基于平衡度调整策略的Ba-AL主动学习算法
2022-05-27汪婵权悦姚洁张帝李振国李新恒
汪婵 权悦 姚洁 张帝 李振国 李新恒




摘 要:提出一种面向不平衡数据的主动学习算法Balance adjustment Active Learning(简称Ba-AL).每次迭代结束检查训练集样本平衡度,对不平衡训练集进行聚类并剔除冗余样本,保持训练集的平衡,从而提高分类效果.UCI数据集及真实的遥感影像数据集仿真结果表明,该方法可以获得较好的分类效果,达到目标正确率所需的最少训练样本数更少,算法效率更高,数据利用指标更优越.
关键词:主动学习算法;平衡度;分类精度;数据利用
[中图分类号]TP7 [文献标志码]A
分类是从数据中获取有价值信息的重要手段,传统分类器若要获得较好的分类效果需要性能良好的训练样本集,这类训练样本集中的数据通常需要借助于人工从海量的数据中甄别出最有价值的样本.但是在很多的应用场合,如遥感影像分类、诈骗检测等,数据量很大,使得人们从这些海量数据中找到有价值的样本变得很困难,增加了样本标记的成本.Lewis和Gale于1994年提出主动学习方法,为提高监督学习的学习效果和减少训练样本个数开辟了一条新的路径.[1]相对于传统的学习方法,在同样的分类精度要求下,主动学习需要的训练样本数更少,有效的减少了人工标注成本.张良利用主动学习算法对高光谱遥感影像分类问题进行了研究,获得了很好的分类效果.胡小娟将主动学习算法应用于垃圾邮件分类,学习模型可以取得较高的分类精度.Tong[2]将SVM和主动学习算法结合在一起,使得主动学习的性能得到进一步提升.
目前的主动学习算法都是基于训练样本集中样本数量平衡的假设,当训练集中不同类别的数据存在较为严重的失衡时,数据少的类别很容易被错分,即便是基于SVM的主动学习算法也很难获得好的分类效果.不平衡数据分类问题在实际应用中很常见,如海面石油油污检测、信用卡非法交易检测、医学数据分类等.为此,本文提出一种面向不平衡数据的主动学习算法Balance adjustment Active Learning(简称Ba-AL),每次迭代后都会检测样本集的平衡度并对训练样本集进行调整,维持训练样本集的基本平衡,保证学习算法的分类效果.
1 主动学习算法
主动学习包含学习和样本选择两个部分,学习部分负责利用已标记数据集数据训练分类器,样本选择部分负责利用样本选择策略,从未标记数据集中选择候选样本交由专家进行标记,然后加入已标记数据集中.这两个部分相互配合交替工作,直到整个迭代学习过程结束.
样本选择策略的设计是主动学习的关键.在各类样本选择策略中,基于不确定度缩减的选择策略由于度量性好,成为被广泛研究和应用的对象.它是依据分类器的分类结果对每个未标记样本进行度量打分,根据分值从大到小对样本进行排序,样本的分值越大表示该样本包含的有价值信息越多,对寻找最优分类面越有帮助.[3]笔者提出的Ba-AL主动学习算法就是基于不确定度缩减方法进行的研究.
2 不平衡数据分类问题
不平衡数据指的是训练样本集中不同类别的训练样本数量差距较大,类间分布不均匀,某些类的样本数量远远少于其他类.主动学习在每一轮迭代结束后,都会选择一部分有价值的样本交由专家标注后加入训练样本集,若选择的样本集中在某些类别,造成个别类别已标记样本稀缺,这样的迭代过程就会存在训练样本集数据不平衡的问题.为了解决这一问题,提出调整训练样本集平衡度的策略.
