
0 引言
研究方法是科研人员进行研究的思维形式和手段,是区分研究型文献和非研究型文献的核心要素。图书情报学科的学术论文作为一种重要的研究型文献成果,蕴含着丰富的研究方法知识[1-2]。学者们针对不同研究对象会形成不同的研究主题,围绕不同的研究主题会使用契合的研究方法深入探究,从而使得隶属于不同主题范畴下的研究方法存在较大差异,该现象反映出图书情报领域中研究主题与研究方法之间存在一定的对应关系。基于此,本文依据研究主题和研究方法之间的潜在联系,从宏观与微观结合视角出发,将主题演化的相关方法运用于学科学术论文的研究方法研究中,不仅能够全局把握学科中各主题对应研究方法的整体发展历程,给学科方法论体系的完善工作提供参考,亦能够细粒度地回溯每个主题下各研究方法的应用趋势,给图书情报学者在针对某一主题展开研究时提供借鉴。
图书情报领域关于研究方法的概念可以归纳为两种理解:一是关于解决应用场景具体问题的过程中所运用的方法、工具、手段或技术[3-6];二是作者提出的问题的解决方案[6-7]。依据上述研究方法定义,本文中的研究方法可以定义为“在围绕学术论文主题研究的过程中所应用的方法、工具、技术和方案”。在构建研究方法演化模型的过程中,本文利用关键词的语义类型特征构造语义共词网络,采用Louvain 算法识别出隐含主题,并通过计算相邻时期主题的关联强度初步构建研究方法演化链;在此基础上,通过对研究方法进行扩充和重要性评估,完成研究方法演化链的优化;最后依据研究演化链中研究方法的数量及其重要程度排名情况进行演化分析。相比于基于内容分析法的研究方法演化分析的相关研究,基于共词网络的研究方法演化分析能更好地呈现出研究方法在具体研究主题中的演化情况。
1 相关研究现状
目前按照研究方法的标注方式,可将研究方法相关研究划分为基于人工标注的研究和基于机器标注的研究。基于人工标注的研究主要是利用扎根理论搭建编码框架以展开研究方法标注。该类研究较为依赖标注者领域知识,因而准确性较高,仍然是研究方法相关研究的主流方法,并产生了丰硕的研究成果。例如,王芳等[8]以《情报学报》为分析样本,发现我国情报学研究方法中理论研究比重下降,实证研究比重逐年增加;化柏林等[9]采用文献调查法、内容分析法、知识抽取法等多种方法,初步构建面向情报工作流程的研究方法体系;李博闻等[2]将研究方法相关论文进行划分,并对每类论文进行内容分析,归纳出存在的问题,并提出基于“相似度”构建方法体系的解决思路,随后利用内容分析法对学术论文研究方法进行标注,并以研究方法演进视角对“大情报观重述”的成因进行探析[10];Chu等[11-12]运用内容分析法发现多种研究方法混合应用的趋势以及定性分析方法增长缓慢的现象,并阐释了研究方法内涵的组成及研究方法分类标准制定的依据。由于人工标注存在成本高、耗时长、主观偏差等问题,很多学者转而对研究方法进行机器标注。例如,章成志等[1]将朴素贝叶斯算法和支持向量机算法与3种问题转换策略结合,构建6种研究方法分类模型,并对其分类效果进行比较,与此同时将双向长短时记忆网络、条件随机场、词向量相结合,对近10年《情报学报》论文中的研究方法进行命名实体识别[13]。
