基于改进YOLOv3 和迁移学习的轻量型补片目标检测
2022-05-25颜光前张兆民夏苠芩
范 博,吴 俊**,孙 亮,颜光前,张兆民,王 强,夏苠芩
(1.云南大学 信息学院,云南 昆明 650500;2.昆明医科大学第一附属医院 胃肠与疝外科,云南 昆明 650032;3.昆明医科大学第一附属医院 科教部,云南 昆明 650032)
腹壁疝是腹部手术常见并发症[1],无法自愈只能通过补片植入手术进行治疗[2],中国疝病患者人数每年可达300 万~500 万,75 岁以上老年男性的发病率可高达44%,高于任何一种恶性肿瘤.目前临床上所植入的补片多为重量型补片,复发率高且容易带来慢性疼痛;轻量型补片网孔稀疏,质地轻盈,腹壁顺应性强[3],正逐渐取代传统重量型补片.但作为植入的异物,轻量型补片依旧会产生移位、皱缩,甚至疝复发等一系列并发症[4-5].因此,需要医生对植入补片重新检测与评估,以确定与补片相关的并发症并指导手术与治疗.
传统计算机断层成像(Computer Tomography,CT)、磁共振成像(Magnetic Resonance Imaging,MRI)等三维成像方式存在辐射危害或禁忌症,且无法对轻量型补片成像,手持超声(Hand-held Ultrasound,HHUS)虽然能成像轻量型补片,但效果不佳.这导致术后检测只能进行侵入性的二次探查手术,大大增加了病人的痛苦和费用负担.自动三维乳腺超声(Automated 3D Breast Ultrasound,ABUS)[6]克服传统超声的缺点,不仅成功用于乳腺肿瘤检测,同时对腹壁疝轻量型补片的检查也十分有效.但ABUS 对病例检查后所产生的数据量极为庞大,医生每天需要检测成百上千张的补片成像结果,人工阅片极其耗时费力,且容易出现漏诊或误诊;据统计,医师查阅医学影像产生的误诊率高达10%~30%.
为了减少检查时间并提高准确率,已经提出了几种计算机辅助检测(Computer-aided Diagnosis,CADe)系统来帮助检查和形成对ABUS 图像的更精确的检测和诊断.理论上,应用于ABUS 肿瘤图像检测研究对于补片检测有一定参考价值.Ikedo等[7]开发了一种基于Canny边缘检测器检测边缘的全自动检测方法,利用分水岭变换对定位位置进行检测,生成候选肿瘤区域.Chang 等[8]提出一种用于多通道自动乳腺超声乳房病变检测的CADe系统,先对图像进行预处理,然后采用灰度切片的方法对候选肿瘤进行检测,最后,提取了7 个用于区分肿瘤和非肿瘤的量化特征.Tan 等[9]提出一种多阶段CADe 系统,包括乳房、乳头和胸壁的检测,然后提取体素特征,并使用神经网络分类器集成来区分肿瘤和非肿瘤.Moon 等[10]提出了一种基于多尺度斑点检测的方法,利用模糊、内部回声和形态学特征对斑点进行分类,减少了阳性斑点的数量.Lo 等[11]提出应用分水岭变换得到均匀区域,并利用LR 分类器得到二维和三维纹理、强度和形态学特征估计候选肿瘤的概率.然而,这些方法都存在以下缺点:①候选区域方案都是针对肿瘤图像,对于补片图像检测效果不好;②手工特征的选择需要专门的领域知识,不方便且可能不是最优的;③这些方法在临床试验中的检测率和执行时间都相对不足.
随着深度学习理论的飞速发展,针对上述问题以及ABUS 补片图像特点,本文提出了一种改进的YOLOv3 卷积神经网络检测算法.实现对ABUS 超声中补片的自动检测,利用对补片超声图像进行检测后得到的检测框来获取补片大小、皱缩情况等超声参数,以辅助医生进行补片的术后检查.