3 训练样本集平衡度调整
每一次迭代主动学习选择出的样本都有可能带来训练集数据不平衡问题,造成分类超平面远离某些类别样本的中心,却过于靠近其他类样本中心.为避免主动学習方法在选择含信息量最大样本的同时带来训练样本集不平衡的问题,在每次样本选择结束后度量当前训练样本集的平衡度b,其定义为:
4.2 算法步骤
S是总样本集,其中训练样本集L=(x1,y1),…,(xl,yl),样本均已标记,{y1,…,yl}为对应的标签.U=xl+1,…,xN为标签未知的测试样本集,l和u=n-l分别为样本集L和U中的样本个数.S=L∪U,X={x1,…,xl,xl+1,…,xN}均为υ维向量,Y=y1,…,ym为样本标签的集合.主动学习的目的就是从未标记样本中选出最有利于训练分类器的样本加入训练样本集,从而训练出分类器f以准确地预测未知样本xi的标签yi.每次迭代结束后选出对提高分类器性能最有价值的样本加入样本集M中,W为错误分类的样本集合.算法步骤:
Step1,初始化.对测试样本集U中所有样本做聚类,类别数为k,类别中心样本为c1,…,ck;将c1,…,ck交由专家标记,若c1,…,ck包含所有类别,则令L=c1,…,ck∪L,否则对U进行k+1类.重复这一过程,直到类中心包含所有类别样本.令U=U-C;
Step2,基于样本集L训练SVM分类器,判断U中样本的类别;
Step3,对每个xi(xi∈U),按式(2)计算w(xi).对U中样本按w(xi)的值进行降序排列,排序越靠前的样本价值越高,取前m个样本加入集合M,并将M中的样本交由专家进行标记;
Step4,比较M中样本的标记结果与Step2中对应样本的标签,将分类结果不同的样本放入数据集W;
Step5,按公式(1)计算当前W集对应的b,若b<ε,则对W的平衡度进行调整,调整L中的样本分布;
Step6,令L=L∪W,L=U-W;
Step7,判定此时是否达到停止条件,满足则停止迭代;否则,返回Step2进行下一次迭代.
5 仿真结果与分析
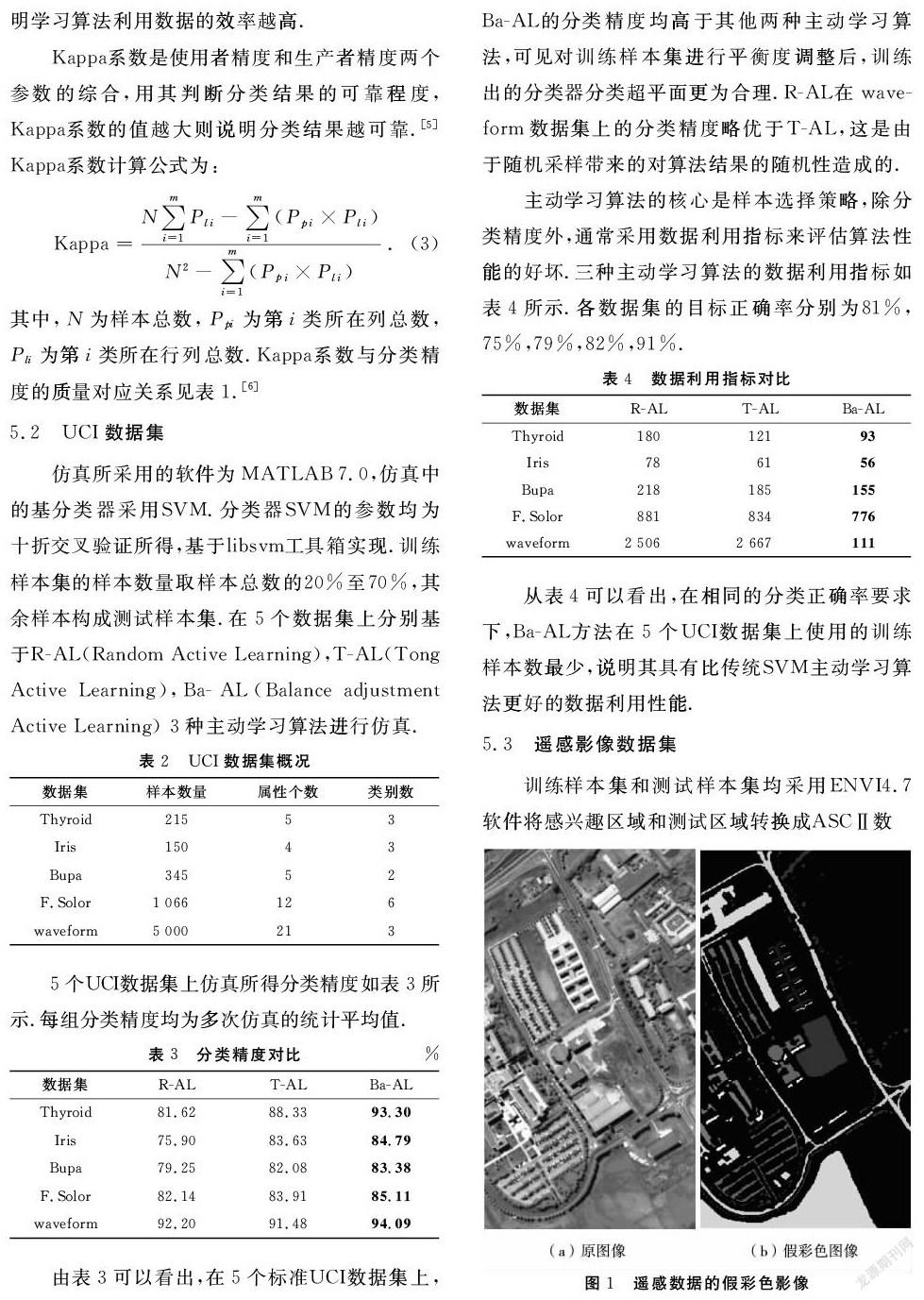
为了验证所提算法性能,基于UCI标准数据集及真实的遥感影像数据集进行仿真分析.数据集基本情况见表2,遥感影像数据集来自文献[4].
