基于局部保序降维的SVDD故障检测方法
2022-05-27谢彦红薛志强
谢彦红,薛志强,李 元
(沈阳化工大学 理学院, 辽宁 沈阳 110142)
现代工业生产过程复杂、规模庞大,在实现高度自动化的同时又要保证控制的安全性、可靠性与准确性,因此对过程的监控以及故障诊断尤为重要.但通常工业过程很难建立准确的过程机理模型,而且不断变化的过程很难应用模型来进行管理,因此,基于历史数据的过程控制与检测方法取得越来越多成果.基于数据驱动的故障诊断方法就是对历史数据进行分析处理,从而在不需知道系统精确解析模型的情况下完成对系统的故障诊断[1].
主元分析(principal component analysis,PCA)是一种基于数据驱动的故障检测方法[2].PCA是通过对过程变量的样本协方差矩阵进行特征值分解,选取前一个最大的特征值所对应的特征向量作为投影方向.将原始数据空间分为正交且互补的主元子空间(principle component subspace,PCS)和残差子空间(residual subspace,RS),PCS包含原始数据的变化信息,RS主要包含了噪声的影响.针对PCS和RS采用Hotelling’sT2和SPE两种统计量来检测故障是否发生变化.PCA 方法解决了线性、单工况的过程故障检测问题,但由于T2和SPE要求数据服从多元高斯分布,对非线性过程数据则不能进行有效检测[3].针对PCA的缺陷,Kim等[4]提出基于核主成分分析(kernel principal component analysis,KPCA)方法,通过将原始空间线性不可分数据投影到高维空间转换为线性可分数据,并且通过原始空间的核运算代替高维空间的点乘运算. 谢等[5]提出自适应递归KPCA方法,解决了KPCA计算复杂的问题.考虑到过程的动态性,Ku等[6]提出了DPCA(dynamic principal component analysis,DPCA)方法.童等[7]考虑到不同测量变量之间的相关性,提出了基于互信息的分散式DPCA故障检测方法.以PCA为基本方法的故障检测策略都对离群值特别敏感,当数据中有离群值出现,PCA寻找的投影方向就会受到影响,从而影响全局建模及检测.
针对离群值影响投影方向的问题,He等[8]提出局部保持投影(locality preserving projection,LPP).LPP通过在拉普拉斯特征映射算法(laplacian embedding,LE)[9]的基础上引入线性变换,解决了LE不能处理“out of sample”,即新数据的问题.作为线性降维方法,LPP与PCA的区别在于降维后最大程度保持了原始数据的局部结构特性,同时最大程度弱化了离群值对寻找投影方向的影响.由于LPP寻找的投影方向为非正交方向,Cai等[10]利用正交基函数提出正交LPP(orthogonal LPP,OLPP).Bao等[11]为了保持数据集局部和全局的信息,提出了稀疏全局局部保持投影(sparse global-local preserving projections,SGLPP),保持了数据集的全局结构和局部结构,并通过稀疏变换向量提取了变量之间的相关性.然而,和PCA方法一样,LPP适用于单模态故障检测,对于多模态结构数据检测能力不足.
Tax等[12-13]首次提出支持向量数据描述(support vector domain description,SVDD)是一种单值分类方法,可以实现对目标样本集建立包含最多样本的最小体积超球面模型,被广泛地应用于故障检测领域.SVDD不仅具有较好的线性数据处理能力,同时具有较好的非线性处理能力.但是SVDD存在计算量较大、训练阶段时间较长的问题.本研究提出LPP-SVDD故障检测方法,采用LPP将原始观测数据集降到低维子空间中,将低维特征空间的数据利用SVDD建立故障检测模型,并确定监控统计量及其控制限.
1 基本方法
1.1 LPP原理介绍
LPP算法是一种线性降维方法,其目的是在降维的同时最大化保留局部近邻信息.
