基于聚类和混合采样的软件缺陷预测研究
2022-06-14李英梅
张 彤,李英梅
(哈尔滨师范大学)
0 引言
软件缺陷指的存在于计算机程序或者软件的不能使得程序正常运行的瑕疵.软件缺陷问题不仅会浪费大量的人力、物力和财力,有的情况还会危及到人类的生命安全[1].因此软件缺陷预测问题在软件工程领域上越来越受到人们的关注.
随着软件缺陷预测技术的不断提高,人们发现传统的机器学习能够取得良好的效果是由于正例和反例的数目相差无几,但是在医学诊断[2]、网络诊断[3]、信息安全[4]等方面中表现得不好,这是由于类不平衡所导致的问题.类不平衡指的是训练样本中正例和反例数目相差很大,这将导致的在机器学习中预测的结果更偏向于多数类.经过大量实验证明,软件缺陷当中有缺陷的数据与无缺陷的数据的数目之比符合八二定律[5],这就可能导致最终的结果趋向于无缺陷数据,但是将错误的数据当做正确数据所付出的代价要远远大于把正确数据当做错误数据的代价.通过采样的方法可以将正例和反例数量变为相同,这也就解决了类不平衡问题,极大地提高软件缺陷预测的能力.该文针对类不平衡问题提出MSKsmote算法,经过实验得出该方法相较经典的采样方法有着更好的效果.
1 相关研究工作
根据多数类和少数类两个不同的角度研究,专家们发现了三种采样方法即过采样、欠采样和混合采样方法.过采样的方法主要思想是增加少数类数量直到与多数类数量相同;欠采样方法的主要思想是减少多数类数据的数量直到与少数类数量相同;混合采样方法则同时运用以上两种方法以解决类不平衡问题.
对于欠采样方法,周传华提出一种聚类欠采样的集成算法,该方法通过得出样本簇的中心位置,筛选出信息特征强的多数类样本,再将该训练集放入引入代价敏感的集成算法[6].陆鹏程提出一种聚类欠采样的方法,将多数类进行聚类之后有放回选出N个多数类子集与N个少数类子集组成N个新的训练集,再将N 个训练集训练成N个分类器[7].张肖提出一种半监督集成学习算法Tri_Adaboost,在Tri_training 算法进行预测的时候引入欠采样方法解决类不平衡问题[8].
对于过采样方法,V García 等学者提出随机采样方法(ROS),该算法直接对少数类数据进行复制,以增加少数类数据数量,但是该方法容易造成严重的过拟合[9].NV Chawlat 提出smote 过采样方法,该算法的主要思想是多次在两个少数类数据中加少数类数量以达到平衡[10].Hui提出borderline-smote 算法,该算法将少数类分为三种情况,只对危险点进行过采样从而使少数类样本边界更为清晰[11].杨智明提出一种改进的过采样方法,根据数据的特性自适应采用近邻选择策略,最终在不影响复杂度的情况下有效提高分类器的准确性[12]. He 等学者提出ADASYN 算法,该算法的思想是根据密度分作为标准来自动添加少数类样本的数量,该算法生成的少数类样本有效的缓解了数据重叠现象[13].陈俊丰提出WKMeans-SMOTE方法,通过引进”聚类一致性系数”筛选出边界上的少数样本,对少数样本进行smote过采样以扩充少数类样本数量[14].周建含等人将过采样方法用到半监督中,取得了较好的预测效果[15].
对于混合采样方法,王海等学者在类不平衡方面提出一种混合采样方法,首先采用smote 过采样方法增加缺陷类数量,对无缺陷类样本采用K-modes聚类算法,聚类的簇数等于过采样后的缺陷样本数量[16].吴艺凡等学者利用SVM 算法得到分类超平面,删除远的多数类样本,对边界类样本进行过采样方法[17].戴翔提出一种将混合采样与集成学习相结合的方法,先用smote过采样提高缺陷类样本的数量,用K-means 聚类算法进行欠采样,最后运用集成学习机制,通过投票机制进行模型预测[18].
虽然三种方法都可以缓解类不平衡所带来的问题,但是过采样容易出现过拟合问题,欠采样由于删减多数类数据可能导致重要的信息丢失.因此该文提出了一种结合聚类算法的混合采样算法.
