基于推荐算法的高血压患者偏好方法研究*
2022-06-16赵贝宁熊巨洋赵仁伟
赵贝宁 熊巨洋 赵仁伟 金 唐
(1.华中科技大学医药卫生管理学院 武汉 430030)(2.河南省渑池县果园乡中心学校 渑池 472400)
1 引言
随着经济的快速发展,人们的生活水平日异得到提高。由于各种不良的饮食习惯、作息习惯等原因导致高血压疾病患者数量也呈现快速增长的趋势。高血压疾病的治疗过程是繁琐复杂的,同时不同类别的高血压人群对于健康管理的偏好不尽相同,因此,有效找到各类高血压患者的健康管理偏好对于治疗高血压疾病来说具有重要的意义。而推荐算法是解决信息与个性化需求之间的有效方法,在诸多的推荐算法中,协同过滤技术较为广泛应用,但是传统的协同过滤推荐算法具有实时性较差、拓展性较差的特点。针对推荐算法的缺点,部分专家学者提出了解决思路。如刘靖明,韩丽川等人结合K均值聚类方法,找到与用户距离最近的集合实现推荐[1]。学者根据对用户行为的分析,建立特征表,提出了聚类的标准[2~4]。李辉,石钊等建立“用户-矩阵”改进聚类中的近邻算法,从一定程度上找到解决推荐实时性问题的办法[5]。周军锋、汤显等根据用户的评分结果,分段归纳用户的分数,根据分数区分不同类别用户进行推荐[6~8]。俞琰,邱广华等通过对用户兴趣网的研究,提出网络混合推荐算法,利用拓扑网络结构分析用户的兴趣行为[9~13]。王均波将用户兴趣、时间效应、用户对项目偏好程度以及用户的特征有机的结合起来融入推荐算法中[7,14~15]。然而目前提出的推荐算法存在执行效率不高的问题,且推荐的准确度仍需要进一步考量。
对于高血压疾病健康管理的用户偏好度推荐,需要针对目前协同过滤算法存在的问题进行改进,在前期特征选择阶段进行兴趣组合、兴趣扩充等方法,在算法模型阶段需要利用聚类思路,进行组合推荐,建立基于高血压疾病患者的行为、特征和内容进行过滤与组合推荐,改进协同过滤推荐算法的实行性弱、扩展性差的特点,并提高推荐的准确度。
2 算法总体框架