按照主题的识别方法,可将主题演化分析研究划分为基于关系网络聚类和基于主题模型两类。在前者中,王晓光等[14]构建科研主题演化分析模型,并开发出网络社区演化分析工具NEViewer;程齐凯等[15]将网络社区演化分为产生、消亡、合并、分裂、扩张、收缩等6种演化类型,提出共词网络社区演化分析框架;Palla等[16]利用边重合度设计了社区演化跟踪算法,将网络社区的演化过程分为产生、消亡、分裂、合并、扩张及收缩6种形式。在基于主题模型进行演化分析的研究中,岳丽欣等[17]利用LDA和多维尺度分析法识别期刊论文的核心主题和次要主题,绘制主题交叉演化脉络图进行相关分析;刘自强等[18]采用PLDA主题模型识别领域论文主题,多维度构建主题演化分析模型,并采用科学知识图谱可视化;Hall等[19]针对主题热度测度提出将其转化为主题对应文档数量及被引量的新思路。
从上述研究可知,主题演化分析的研究范式已较为成熟,而研究方法的研究中仍主要采用内容分析法对论文研究方法编码分类并展开分析。然而,目前大多数研究方法研究只是对研究方法进行粗粒度的统计和分析,没有从微观层面对研究方法演化情况进行细粒度的刻画。基于此,本文将主题演化分析引入研究方法研究中,以主题维度对研究方法的演化情况进行深入探究。
2 学术论文研究方法演化分析模型
本文所提出的学术论文研究方法演化分析模型由共词网络构建、主题识别及其演化、研究方法演化分析3个模块构成,如图1所示。
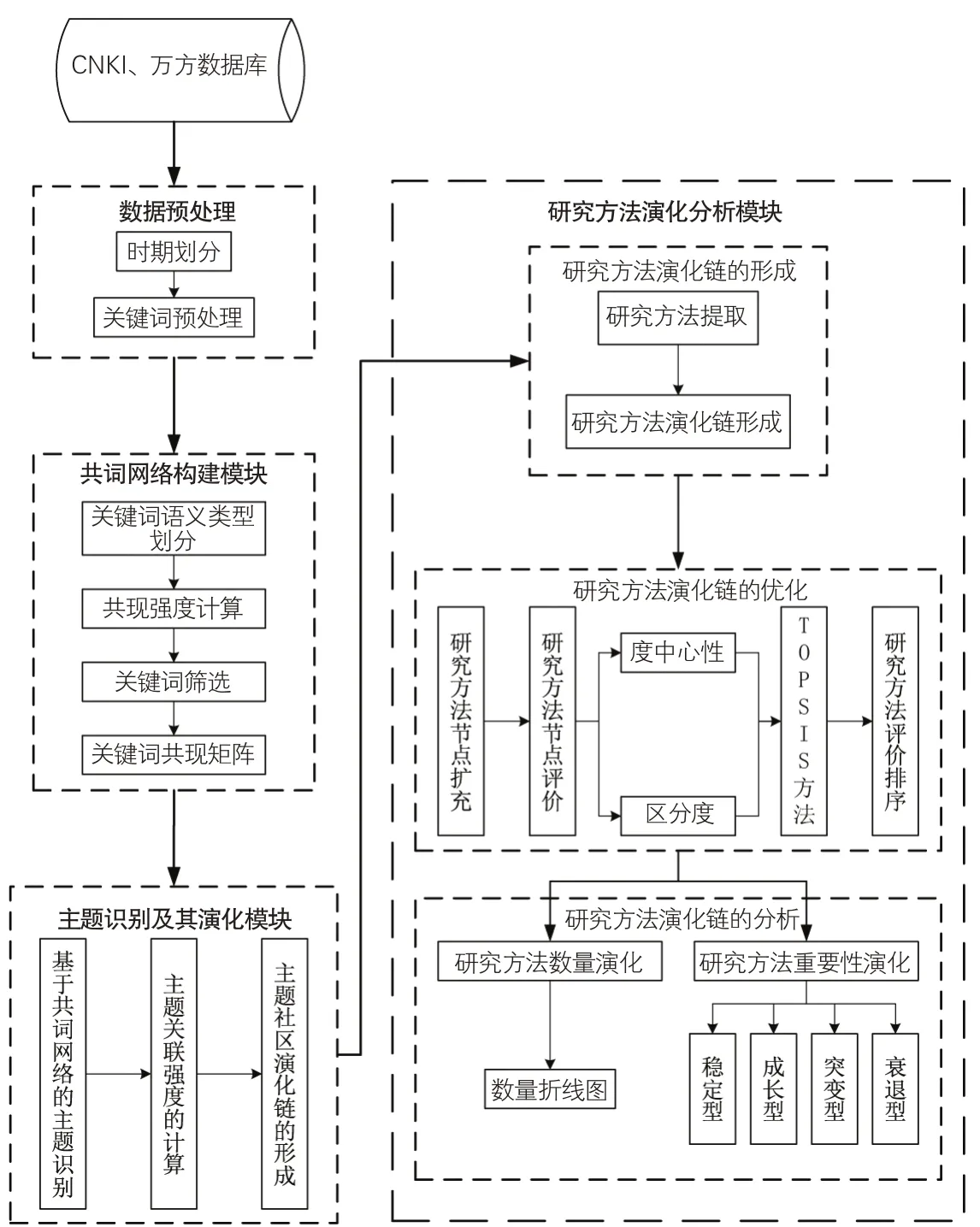
图1 学术论文研究方法演化分析模型
(1)共词网络构建模块。首先,获取图书情报领域学术论文的题目、关键词及摘要等外部特征数据,将其划分不同时期。其次,对关键词进行规范化处理,并分为研究主题类关键词、研究方法类关键词和其他类关键词。最后,基于关键词词对共现强度筛选关键词,并构建共词网络。
(2)主题识别及其演化模块。首先采用Louvain算法对各个时期的共词网络进行社区划分,利用社区与主题之间的潜在对应关系进行主题识别。而后计算主题关联强度,以确定前后主题间的演化关系,并形成主题社区演化链。
(3)研究方法演化分析模块。首先,从主题社区演化链中抽取研究方法类关键词初步形成研究方法演化链。其次,补充研究方法类关键词,并利用度中心性和区分度两个指标以及TOPSIS方法对研究方法的重要性进行评价。最后,依据演化链中研究方法的数量以及研究方法重要度排名的变化情况进行分析。
2.1 共词网络构建模块
2.1.1 关键词语义类型划分
论文关键词是对论文内容的浓缩,通常用于揭示论文研究主题、研究方法、研究范围、研究领域等信息,因而关键词天然遵循某种特定的类型特征。胡昌平等[20]将关键词语义类型划分为“研究主题”“所属领域”“限定范围”“理论方法”“子知识点”。结合本文研究思路,本文将关键词语义类型人工划分为研究主题、研究方法及其他3类,分别以[T]、[M]、[O]后缀进行标识,具体划分标准见表1。例如,论文《基于共词分析的学科结构可视化方法的比较》的关键词为“学科结构”“可视化”“聚类分析”“战略坐标”“社会网络分析”“共词分析”。从标题可知论文的研究聚焦于“学科结构”,因而“学科结构”为研究主题类关键词;对摘要进行内容分析发现,论文在研究过程中运用社会网络分析、聚类分析等方法,因此“可视化”“聚类分析”“战略坐标”“社会网络分析”“共词分析”关键词应划分为研究方法类型关键词。在对关键词语义类型划分后,由3名本领域学者对划分结果进行独立检查,针对有分歧的关键词划分进行集中讨论,以保证关键词语义角色标注的客观性和准确性。

表1 关键词语义类型划分标准
2.1.2 语义关键词筛选
根据以往研究发现,共词网络质量取决于网络结构的清晰性及知识点覆盖程度。共词网络中存在大量低频词会导致共现矩阵稀疏、网络结构松散等问题;而只选择高频词则会使网络丢失大量的重要共现关系,造成知识点覆盖面较小的情况,为平衡网络结构清晰性与知识点覆盖度,本文提出“先筛选后扩充”选词策略。该策略分为两个阶段:关键词筛选阶段和扩充阶段。关键词筛选阶段主要采用改进的E指数公式计算关键词间的共现强度[21],计算方法如下:
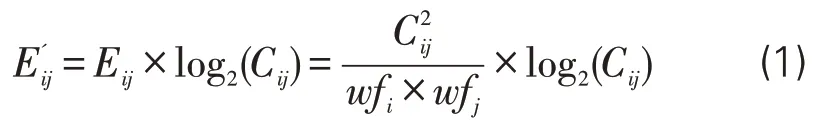
2.2 主题识别及其演化模块
2.2.1 基于共词网络的主题识别
共词网络作为一种特殊的社会网络,呈现出较为显著的社区分布特征,每个社区中的关键词更有可能呈现出相同或相似的主题特征,因而共词网络中的社区与主题之间存在天然的对应关系[22-23]。基于此,本文将主题识别问题转化为社区划分问题,利用Louvain算法对各时期共词网络进行社区划分,并将划分后的结果抽象为一个主题,以达到识别主题的目的[14]。为突出社区的主题特征,本文将共词网络中的社区命名为主题社区,其由不同语义类型的关键词组成。
2.2.2 主题社区演化链的形成
随着社会需求的变化、科学技术的革新、学科研究范式的转变,科研主题发展会发生一定的突变,具体表现为新主题的产生与旧主题的消亡。新主题常在旧主题的消亡过程中孕育产生,形成科研领域常见的主题演化现象[14]。在本文中,由于主题被具象化为主题社区,因而主题演化现象对应为主题社区演化。相邻时期主题社区的演化关系通常根据前后时期社区的关联强度判断,即社区间关联强度越大越可能存在演化关系。本文基于点相似度和价值贡献的思想,引入关键词的语义类型进行社区关联强度计算。本文认为关键词的价值贡献度由两方面构成,一方面为关键词词频占所属主题社区总词频的比重;另一方面通过设定调节系数对不同语义类型的贡献度加以区分。主题社区i与主题社区j的关联强度用Fij表示,其计算方法如下:

其中,s为社区i和社区j共有的关键词数量,Viu为主题社区i中第u个关键词所贡献的价值,Vju为主题社区j中第u个关键词所贡献的价值。语义关键词对所属社区的价值贡献计算方法如下:
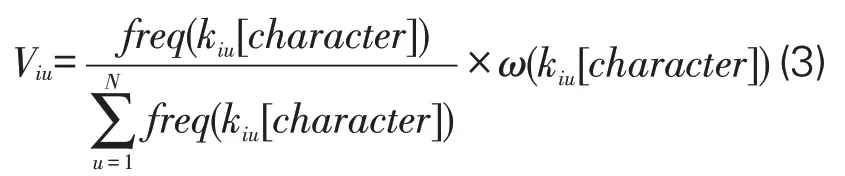
分子freq(kiu[character])为社区i中第u个语义类型为character的关键词的词频数,分母为社区i中所有语义类型为character的关键词的总词频,N为社区i节点数量。ω为不同关键词语义类型所对应的调节系数函数,见公式(4)。
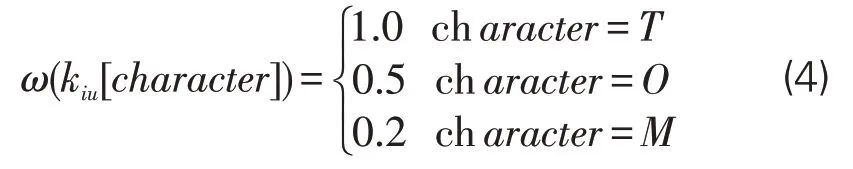
考虑到主题社区中研究主题类关键词最能凸显该社区的主题特征,对社区贡献所贡献的价值最大,因而其调节系数最大;其他类关键词往往与研究主题存在一定关联,但不能直观地反映出社区的主题特征,因而调节系数次之;不同研究主题的论文可能会运用相同的研究方法,导致部分研究方法类关键词存在广泛适用性,对其所属社区的价值贡献度较低,因此研究方法类关键词调节系数设为最低。
最后,构建出相邻时期的两两社区之间的关联强度矩阵ST。
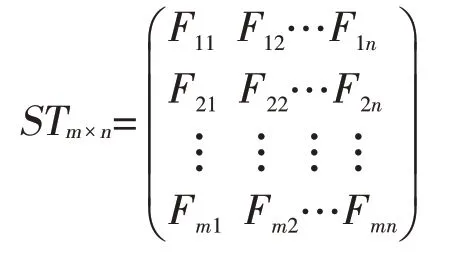
其中m和n分别代表相邻时期的社区数量。为方便后续分析,将ST转换列向量形式。
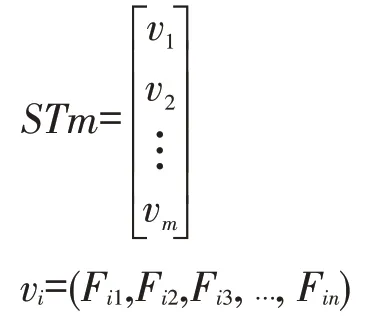
设定阈值δ,依次扫描向量v1到vm,选取每个向量中高于δ的元素。由于本文对主题社区演化过程中可能出现的分裂、融合等情况不进一步展开研究,因此将前后社区中关联强度最大的社区判定为前后演化社区,即若满足阈值条件的社区数量大于1,则选取关联强度的最大值并记录该值所对应的行标和列标,从而得到相邻时期存在演化关系的主题社区。
