距离最小化数据驱动计算方法中平衡因子取值影响研究
2022-06-02张玉辉姜清辉
张玉辉,姜清辉
(武汉大学土木建筑工程学院,武汉 430072)
传统弹性力学法求解边值问题建立在联立平衡微分方程、几何方程以及物理方程的基础上。其中平衡微分方程和几何方程由静力学平衡和运动学导出,无不确定性。而物理方程是在对观测数据进行经验总结和拟合的基础上建立的,包括根据实验数据识别现有模型参数,或者拟合提出一种新的材料物理模型,至今依旧是力学研究的热点[1-3],具有经验性和不确定性。
距离最小化数据驱动计算方法是在大数据时代背景下由Kirchdoerfer 和Ortiz[4]首先提出,通过在应力-应变相空间内仿照应变能密度和应变余能密度的形式定义空间距离,在材料的宏观力学响应数据库内为每个积分点搜索并匹配最可能的应力-应变数据点。该方法在计算过程中不再依赖显式表达式形式的材料本构关系,将联立弹性力学三大方程的显式求解问题转变为搜索匹配最可能的静力许可应力场、变形许可应变场和数据分配方案的最优化问题,最大程度上保留了观测数据的原始性。各个搜索对象分别对应平衡微分方程约束下的可行解集、几何方程约束下的可行解集和物理本构关系约束下的可行解子集。
针对数据点的质量,Kirchdoerfer 和Ortiz[5]在原有框架的基础上,提出了熵最小化数据驱动计算方法,降低了数据噪音对计算精度的影响;针对边值问题的类型,该方法的适用范围被陆续推广到动力学问题[6]、非线性弹性问题[7]以及非弹性问题[8]。在理论上,Conti 等[9]论证了该方法在数学层面上的一系列问题,Nguyen 等[10]给出了该方法在变分框架下的一般形式;在应用上,Yang 等[11]和Xu 等[12]将该方法与多尺度有限元法相结合,拓展了求解复合材料等效连续介质问题的新思路,Stainier 等[13]基于数字图像关联技术提出的数据识别方法能够生成更有效的材料数据库;在运行效率上,分层搜索方法[14],k-d 树搜索方法[15]的提出有效降低了计算开销。
