基于机器学习的热释放速率实时预测方法
2022-05-24张羽杨陆梓萍杨立中
舒 舜,张羽杨,陆梓萍,王 董,姜 楠,杨立中*
(1.上海市消防救援总队黄浦区支队,上海,200011;(2.中国科学技术大学火灾科学国家重点实验室,合肥,230026)
0 引言
城市内火灾隐患多且人员分布密集,极易发生威胁群众生命与财产的火灾事故。提升城市的火灾应急救援能力一直是公共安全研究的重要课题。然而,当前我们国家的消防救援在动态监测感知城市火灾方面的基础还很薄弱,缺乏对灾害现场的数据掌握和实时预测能力。目前科研人员常用场模拟软件(例如FDS)对建筑、隧道、船舶等火灾场景进行模拟[1-3],从而判断相应火灾场景下火势发展和火灾产物可能带来的危害性。虽然现有的数值模拟软件已经很成熟,其准确性也得到了认可,但是精确模拟需要细小精致网格,一个场景的运算往往需要几个小时、几天甚至更长的时间,导致这些方法难以应用在消防现场实战中。
为了实时预测火灾的发展态势,机器学习逐渐受到科研人员的关注。机器学习可以利用计算机模拟或学习给定的数据集得到指定参数之间的耦合关系,在真实火场中利用预训练模型在数秒内即可获得相关数据。近年来国内外很多科研人员尝试用各种机器学习方法对火场参数进行实时预测。李梦婕[4]基于FDS模拟得到的54组地铁区间隧道火灾数据提出了基于自编码器的CAERES-DNN模型,实现了烟尘能见度和烟气扩散距离的准确预测。Hodges等[5,6]利用DCIGN模型预测野火蔓延情况,提出了用于预测房间内的温度和速度分布的TCNN建模方法。Wu等[7-9]建立了一个含有大量隧道火灾实验数据的数据库,并基于此数据库搭建了预测隧道火灾中火源位置和温度场分布的多种模型。Wang等[10]提出了P-Flash轰燃预测模型,利用序列分割和支持向量回归两种方法,克服了探测器因高温失效造成温度数据无法获取的难题,提高了模型预测单室和多室发生轰燃的能力。
然而,前人对烟雾、温度、有害气体浓度等火场参数的预测建立在火灾热释放速率为已知参数的基础之上,目前很少有实时获取火灾热释放速率的技术和研究。热释放速率是火灾至关重要的参数之一,影响着火灾的规模和发展态势。火灾热释放速率反演求解大多采用经验估计对火源参数做出判断,例如根据Heskestad平均火焰高度经典方程反推热释放速率[11]。当热释放速率不变时,火焰高度和体积会因为火焰的脉动特性而不断变化,通过火焰高度和体积反推就会得到不同的热释放速率,计算结果具有较大的不准确性和不稳定性。