基于随机距离预测的高铁客流需求研究
2022-05-30纪宇宣蒋秋华朱颖婷
纪宇宣,蒋秋华,朱颖婷
(1.中国铁道科学研究院研究生部,北京 100081;2.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;3.北京经纬信息技术有限公司,北京 100081)
0 引 言
高铁线路增加,铁路网规模扩大改变了原有路网的结构,拓展了大量新增客起讫点(Origin-Destination,OD)。了解不同OD之间旅客的真实需求量,挖掘热门OD需求,分析城市之间客流出行的特征和规律一直是铁路部门致力研究的重点内容之一。
近年来,一些学者已经开展了对不同交通方式下OD客流分析的研究。文献[1]通过对沪宁沿线高铁站点进行客流行为特征分析,建立了上下净客流量模型,并分析了站点与客流量对周边的影响和站点及中心城区的关系;文献[2]利用层次聚类法对高速铁路OD客流进行分类,构建了OD服务水平的量化指标体系;文献[3]对空铁联运OD进行分类,根据客流数据建立了Logit模型,并给出空铁联运的服务特性指标取值方法;文献[4]以单日OD概率矩阵为样本,利用系统聚类和快速聚类法,将工作日划分为五类,为行车计划提供决策支持;文献[5]针对铁路OD客流受季节性因素影响的问题,提出了一种同时考虑周和月的季节指数计算方法,该方法为铁路客运量预测提供了重要的理论依据。目前主要是针对OD的客流影响因素进行研究,而对于热门OD客流特征的研究较少,并且目前的研究多数是以实际客运量或订单量进行分析,在一定程度上存在着局限性,难以准确反映旅客的实际需求。而余票查询[6]服务是旅客使用互联网售票系统完成车票预订、改签的前置业务环节,由铁路客运官方服务平台12306提供,可以反映乘客对线路的需求程度。
此外,针对余票查询服务的特征较多,如何抽取更有效的特征集合是亟需解决的问题。使用聚类算法[7]在处理高维数据时鲁棒性较差,需要使用降维技术进行特征重构。文献[8]针对交通客流路线设计问题使用了PCA K-means算法对交通路口数据进行聚类挖掘,然而使用PCA算法不能较好地保留样本之间的距离信息。因此,为了尽可能真实地贴近旅客出行需求,该文准确地分析不同类别OD客流的特征,提出一种基于随机距离预测的OD客流特征分析方法。以挖掘热门OD的特征为目标,运用一种基于随机距离预测(RDP)原理的神经网络对原始数据进行特征重构,而后采用K-means算法对重构特征进行聚类,并对聚类结果进行特征挖掘。
1 OD客流特征分析模型构建
1.1 OD余票查询数据提取
京沪高速铁路是中国运量最大、运输最繁忙的高铁,线路纵贯京、津、沪三大直辖市和冀、鲁、皖、苏四省,具有良好的客流基础。全线共设24个车站,其中始发站有五个,分别为北京、天津、济南、南京、上海,其余均为中间站。截至2019年9月,累计发送旅客10.85亿人次。京沪高速铁路具有需求量大、旅客多、车次多、途径热门城市多、路网地位重要等特点,因此该文以京沪高速铁路为例进行热门OD挖掘。
1.2 数据预分类
旅客需求在普通日期和假期往往差距很大,图1给出了普通日期一周和五一假期前后两天的余票查询数据,以天为统计单位。
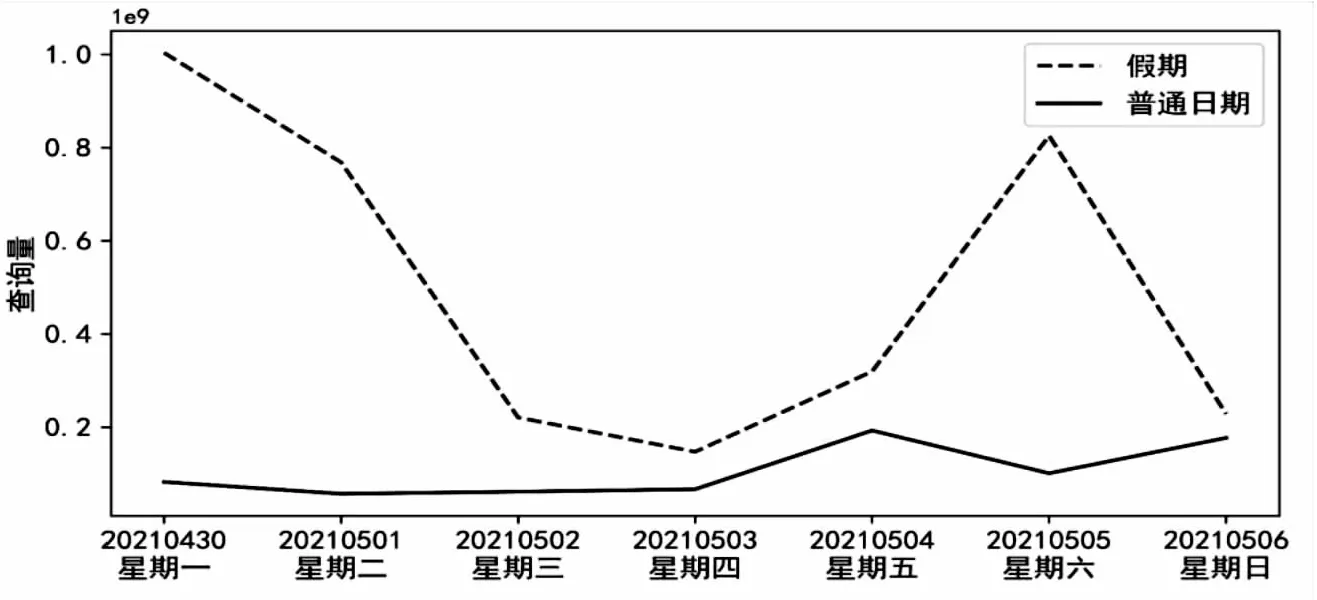
图1 每日查询量分布图
从图1可以看出,假期和普通日期余票查询量走势不同,假期的每日查询量波动较大,普通日期相对平缓。普通日期查询量在星期五和星期日达到高峰,点击量在2×108左右,其他日期相对稳定,其点击量基本为高峰期的1/2左右。假期余票查询量高峰集中在假期前一天、假期第一天和假期最后一天,并且节假日的余票查询量显著高于普通日期查询量,从两者高峰期的数据来看,假期是普通日期的4~5倍。由此可见,应将旅客乘车日期按照假期和普通日期进行分类,对两类数据分别进行聚类分析,并根据聚类分析结果分别表征不同乘车日期的OD客流特征。
1.3 聚类方法
1.3.1 原始聚类特征构建
12306客票系统在给旅客带来便利的同时,也给第三方抢票软件等互联网黑商企业带来商机。抢票软件[9]通过不断访问余票查询接口来刷票,导致部分用户名或ip在短时间内访问不同的OD,生成了大量余票查询日志。因此单独通过查询量分析OD客流特征并不准确。需综合考虑多种特征指标进行聚类分析从而划分热门OD。结合OD余票查询日志数据和业务特点,选择点击次数、用户名数、空用户名数和ip数四类作为特征因素,其含义如表1所示。