传统的协同过滤推荐算法是以用户评分作为特征基础,不同的分数代表不同用户的喜好程度,以分数的特征代表用户之间的特征。而组合建立推荐方法目的在于解决算法在运行过程中的数据稀疏性、准确度方面存在的问题,从而提高对高血压患者健康管理偏好推荐的准确性。首先,对高血压健康管理进行属性分析,利用聚类的方法对项目评分值预测,建立“高血压患者-健康管理”项目评分矩阵,为处理数据稀疏性做准备,保证推荐过程中的多样性;其次将聚类的结果值作为特征分析依据,利用患者在在日常健康管理中的各种行为特征提取患者对健康管理的倾向度,提出高血压患者对健康管理方式的偏好融合相似计算方法,改进传统协同过滤方法中的局限相似性计算方法;最后,分析高血压患者健康管理偏好倾向度的计算结果,对用户进行聚类,实现健康管理方式的推荐,改进后的协同过滤推荐方法相对于传统的方法在高血压患者健康管理偏好推荐方面更具有实用性。算法总体框架结构如图1所示。

图1 算法总体框架
算法的执行过程中,健康管理项目聚类是先行开始的,其次高血压患者进行聚类,利用近邻相似度计算实现近邻查找、预测和推荐,并将聚类的结果用于推荐中。其中除预测和推荐外的环节,均可提前进行处理,处理后实行推荐功能时仅需进行预测和推荐环节即可,后续对其余环节持续进行更新。这样既可以节省算法的运行时间,也可以解决算法在应用过程中实时性差的问题。
2.1 基于内容的聚类算法描述
对象应具有的特征和采取的相似度计算方法关乎聚类效果的好坏,将高血压患者的群体意见和健康管理的基本属性相结合用于聚类计算,并通过组合扩大特征,实现提高算法计算精确度的目的,达到聚类准确性高的效果。方法从高血压患者的行为特征和内容中提取健康管理的偏好标识,将标识与健康管理项目特征相结合,计算健康管理项目中的相似性,实现项目聚类。同时利用聚类结果判断相似近邻的健康管理子项目,根据邻居集合确定所评的分值集合,将“高血压患者-健康管理”项目评分矩阵进行填充,使得数据的稀疏性问题得到解决。因此,可以引入K-Means聚类方法实现项目聚类,主要步骤如下:
Step1:设定健康管理方式的项目集为I,I 中的子集分别为i1,i2,…,in,从I中任意选出S个子项目,并设S为聚类中心个数,可以看做C1,C2,…,Cn。
Step2:将项目和聚类中心的相似性记为sim(ii,Cj),以相似性为分界,将各个子项目划分到相似度较高的聚类簇中,直至没有可划分的为止。
Step3:计算项目的平均值,并重新确定聚类中心。
Step4:将Step2 和Step3 持续重复,直至聚类中心C1,C2,…,CS与原循环中的聚类中心保持吻合度一致。
2.2 基于行为的聚类算法描述
在基于内容的聚类算法结果基础上,将不同的高血压患者对各种健康管理方式的评分特征设为满意度,高血压患者的各种行为记为关注度,对其进行相似度融合计算实现对高血压患者的聚类,基于行为的聚类也采用K-Means聚类方法。
Step1:设定患者数为n,m 为用户聚类数,患者集为U,从U 中选取m 个用户,可以看做C1,C2,…,Cn。
Step2:将患者和聚类中心的相似性记为sim(Ui,Cj),以相似性为分界,将各个患者划分到相似度较高的聚类簇中,直至没有可划分的为止。
Step3:计算平均值,并重新确定聚类中心。
Step4:将Step2 和Step3 持续重复,直至聚类中心C1,C2,…,Cm与原循环中的聚类中心保持吻合度一致。
2.3 协同过滤组合推荐
组合推荐方法的整体思路是:利用基于内容的聚类方法分析患者对各种健康管理方式的分值,将其填充到“高血压患者-健康管理”项目评分矩阵,结合患者行为特征,实现内容与行为特征融合的聚类,利用患者对健康管理方式相似度偏好的计算方法,实现预测,根据预测结果进行推荐。组合推荐算法可分为挖掘高血压患者倾向度、近邻搜索、排序推荐三部分。
1)高血压患者倾向度。倾向度的分析建立在行为集获取的基础上,对行为进行评分就是获取患者喜爱程度的过程,将喜爱程度数字化,挖掘高血压患者对健康管理方式的潜在兴趣。
2)近邻搜索。可看做是目标相似度较一致的患者聚类的过程,通过对患者间的相似度计算,将相同健康管理喜好的患者聚类,找到相似的邻居。