1 相关理论
1.1 YOLOv3 神经网络随着卷积神经网络在计算机视觉领域的广泛应用,对卷积神经网络模型检测的精度和速度提出了越来越高的要求.J.Redmon等提出的单阶段目标检测YOLO 系列[12-14],相对于双阶段较慢的检测速度以及难以优化检测策略(如Fast R-CNN[15]、Faster R-CNN[16]),YOLO 算法将目标检测转化为回归问题,可以对图像直接预测得到物体边界位置和分类.YOLOv3 作为YOLO系列的集大成者,其优秀的检测性能及卓越的检测速度,在实际应用得到广泛认可和应用.
图1 为YOLOv3 的网络结构,YOLOv3 的特征提取网络Darknet-53 引入残差模块(Residual Block)借鉴了Resnet[17]的思想,相比YOLO9000 中采用的Darknet-19,可以很好地控制梯度的传播,避免出现梯度消失或者爆炸等不利于训练的情形,使得训练深层网络难度大大减小.同时Darknet-53 用步长为2 的卷积层代替池化层,避免了信息丢失.

图1 YOLOv3 构图结构简图Fig.1 Schematic diagram of YOLOv3 composition structure
YOLOv3 借鉴了FPN[18](Feature Pyramid Networks)的思想,采用多尺度融合的方式预测,通过两次上采样(Up Sampling),得到3 个不同尺度(13×13,26×26,52×52)的特征图(Feature Maps).采用K 均值聚类法[19]对3 种不同尺度的特征图进行聚类,得到9 种先验框,并根据大特征图匹配小尺寸框的原则进行分配.YOLOv3 模型利用线性回归来预测每个先验框的目标分数,模型中的每个先验框对应1 个ground truth 对象.
如图2 预测边界框的中心坐标(bx,by)及宽度bw,高度bh的计算过程为:

图2 先验框与预测边界框Fig.2 Prior box and prediction bounding box

式中,σ是sigmoid 函数,tx、ty为预测的坐标偏移量,tw、th是预测边框的宽高尺寸缩放,cx、cy分别为特征图中grid cell 的左上角坐标,pw、ph分别为预设的anch or box 映射到特征图中的宽和高.
YOLOv3 模型不采用softmax 分类,而是使用单独的Logistic 回归分类器,以确保每个边界框使用多标签分类.在训练过程中,利用二元交叉熵损失(Binary cross entropy)进行类别预测.
1.2 迁移学习迁移学习[20]是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中[21].迁移学习分为基于实例迁移学习、基于特征迁移学习、基于模型迁移学习和基于关系迁移学习4 大类别.传统机器学习在训练一个好的网络模型时需要训练大量数据进行学习,对于一些数据较少的样本往往训练效果不佳.迁移学习能有效解决小样本数据的学习问题,提升卷积神经网络对小样本数据目标分类识别的准确率.
在迁移学习中,被学习的领域称为源域(Source Domain),待解决问题的领域称为目标域(Target Domain),公式如下:

其中,D(s)为源域,D(t)为目标域,xs是源域的特征空间,xt是目标域的特征空间,P(xs)是与xs对应的边际概率分布,P(xt)是与xt对应的边际概率分布.
2 本文算法(YOLOv3-SPP)
2.1 SPP 模块由于轻量型补片相对于周围组织呈等密度,超声图像中轻量型补片受人体组织生长所影响,存在遮挡轻量型补片的情况发生,从而影响检测效果.为了增强这类目标检测效果,本文提出了在YOLOv3 模型的基础上引入空间金字塔池化结构SPP 模块[22].
SPP 模块将从卷积层提取的特征图分别进行大小为13×13,9×9 以及5×5 的固定分块大小的最大池化操作,并在池化操作前对特征提取器的输出进行padding,设置池化步长为1,以保持输入输出的尺寸一致.
