基于蜂群优化核极限学习机的电能扰动识别方法
2022-06-15何昌龙曲丽萍高泰路
何昌龙,曲丽萍,张 杰,高泰路
(北华大学电气与信息工程学院,吉林 吉林 132021)
近年来,电力电子技术在现代电网中的大量使用,大容量冲击性负荷的投切,不但严重威胁到系统的暂态稳定性,同时也会影响供电质量.为了提高供电质量,实现优质供电,需要准确识别出电能中的各种扰动信号,针对不同扰动,采取相应的补偿措施.比如,系统中节点电压降低,需要投入无功补偿装置对其进行无功补偿,但是补偿控制的前提是准确检测系统扰动类型,进而根据扰动类型采取相应措施.目前,常用的电能质量扰动信号特征向量提取方法有傅里叶变换(Fourier transform,FT)、短时傅里叶变换(short-time Fourier transform,STFT)、小波变换(wavelet transform,WT)等.FT在信号处理中应用非常广泛,对于平稳信号有很好的分析能力,适合信号整体分析,但对于局部高频的突变信号,不能有效进行检测分析[3].为了克服这个缺点,在其基础上引入STFT,即在FT上加入时窗,将非平稳信号看成一系列短时平稳信号,但由于窗函数宽度已提前设定,在变换过程中无法改变,对于未知信号,难以确定与信号匹配的窗函数宽度.WT的提出刚好可以解决这个问题,其思想是在STFT局部化基础上,灵活改变时间窗口和频率窗口,通过多个尺度对信号进行分析,能够更好地提取非平稳信号的特征,保留信号间的差异性.
针对特征识别方法,目前应用比较多的是神经网络.传统的前馈神经网络采用梯度下降法进行迭代训练,通过误差的反向传播,不断调整权值,导致计算量增大,训练时间增长,且容易陷入局部最小值.为了解决这一问题,提出了极限学习机模型.网络模型的参数训练不需要反复迭代,而是对输入层权值和阈值进行随机赋值;输出层权值通过广义逆矩阵求出,训练速度大大提高,且泛化性能好,已证明了其可行性.本文利用小波变换,提取扰动信号的特征向量,利用传统极值学习机和蜂群优化核极值学习机构造电能质量扰动识别算法,并进行仿真试验.
1 电能质量扰动信号的特征提取
1.1 电能质量扰动的数学模型
在电力系统实际运行中,各种扰动可能会影响系统稳定性.若暂态稳定性得不到保障,可能导致系统解列,造成大面积停电事故.因此,检测系统暂态稳定性下的状态变量,是保证系统稳定性必不可少的重要环节.系统实际运行中出现比较多的是暂态电压质量扰动,根据IEEE相关通用标准,研究表1中的标准电压和7类电压质量扰动.

表1 标准电压和7类电能质量扰动数学模型Tab.1 Mathematical model of standard voltage and seven kinds of power quality disturbances
7类扰动信号和标准信号仿真波形见图1.其中,频率f0=50 Hz,周期T=0.02 s,每个周期采样100个点,采10个周波,共1 000个采样点,电压幅值全部采用标幺值.

图1 标准信号与扰动信号波形Fig.1 Disturbance signal waveform and standard signal
1.2 小波变换原理
小波变换是一种分析信号时频特性强有力的数学变换,其原理与傅里叶变换相似,用满足一定条件的小区域波函数,经过平移、伸缩、叠加代替原始信号,其本质是度量被分析信号波形与所用小波波形的局部相似程度,相似程度越高,对应的小波系数越大.
设时域信号为f(x),小波变换可以表示为
f(x)=∑sa,bΨa,b,
其中:sa,b为小波系数;Ψa,b为小波函数.对于函数Ψ(t)∈L2(),若其傅里叶变换满足

则称Ψ(t)是一个基本小波.常见的小波有Haar、Biorthogonal、Coiflet、Daubechies等.将母小波经过平移和伸缩后得到一个小波序列族{Ψa,b}:

式中:a为比例因子;b为平移因子.
对于任意函数f(x)的连续小波变换式
若将a、b作离散化处理,就是离散小波变换.离散小波变换为

1.3 特征向量提取
对7类扰动信号和标准信号进行小波分解,得到扰动信号在不同尺度下的小波系数,以小波系数间的差异作为扰动信号分类的特征.由于小波系数冗长复杂,需要对其进行处理后才能作为表征扰动信号特征的特征向量.在处理过程中,需要保留信号的特征,同时希望维数比较少.在有效表征信号特征的同时减少维数,训练过程计算量少,训练速度快.
用MATLAB产生常见的7类电能质量扰动信号和标准信号各200个样本,共1 600个样本作为样本数据,选择合适的小波基函数进行小波变换.考虑扰动信号局部突变的特点,本文采用对暂态局部信号分解效果较好的db4小波作为母小波,对扰动信号进行N层分解,将每层小波系数平方和作为能量表征[5],即
选取标准化后的能量特征P作为新的特征输入.标准化公式
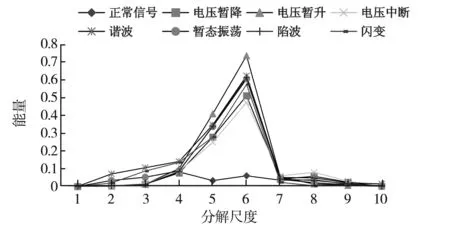
图2 扰动信号能量分布Fig.2 Disturbance signal energy distribution
式中:j=1,2,,N;k为采样点数量.将数据在[0,1]间进行归一化处理,进一步提升数据间的区分精度.小波分解层数少,会丢失信号的细节信息;分解层数多,数据信息冗长,数据特征不易区分.文献[6]采用了8层小波分解,得到扰动信号的8维特征向量,直接作为神经网络的输入.对于本文的7类扰动信号和标准信号,采用db4小波对其进行10层分解,将每层小波系数平方和作为特征向量,见图2.由图2可以清楚地看到,小波系数的能量值先从尺度1逐渐增大,然后逐渐减少,趋近于0,能量主要集中在尺度5、6、7上,尺度1和尺度10的能量值几乎为0.如果将尺度1和10的能量也作为扰动信号的特征向量,则增加了计算量,同时对数据间的区分度影响甚小,得不偿失.因此,本文选择尺度2至尺度9作为扰动信号的8维特征向量,既保留了信号的特征,也减少了计算的复杂度.
2 扰动信号的分类识别
2.1 BP神经网络
20世纪80年代末,BP(Back Propagation)网络刚刚出现就得到广泛应用.在此之前,建立输入、输出之间的关系需要通过具体的数学模型或数学表达式来实现,而神经网络如同一个黑匣子,只需要经过训练,在不知道输入、输出间具体表达式的情况下,就可以建立起联系.对于有着强大计算能力的计算机来说,采用梯度下降法来不断修正网络权值和阈值变得简单快速,使得输入、输出间的关系不需要直接写出具体数学表达式,而是隐含在神经网络参数中.在工程实践中,很多系统输入、输出间的数学模型是无法准确建立的,但是系统的输入可以控制,输出可以测量,利用大量数据对神经网络进行训练,就能得到高精度的输入、输出关系.因此,BP神经网络在工程实践中得到了广泛应用.
在BP神经网络设计中,隐含层节点个数、权值初值、学习率、学习训练函数的选择都将影响到最后的网络性能.本文根据数据样本大小,经多次尝试确定采用1层隐含层,隐含层节点数量选取为50,使得网络的训练时长和精度比较均衡.初始权值的选择也会影响网络的收敛速度和精度,为了避免初始值加权后的输入落在S型激活函数的饱和区,初始权值应选得比较小,本文取[-1,1]上的随机数.学习速率对收敛性影响比较大,学习速率大,可能在极值点附近振荡,无法收敛;学习速率小,收敛速度慢,可能无法跳出局部极值点,本文的学习速率选为0.05,兼顾训练时长和稳定收敛.
将提取的1 600个样本信号划分为训练集和测试集:每类样本取150组作为训练集,共1 200个样本;每类剩余的50个样本作为测试集,共400个样本.在训练前,首先对数据进行归一化处理,不仅能加快梯度下降算法的速度,还能提高训练精度.BP网络的期望输出(实际的扰动类别号)见表2,用1 200个样本数据对网络进行训练.通过仿真得到的各类信号分类准确率见表3.由表3可见:由于BP神经网络训练算法存在不断迭代修正网络参数的局限性,导致训练时间比较长(大于20 s),收敛速度慢;暂态振荡和电压中断这两类扰动的正确识别率比较低,参数的选择对网络性能的影响比较大.在实际运行的电力系统中,对于海量的检测数据,BP网络的训练时间会更长.当系统出现故障时,如果不能及时识别出故障类型,也就不能及时采取相应的保护措施,可能导致电网发生更大事故,更严重的会导致电网解列,大规模停电,造成不可估量的损失.