对比传统弹性力学法,该计算方法除了以数据库替换本构方程外,同时还要求输入定义空间距离时使用的平衡参数。在一维桁架问题中,表现为一常数因子,记为C,用于平衡应力和应变单位上巨大的量级差;在平面和空间问题中表现为正定的常数矩阵,以保证距离度量始终为正,记为C,在平衡应力应变量纲的基础上为各个方向上的分量也定义了权重。已发表的文献多是针对数据库容量[4-7,11-12]及数据点质量[5]对计算精度和运行效率的影响展开讨论,对于平衡因子取值影响的讨论却很少,或是针对特定的模型和边界条件,仅以计算结果的好坏给出取值建议[7,11-12]。
本文分别对线弹性桁架问题和线弹性平面问题中,平衡因子取值对算式的收敛速率和性能的影响进行了研究。结果表明:尽管平衡因子只是数值而没有物理上的意义,不代表任何的材料力学响应,为保证计算精度,一定程度上仍需要反映材料自身的物理本构关系,这种依赖性将随着数据点密度的上升而降低。
1 距离最小化数据驱动计算方法

上述整形约束二次规划问题采用的求解策略是交替极小化算法。第一个极小化问题的描述为:从满足物理本构关系的应力-应变场出发,找到相距最近的应力可行解和应变可行解;第二个极小化问题的描述为,从满足力系平衡和几何条件的应力-应变可行解出发,找到相距最近的应力-应变数据点。由此形成一个定点迭代过程:

式中:Zj表示第j步迭代中的数据点分配;PM表示子问题一向所有应力-应变可行解的集合(EL/KL)映射;PC表示子问题二向所有数据分配方案的集合(CL)映射。如图1 所示。
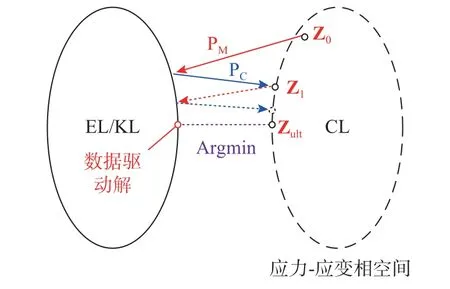
图1 迭代流程Fig. 1 Iterative procedure
算法的目标在于,找到应力-应变相空间内,图1 中两个集合的交集或使二者距离取得最小值时的数据分配Zult。当Zj不再发生变化时,认为迭代收敛,满足平衡和几何约束条件的可行解输出为力学边值问题的近似解。输入不同的迭代初值Z0、距离度量方式以及数据库时,输出的解不一定相同。