3)排序推荐。利用最近的邻居集合,采用预测计算公式计算患者间的相似性,将具有同类喜好的患者健康管理方式进行推荐,使患者获得自己满意的健康管理方式,产生推荐集。
算法具体步骤如下:
Step1:设定m 表示患者,n 表示健康管理方式,评分矩阵为Rm*n,矩阵中的每个元素表示患者对健康管理方式的评分。
Step2:设定相似度阈值为X,目标患者U,其它患者为V,m 为聚类数,则计算患者间的相似度sim(U,V)计算公式为
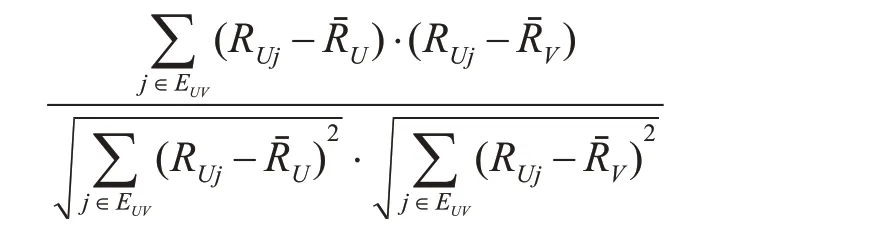
Step3:选取相似度大于阈值X 的患者集,取前m 个作为最近邻居,获得目标患者的最近邻居集MN。
Step4:根据目标患者已有的评分信息,及最近邻的评分数据,预测目标患者偏好的健康管理方式。预测公式如下:

其中,Rvk为患者V 对项目方式K 的评分,RˉU和RˉV分别是填充矩阵后的患者U,V的平均分值。因此,可以根据预测值进行推荐排序,推荐高血压患者偏好度高的健康管理方式。
3 实验结果及分析
实验采用的数据集共包含6 万条记录,包括803个高血压患者对1243个健康管理方式的评价,其中每个患者至少对20 个健康管理方式进行评分。为验证算法的合理性以及可行性,与传统的协同过滤推荐算法分别在实时性、数据稀疏性和准确性方面进行对比分析。
1)实时性
在实验过程中,把聚类数和近邻数的取值进行设定,在分析相关数据的基础上,将患者聚类数均值取20 时分析算法在查询最近邻居效率的情况,实验结果分别如表1和图2所示。
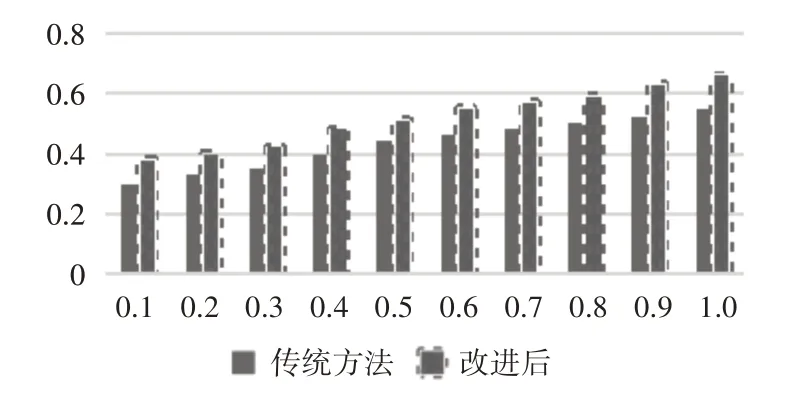
图2 实时性对比分析图
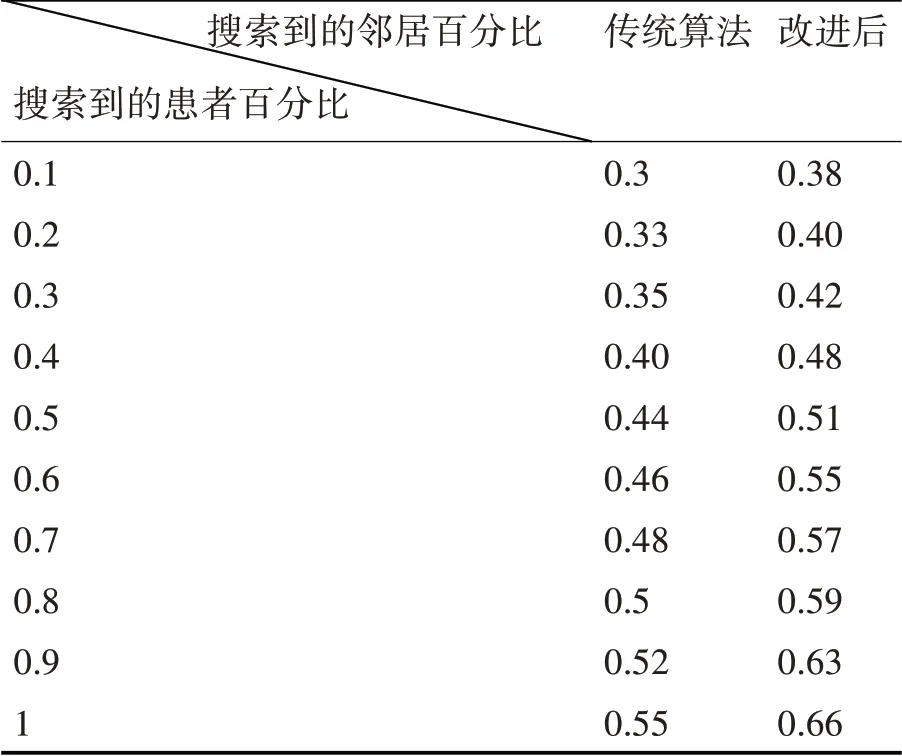
表1 实时性对比分析表
实验结果可知,搜索的近邻数与搜索患者百分比、制定患者近邻数成正比增长的趋势。因此,在聚类改进算法后,目标患者和近邻患者划分到最相似的患者簇中,利用较小的空间就可以找到较大的数量近邻,使得效率得到明显的提高。
2)数据稀疏性