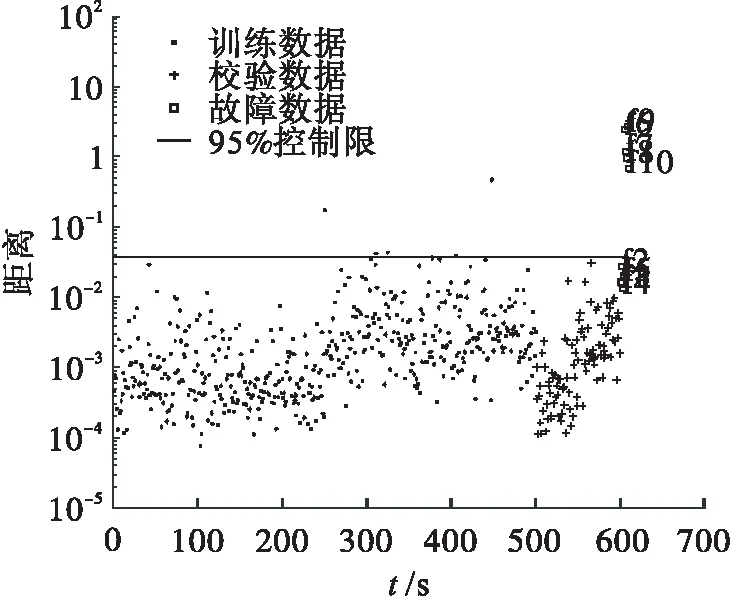
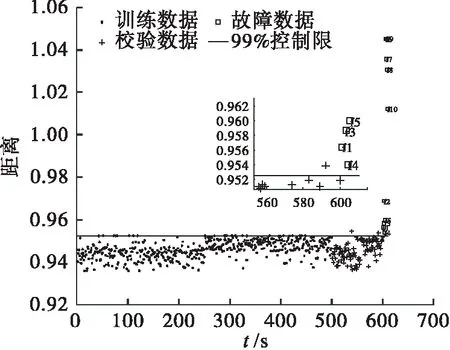
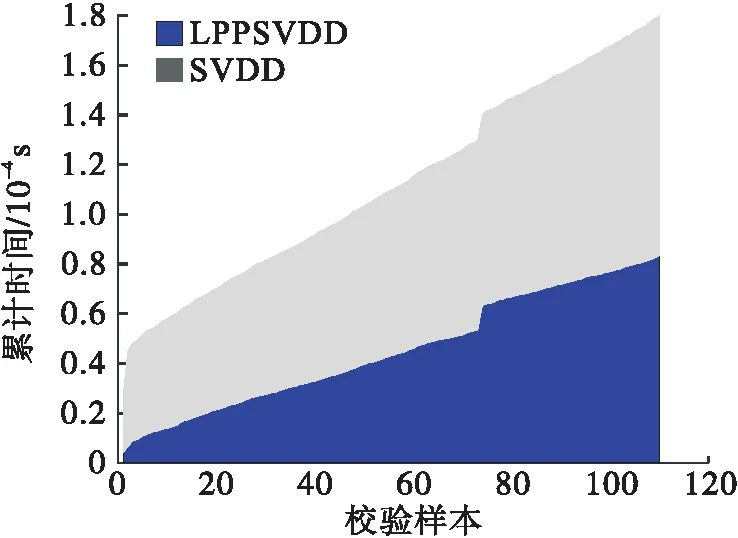
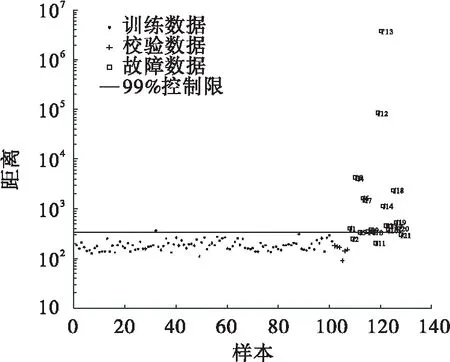
给定数据集X=[x1,x2,…,xm]∈Rn,其中:m为X的样本数;xi为n×1维列向量;n为X的维数,也就是其变量数.LPP算法通过寻找投影矩阵v,使得yi=vTxi.其中:Y=[y1,y2,…,ym]∈Rd;yi是d×1维列向量,d min[∑ij(yi-yj)2]W. (1) 其中:W为权值矩阵,它表示数据集X样本间的关系,其内部元素wij定义为 (2) 其中:xj为xi的k近邻,k为近邻数;t为参数,通常依据数据特征进行调选;wij的含义为当xj在xi的近邻集内时,会对应一个权值wij,如果不在则权值为0.式(1)可转化为 最终的优化目标函数为 (3) 为保证wij存在唯一解,加入约束条件vTXDXTv=1.使目标函数取v的最小值,可转换为求解式(4)的广义特征问题的最小特征值问题. XLXTv=λXDXTv. (4) 其中:λ为特征方程的特征值,将其从小到大排列,取前d个最小特征值对应的特征向量构成投影矩阵vn×d.对于新的数据样本x*,可得投影后的样本y*=vTx*,y*为d×1维列向量. (5) 采用T2统计量监控主元子空间数据变化信息. (6) 其中Λ是X的协方差矩阵.T2的控制限为 (7) 采用SPE统计量监控残差子空间数据变化信息. (8) SPE的控制限为 (9) SVDD方法目标是构建一个超球面.超球面需要满足其体积最小,同时保证包含全部(大多数)数据.构建超球面的目标函数 F(R,a)=R2. (10) 其中:R表示超球面的半径;a表示球心. 当数据中出现偏离的数据时,会导致构建的超球面不能有效地描述数据边界,此时构建的目标函数需要引入松弛向量ξi来调节离散数据对超球面的影响. (11) 其中:C是惩罚系数,它权衡超球面包含数据个数和超球体积的比率关系,通常利用公式(12)[14]计算得到. (12) 其中:d与置信度相对应,选取99%置信度,则d=0.01. 为了保证超球体的体积最小,建立约束条件 (xi-a)T(xi-a)≤R2+ξi. (13) 从而转化为求解最优化问题 利用拉格朗日乘子法求解最优化问题. L(R,a,ξi,α,β)=R2+ s.t.αi≥0,βi≥0. (14) 解(14)式得 (15) 可知球心是所有数据点的线性组合.数据xi都会被分配系数αi,其中非零系数αi对应的数据xα被称为支持向量,超球体的大小、轮廓正是由支持向量决定的.把式(15)带入式(14),拉格朗日函数问题转化为 (16) 通常原始空间数据不会呈球状分布,无法利用一个准确的球面边界来描述数据.因此通过映射将数据投影到高维空间,使高维空间数据呈球状分布,构建包含高维空间数据的超球面,引入核函数代替高维空间数据之间的内积运算.由于高斯核[15]表现出更加稳定的数据描述能力,因此通常选取高斯核函数[16-17]作为映射对应的函数: KG(xi,xj)=exp[-(xi-xj)2/s2]. (17) 其中s为核参数.