通过对前后主题社区的演化关系进行识别,可以将主题社区串联为一种链式结构,本文依照其数据结构特点将其命名为主题社区演化链,该主题社区演化链由5个不同时期的社区网络构成,相邻时期的社区网络之间存在演化关系。具体可定义为假设Topicti表示t时期的第i个主题社区,Topic(t+1)j表示t+1 时期的第j个主题社区,Topic(t+2)k表示t+2 时期的第k个主题社区。若Topicti与 Topic(t+1)j存在演化关系,Topic(t+1)j和Topic(t+2)k存在演化关系,则说明Topicti、Topic(t+1)j、Topic(t+2)k所对应的主题从t时期到t+2时期一直存在,形成形如Topicti→Topic(t+1)j→Topic(t+2)k的3个时期主题社区演化链。
2.3 研究方法演化分析模块
2.3.1 研究方法演化链的形成
研究方法类关键词与研究主题类关键词属于同一主题社区,使研究方法类关键词被赋予了主题属性,而主题社区之间又存在演化关系,因而研究方法之间也应存在演化关系,该演化关系给本文针对研究方法演化分析提供了逻辑依据。而要对研究方法演化情况进行分析,需要将研究方法类关键词从所属主题社区中提取出来,以初步构建研究方法演化链。由于前文小节对关键词的语义类型已经进行标注,因而研究方法类关键词的提取工作其实已经完成。初步构建的研究方法演化链由5个时期的研究方法类关键词集合构成,形如Topicti[M]→Topic(t+1)j[M]→Topic(t+2)k[M]→Topic(t+3)p[M]→Topic(t+4)n[M],其中 Topicti[M]代表t时期的第i个主题社区下研究方法类关键词集合。
2.3.2 研究方法演化链的优化
在本文中,研究方法演化链的优化分为两个步骤:研究方法节点的扩充和研究方法节点的评价及排序。
(1)研究方法节点扩充。由前文可知本文采用改进的E指数方法对关键词进行筛选,但分析公式(1)发现,当两节点共现频次为1时,log2(Cij)的值为0,会导致关键词词对共现强度为0。假设某研究方法类关键词的词频大于1,它与社区中多个语义关键词存在共现关系,但每组词对的共现频次都为1,因而词对的共现强度为0,会导致该研究方法类关键词丢失(见图2)。
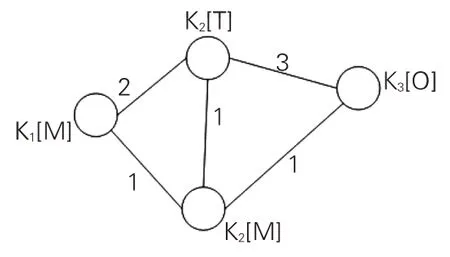
图2 研究方法节点示意图
在语义关键词的初步筛选阶段,上述特殊现象会使得共词网络丢失重要的研究方法类关键词,为保证研究方法演化链的完备性,本文对研究方法节点进行补充。考虑到社区的主题特征集中体现在研究主题类关键词,因而本文以研究主题类关键词为基础,将与之存在共现关系的研究方法类关键词补充进主题社区,具体步骤如下:第一,遍历社区i内研究主题类关键词ki[T];第二,首先,查询ki[T]所在论文集合DT,遍历DT中的每一篇论文Dk,以Dk摘要为基础,人工筛选出摘要中的研究方法作为研究方法类关键词,添加至论文Dk的关键词列表keylistk中;其后,将所有论文所对应的关键词列表合并去重后形成主题社区i的关键词集合ki_set;第三,遍历ki_set集合中的所有研究方法类关键词。若该关键词之前不在社区i中,则将该关键词添加到主题社区i中,同时将该关键词与研究主题类关键词ki[T]共现的边也添加到社区i中;若该关键词原本就在社区i中,则进一步判断该关键词与ki[T]的共现边在社区i是否存在,若不存在则将词对共现边加入社区,否则原共现边的频次加一。若该研究方法类关键词与社区中除研究主题类型以外的其他语义关键词也存在共现关系,则一并加入到社区中,最终得到扩充后的主题社区。