数据稀疏性验证主要是验证实验过程中填充评分矩阵方法,研究此方法对于数据稀疏性问题的效果,实验对算法在原始均值填充和以聚类填充两种方式作比较,以项目预测评分的MAE[0,1]均值作度量标准,实验结果分别如表2和图3所示。
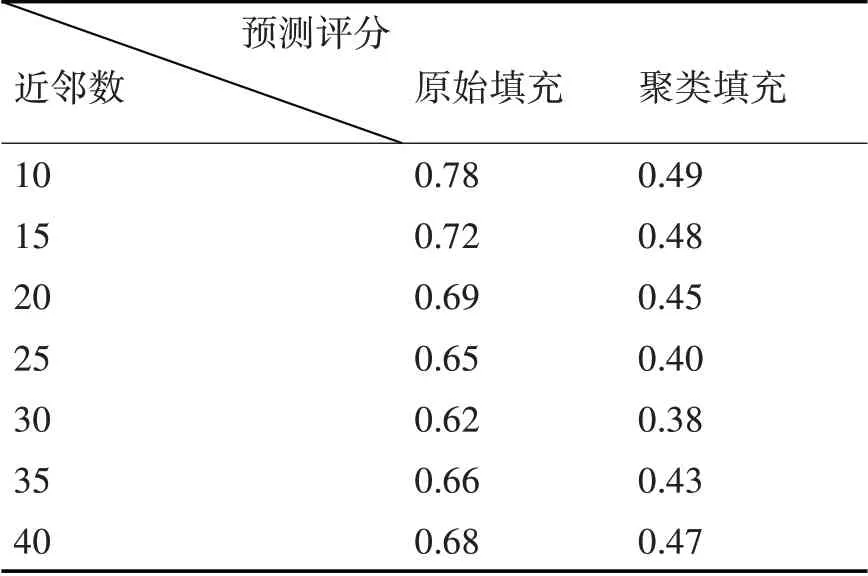
表2 数据稀疏性对比分析表
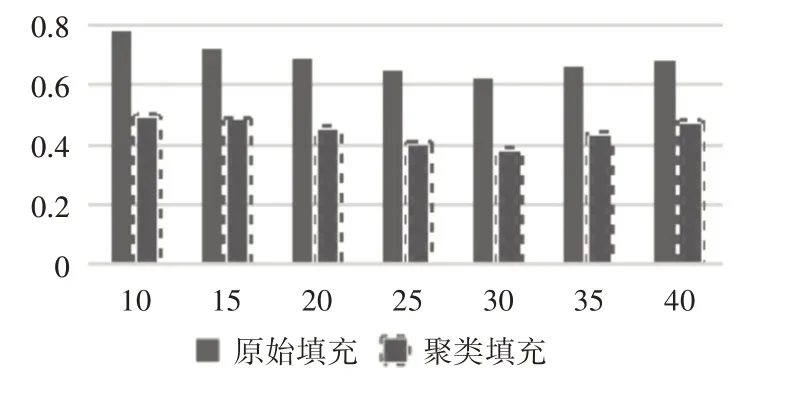
图3 数据稀疏性对比分析图
实验结果可知,在评分矩阵中,聚类填充方法与原始均值填充方法的MAE 值更低,代表准确性更高。可以说明聚类填充评分矩阵的方法可以解决数据稀疏性的问题,提高推荐的精度。
3)准确性
在实验过程中,为验证改进后的推荐算法与传统的协同过滤推荐算法相比的准确性,以预测评分MAE 作为度量标准,利用测试集进行多次实验,可得到实验结果如表3和图4所示。
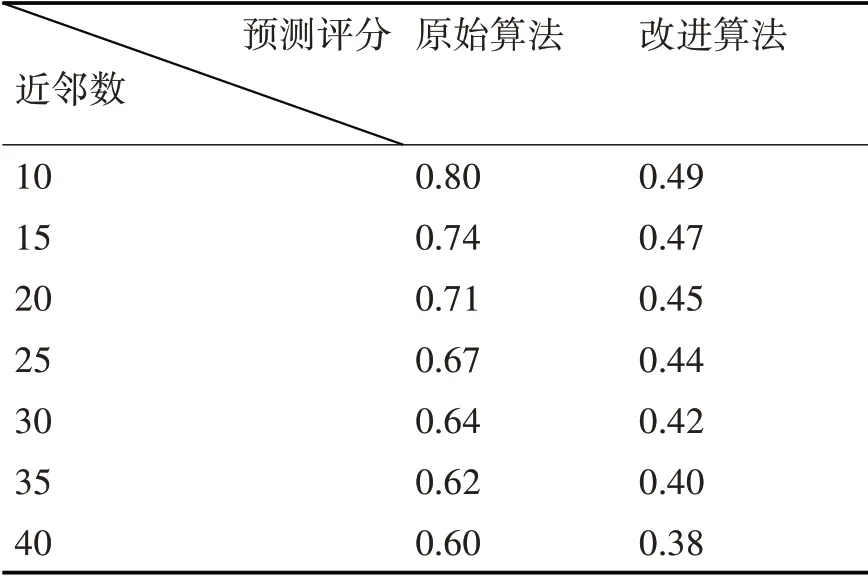
表3 算法准确性对比分析表
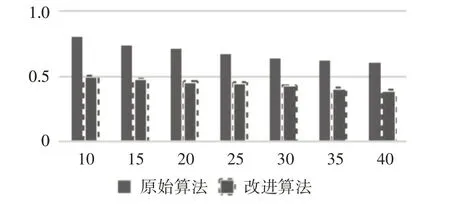
图4 算法准确性对比分析图
实验结果可知,在邻居数目由10~40 的逐步变化过程中,MAE 值在不断降低,在实验结果图中可发现改进后的组合推荐算法MAE 值更低。因此,改进后的推荐算法较传统的算法比具有较好的推进准确度。
4 结语
本文通过对高血压健康管理方式的分析,研究了推荐算法的应用,并分析传统协同过滤推荐算法的不足,对传统协同过滤推荐算法存在的问题进行了研究,综合健康管理方式和高血压患者的行为特征,结合聚类思想方法对算法进行改进,得到了如下结论。
1)改进后的推荐算法较传统协同过滤推荐算法相比,可以提高算法在应用过程中查询高血压患者最近邻居的效率。
2)改进后的推荐算法较传统协同过滤推荐算法相比,可以解决算法在应用过程中的数据稀疏性的问题,提高推荐的精度。
3)改进后的推荐算法较传统算法协同过滤推荐相比,可以提高对高血压患者选择偏好度较高的健康管理方式的精度。