如图3,空间金字塔池化结构对3 种不同尺度池化的结果进行了融合(concat)操作,多次最大池化操作在不同尺度上保留相应最显著的特征,并利用拼接特征提取器的输出与空间金字塔池化结构的输出,实现局部特征和全局特征的特征图融合,使更多的特征被捕捉,大大增强了目标的识别精度.
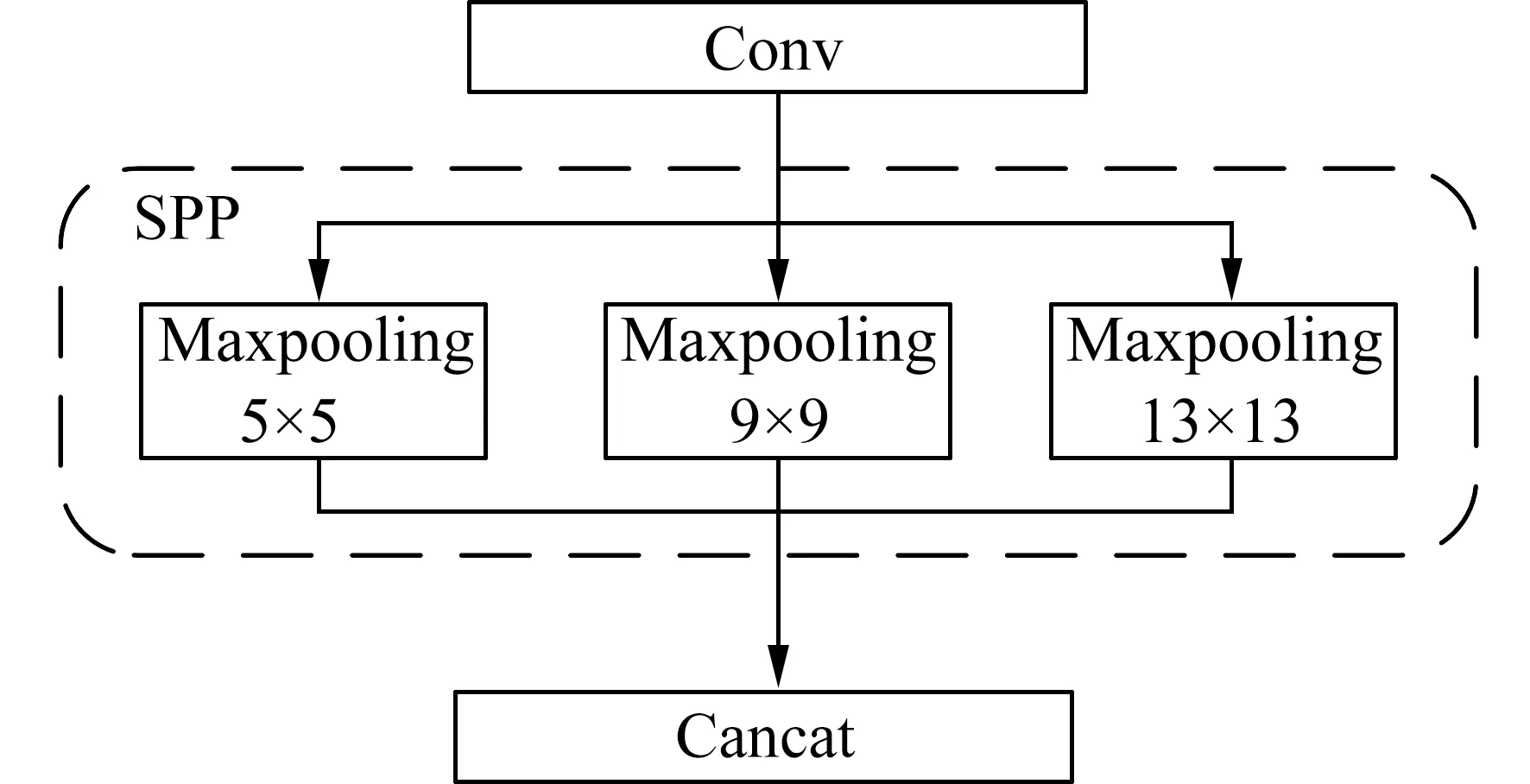
图3 空间金字塔池化结构Fig.3 Spatial Pyramid Pooling structure
2.2 YOLOv3-SPP鉴于YOLOv3 在自然图像检测方面的出色表现,本文采用YOLOv3 为基础框架,充分考虑ABUS 补片超声图像特性,引入空间金字塔池化结构SPP 模块,以进行局部特征和全局特征的特征图级别的融合,实现更有效、更加有针对性的特征提取,改进后得到的YOLOv3-SPP模型更加适合ABUS 补片超声图像的检测.融合YOLOv3 和SPP 模块的优势,本文提出了一种新的网络模型YOLOv3-SPP.该模型的结构如图4 所示.