5.1 分类结果评估指标
数据利用是指主动学习算法达到目标正确率所需的最少训练样本数.该指标数值越小,说明学习算法利用数据的效率越高.
Kappa系数是使用者精度和生产者精度两个参数的综合,用其判断分类结果的可靠程度,Kappa系数的值越大则说明分类结果越可靠.[5]Kappa系数计算公式为:
Kappa=N∑mi=1Pli-∑mi=1Ppi×PliN2-∑mi=1Ppi×Pli.(3)
其中,N為样本总数,Ppi为第i类所在列总数,Pli为第i类所在行列总数.Kappa系数与分类精度的质量对应关系见表1.[6]
5.2 UCI数据集
仿真所采用的软件为MATLAB7.0,仿真中的基分类器采用SVM.分类器SVM的参数均为十折交叉验证所得,基于libsvm工具箱实现.训练样本集的样本数量取样本总数的20%至70%,其余样本构成测试样本集.在5个数据集上分别基于R-AL(Random Active Learning),T-AL(Tong Active Learning),Ba- AL(Balance adjustment Active Learning) 3种主动学习算法进行仿真.
5个UCI数据集上仿真所得分类精度如表3所示.每组分类精度均为多次仿真的统计平均值.
由表3可以看出,在5个标准UCI数据集上,Ba-AL的分类精度均高于其他两种主动学习算法,可见对训练样本集进行平衡度调整后,训练出的分类器分类超平面更为合理.R-AL在waveform数据集上的分类精度略优于T-AL,这是由于随机采样带来的对算法结果的随机性造成的.
主动学习算法的核心是样本选择策略,除分类精度外,通常采用数据利用指标来评估算法性能的好坏.三种主动学习算法的数据利用指标如表4所示.各数据集的目标正确率分别为81%,75%,79%,82%,91%.
从表4可以看出,在相同的分类正确率要求下,Ba-AL方法在5个UCI数据集上使用的训练样本数最少,说明其具有比传统SVM主动学习算法更好的数据利用性能.
5.3 遥感影像数据集
训练样本集和测试样本集均采用ENVI4.7软件将感兴趣区域和测试区域转换成ASCⅡ数据,训练集具有较好的代表性.仿真过程中,基分类器采用SVM,选用高斯核函数,分类器参数为十折交叉验证所得,基于libsvm工具箱实现,分别采用R-AL(Random Active Learning),T-AL(Tong Active Learning),Ba-AL(Balance adjustment Active Learning)3种主动学习算法进行仿真.每组仿真所得分类精度均为20次仿真结果的平均值,每次仿真时,训练样本集的样本数量在样本总数的1/5到4/5之间取值,剩余样本作为测试样本集.仿真过程中,主动学习迭代次数取100次.
3种主动学习算法的分类精度和数据利用性能指标如表5所示.其中,仿真数据利用性能时的目标正确率为80%.
由表5可以看出,Ba-AL算法的平均分类精度均高于其他两种算法,数据利用指标较前两种算法更好.