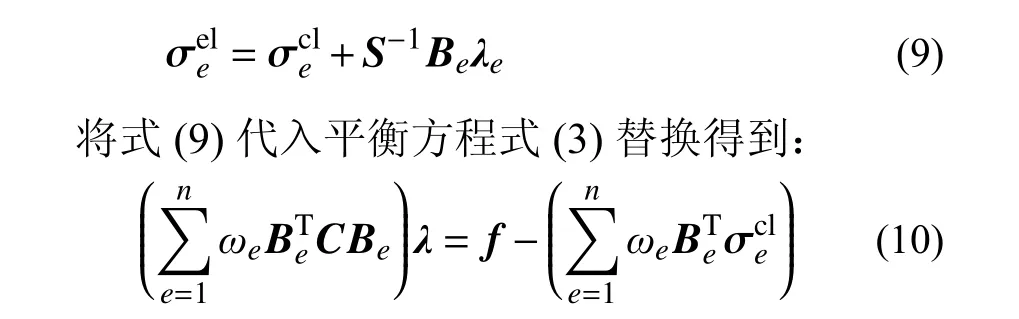
解线性方程式(8)和式(10)可得到节点位移列阵和拉格朗日乘子列阵,代入式(2)和式(9)即可得到应变可行解和应力可行解。
第二个极小化问题中约束条件式(2)、式(3)已满足,只剩约束条件式(4)。有限元格式下,可以将问题分治到各个积分点,每个积分点均匹配最近的材料数据点时,全局罚函数最小,对应的数学模型为:

算法的本质是将碎片化后材料力学响应作为整形约束引入,从而找到满足平衡方程和几何方程,且与整形约束冲突程度最小的近似解。
2 桁架问题中常数C 的影响
文中使用的桁架和平面数据驱动计算程序均基于Visual Studio 19.0 平台C++语言开发。
2.1 松弛问题的收敛速率
对收敛速率展开的分析建立在数据库直接由材料宏观力学特性表征的基础上,即约束条件式(4)中去掉整形约束,数据库替换为材料本构方程曲线:

式中,m=C/E为平衡常数与弹性模量的比例系数。


式(34)和式(35)表明,应力-应变可行解分别以恒定的收敛比线性收敛。以应力作轴,并将应变乘以弹性模量E投影到轴上,如图2 所示。

图2 桁架问题迭代过程Fig. 2 Iterative process of truss problem

当迭代步k趋于无穷时,应力-应变可行解都将收敛于精确解,而参数m只影响二者收敛的快慢。式(36)表明,分配的数据点始终位于该轴上应力和应变可行解之间,并最终恢复为有限元解。边值条件对迭代路径的影响主要体现在对可行解集合的限制,如静定桁架结构的应力可行解始终保持为参考解(存在且只有一个静力许可应力场),在迭代过程中仅应变可行解发生改变。显然,该类问题中平衡常数C的最优取值趋近于0,以加速应变解收敛。
2.2 原始问题的收敛性能
2.1 节中的讨论基于数据点连续无间断的假设,但是在实际情况中,数据点是离散且有限的,迭代过程不可能一直持续下去。该节主要讨论数据库为均匀分布的离散数据点时,平衡常数C对算式收敛性能的影响。恢复整形约束后的数据库集合为:
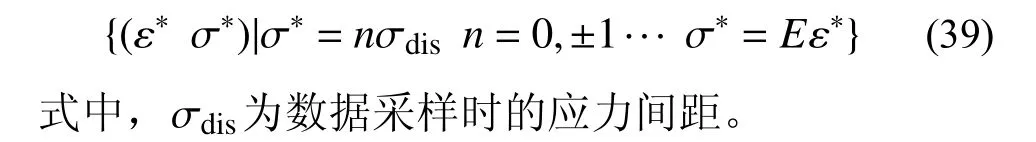
模型选用图3(a)所示的代表性桁架[16],位移约束和边界荷载如图所示,弹性模量E取10 MPa,两杆横截面面积取0.01 m2,荷载大小取3 kN,生成数据点的平均应力间距取10 kPa。平衡常数C取2×107时,对相同的迭代初值,松弛问题和原始问题对应的迭代路径如图3 所示。
对比图3(b)及图3(c),当迭代步数较低时,二者路径基本相同,但是在迭代末期,图3(c)所示迭代过程在远离参考解的位置收敛。这是由于原始问题中数据点作为整形约束,其间距限制了相邻迭代步间数据点所能产生的最小改变量,形成了天然的收敛准则[17]。当自变量的变化不足以克服数据点间距时,算法将过早收敛。
以2.1 节松弛问题中应力-应变可行解的收敛速率联立式(15),应力数据在相邻两次迭代中的改变量计算如下:

2)数据点间距 σdis;给定迭代初值以及平衡常数后,应力-应变可行解将以恒定的收敛比线性收敛。迭代步数越多,收敛解的精度越高,这就要求数据点间距尽可能小。
3)系数m;式(40)表明,m=1 时,数据点的线性收敛比为50%;当m≠1 时,数据点的渐进线性收敛比将与应力-应变可行解中较大的一方相等(如图3(b)中,m=2 时,应力可行解在第4 迭代步时已逼近参考解,此时数据点的收敛比与应变可行解一致)。当收敛阶均为线性时,收敛比越大,收敛速率越慢,相邻迭代步间自变量的变化量越小,越容易满足停步准则,早熟收敛现象愈发显著。
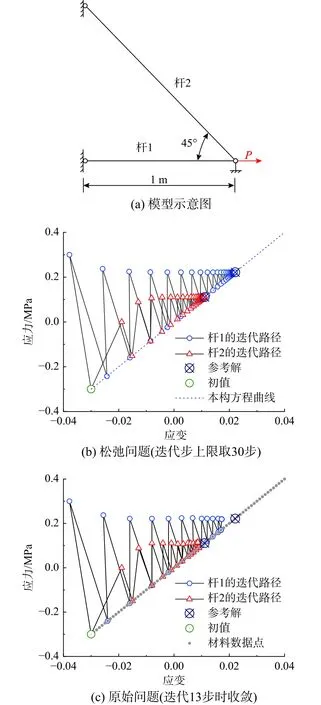
图3 松弛问题和原始问题迭代路径对比Fig. 3 Comparison of iterative paths between relaxation problem and original problem
从计算精度的角度看,当m>1 时,经过充分迭代后,可以忽略应力项将式(42)改写为:
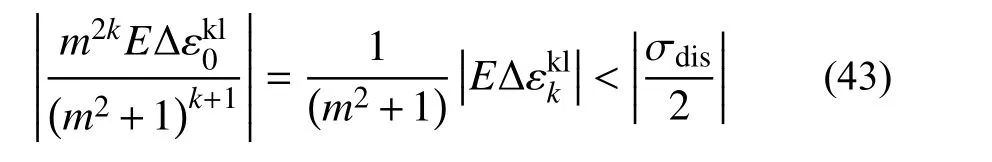