表1 余票查询特征因素
一般情况下,铁路车票预售期为15天,在预售期内,不同OD的特征因素分布不同,图2给出了不同OD预售期查询量占比分布图。从图中可以看出,不同OD在预售期内的需求量差异较大,如OD1主要在预售期后3天时查询量达到高峰,而OD2在预售期前3天的查询量占比较高,可见,在分析OD客流特征时,预售期特征因素不可忽略。

图2 不同OD预售期查询量分布图
结合上述分析,将预售期每天点击次数、用户名数、空用户名数和ip数作为聚类分析的原始特征。
1.3.2 特征预处理
在构建原始特征之后,需先对数据进行标准化预处理[10],原始特征中的点击次数、用户名数、空用户名数和ip数等特征因素处于不的数量级,如果直接使用原始特征进行聚类分析,就会突出数量级大的特征在聚类分析中的作用,削弱数量级小的特征在聚类分析中的作用。因此,选取特征归一化方法来对原始数据进行预处理,使不同量级的特征处于同一数值量级,并加快算法的收敛速度,其公式如下所示:
(1)
1.3.3 聚类分析流程
归一化预处理后,使用RDP算法将数据的高层特征提取出来输入到K-means算法中进行聚类,并对聚类结果进行评估,最后根据OD数据的聚类结果进行统计分析从而得到OD数据的客流特征。聚类分析流程如图3所示。