因此,本文提出了一种基于支持向量机的热释放速率实时预测模型。该预测模型可以根据连续的火焰体积或高度连续变化特征快速准确地完成热释放速率的实时预测,有效地解决了以上问题。预测结果可以为消防救援战术的制定提供科学合理的依据,消防指战人员可以据此预判火灾态势发展和极端火灾行为的发生。
1 数据准备
本文通过火焰体积或高度与热释放速率之间的联系建立数据库进行分类训练,主要流程分为六个步骤,具体过程如图1所示。首先拍摄丙烷燃烧视频得到火焰图像,基于圆柱形假设重建三维火焰;然后通过计算机图像处理技术获取火焰的体积和高度数据[12],对火焰体积和高度数据进行处理后结合热释放速率数据建立数据库;最后选用合适的分类模型进行训练优化,最终的预测模型可以根据火焰体积或高度的连续变化特征实时预测热释放速率。

图1 技术路线图Fig. 1 Technology roadmap
1.1 数据获取
模型训练使用的数据来自丙烷燃烧实验拍摄的火焰视频[12]。实验采用六种不同尺寸的圆形丙烷气体燃烧器作为火源,燃烧器直径分别为0.05 m、0.1 m、0.15 m、0.2 m、0.25 m和0.3 m。燃烧器底部铺设约4 cm厚度的透明玻璃珠,保证气体燃料出流时扩散均匀。
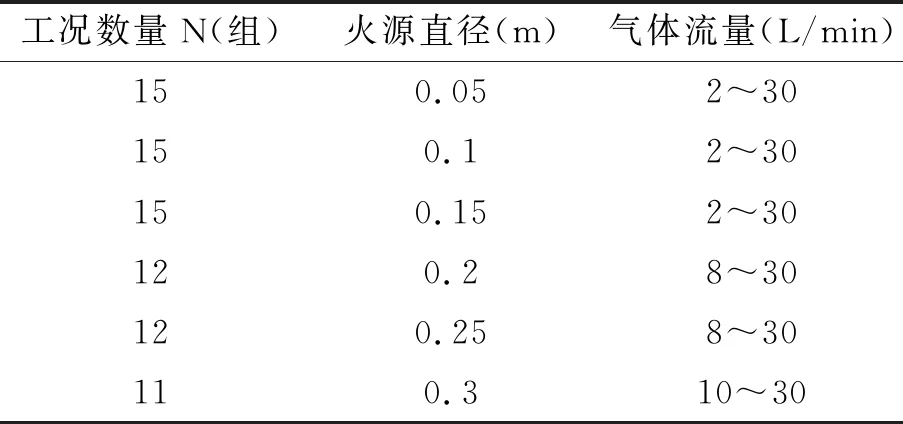
表1 测量火焰高度和体积实验工况
表1列出了测量火焰高度和体积实验中的80种工况。由于气体流量较小时,火焰无法充满直径较大的燃烧器,对不同直径的燃烧器,需要根据火焰的扩散情况确定各个直径不同的燃烧器的初始燃料流量。最大燃料流量均设置为30 L/min,变化梯度为2 L/min。摄像机的曝光度根据实验环境调整,使得拍摄出来的图片中只有火焰且火焰细节拍摄清晰。每组工况采集燃烧稳定后90 s的视频数据。
从每个采集到的视频中截取一分钟作为训练数据集数据来源。视频每秒25帧,一分钟的视频可以转化成1 499张图片。然后,根据火焰与周围背景之间的亮度差进行火焰高度和体积测量[12]。对同一燃烧器尺寸的数据进行整理,生成如表2所示的原始数据集。原始数据集中的每一行都代表某一帧的具体参数,每组流量有1 499行数据,每个燃烧器的数据量为1 499*N(N为该燃烧器尺寸下的工况数量)。
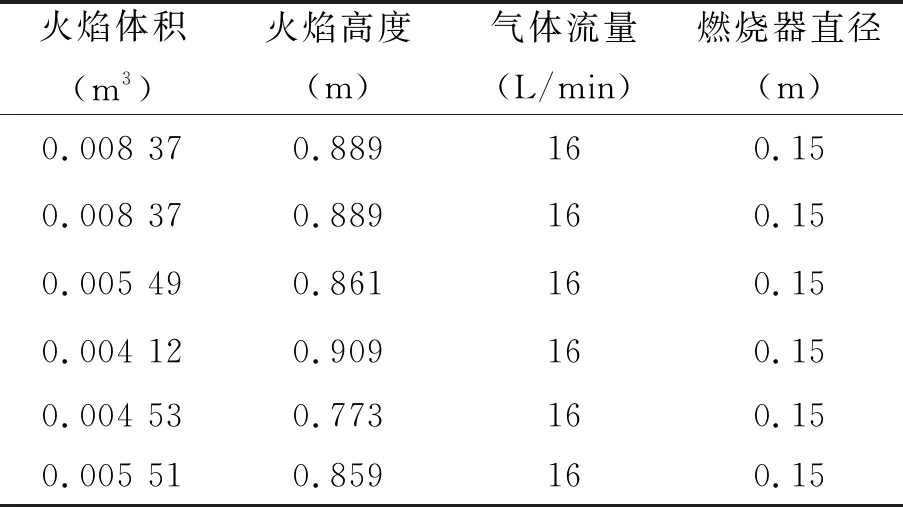
表2 部分原始数据集