表2 BP网络的期望输出(实际扰动类别)Tab.2 Expected output of BP network(actual disturbance category)
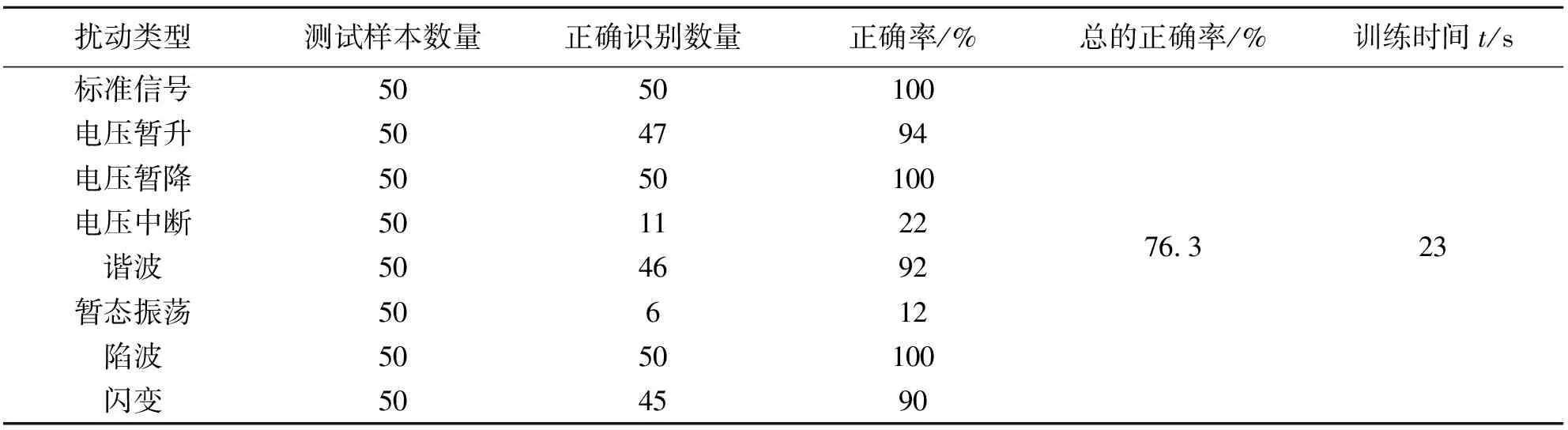
表3 BP神经网络电能扰动分类仿真结果Tab.3 Simulation results of electric energy disturbance classification based on BP neural network