2 算法介绍
该文针对类不平衡的问题提出MSKsmote算法,其中可以主要分为两个部分,第一部分是样本预处理阶段,类似于borderline-smote 算法,判断出危险点,安全点和噪声点,将噪声点去除.第二部分是聚类和混合采样阶段,主要是运用K-means聚类算法,将数据集分为多个簇,然后根据簇中多数类数据和少数类数据的数量分为多数类数据簇和少数类数据簇,去除危险点中是少数类数据簇的多数类数据以及对危险点的少数类数据进行smote 过采样.该算法能够使得边界更为明确,从而有效解决类不平衡的问题.其流程如图1 所示.
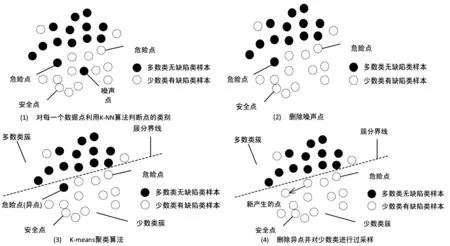
图1 MSKsmote算法流程
2.1 样本预处理阶段
该阶段是在borderline-smote 算法的基础上进行创新,而borderline-smote 算法的主要思想主要是基于smote 算法,因此在介绍该阶段需要介绍smote 过采样算法思想. Smote 算法基于随机过采样算法的一种创新,其基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中(如图2 所示).
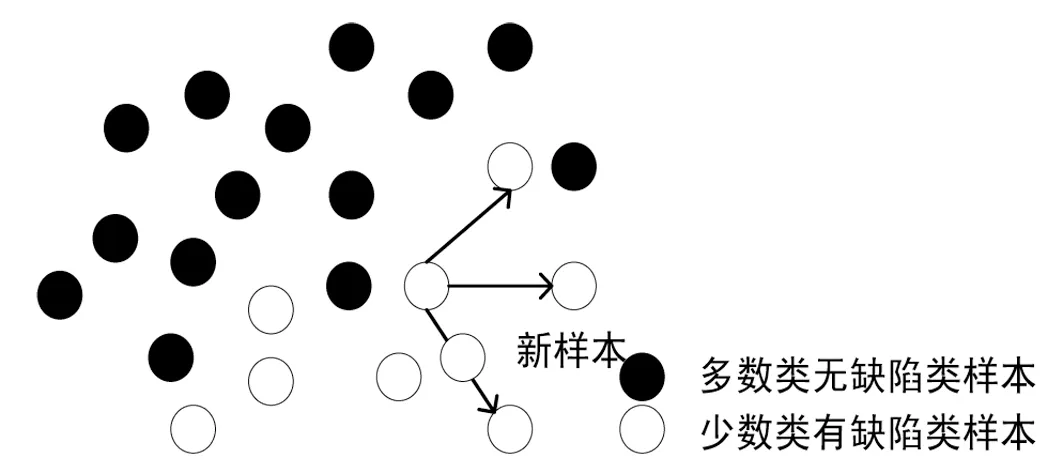
图2 Smote过采样算法思想
该算法的算法流程如下:
输入:T为少数样本数据数量
N为过采样数量
K为最近邻的数量
输出:新的少数类数据
(1)对于缺陷类每一个数据x,用欧式距离计算出它到其它所有有缺类数据的距离.
(2)设计一个采样倍率N(根据有缺陷类和无缺陷类的比例确定),在每一个有缺陷类样本x,用k近邻算法随机选取若干个数据.
(3)对于每一个随机选出的近邻xn,按照公式(1)分别构建新的有缺陷数据.
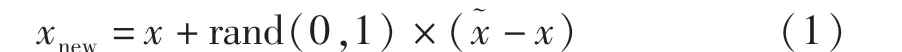
虽然smote能够合成少数类数据样本数量,在一定程度上比随机过采样方法降低了过拟合性,但是容易模糊多数类数据和少数类数据的边缘,使得分类器不能较好的区分边界点的多数类数据和少数类数据.
borderline-smote 算法为了使边界更为清晰,将少数类数据分为三类:安全点,危险点,噪音点.安全点指周围不同类型的数据数量要远远小于同类型的数据数量,噪音点指周围不同类型的数据数量要远远大于同类型的数据数量,危险点指周围既有多数类数据又有少数类数据,但是多数类数据数量要大于少数类数据的数量且仅对危险点进行过smote过采样方法.如图3 所示.