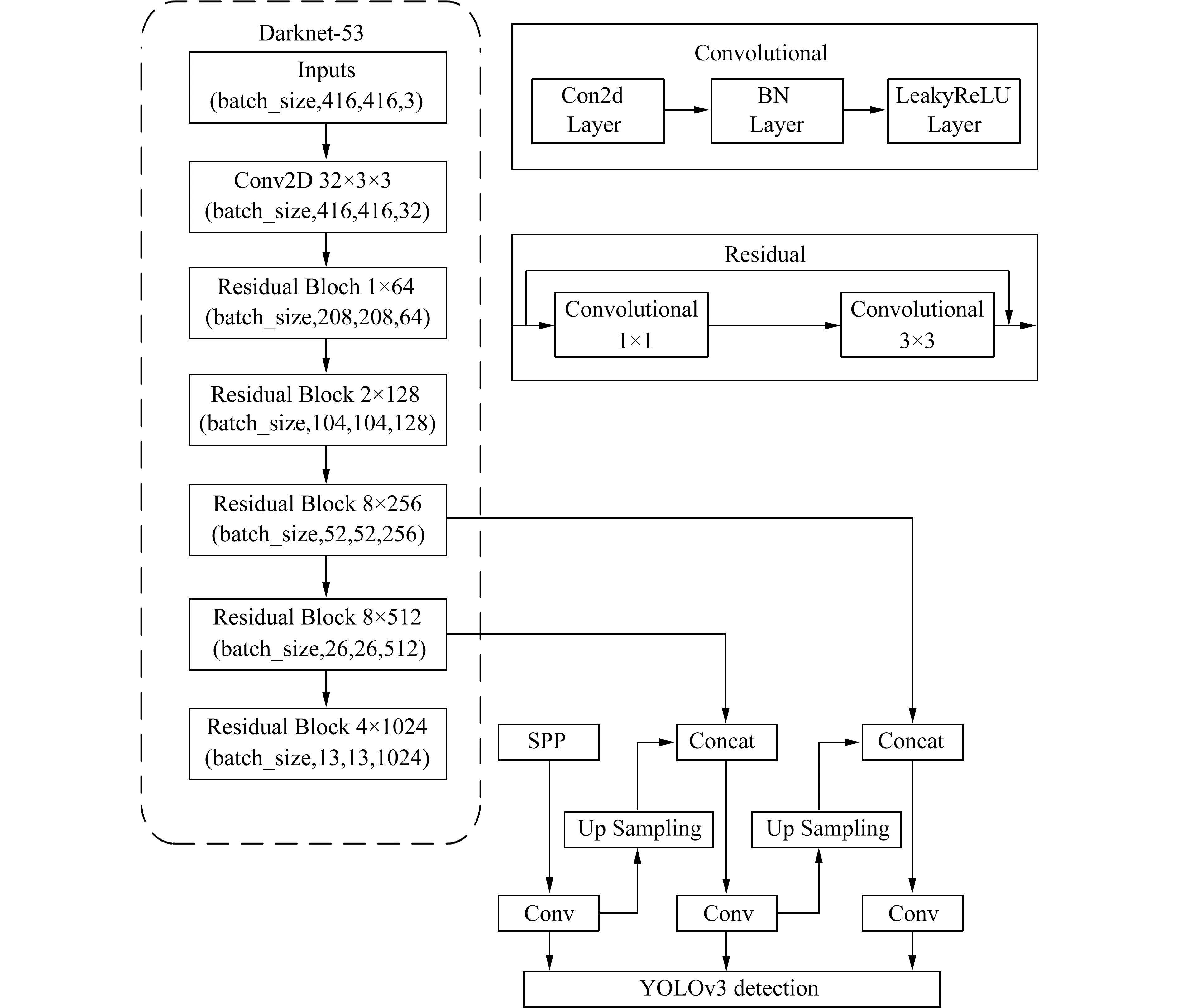
图4 YOLOv3-SPP 的网络结构示意图Fig.4 The schematic diagram of the network structure of YOLOv3-SPP
输入图片进入该网络后,首先将图像大小调整为416×416,通道数为3,然后进入YOLOv3-SPP 的主干网络Darknet-53 进行特征提取:经过一层卷积操作后进入5 个Residual Block 层进行5 次下采样,其中卷积层为Conv(卷积)+BN(批规范化Batch Nomalization)+Leaky ReLu(激活函数),Residual Block层中包含多个残差单元,整个网络Residual Block部分采用串联的方式,其输出直接作为后续网络的输入.然后在检测层前通过SPP 模块采用固定分块大小为5,9,13 的池化操作,实现局部特征和全局特征的特征图级别的融合,提取图像特征.后续为网络检测部分,主要任务是识别分类和预测目标检测框.YOLOv3-SPP 应用多尺度融合的方式形成金字塔形网络,提供了3 种不同尺寸的边界框.我们从主干网络Darknet-53 的后面几个图层以及SPP模块中得到特征图,由SPP 模块得到最底层13×13尺度的特征图,对该特征图进行上采样,然后与26×26 尺度的特征图进行拼接,融合后的特征图再进行采样,与52×52 的特征图进行拼接,直至完成3 个尺度特征图的融合.