图3 聚类分析流程
1.3.4 RDP K-means算法
(1)随机距离预测模型RDP。
随机距离预测(RDP)模型于2020年由Wang等人[11]提出。该模型是通过训练神经网络逐步逼近目标映射的方式来学习数据的底层结构,从而获取数据的重构特征,是目前较新的一种数据特征重构的方法。这种方法可以在保留原始数据之间距离信息的同时,降低数据的维度,获得数据的高层特征表示。
该文参考RDP模型,构建高速铁路余票查询量的神经网络模型,其模型架构如图4所示。

图4 RDP模型架构
其中,RTargetNet为目标映射网络,由一个简单的全连接层表示;RNet为学习网络,由两个全连接层和中间的Dropout层构成。
OD客流特征数据训练过程如下:将两个归一化后的OD特征xi和xj输入到目标网络RTargetNet得到高层的重构特征η(xi)和η(xj),再将xi和xj输入到学习网络RNet,得到与目标网络输出维度相同的两个特征φ(xi;θ)和φ(xj;θ),分别计算两类重构特征的内积为η(xi)·η(xj)和φ(xi;θ)·φ(xj;θ),将内积差的平方作为RDP模型的训练损失函数,如公式(2)所示,通过学习网络逐渐逼近目标网络,使学习网络获得目标网络的映射关系。
Lrdp=(η(xi)·η(xj)-φ(xi;θ)·φ(xj;θ))2(2)
此外,为了更好地保留OD数据的全局特征信息,引入自编码器作为模型的辅助训练,自编码器的损失函数计算公式为:
Laux=(X-φ'(φ(X;θ);θ'))2
(3)
模型最终训练的损失函数计算公式为:

η(xj))2+(X-φ'(φ(X;θ);θ'))2
(4)
通过不断降低损失函数完成对RNet模型的训练,最终RNet的输出结果即为RDP模型输出的重构特征。
(2)K-means算法。
将获得的重构特征输入K-means算法进行聚类分析,选择合适的K值为各OD数据打上类别标签,即将各OD数据划分为相应的类别。
2 实 验
2.1 实验环境与数据
数据分析及算法软件环境为Python3.7,深度学习框架应用Pytorch1.8.1。数据源于铁路12306客票系统大数据集群,运用spark-sql脚本分别抽取京沪高速铁路普通日期一周(星期一-星期日)和五一高峰期(2021.4.30-2021.5.6)的余票查询日志数据作为OD客流特征分析的基础数据。
2.2 RDP模型参数选取
以普通日期数据为例,原始数据集经特征归一化处理后输入RDP模型。RDP模型的输入与OD原始数据集的特征维度相同,输出维度主要通过训练时的损失函数曲线和聚类结果进行选取,不同数据输出维度不同,普通日期选取输出特征为7。优化方式使用随机梯度下降算法,学习率设置为0.01,Dropout值设置为0.03,用以防止模型过拟合。数据集的总训练轮次(total_epoch)设置为500,每个轮次将数据随机分为15个批次(epoch_batch),每个批次训练200条OD数据(batch_size)。
2.3 K-means参数选取
将RDP模型训练后的特征输入到K-means算法中,分别设置不同的K值,并计算出簇内误方差(SSE)值后绘制曲线(如图5所示),依据手肘法[12]选取K=6作为簇个数。

图5 SSE曲线
2.4 聚类方法评估
评判聚类算法的性能主要通过聚类算法的评价指标进行评判。聚类评价指标[13]主要分为内部评价指标和外部评价指标,其中外部评价指标需要使用已知真实标签数据和聚类结果进行对比从而评判模型;而内部评价指标则通过数据集自身属性特征进行评判,如簇间平均相似度或簇内平均相似度。该文数据未涉及真实标签,适用于内部评价指标进行评价。论文选取Calinski-Harabasz(CH)指标、轮廓系数(Silhouette Coefficient)和戴维森堡丁指数(Davies-Bouldin Index)这三种内部评价指标来评判聚类结果。
其中CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心与数据集中心点距离平方和来度量数据集的分离度,CH指标越大则代表类自身越紧密,类间越分散,聚类效果越好。
轮廓系数分别通过计算样本到簇内其他样本的平均距离和样本到其他簇所有样本的平均距离来评判簇内相似度和簇间分离度。轮廓系数越大表示簇内样本紧凑、簇间距离大,聚类效果越好。
DB指标用类内样本点到其聚类中心的距离估计类内紧致性,用聚类中心之间的距离表示类间分离性。DB指标越小,聚类效果越好。
依据上述三种指标,分别对RDP K-means、PCA K-means、K-means、层次聚类[14]、密度聚类DBSCAN[15]等几种算法进行评判,每个算法重复计算10次取评价指标均值,其中模型输出类簇均相同,PCA输出维度与RDP输出维度相同,评估结果见表2。