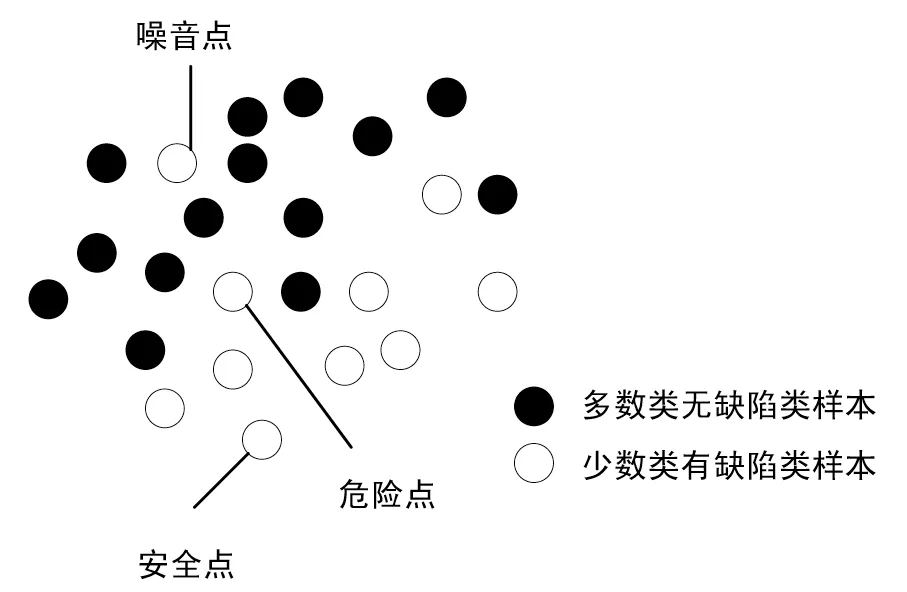
图3 borderline-smote算法
虽然borderline-smote 算法能够使边界更为清晰,但是该算法对于噪音未进行处理,因此该文在采样阶段,为降低噪音带来的干扰,将存在于少数类中的多数类噪音数据进行删除.其次,borderline-smote 只对少数类数据进行过采样,这样容易造成过拟合,于是为了缓解欠拟合问题,该文结合聚类欠采样方法,删除部分为危险点的多数类数据,再对危险点的少数类数据进行扩充.
2.2 K-means聚类算法
聚类算法是一种探索性数据分析技术,其基本的原理是将相似的数据归纳为一组,不相似的数据则为不同组.K-means算法思想是寻找k个质心,经过多次迭代之后,形成k个簇,最终形成的k 个簇之间距离最大,簇间的数据距离最小.该算法的算法流程如下:
输入数据样本集合D:{x1,x2,x3…xn}
输入聚类的簇数:k 输入最大迭代次数:T
(1)在初始的样本集合D中,随机选取k个点作为初始质心{u1,u2,u3…uk}.
(2)重复下面过程直到达到最大迭代次数或者质心不再发生变化为止.
(3){对于每一个数据样本,利用公式(2)计算该点属于何类.

其中ci表示样本数据i与k个簇中距离最近的那个类.uj表示质心j.经过对初始数据的聚类之后,对簇的类型进行判断,当一个簇中少数类数据多于多数类数据的时候称为少数类数据簇,反之称之为多数类数据簇.这一步的主要作用是可以找出簇中的异点(例如多数类簇中的少数数据),因为该点由于与其它点结构相似,但是与多数周围其他点不同,这就会影响模型的最终预测效果.通过聚类算法,可以找出危险点中的异点,随后删除该点并最终对少数类点进行smote过采样方法扩充少数类.
3 实验
该文实验将在AEEEM 数据集,在python的sklearn 工具包的基础上,以贝叶斯分类器作为基分类器,采用十折交叉法,进行100 次的实验,取平均值作为本次实验的最终结果.该文将选取经典的类不平衡算法作为对照实验组.
3.1 数据集
在实验数据方面,该文主要采用的是AEEEM数据集,AEEEM 数据集是开源的数据集,是由D’Ambros[19]等人共同收集整理获得,在软件缺陷预测中具有可靠性.其表的信息见表1.