(2)研究方法节点的评价及其排序。为了直观地把握研究方法在其所属主题社区中的重要程度,本文从度中心性以及区分度两方面对研究方法节点进行评价,随后利用TOPSIS方法对两项指标进行综合评价,以度量研究方法类关键词在主题社区中的重要程度。
第一,度中心性。主题社区作为共词网络的子图,为无向带权类型网络。本文将关键词语义类型引入共词网络,因而在计算研究方法节点度中心性时,需要同时考虑关键词词对共现频次以及与研究方法节点存在共现关系的节点的语义类型。带权网络的度中心性计算方法如下[24]:
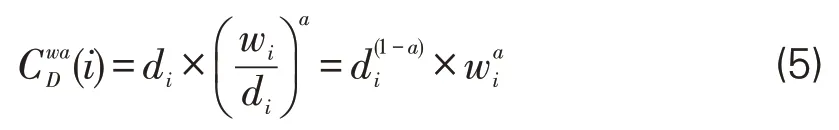
其中,di为关键词节点度数,即与多少关键词存在共现关系,wi为关键词词对共现频次总和。α 为调节系数。当α=0 时,当α=1时,当0<α<1时,节点度中心性介于di和wi之间,在词对共现总频次相同的情况下,有利于度数较高的关键词;当α>1时,度中心性则更有利于度数较低的关键词。基于关键词语义类型的节点度中心性计算方法如下:
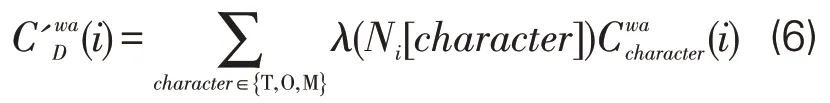
公式(6)中,Ni代表与i节点存在共现关系的关键词节点集合,根据所连节点的语义类型不同,可将Ni分为Ni[T]、Ni[O]、Ni[M]3种,Ni[T]表示与i节点相连的研究主题类关键词集合,Ni[O]和Ni[M]同理。λ根据相连关键词集合的语义类型特征进行区分,本文依据各语义类型对社区中主题属性的凸显度,对λ值进行设定,具体见公式(7)。代表关键词i与某一种语义类型关键词节点相连时的度中心性,其计算方式与公式(5)类似,见公式(8)。
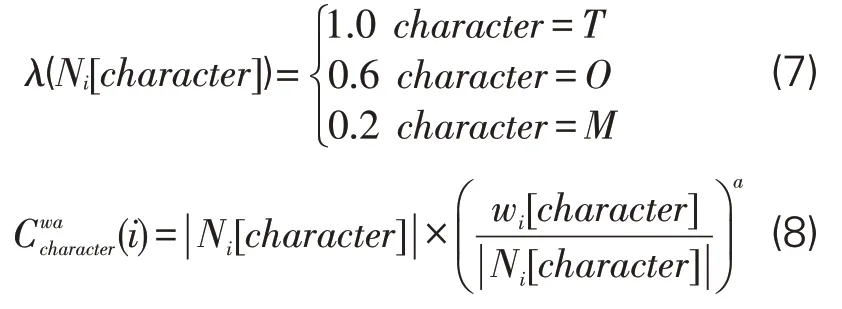
其中,|Ni[character]|代表节点i所连接的某种语义类型关键词的数量,wi[character]代表关键词i与某种语义类型关键词的共现总频次。α为调节系数,其含义同公式(5)。
第二,区分度。本文利用逆文档频率思想对关键词区分度进行描述,即研究方法类关键词i在不同时期出现的频次越少,则该研究方法区分度越高,反之亦然,计算方法如下:

其中,freqyeari为关键词i在不同时期出现的频次。
第三,基于TOPSIS方法的多指标综合评价法。本文基于TOPSIS方法思想,将主题社区中的每个研究方法类关键词节点看作一个方案,以度中心性和区分度作为节点方案属性,从而将评估研究方法节点重要性问题转换为多属性方案决策问题。通过监测节点方案与最优解、最劣解的距离来进行排序,最靠近最优解同时又最远离最劣解为最好解,否则为最差解。
2.3.3 研究方法演化链的分析
(1)研究方法的数量演化。本文采用折线图的方法对研究方法演化链中各时期研究方法数量进行分析。
(2)研究方法的重要性演化。为更具体地呈现研究方法重要性演化情况,将研究方法演化链进一步划分为“稳定型”“成长型”“突变型”“衰退型”4种类型,其表现特征如表2所示。

表2 研究方法演化链类型及其特征
3 实证结果及分析
3.1 数据获取及关键词处理
考虑到关键词人工划分工作量较大,为验证模型的可行性,本文以《情报学报》《情报资料工作》《情报理论与实践》3种图书情报领域比较有代表的核心期刊为例,在CNKI和万方数据库中检索3种期刊2011-2020年的所有学术论文,导出题目、关键词、摘要等外部特征信息,筛除投稿须知、卷首语等非学术文章后,共获取期刊论文5,891篇。主题演化分析中关于时间区间的划分方法主要有根据时间标签确定法和固定时间窗口法。由于每年刊载的论文数量大致相同,因而采用固定时间窗口法将10年时间划分为5个时期,依次对应2011-2012 年、2013-2014 年、2015-2016 年 、 2017-2018 年 、 2019-2020年。针对关键词中常出现的中英翻译、同义词、缩写、单复数等现象,进行规范化处理。而后依据表1对关键词语义类型进行划分,共得到语义关键词15,229个,将各时期的关键词用id进行标识,得到各时期关键词列表,其中第1时期关键词列表见表3。