m越大,收敛时应变误差越大;同理m<1 时有:
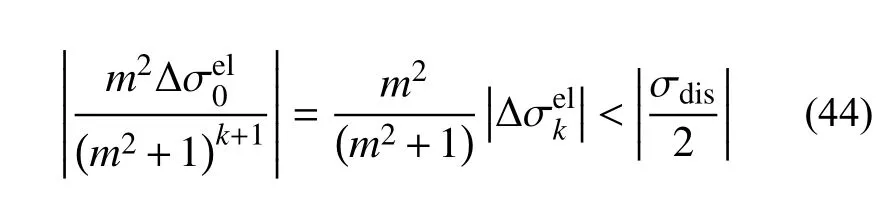
m越小,收敛时应力误差越大;
本节分析表明,数据点的离散性将迭代步数k限制为有限的整数,这就要求C的取值能够在有限的迭代步内,使应力-应变可行解均充分收敛至参考解邻域。当m等于1 时,应力-应变解均以50%的收敛比线性收敛,二者相对精度不易产生较大差异。同时,数据点的渐进线性收敛比最小,迭代早熟收敛的可能性低,收敛解的可靠性高。当然,也可以根据实际工程中位移场和应力场计算精度需求和主要的边界约束类型等灵活取值。
3 平面问题中矩阵C 的影响
对于平面问题,平衡系数从一个增加到九个,若按照对称正定的要求给出系数矩阵C,剩余六个独立参数。
3.1 松弛问题的收敛速率



从3.2 节生成的数据库(数据库A)中随机选取初始数据分配方案Zini,然后,将其固定为每次试验的迭代初值。将D中的每个元素分别乘上0 到2 的随机系数,从而生成50 组满足正定对称约束的系数矩阵C用于试验。为减轻量级变化带来的影响,各矩阵均放缩至与D的二范数相等。图5给出了第5 和第10 迭代步中,势能和余能随r变化的散点图和拟合趋势。
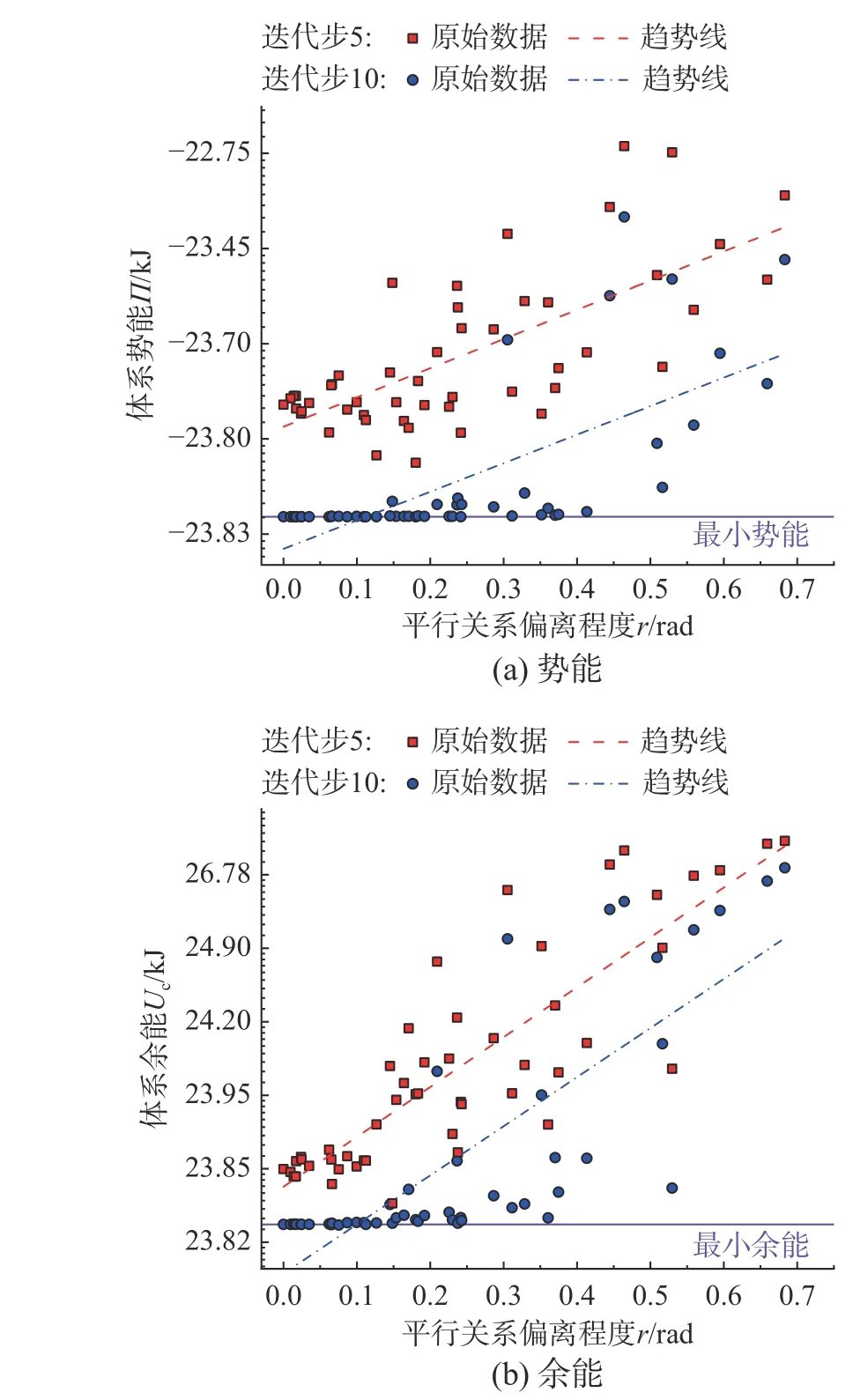
图5 第5 和第10 迭代步的势能和余能Fig. 5 Potential energy and complementary energy for thefifth and tenth iteration steps
从拟合趋势上不难看出,随r上升,势能和余能均呈上升趋势,这意味着算式收敛到精确解将需要更长的迭代步。至此,发现与m对应力-应变可行解收敛速率影响相反所不同的是,随r的增大,以余能和势能度量的应力-应变解整体收敛速率呈下降趋势。
3.2 原始问题的收敛性能