表1 AEEEM数据信息
3.2 评价指标
该文重点研究软件是否有缺陷,所以该实验被认为是一个二分类问题,一种是有缺陷标记模块(少数类),一种是无缺陷模块(多数类).为了能更好的验证该方法是否比其它经典的类不平衡算法更好,将介绍以下公式.
(1)准确率:又被叫做查准率,真正含有缺陷的模块在所有被预测模型标记为有缺陷模块所占的比例,其定义如式(4).
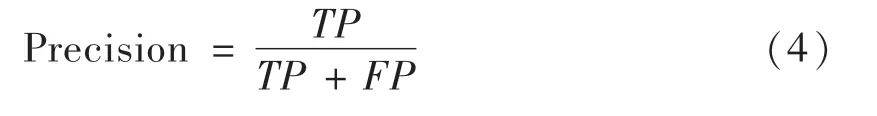
(2)召回率:又被叫做查全率,被预测模型正确标记的但是有缺陷模块在所有真正含有缺陷的模块所占的比例,其定义如式(5).

3.3 实验结果
该文将多个经典的类不平衡算法与MSKsmote算法进行比较,在AEEM 数据集上的各个方法实验结果见表2.其中经典的类不平衡算法包括随机过采样方法(ROS),随机欠采样方法(RUS),Smote过采样方法和ADASYN.
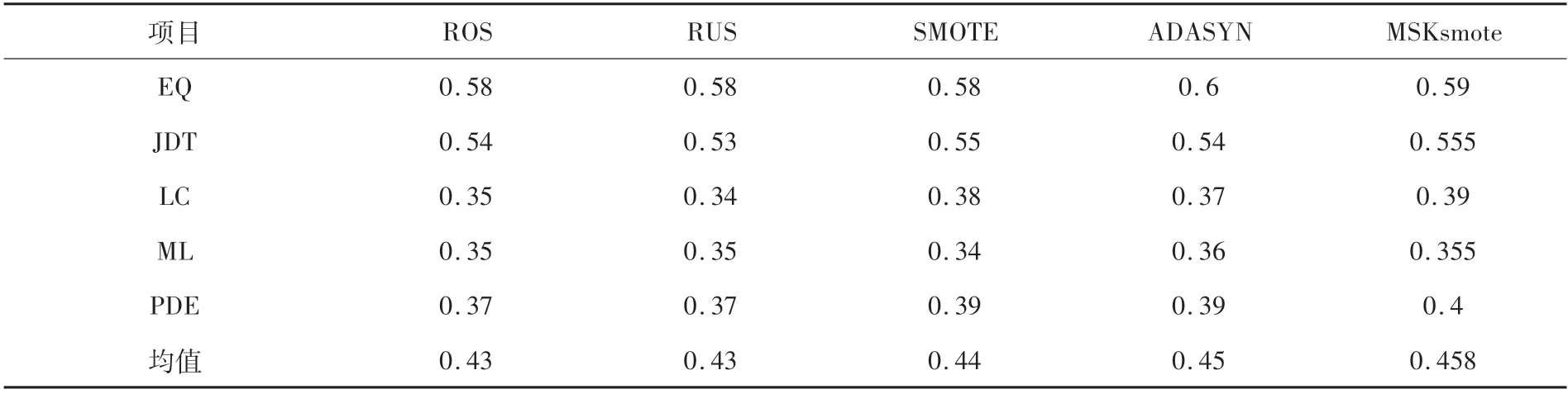
表2 不同类不平衡方法的比较
由表2 可知,在经典的类不平衡算法中,ADASYN算法效果最好.但是MSKsmote 算法在绝大多数的情况中表现最好,并且F1均值最高,因此该文提出的MSKsmote算法较经典的类不平衡算法更为好,这也说明将危险点中的异点清除会提高模型的预测效果.
4 结论
为了解决类不平衡问题,该文为避免过采样的过拟合以及欠采样的欠拟合问题,提出一种混合采样方法,该方法为了使边界更为清晰,将危险点的部分多数类数据删除,然后再对危险点中的少数类数据进行过采样,从而达到数据的平衡. 通过在AEEEM 数据集的实验,证明出MSKsmote算法所表现的效果更为优异.
该文只是考虑了软件缺陷预测中类不平衡方面,下一步将研究能与MSKsmote 算法相匹配的特征选择方法,进一步提高模型的预测效果.