将式(17)带入式(16),得 (18) 通过计算式(19)得到支持向量xα到球心a的距离 (19) 新的样本到球心的距离 (20) 将Rα设定为控制限,当Dist≤Rα时,可以认为该样本为正常样本,反之,则为异常样本. 支持向量数据描述方在数据维数较大时,建模消耗时间和新样本决策时间均较长[18-20].本研究提出使用LPP进行数据维数约减结合支持向量数据描述的故障检测策略,将此故障检测方法分为两个步骤:第一步,离线建模;第二步,在线检测. 给定Xm×n由m个样本和n个监测变量组成数据集: (1) 对Xm×n利用Z-Score方法进行标准化处理,得到标准化数据集 (21) 其中:μ为1×n维样本均值向量;σ为m×n维的样本标准差对角矩阵.其目的是使数据中心移至坐标原点,并且消除数据不同量纲间的影响. (3) 令数据集Xnew={xi_new},i=1,…,m,利用式(19)计算控制限Rα. (3) 通过式(20)计算新的数据样本到球心的距离Dist,如果Dist≤Rα,可以认为新的数据为正常数据,反之,则该数据为故障数据. 为了可视化,参考文献[21]生成多模态数值例子.生成方式如下:变量x1为多模态结构,其前250个样本服从均值为0、标准差为0.3的正态分布,后250个样本服从均值为15、标准差为1.5的正态分布. 训练样本集Xtraining由变量x1、x2、x3组成,按式(22)共生成500个样本. (22) 其中e为高斯噪声. 测试样本集由校验样本集Y和故障样本集F两部分组成.Y按Xtraining生成方式生成80个样本.F生成方式如下:f1为基变量,其前5个样本服从均值为1.2、标准差为0.2的正态分布,后5个样本服从均值为7.5、标准差为0.6的正态分布.数据散点图如图1所示. 图1 多模态数据散点图 训练数据分为两个疏密程度差异较大的模态,各模态分别有250个样本.校验数据分布相同,每个模态各50个样本.故障样本的前5个样本是靠近密集模态的小尺度故障,后5个样本是位于训练样本两个模态中间的故障. 图2为kNN方法对数据仿真检测图(近邻数选取为3).kNN方法采用的统计量可以反馈数据的多模态特性.从图2可以看出:同时位于模态间的5个故障可以被检测出来,但靠近密集模态的5个小尺度故障却没被检测出来.由于控制限主要被稀疏模态的统计量所决定,密集模态统计量的范围被稀疏模态所湮没,因此故障没有被检测出来. 图2 kNN检测图 图3为降维后样本前三近邻的保序图.由图3可知:通过调整参数使得降维前后同一样本的近邻保序,最终确定LPP的参数k为3、t为0.095.降到二维时,第一近邻的保序率为98.4%,第二近邻的保序率为95.0%,第三近邻的保序率为90.0%. 图3 保序图 图4 和图5 分别是LPP检测图和LPP降维后低维空间散点图.从图4和图5中可以看出LPP降维之后依然保留了数据的多模态结构.由于LPP的统计量要求数据服从多元高斯分布,因此不能有效地检测多模态结构数据. LPP:k=3,t=0.095,PCs=2 图5 LPP降维后低维空间散点图 采用SVDD方法在Xtraining建模后检测测试集Xtest.