图3 ELM网络模型Fig.3 ELM network model
2.2 核极限学习机
2005年,黄广斌教授针对单隐含层前馈神经网络,提出了极限学习机(Extreme learning machine,ELM)的概念,即随机产生输入层与隐含层的连接权值,训练过程无须调整,只需设置隐含层神经元个数,便可得到最优解.单隐含层神经网络(SLFN)网络模型见图3.
对于N个任意样本(Xi,Ti),样本特征列向量Xi=[xi1,xi2,,xin]T∈n,样本类别列向量Ti=[ti1,ti2,,tim]T∈m;对于隐含层中具有L个神经元的单隐含层神经网络可以表示为
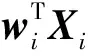
以上L个等式方程可以用一个线性方程组来表示为
Hβ=T,
其中:系数矩阵
极限学习机的神经元权重wi和偏置值bi是人为随机产生的,当激活函数g(x)选定时,系数矩阵H为常数阵,极限学习机的训练转化为线性方程组Hβ=T的求解,得到输出权值
β=H-1T.
对于不可逆的H,可以采用最小二乘法来处理,得到H的广义逆矩阵H+,求得输出权值β的最小范数解,极限学习机网络就训练完成.用广义逆求取H的逆,只是得到一个不准确的解,β存在误差,影响ELM的性能.为了解决系数矩阵病态的问题,根据BARTEL理论,把ELM的训练模型改写为一个原-对偶最优化问题.原问题是
(1)
其中:εi=[εi,1,εi,2,,εi,m]T为训练误差向量;C为惩罚参数.此时,根据KKT条件,式(1)的对偶问题为
其中:αi, j为拉格朗日算子.在此情况下,ELM的输出权值β写为
对于待分类的样本xp,其分类函数可以写为
其中:H(xp)HT和HHT均为矩阵内积形式.用满足Mercer条件的核矩阵代替内积,有
ΩN=HHT,ΩNi, j=(H(Xi))TH(xj)=K(Xi,xj),
其中:K(·)是核函数;K(Xi,xj)是核矩阵ΩN中第i行、第j列的元素,它是把数据样本Xi和xj代入核函数K(·)后所得的函数值.由此,ELM的输出权值β的计算方法写为
(2)
而分类函数则写为
(3)
通常将式(1)、(2)和(3)简称为核极限学习机的训练过程,最终网络的性能还与核参数的选择有关,找到合适的参数,是网络特征识别准确性的保障.本文选择RBF核函数,其定义如下:
根据上述推导可知,网络对样本的分类识别准确率与惩罚系数C和核函数参数γ有关,寻找使网络性能最优的C和γ是提高网络性能的关键.对于惩罚系数C来说,取值过大,容易出现过拟合;取值小,容易出现欠拟合.对于核参数γ来说,γ越小,低维空间中选择的曲线越复杂,分的类别越细,容易出现过拟合;γ越大,分的类别越粗,可能导致无法将样本数据区分开来,容易出现欠拟合.因此,(C,γ)组合最优是网络性能良好的必要前提.
2.3 人工蜂群算法优化核极限学习机
人工蜂群算法(artificial bee colony,ABC)是模拟自然界蜜蜂采蜜行为进行数值寻优的方法,可形象地表示为把所有的蜜蜂分为采蜜蜂、跟随蜂、侦察蜂3类.其中,采蜜蜂外出采蜜,并把找到的蜜源位置信息带回来分享给跟随蜂;跟随蜂分析这些蜜源信息,根据某种标准,选择去哪个蜜源采蜜;侦查蜂则是在旧的蜜源被舍弃后,寻找新的蜜源代替它.蜂群通过反复更新蜜源寻找最优质的蜜源.
本文将ABC算法与核极限学习机相结合,利用ABC算法寻找出核函数对网络的最优参数,以达到更好的泛化映射能力[11].本文的核函数选取高斯核函数,不但学习能力强,而且泛化性也比较好,在实际运用中能取得很好的效果[10].优化流程见图4.