为讨论当数据库为有限的离散数据点时,r对收敛性能的影响,构建了如下数据库:离散数据点在域内均匀分布,应力数据取值的上下限为有限元参考解最大应力水平的1.2 倍。每个独立的应力分量上均匀布置有20 个采样点,正交组合后共生成8000 个数据点。在生成数据库的过程中,应变数据直接由应力数据和给定的材料物理方程获取。生成的数据库记为数据库A,其在应力空间内的投影如图6 所示。
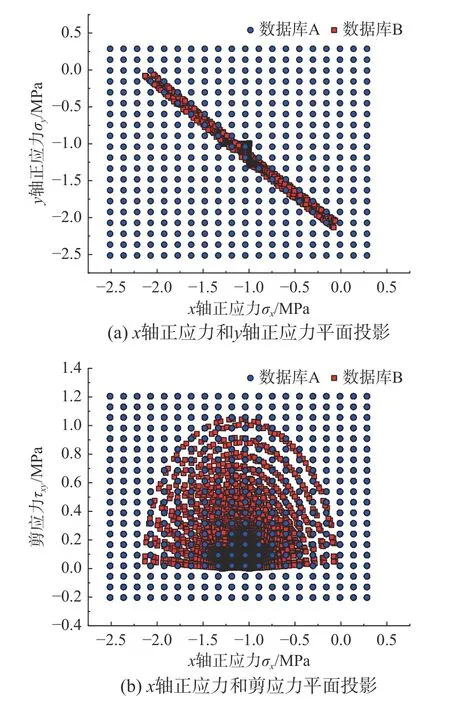
图6 数据库平面投影Fig. 6 Plane projection of database
第一节中指出算法的本质是找到满足平衡方程和几何方程,且与整形约束冲突程度最小的近似解。引入罚函数的数学意义是对数据点整形约束的放松,松弛后将形成以各个数据点为中心的凸包,但整个数据库松弛后仍然是非凸集合。凸包的形态决定了跳出局部最优的难度,尖锐部分越有可能成为局部陷阱,“捕获”迭代过程从而导致算法在局部极小值处收敛,如图7 所示。
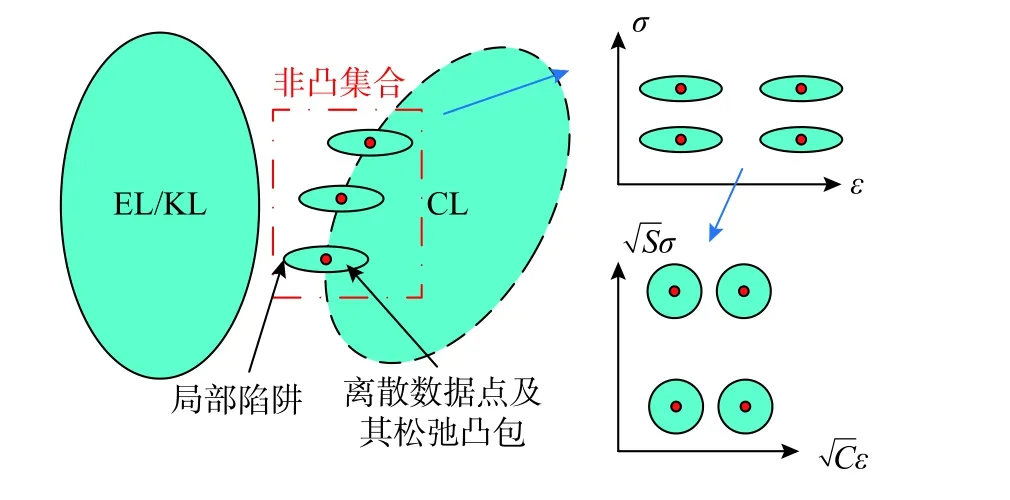
图7 局部陷阱和自定义欧氏空间图示Fig. 7 Visual illustration of local trap and custom Euclidean space


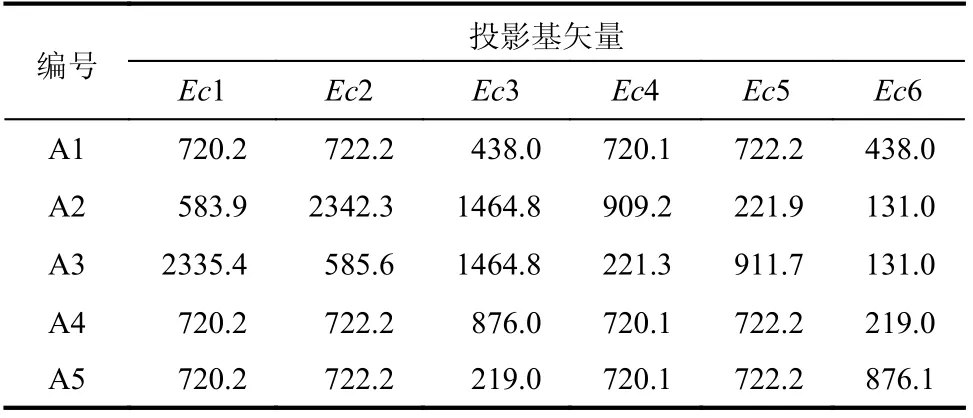
表1 基矢量方向上的方差Table 1 Variance in direction of basis vector
图8 为Zini作为迭代初值时,应力数据的各个独立分量与参考解的偏差绝对值统计直方图。结果表明,方差越大的矢量方向上,收敛点的偏差幅度也越大。原因是方差一定程度上反映了给定数据库在定义的欧氏空间内平均间距的大小,而在平均间距较大的矢量方向上,图7 所展示的局部陷阱问题越严重。A1~A5 中的六个正交基矢量与应力-应变空间内相应分量之间的最大夹角不超过6°,在后续分析中近似为平行处理。