在多个尺度的融合特征图上分别独立检测,获得更多的语义信息,提升目标检测能力.最后,通过一个卷积层得到预测结果
本文以ABUS 补片超声图像样本作为输入,通过多尺度调整生成416×416×3 的模型输入,再进行特征提取、空间金字塔池化、特征融合和目标检测,最终得出精准结果.
2.3 迁移学习设计与实现深度学习模型的检测效果与训练样本数密切相关,只有在大量训练样本的基础上,才能得到高质量的深度学习模型[22].由于本领域为新兴领域,标记好的轻量型补片超声图像数据集较少,直接用数据训练YOLOv3-SPP 模型时,模型的泛化性能较差,不能在复杂的超声图像背景下实现准确检测.
本文将迁移学习引入到研究中.在迁移学习过程中,主流观点认为,相近的种类迁移效果优于两个相差较大类之间的迁移.ABUS 离体补片图像与在体图像之间存在一定相似性,其基本特征(例如,构成图像的直线和曲线,补片的网状特征)是通用的[23-24].因此,传送的参数(权重)可以用作一组强大的特征,其减少了对大型数据集的需要以及训练时间和存储成本.对此,本文采用迁移学习的方式[25]训练模型.
本文基于迁移学习实现YOLOv3-SPP 网络模型的预训练、训练以及优化等,迁移模型如图5所示.