图4 ABC算法优化KELM网络流程Fig.4 Flow of ABC algorithm to optimize KELM network
ABC算法优化KELM网络步骤如下:
1) 创建一个KELM网络.
2)设置蜂群算法的初始值.包括蜂群的大小(Nc),采蜜蜂的数量(Ne),跟随蜂的数量(No),解的个数(Ns),极限值(limit),最大循环次数(MCN)及D维的初始解zi(i=1,2,,Ns).其中,Nc、Ne、No、Ns满足
Nc=2Ns=Ne+No,Ne=No
.
D维解向量zi表示高斯核函数的两个参数,初始解是随机产生的(-1,1)上的值.
3)按照
(4)
计算各解的适应度,式中:MSEi为第i个解的网络均方误差.
4)采蜜蜂根据当前的记忆解搜索新的解.
Vij=zij+rand(-1,1)(zij-zkj),
(5)
式中:i是解的编号;j∈{1,2,,D},k∈{1,2,,Ns}是随机产生的,且i≠k,当新解的适应度大于旧解的适应度时,新的蜜源取代旧的蜜源;相反,旧解在失败次数上加1.
5)跟随蜂选择蜜源的可能值Pi.
(6)
式中:f(zi)是第i个解的适应度值.
6)如果蜜源Xi更新失败的次数超过最大失败次数,那么这个解需舍去,然后再生成一个新的蜜源取代它.
zi=zmin+rand(0,1)(zmax-zmin)
.
(7)
7)当迭代次数大于最大循环次数时,训练结束.
8)将适应度最大的解应用于网络,测试网络性能.
2.4 试验结果与分析
利用MATLAB 2019b仿真平台对ELM和ABC-KELM的性能进行对比测试,检验ABC优化核极限学习机分类的准确性.试验设置ABC算法参数为蜂群200个,最大极限失败次数为50,最大循环次数(MCN)为100.根据2.3中的建模步骤,采蜜蜂和跟随蜂的数量均为100,即Ns=Ne=No=100,以均方误差(MSE)为性能指标,惩罚因子C和核参数γ的搜索范围分别为[10,1 000]和[0.01,1].为了避免样本差异对试验的影响,采用相同训练样本和测试样本作为ELM和ABC-KELM的训练集和测试集.仿真结果见图5、图6,其中:横、纵坐标的数字1至8表示扰动信号的类别,与表2中的扰动信号排序相对应;对角线上的元素表示对应扰动信号的正确分类样本数量和占总测试样本的比(%),非对角线元素表示错误分类的数量和占比(%).由图5、6中可以清楚地了解每类样本的正确分类数量和被误分到其他类别的数量,如由图5第2列可以看出,第2类扰动(电压暂升)正确分类样本数量为47,有3个样本被错误地分类到第1类(正常信号),分类正确率为94%;第2行非对角元素全为0,表示没有样本被误分到第2类扰动.

图5ELM验证集合Fig.5Validation set of ELM图6ABC-KELM验证集合Fig.6Validation set of ABC-KELM
由图5可见:输入相同的样本,采用极限学习机进行分类识别,分类效果比较差的是第4类(电压暂降),50个测试样本只准确识别了11个样本,正确率只有22%.另外,有13个样本被错误分到第1类(标准信号),26个样本被错误分到第3类(电压中断).除此之外,第6类(暂态振荡)分类效果也不好,在50个样本中只有14个被准确识别,正确率不足30%,26个样本被错误分到第1类(标准信号),10个样本被错误分到第5类(谐波),这种分类效果远远达不到工程应用的要求.由图6可见:第4类(电压暂降)正确率为96%,只有2个样本被错误分到第3类(电压中断),第6类则全部识别,而且总的准确率达到了95.5%.
ELM网络和ABC-KELM网络平均分类准确率见表4.由表4可见:人工蜂群算法优化核极限学习机效果很好,其分类识别的正确率提高了20%左右,分类精度得到了很大提高.

表4 ELM和ABC-KELM分类对比Tab.4 Comparison of ELM and ABC-KELM classification
3 结 论
本文采用蜂群算法和核极限学习机相结合,对电能扰动信号进行分类.首先采用db4小波对常见的电能质量扰动信号进行10层分解,用小波系数的平方和表征其能量特征.由于第1层和第10层的能量值接近于0,不适合作为扰动信号的特征向量,故用第2~8层的能量作为扰动信号的特征向量.由于算法固有的局限性(训练计算量大、计算复杂、训练时间长等),使用传统BP前馈神经网络进行分类识别分类效果不尽如人意;而极限学习机的提出虽然解决了网络训练速度慢、计算简单等问题,但分类的准确率达不到要求,需要对网络进行优化.因此,本文采用ABC算法优化核极限学习机,用最优参数下的核极限学习机对扰动信号进行分类识别.经过仿真试验,验证了该方法比传统的极限学习机分类效果有很大提高,具有一定的工程应用价值.
当前,对于电能质量扰动信号分类识别的研究主要从扰动信号特征提取和分类器模型选择两方面入手.除了采用小波变换外,信号的特征提取还可以采用S变换和希尔伯特变换对扰动信号进行分解,然后采用合适的方法提取扰动信号的特征向量.以神经网络为基础的分类器模型,在确定合适的网络结构和参数后,能够得到很好的分类效果.本文用蜂群算法优化核极限学习机的核参数,以网络的均方误差最小为目标函数寻优,得到该目标函数下的最优网络,进行扰动信号的分类识别.由于目标函数的选取决定网络的性能,因此,可以通过改进目标函数来进一步改进网络性能.