在试验A2 中,数据库A 在Ec2 和Ec3 基矢量方向上的方差最大,反映在计算结果(图8(b)和图8(c))中就是σy和τxy分量的偏差幅度最大;A3 的试验现象与A2 类似;在试验A4 和A5 中,数据库A 分别在Ec3 和Ec6 基矢量方向上的方差最大,但是由于应力-应变数据是共同参与迭代的,因此,τxy分量的偏差幅度均增大。
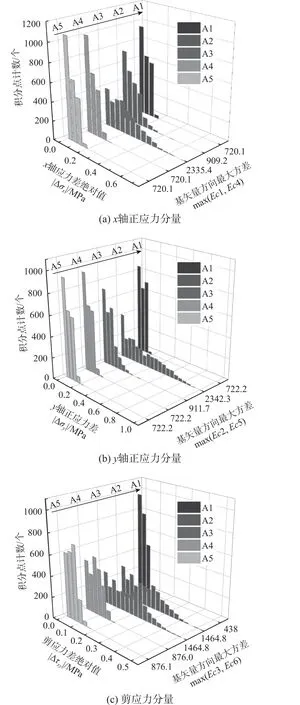
图8 分配的数据点各应力分量与参考解之差Fig. 8 Difference of each stress component between assigned data point and reference solution
图9 为某代表性积分点的应力数据在松弛问题和原始问题内的迭代路径对比。其中标号C11=4C22对应试验A2,标号C11=2C22则是在A2 的基础上降低了r。在松弛问题中,C11=C22对照组仍沿直线路径逼近精确解,各个分量的线性收敛比均为50%。随C11/C22上升,σy和τxy分量收敛到参考解邻域所需迭代步数显著上升。从原始问题的迭代路径观察到,数据点在σx分量上均收敛至参考解邻域,但在σy和τxy分量上,随着C11/C22上升,与参考解的偏差幅度也相应上升。
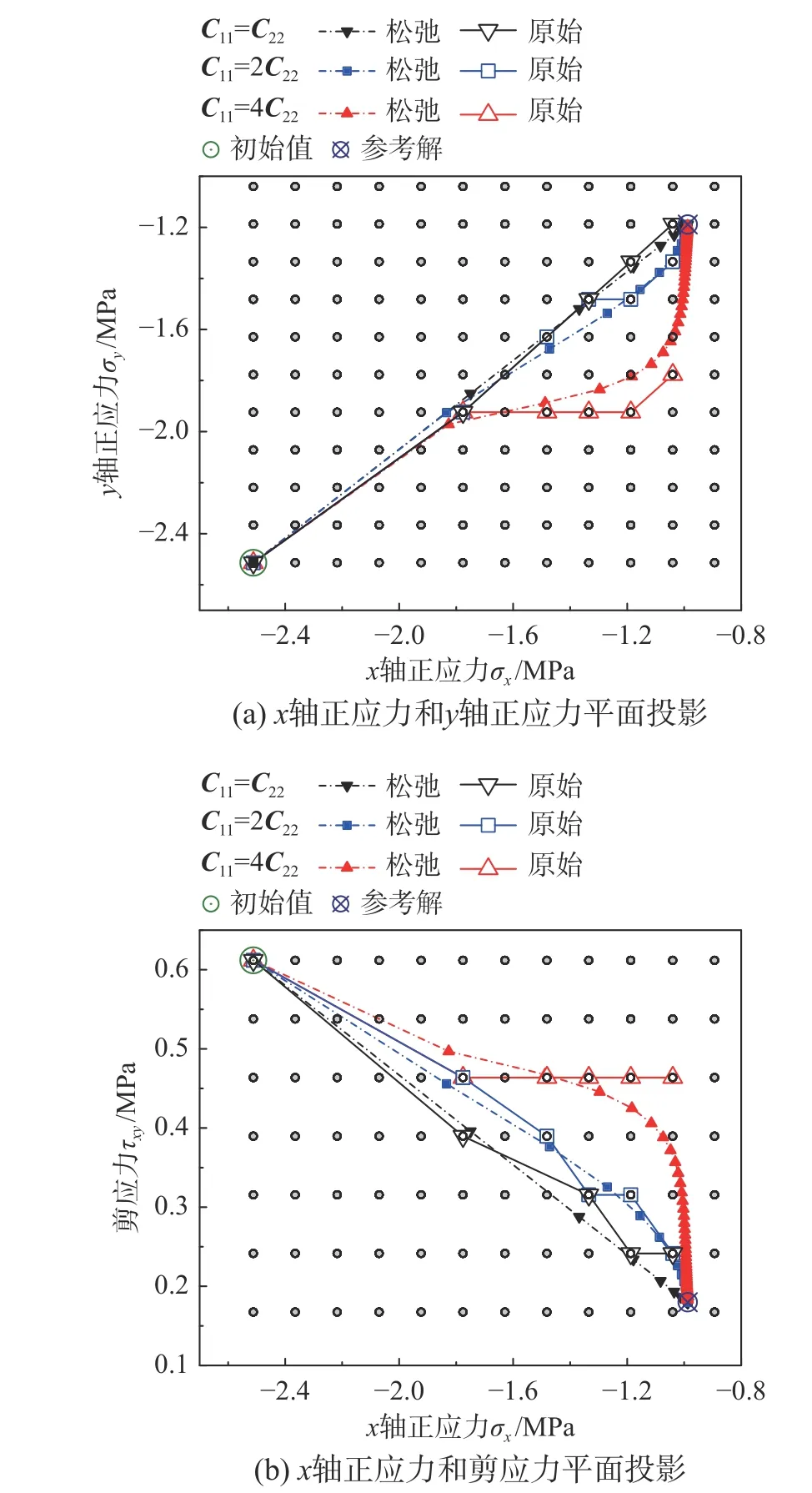
图9 某代表性积分点的应力数据迭代路径Fig. 9 Iterative path of stress data at a representative integral point
为进一步说明早熟收敛性质的影响,由图4 中相同边界条件但网格剖分更精细的有限元模型计算生成了第二个数据库。共包含8044 个数据点,记为数据库B,其在应力空间内的投影见图6。
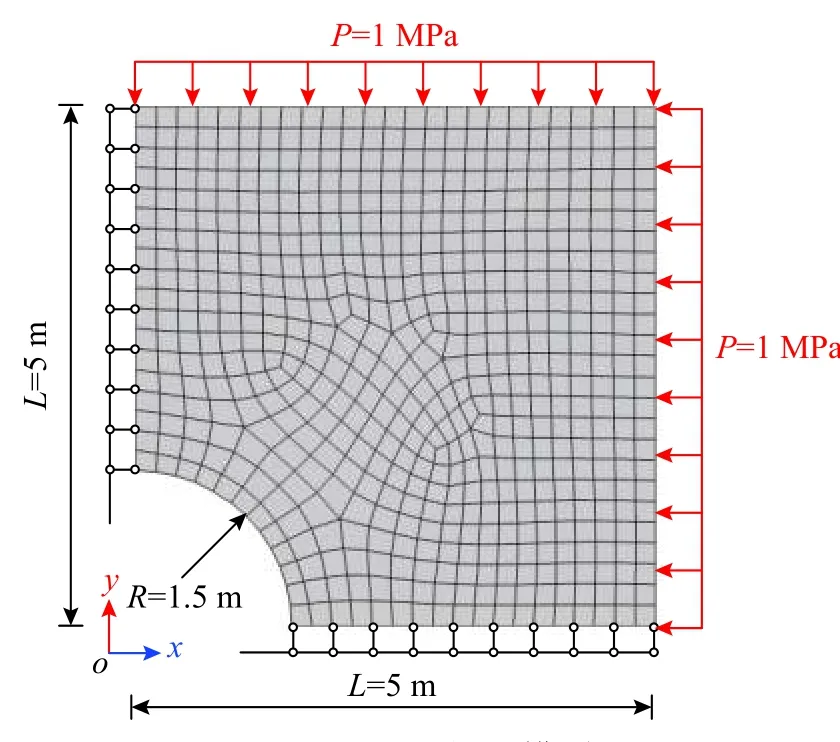
图4 平面问题模型Fig. 4 Model of plane problem
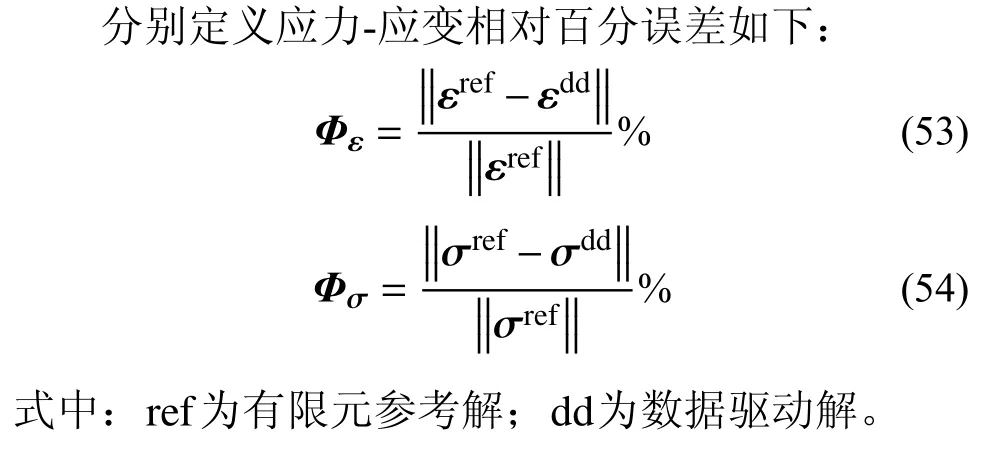