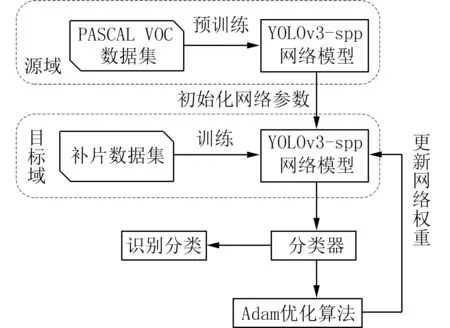
图5 基于迁移学习的YOLOv3-SPP 模型Fig.5 YOLOv3-SPP model based on transfer learning
算法的具体实现过程如下:
步骤 1将离体补片数据集中的离体补片作为源域检测任务,离体补片数据集作为源域训练样本.对YOLOv3-SPP 模型进行预训练,得到预训练模型参数;
步骤 2构建与源域模型相同的目标域模型;
步骤 3将在体补片数据集中的在体补片作为目标域检测任务,在体补片数据集作为目标域的训练样本.将上述预训练模型中的参数作为目标域模型的初始化参数对目标域模型进行训练;
步骤 4采用Adam 算法优化网络;
步骤 5最终通过Logistic 分类器实现目标的检测分类.
通过迁移学习,使网络能够在训练过程中,更容易地得到超声图像中轻量型补片的特征信息,减少训练时间和存储成本并提高训练的精度,同时解决模型训练数据量不足导致模型泛化能力差的问题.
3 实验与分析
3.1 实验配置本文实验环境为:Windows 10(64 位)操作系统;Intel Core i7-9750H CPU,16 GB内存;NVIDIA GeForce RTX 2080 GPU,显存11 GB;PyTorch 版本为1.6.0,torchvision 版本为0.4.1,CUDA版本为10.1,CUDNN 版本为7.6.1.
3.2 补片检测数据集查询到在补片检测领域,目前还没有公开的图像数据集.为验证本文算法的有效性,实验自行构建了离体轻量型补片数据集以及在体轻量型补片数据集.其中,离体补片数据集,如图6 是将补片放入琼脂、动物明胶、甘油、石墨粉等原料构建的仿体,并在不同的原料配比下得到模拟组织.在体补片数据集(图7)包含143 例腹疝患者(男71 例,女72 例;年龄42~79 岁,平均(60.6±11.2)岁)进行临床研究.共植入轻量型补片193 枚,其中右侧109 枚,左侧84 枚.48 例患者均为双侧腹股沟疝,双侧均植入轻量型补片,共2 380张超声图像.使用开源标签工具LabelImg 根据PascalVOC 公共数据集标准创建补片检测数据集,图像标注是由3 名专业医生使用矩形标记框标注轻量型补片的真实位置.

图6 离体补片数据集不同深度超声图像示例Fig.6 Ultrasonic image example of in vitro mesh data set
图7 在体补片数据集不同区域超声图像示例Fig.7 Examples of ultrasound images of different regions of the in vivo mesh dataset
该数据集的图像来源于昆明医科大学第一附属医院采集自Siemens ACUSON S2000 ABUS 设备;所有个人敏感隐私信息都已从图像中移除,所有工作均经机构评审委员会批准通过.
3.3 基于迁移学习的YOLOv3-SPP 训练在训练过程中,神经网络主干特征提取部分所提取到的特征是通用,冻结训练可以提高训练效率,也可以在训练初期防止权值被破坏.结合迁移学习共设置150 个epoch,使用冻结训练.在前75 个epoch 冻结主干网络,利用模型在离体补片数据集上预训练得到的参数作为初始参数.仅训练检测器层,初始学习率设为0.001 可以收敛的更快;在第76 个epoch解冻训练,同时学习率减小为0.000 1.每次迭代输入样本的batchsize 为8,梯度优化函数使用Adam,衰减系数为0.000 5,动量为0.9,IoU 阈值设置为0.5.