表3 第1时期关键词列表(部分)
3.2 共词网络构建及主题演化链构建
利用公式(1)对各时期关键词进行筛选,构建语义关键词共词网络。其中第1时期语义关键词词频及共现频次见表4-5。
表4 第1时期关键词词频(部分)
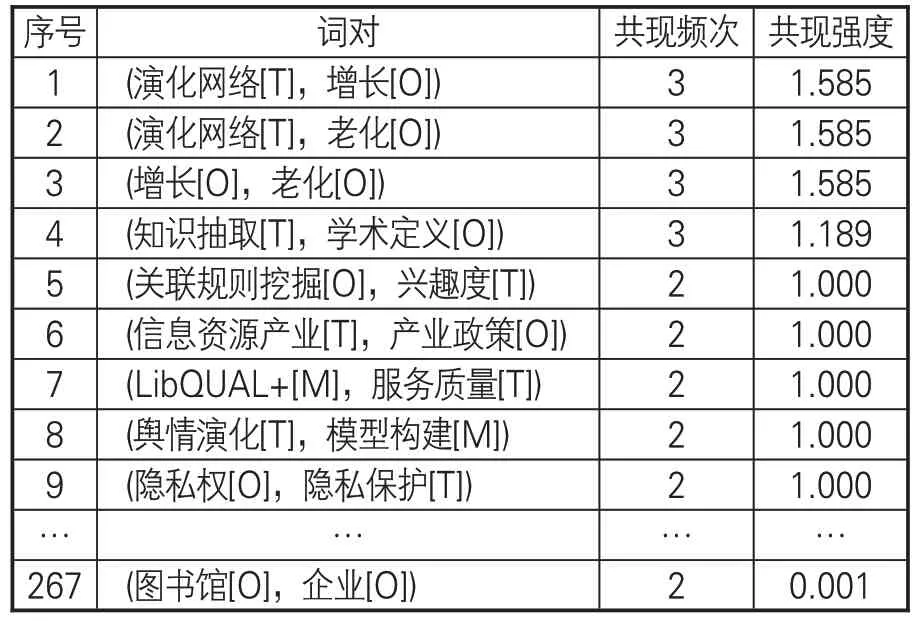
表5 第1时期语义关键词共现词对列表(部分)
将节点信息放入node.csv表格,将边信息放入edge.csv 表格,利用python 程序读取node.csv和edge.csv文件构建语义关键词共现矩阵,导入Louvain算法程序进行社区划分,共得到53个主题社区,其中第1 时期主题11个,第2、3时期主题各9个,第4时期主题10个,第5时期主题14个。为了方便后续对主题社区进行分析,针对每个主题社区进行编号,其编号的命名规则为“时期序号+主题序号”。例如,第4时期第10个主题社区其id为“410”。以第4时期的社区划分结果为例,其主题社区id及社区内语义关键词见表6-7。
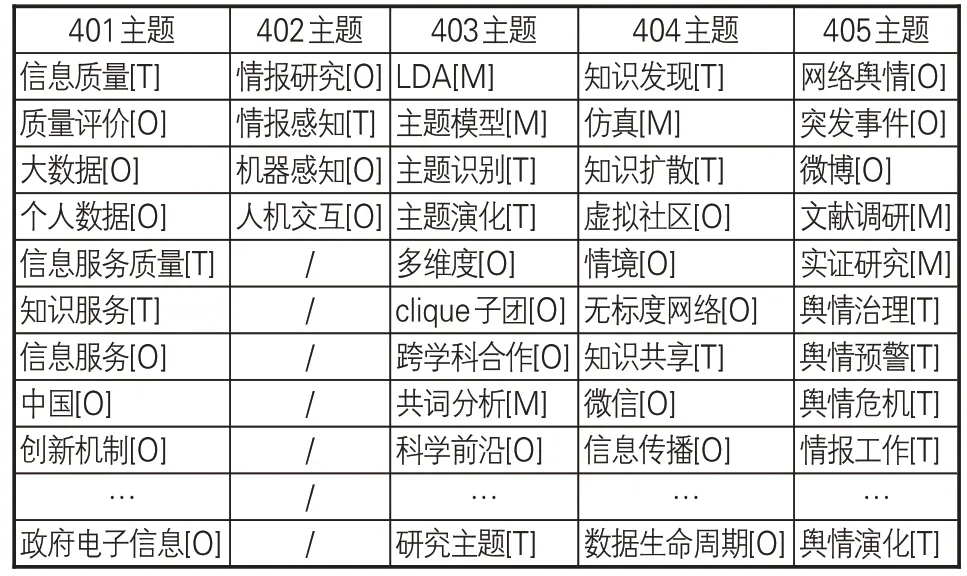
表6 401-405主题社区关键词列表
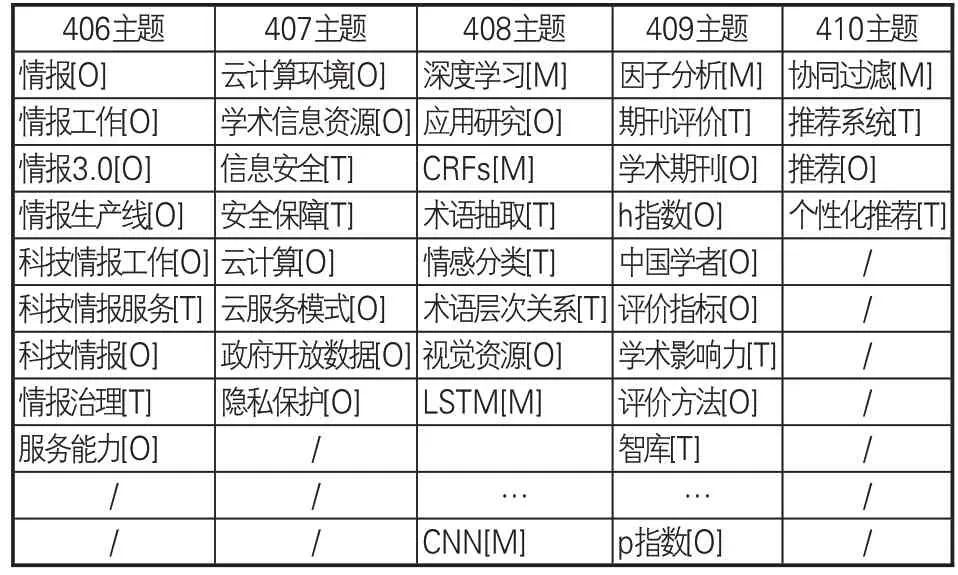
表7 406-410主题社区关键词列表
利用公式(2)-(4)构建相邻时期主题社区关联强度矩阵,并利用heatmap函数生成主题关联强度矩阵热力图。其中,第4和第5时期的社区主题关联强度如图3所示。单元格颜色越深则主题关联强度越大。通过实验得知,当阈值设为0.1时,两个主题社区具有较为明显的演化关系,相邻时期的主题社区演化关系识别如下:
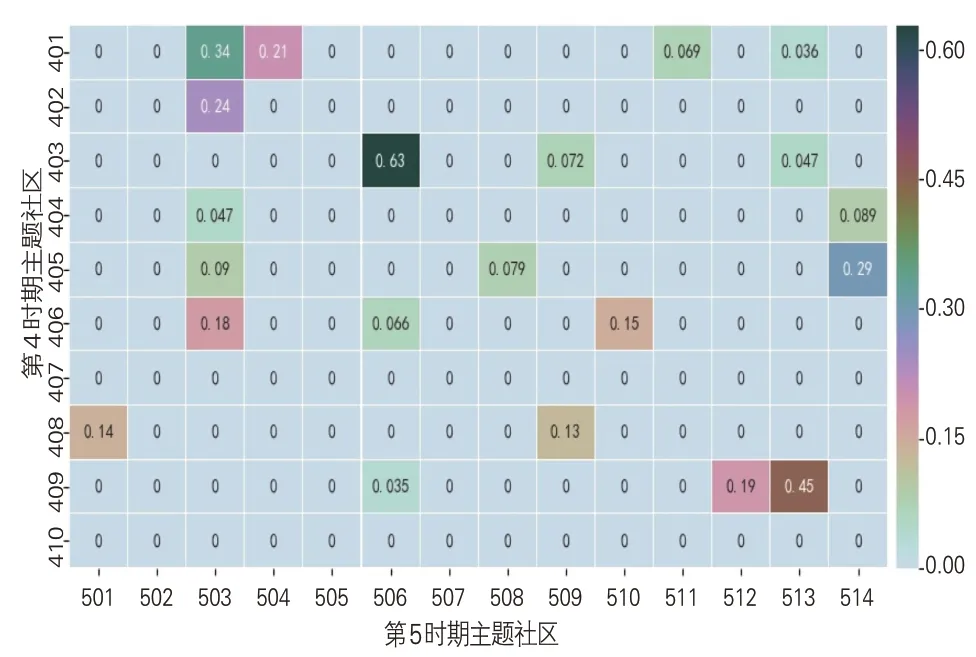
图3 第4时期与第5时期主题关联强度

基于相邻时期的主题演化关系,构建出3条完整的主题演化链。
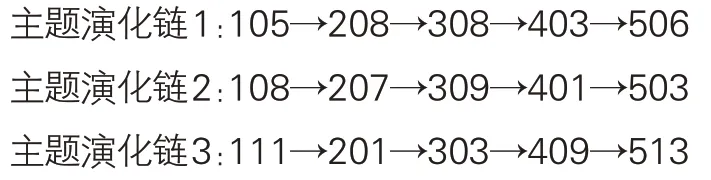
本文依据主题演化链主题社区中研究主题类关键词及其频次确定主题社区名称,分析发现主题演化链1中的主题社区主要围绕研究热点[T]、主题识别[T]、主题演化[T]等研究主题类关键词,因此将主题演化链1 确定为研究热点主题演化链;主题演化链2主要围绕信息服务[T]、知识服务[T]、知识共享[T]、图书馆[O]等语义关键词,因此将主题演化链2确定为图书馆信息知识服务演化链;演化链3出现频次较高的语义关键词主要有学术影响力[T]、期刊评价[T]、评价指标[O]等,因此将演化链3确定为学术评价演化链。
3.3 研究方法演化链的构建及优化
从主题演化链中抽取研究方法类关键词以构建研究方法演化链,在主题社区编号后添加后缀“[M]”表示主题社区中研究方法类关键词的集合,由此形成3条完整研究方法演化链。
“研究热点主题”社区研究方法演化链:
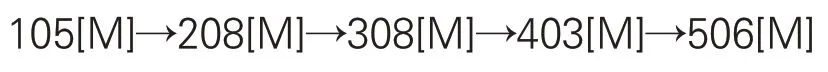
“图书馆信息知识服务”社区研究方法演化链:
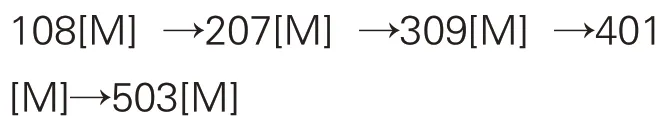
“学术评价”社区研究方法演化链:
对每条演化链中的研究方法集合进行扩充,利用公式(5)-(9)对研究方法节点进行重要性评价和排序。由于最终得到的评价值较小,为方便直观分析,统一乘以100作为综合得分。其中,506[M]排名前10研究方法见表8。为清晰呈现研究方法重要性的动态变化情况,本文利用D3.js 工具编写代码对研究方法演化链进行可视化展示,见图4-6。同一时期内,节点之间的高低次序代表当期研究方法的重要性排序,以“学术评价”研究方法演化链为例,第1 时期的“社会网络分析”节点位置最高代表其重要性最高。
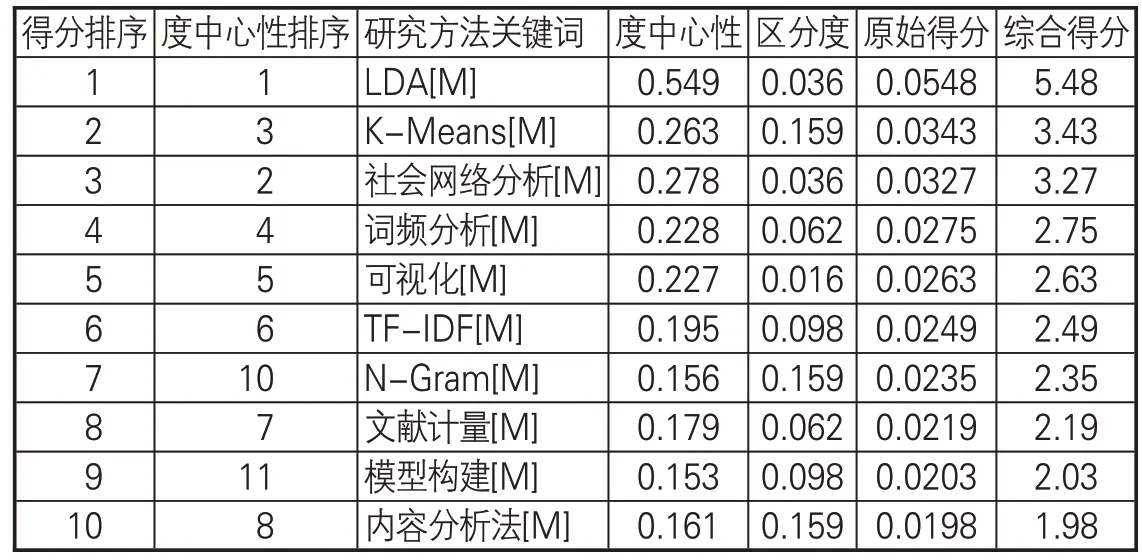
表8 506[M]研究方法列表
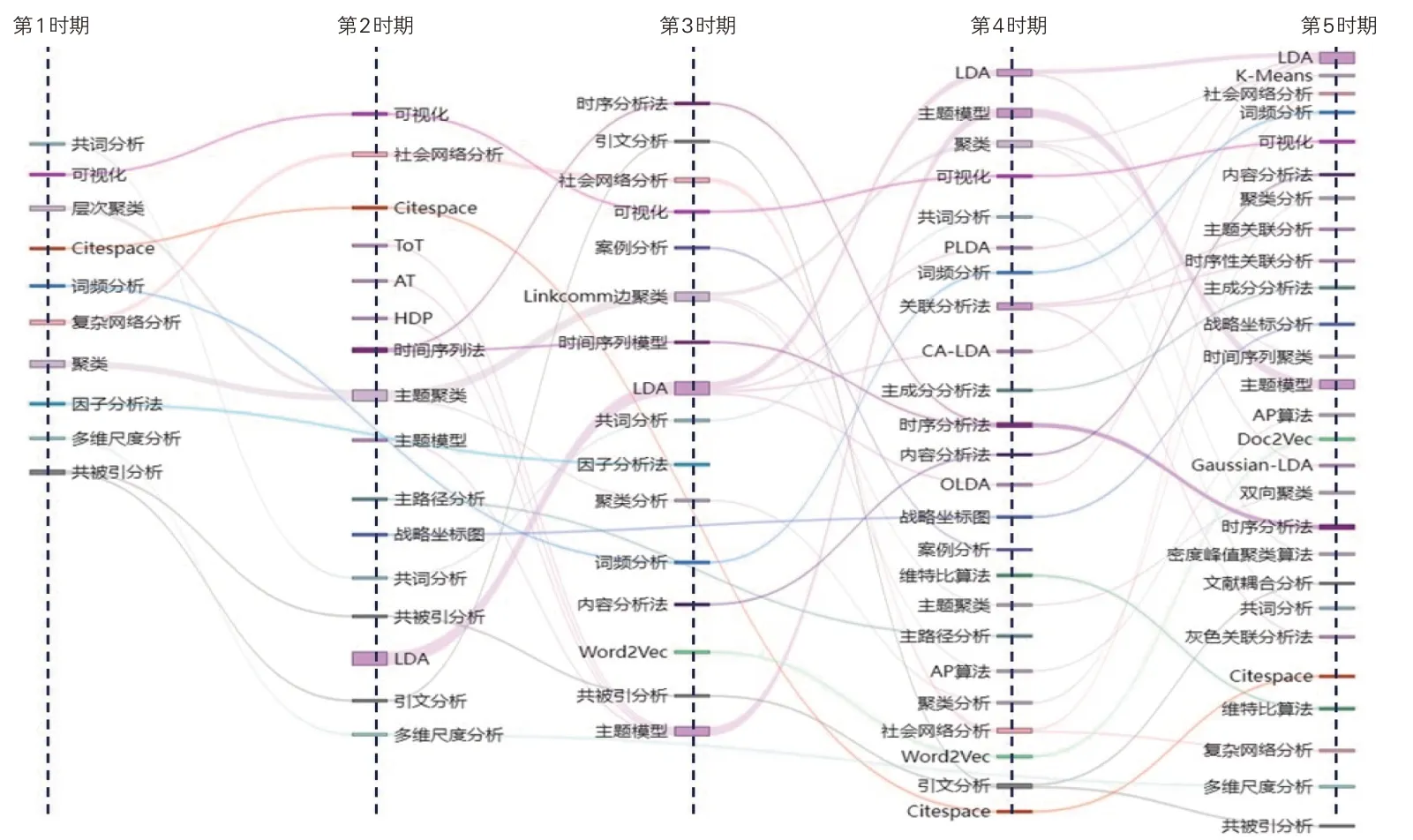
图4 “研究热点主题”研究方法演化链
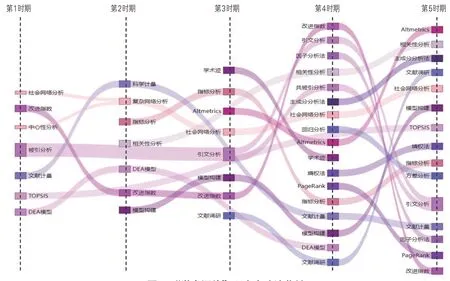
图6 “学术评价”研究方法演化链
3.4 研究方法演化链分析
3.4.1 研究方法的数量演化
统计各时期研究方法关键词数量并绘制折线图,见图7。“研究热点主题”演化链中的研究方法随时间呈现稳步增长态势,原因有两点,一是该主题发文量的增大可能会导致研究方法数量增多;二是单篇文献所用方法的多元化也会使研究方法关键词规模的扩大。
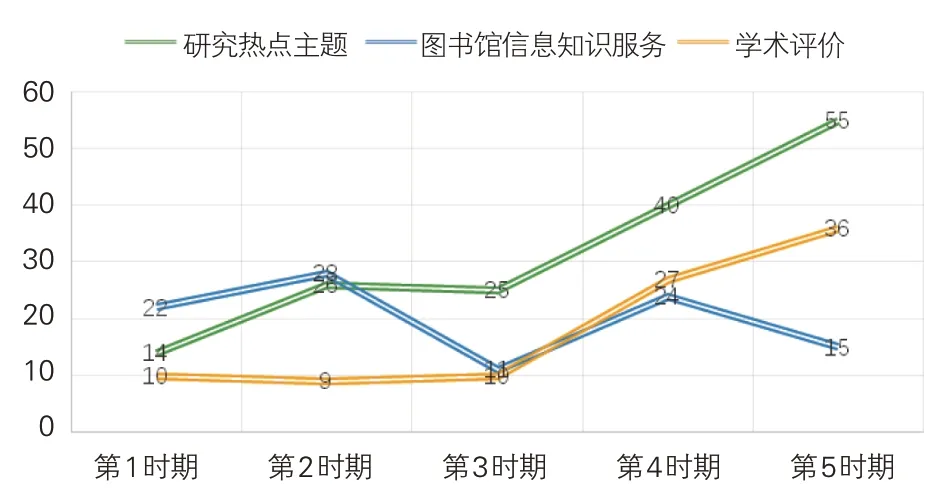
图7 各时期研究方法数量变化曲线
“图书馆信息知识服务”演化链的研究方法数量整体呈不稳定的震荡波动态势,略微有下降的趋势。仔细分析该主题对应的学术论文发现,“图书馆信息知识服务”的相关研究中学理类论文占有一定比例,可能会是导致研究方法迭代速度较慢的原因,再加之数据驱动的第四范式崛起,从而可能会导致研究方法规模下降。
“学术评价”演化链的研究方法总数在1、2、3时期呈现较为稳定的态势,但在4、5 时期有较高幅度的增长。导致这一现象可能是“学术评价”研究主题所运用的研究方法出现了较大变革,引发学界广泛关注,从而使得发文量增加,其研究方法规模扩大。
3.4.2 研究方法的重要性演化
本文分别从“稳定型”“成长型”“突变型”“衰退型”4种类型研究方法演化链出发,对3条研究方法演化链进行剖析。
(1)“稳定型”研究方法演化链。第一,“研究热点主题”演化链,“聚类”“可视化”“网络分析”等研究方法呈现稳定的演化状态。以“聚类”为例,第1时期出现“层次聚类”“聚类”,第2 时期有“主题聚类”,第3 时期出现“Linkcomm边聚类”“聚类分析”,第4时期代表聚类的研究方法有“聚类”“主题聚类”“聚类分析”“AP算法”等,第5时期出现“K-Means”“时间序列聚类”“双向聚类”“密度峰值聚类算法”“AP算法”等方法,可知虽然聚类方法逐渐多样化,但聚类思想却贯穿主题始终。从研究过程看,“研究热点主题”需要将相同或相近属性的研究对象凝聚成社团或簇,以便后续进一步展开研究。第二,“图书馆信息知识服务”演化链,根据图5可知,“模型构建”和“问卷调查”具有较为稳定的演化特点。其中,“模型构建”研究方法在第1、3、4时期的排名较高;“问卷调查”在第1、2时期排名较高,在第3、4、5时期排名较低,但该方法始终贯穿整个演化链。由此可知,“模型构建”与“问卷调查”是研究“图书馆信息知识服务”主题时所用到的传统研究方法。第三,“学术评价”演化链,“社会网络分析”“指标分析”“引文分析”呈现出稳定演化态势。需要注意的是“引文分析”在5个时期中具有不同形式,其在第1时期为“被引分析”,第4时期为“引文分析”和“共被引分析”。上述研究方法之间存在的内在关联可能是其稳定演化的原因之一,学术评价往往引用相关指标来衡量期刊、作者或者机构的学术影响力,而引用指标是引文分析后的结果,在引文网络分析中通常借助社会网络分析方法对网络中节点特征属性进行描述。