表2 各方法聚类结果对比
从表2可以看出,RDP K-means算法的CH指标和轮廓系数均为最大且DB指标最小;相比于层次聚类算法和密度聚类算法,K-means算法的评价指标更好,证明K-means算法更适合余票查询数据;从降维后的聚类效果来看,RDP K-means>PCA K-means>K-means,表明数据经过特征降维后,聚类的效果是最好的,所以在做热门车次挖掘时采用该算法首先进行OD类别划分。
2.5 聚类结果挖掘
选用RDP K-means聚类方法分别对普通日期和假期的高速铁路余票查询量进行聚类,并对聚类结果进行相关特征分析,特征参数包括:OD城市中间站占比、客流距离、出行日期查询量分布、预售期内查询量分布和总体查询量等特征。以普通日期总体查询量为例,分别统计各簇类中不同OD查询量的出现频次,其分布情况如图6所示。

图6 各簇类OD查询流量分布图
从图6可以看出,各簇类查询量差异显著,其中第2类OD查询量分布在20万以内,该类别查询量最少,为冷门OD类别;第3类OD查询量分布在400万~1 000万,OD数量稀少,但查询量最高,为热门OD类别。
根据上述分析方式分别对普通日期和假期各个簇类OD的查询量、中间站占比、乘车日期、预售期流量占比和客流距离等特征进行分析,可得出京沪高速铁路OD客流特征,见表3和表4。

表3 普通日期各类别特征

表4 假期各类别特征
其中表3和表4各参数含义如下:
a:该类别的出发城市是中间站的OD数量占比。
b:该类别的到达城市是中间站的OD数量占比。
c:普通日期代表该类别乘车日期是星期五和星期日的OD数量占比;假期代表该类别乘车日期是假期第一天和假期最后一天的OD数量占比。
d:该类别预售期15天内查询量高峰日。
e:该类别OD客流距离分布范围,单位km。
根据上述获得的OD客流特征可得出以下结论及相应的建议:
(1)非节假日热门OD乘车日期主要集中于星期五和星期日,这类客流特点主要体现了跨城上班、周末往返的旅客需求,该结果可为推荐12306计次定期票业务提供数据依据。
(2)热门OD中始发站需求高,符合铁路旅客的出行规律。然而部分中间站的需求也相对较大,在节假日车次供不应求时,此类分析结果可为票额预分、增加车次等业务提供参考。
(3)热门OD预售期内查询量在乘车日期前1-2天占比较多。根据此结果,可以为节假日期间铁路售票调系统调节负载能力提供参考依据。
(4)热门OD的客流距离相对较短,可在节假日期间增加相应OD的出行车次,从而进一步满足旅客的出行需求。
3 结束语
针对OD客流分析问题中历史客运量与客运需求存在差距,聚类算法处理高维数据时鲁棒性较差等问题,以余票查询数据为基础,提出了一种基于随机距离预测的高层特征抽取模型RDP与K-means结合的OD客流聚类分析方法。以挖掘京沪高速铁路热门OD特征为目标,先使用RDP算法提取数据的重构特征,然后使用K-means算法对重构特征进行聚类,结果表明在三种聚类内部评价指标的评判下,RDP K-means算法均优于传统的PCA K-means、K-means、层次聚类、DBSCAN算法,证明了RDP K-means算法对OD客流特征分析问题的有效性,最后挖掘出京沪高速铁路OD客流特征,为相应的业务问题提供一定的参考依据。
基于余票查询角度进行的客流分析研究,较大程度体现了旅客真实购票需求,可为铁路票额预分、优化余票缓存、线路规划等业务提供参考,有助于优化铁路客运运力结构和资源配置。在后续的研究中,还可将余票查询数据与实际订单数据和候补订单数据等结合起来,更加准确地分析旅客需求,进一步提高铁路客运市场竞争力。