网络模型的损失函数为目标类别的损失Lclass、置信度损失Lconf以及定位损失Lloc,三者之和为最终损失Ltotal,具体如下:


3.4 实验结果与对比实验分析本文实验在构建的补片检测数据集上进行,为证明本方法的有效性,文中选取了双阶段检测算法(Faster R-CNN)和单阶段检测算法(SSD、YOLOv3),目标检测领域主流的深度学习算法作为对比模型.评价指标包括精确率(precision)、召回率(recall)与平均精度均值(Mean average precision,mAP)以及检测速度(FPS),其中,mAP 指的是各目标类别平均检测精度的均值,也是目标检测领域最常用的基本评价指标.
从表1 可以看出,在相同数据集上做训练得出的测试结果显示本文提出的YOLOv3-SPP 检测算法平均精度均值达到了87.11%,高于单阶段目标检测算法SSD 和YOLOv3 的平均精度.虽然低于双阶段目标检测算法Faster R-CNN 的平均精度均值,但Faster R-CNN 检测速度过慢,无法满足医生要求.YOLOv3-SPP 的精度足以保证得出的各项数据可辅助医生进行疝修补术后诊断.

表1 4 种算法的性能对比Tab.1 The performance comparison of four algorithms
在数据集相同的情况下,对YOLOv3-SPP 采用迁移学习的训练策略,对比其对于模型目标检测性能的影响.通过表2 发现,直接进行训练,模型泛化性能差,检测结果准确率和召回率以及mAP 都较低.在迁移学习的策略下训练,模型训练更加充分,提高了网络模型的泛化能力及鲁棒性,测试结果表明各项指标大幅提升,其中mAP 达到90.15%.综上所述,采用迁移学习的训练方式可有效提高模型整体性能.
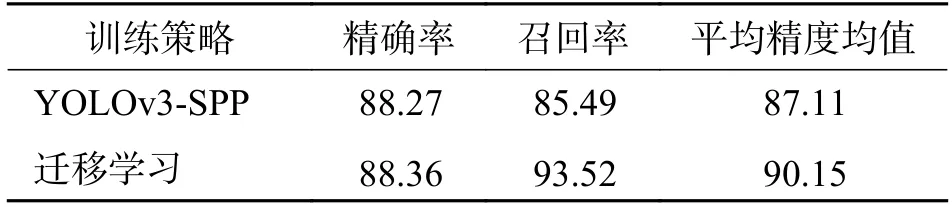
表2 YOLOv3-SPP 在不同训练策略下的检测性能Tab.2 YOLOv3-SPP detection performance under different training strategies%
图8 为传统训练方法训练YOLOv3-SPP 和迁移学习训练策略的检测结果的对比.图8(a)(c)为传统训练方法后的检测结果,(b)(d)为采用迁移学习的检测结果.可以看出,两者都有较好的检测性能,但使用传统训练方式的检测结果依然存在部分小目标漏检以及一些检测框与目标贴合不精确的情况.而使用迁移学习的训练方法使网络对特征的学习和分类能力更强,能对小目标进行更好检测,边界框更加贴合补片轮廓;更少的漏检较大地提高了召回率以及mAP.

图8 有无采用迁移学习训练典型结果对比Fig.8 Comparison of typical results with or without transfer learning training
图9 显示了本文方法对超声图像中轻量型补片在不同部位下的检测效果.在不同的部位,本文提出的方法均能得到良好的检测结果.

图9 不同部位检测结果Fig.9 Detection results of different parts
4 结语
本文基于改进YOLOv3-SPP 网络结构与结合迁移学习的目标检测算法可以对ABUS 超声图像中不同形状补片的特征信息更全面、完整、高效地学习,有效改善了检测性能,显著提高了检测效果.实验结果表明,本文所提改进算法最终mAP 可以达到90.15%,每张图像检测速度为33.2 f·s−1,可以满足医生对ABUS 轻量型补片诊断中目标检测的需要,具有应用于临床辅助诊断的巨大价值.未来,我们将进一步应用深度学习方法,对ABUS 补片图像进行分类、检测、分割等,进一步提高计算机辅助诊断的应用性能.