图10 为使用不同数据库驱动仿真计算时,各积分点的应力-应变相对误差统计直方图,计算过程中平衡因子取值均为D。分析表明:精确解附近的数据点密度比数据库容量对算式精度的影响更大。从图10 中可以看出,虽然数据库容量相近,但使用数据库B 的计算误差明显低于数据库A。一方面,由于精确解附近的可行解集合被拓展,可能引入了新的全局最优解;另一方面,停步准则中允许出现更小的改变量,减小了在迭代过程中跳出局部最优的难度。合并两个数据库后,计算误差仍与单独使用数据库B 相近,说明结合松弛问题在迭代末期、参考解邻域内的性质来评价原始问题的收敛性能是有效可行的。
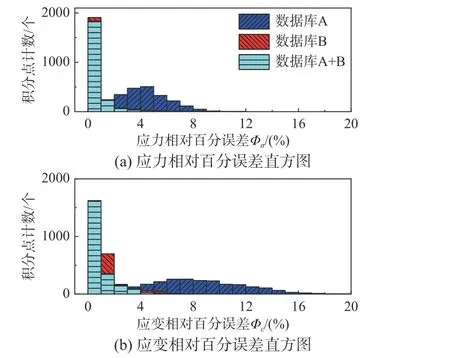
图10 积分点误差统计Fig. 10 Error statistics of integral points
4 结论
在线弹性距离最小化数据驱动算法的框架下,分别以桁架和平面问题为例,讨论了平衡因子取值关于弹性常数的量级m和平行关系偏离程度r对算法的收敛速率及收敛性能的影响:
(1)在去掉整形约束的松弛问题中,对于给定的m,应力可行解和应变可行解分别以1/(1+m2)和m2/(1+m2)的收敛比线性收敛,并在迭代终止时作为近似解输出。m越大于1,应力解的相对精度更高,m越小于1,应变解的相对精度更高。随r的增大,以余能和势能度量的应力-应变可行解整体收敛速率均呈下降趋势。
(2)在包含整型约束的原始问题中,迭代路径与松弛问题的主要区别在于:应力-应变数据点在相邻迭代步间的最小改变量受整型约束限制,算法早熟收敛。r为0 时,应力-应变数据点沿直线逼近参考解,m取1 时的渐进线性收敛比最小,为50%;r不为0 时,数据点在各个分量方向上收敛到参考解邻域所需的迭代步长出现较大差异。对于收敛较慢的分量,迭代终止时偏差幅度上升,早熟收敛问题愈发突出。
(3)除了m和r外,边值约束条件的主要类型、随机初值的选取、数据点间距也是影响算法收敛性能的因素。其中,精确解附近的数据点密度能够很好解决数据点间距和平衡因子取值带来的早熟收敛问题,从而保障算法的计算精度。