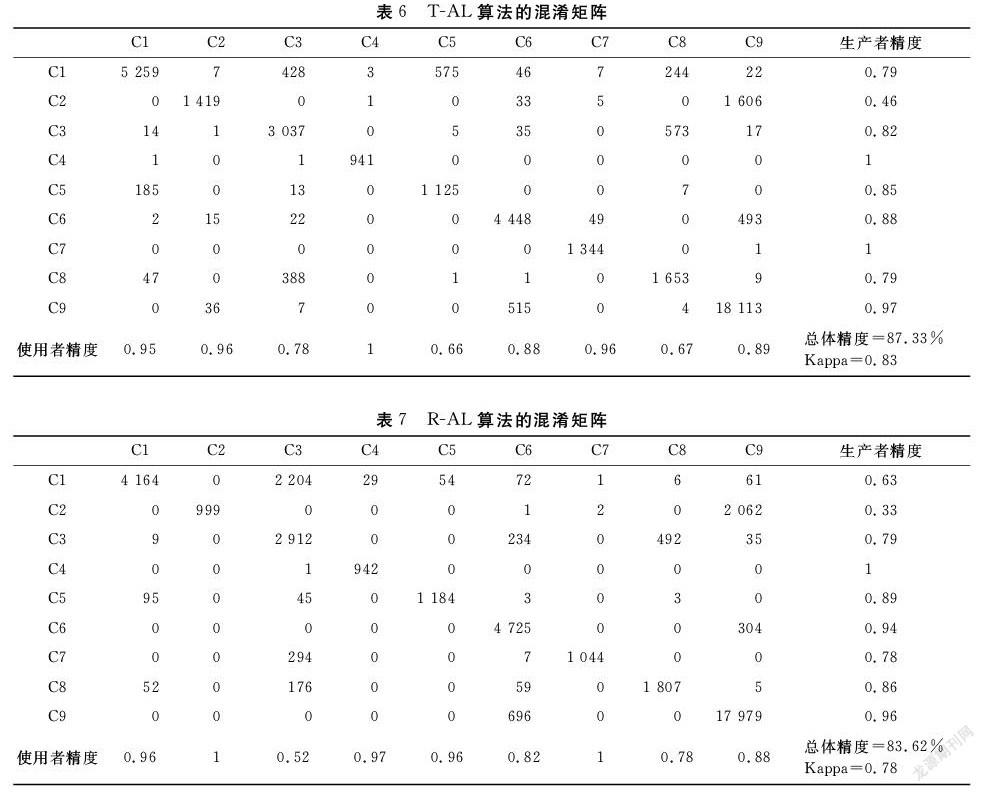
3种主动学习方法的混淆矩阵见表6-8,三种主动学习算法的Kappa系数都较高,对照表1中的Kappa系数分段,说明仿真结果是可靠的.
图2给出了遥感影像分类效果图,与图1(b)中原始的影像分类图对比,可以看出分类难点主要在沙地及草地等地物的混合处.R-AL算法可以大体看出各类地物的情况,但是对草地、裸地等地物分类错误率很高.T-AL算法整体分类效果比T-AL要好,但对于砂砾、草地和阴影区域分类效果较差,对各地物混杂处分类也不准确.采用预聚类的方法对训练样本集进行选择的Ba-AL法对阴影部分的分类效果均优于前两种算法.
6 结语
为解决主动学习算法中存在的各类别数据量不平衡问题,提出对每次迭代后的训练样本集进行平衡度评估,对存在数据量不平衡的训练样本集进行调整,通过删除冗余信息的方式使训练样本集始终保持平衡.UCI数据集及真实的遥感影像分类数据集的仿真结果表明,Ba-AL算法比随机取样主动学习及Tong所提主动学习算法具有更好的分类效果.
参考文献
[1]Lewis D D,Gale W A.A sequential algorithm for training text classifiers[J].Proceedings of the 17th ACM International Conference on Research and Development in Information Retrival,1994:3-12.
[2]Tong S,Koller D.Support vector machine active learning with applications to text classification[J].Journal of Machine Learning Research,2002,2:45-66.
[3]李延超,肖甫,陈志,等.自适应主动半监督学习方法 [J].软件学报,2020,31(12):3808-3822.
[4]苏红军,顾梦宇.高光谱遥感影像优化判别局部对齐特征提取[J].遥感学报,2020,25(05):1055-1070.
[5]Tayebi MH,Tangestani MH,Roosta H.Mapping salt diapirs and salt diapir-affected areas using MLP neural network model and ASTER data[J].International Journal of Digital Earth,2013,6(2):143-157.
[6]卢丽琛, 洪亮. 面向对象的高分辨率遥感影像建筑物变化检测[J].牡丹江师范学院学报;自然科学版,2021(01):50-54.
[7]曹倩倩, 黄袁升.遥感影像分类方法精度研究[J].牡丹江师范学院学报:自然科学版,2017(01):37-38.
编辑:琳莉