通过式(12)确定SVDD惩罚因子C为0.2,通过多次实验,得到核参数σ为0.27时,SVDD方法在线检测的结果最稳定,如图6所示. SVDD:C=0.2,σ=0.27 从图6可以看出:相比于kNN,SVDD的优越性在于可将所有故障全部检测出来. 图7为LPPSVDD的检测图,图8为SVDD与LPPSVDD建模累计时间对比图,图9 为SVDD与LPPSVDD检测时间对比图.由图7~图9可知:SVDD存在离线建模和在线检测计算量大、耗时长的问题;LPPSVDD继承了SVDD的检测性能,同时缩减了在线检测的时间,提高了检测的及时率. LPP:k=3,t=0.095,PCs=2;SVDD:C=0.2,σ=0.07 图8 建模累计时间对比图 图9 检测累计时间对比图 本节所应用的半导体数据来源于美国德州仪器公司的半导体生产过程实际数据.半导体工艺过程[22-24]是典型的间歇过程,包含气体流动、压力稳定、等离子点火阶段、AI蚀刻、底层锡和氧化物的过度腐蚀、通风等6个过程.在理想情况下,蚀刻过程是平稳的,即数据各特征的轨迹不会偏移.但反应器内残留物的积累使设备腐蚀老化、上流工序发生变化使材料产生差异、过程监控传感器的监控发生漂移等原因都会使过程数据产生变化. 数据集是典型的三维数据结构,由实验29、实验31、实验33共129生产批次组成,每一生产批次对应不等长的采样时间和相同的21个检测变量,其中变量EndPt A的轨迹图如图10所示. 图10 EndPt A 轨迹图 由于数据缺失,第二个实验的第22正常批次数据只有3个采样时刻,因此该批次不作为监控批次.本节采用统计模量分析方法将半导体数据集进行展开,选取变量数据的均值、方差、偏度、峭度四种模量信息来代替数据信息,针对数据包里的107个批次和21个故障批次进行数据预处理,随机从3个实验中各抽取两个批次作为校验数据.故障类型参见表1. 具体实验过程参考数值仿真实验.图11~图14分别为kNN、LPP、SVDD和LPPSVDD检测图.图15为SVDD、LPPSVDD两种方法检测累计耗时对比图. 表1 故障类型 图11 kNN检测图 LPP:k=3,t=2.5,PCs=30 由图11~图14知:半导体数据分为三个模态,kNN、LPP并未检测出全部故障.SVDD和LPPSVDD两种方法均能检测出半导体过程中的21种故障,但由图15可知SVDD所消耗时间远远多于LPPSVDD. SVDD:C=0.2,σ=9 LPP:k=3,t=1.8,PCs=30;SVDD:C=0.9,σ=2.8 图15 检测累计耗时对比图 传统的SVDD方法拥有较强的数据适应能力和检测能力,但是往往建模阶段计算量大,消耗时间较长.为了保证在不影响SVDD检测能力的前提下,降低检测时间,提高检测的及时性,本研究提出基于LPPSVDD的故障检测方法,通过LPP对数据维数进行约减,降低SVDD计算量,缩减了检测时间,提高故障检测的及时率及准确率.故障诊断与分离将为下一步研究方向.



1.2 SVDD原理介绍


2 故障检测
2.1 离线建模

2.2 在线检测

3 仿真实验
3.1 数值仿真






3.2 半导体工艺实验






4 结 论