(2)“成长型”研究方法演化链。第一,“研究热点主题”演化链,由图4可得,“LDA”为“成长型”研究方法。“LDA”在第2时期排名较后,在第3、4、5时期“LDA”热度逐渐攀升,并衍生出“PLDA”“CA-LDA”“OLDA”“Gaussian LDA”等LDA 的改进模型。同时,“时序分析”“内容分析法”等研究方法也呈现成长型演化特征。第二,“学术评价”演化链,“相关性分析”和“Altmetrics”呈现成长型演化特点。以“Altmetrics”为例,“Altmetrics”是一种基于社交网络来评价学术成果的计量指标。由于该指标起源于国外,若将其应用于国内学术成果评价,仍需进行深入研究,因而众多领域学者投入到Altmetrics 的研究中。同时,“Altmetrics”排名大幅提升的时间点大致与“学术评价”演化链研究方法数量大幅上升的时期一致,因而本文大胆推测“Altmetrics”研究方法是“学术评价”研究方法数量激增的重要因素,对“学术评价”主题研究产生重大影响。
(3)“突变型”研究方法演化链。第一,“研究热点主题”演化链,根据图4可知,“因子分析法”“耦合分析”“案例分析”等研究方法呈现出“突变型”演化链特征。第二,“图书馆信息知识服务”演化链,突变型研究方法占有较大比例,例如“因子分析法”“熵权法”“系统动力学”“层次分析法”等,其中“因子分析法”也从侧面反映出这一类研究主题的方法论体系仍不够成熟有待完善。第三,“学术评价”演化链,“TOPSIS”“DEA模型”等方法呈现出间断出现的演化特征,两种研究方法的提出时间都较早,没有连续使用的原因可能在于“学术评价”的研究侧重点迁移,与两种方法的契合度逐渐降低。
(4)“衰退型”研究方法演化链。第一,“研究热点主题”演化链,“Citespace”较为满足“衰退型”演化特征。“Citespace”在第1、2、4、5时期的排序分别是7、8、41、51。其原因主要在于Citespace软件逐渐无法满足“研究热点主题”研究领域日益多元复杂的研究需求,如Citespace软件无法适用于CNKI数据库进行引文分析,Citespace构建的关键词网络关系太过单一等。第二,“图书馆信息知识服务”演化链,“比较分析”与“结构方程模型”研究方法呈现衰退型趋势。“比较分析”和“结构方程模型”方法在第1、2、3 时期排名靠前或呈现上升趋势,但在第4、5时期消失,这一现象可能与“图书馆信息知识服务”研究内容变化有关,使得研究方法不再与研究主题相契合,也有可能与方法自身存在的缺陷有关。
5 结语
本文通过共词网络构建、主题识别、主题演化关系判断、研究方法演化链构建、研究方法演化链优化及其分析等步骤完成了学术论文研究方法演化分析模型的构建,并利用CNKI以及万方数据库获取学术论文数据,验证了研究方法演化分析模型的可操作性,并从主题的维度对研究方法的演化进行详细阐释。然而,本文仍存在不足:第一,数据量不足,本文考虑到人工关键词语义划分工作量的原因,只选择《情报学报》《情报资料工作》《情报理论与实践》3本期刊,使得主题社区未能全面覆盖所有研究热点;第二,演化过程相对单一,本文中将主题社区演化关系定义为“一一对应”关系,即一个前驱社区对应一个后继主题社区,而实际上在科研主题的发展过程中旧主题可能分裂成多个新主题,多个旧主题也可能融合成一个或多个新主题。针对这些复杂的演化过程本文未能进行深入分析。针对以上不足,本人将在后续研究中对其进行逐一探讨。