1.2 数据处理
燃烧过程中火焰周期性的振荡造成火焰形状的不稳定性,从而导致火焰体积与气体流量之间的对应关系并不唯一,如表2中相同的气体流量和燃烧器直径工况下对应不同的火焰体积和火焰高度。通过平均火焰高度经验公式反演热释放速率只能得到一段时间内的平均值,实时热释放速率的计算因火焰高度不断波动而存在较大差异,其准确率难以保证。为了消除火焰快速脉动带来的偶然性影响,我们通过建立火焰高度或体积的连续变化规律与热释放速率之间的关系,解决火焰脉动带来的火焰高度、体积与热释放速率之间对应关系的不唯一性。
2 模型搭建
2.1 分类模型选取
模型的搭建、训练和测试在MATLAB中进行,MATLAB分类学习器中包含各种精度的SVM、决策树、KNN、神经网络等各类分类器,可以对同一数据集进行多种分类器的训练比较,选出在特定数据集上表现更为优异的一种。
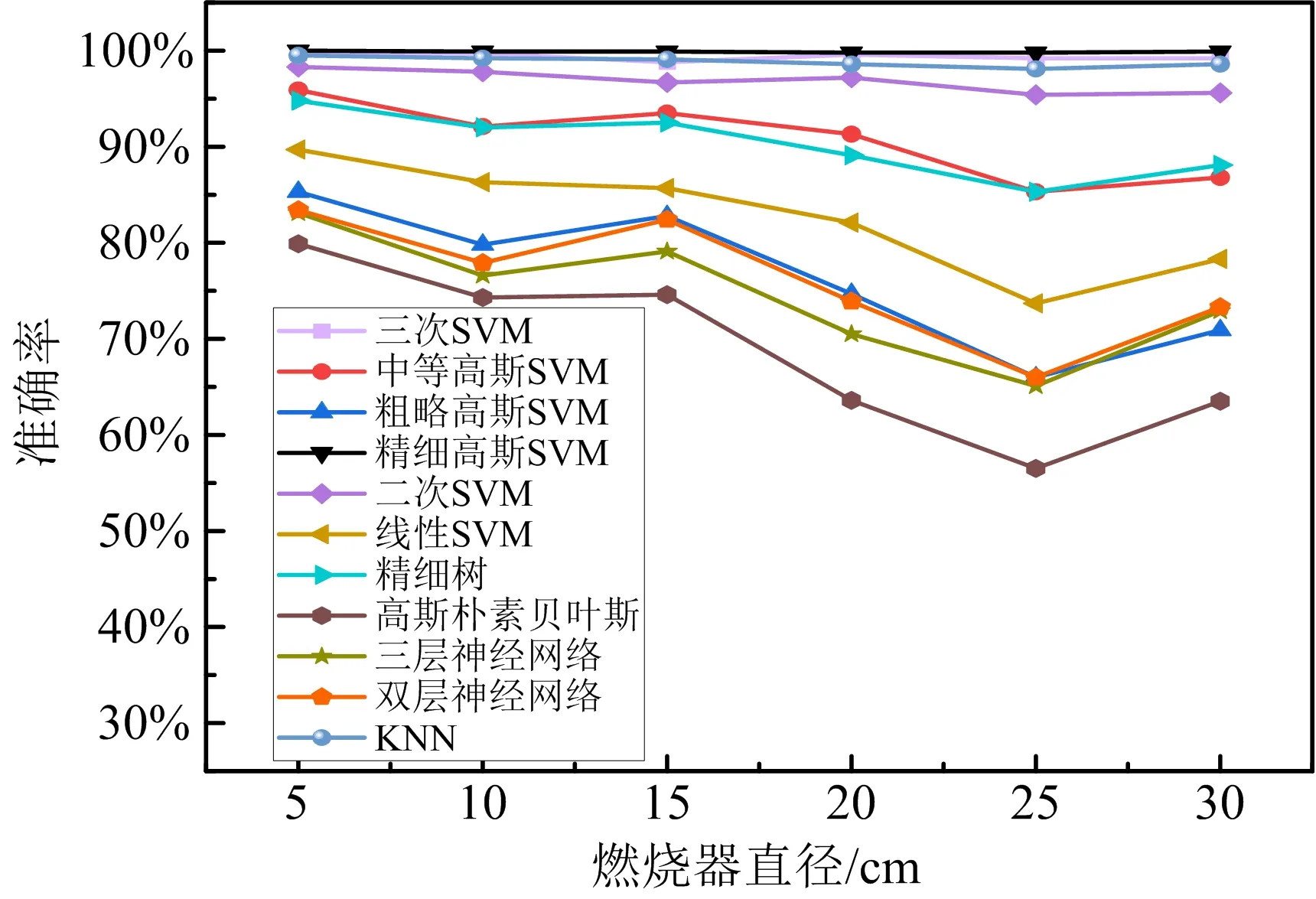
图2 不同分类算法训练结果Fig. 2 Training results of different classification algorithms
在MATLAB环境中选用多种分类学习算法对数据集进行训练,训练结果如图2所示。由于实验中直径为0.2 m、0.25 m和0.3 m的燃烧器的试验工况较少,相对应的数据量也远小于燃烧器直径为0.05 m、0.1 m、0.15 m的数据量,所以在图2中表现为多种分类模型在直径为0.2 m、0.25 m和0.3 m的准确率明显小于直径为0.05 m、0.1 m、0.15 m的准确率。精细高斯SVM、KNN、和三次SVM三种分类模型在不同燃烧器直径工况下都表现出了较高的准确率,精细高斯SVM的准确率接近100%,所以本文选取精细高斯SVM为本次实验的分类算法。
2.2 SVM介绍
支持向量机(SVM)是一种对数据进行分类的机器学习算法。用支持向量机进行分类,需要由特征X= (x1,x2,…,xn)和标签Y= (y1,y2,…,yn)组成样本训练集。本次训练中的特征X是1.2节中经随机抽取及排序后的n个体积数据组,标签Y是表征理论热释放速率的气体燃料流量。样本训练集D中各个样本分别对应其标签,形式为D= {(x1,y1), (x2,y2), …, (xn,yn)}。SVM根据学习样本训练集D中各个“样本特征-标签分类”组合,在这组数据中找出一个超平面作为决策边界,使模型在数据上的分类误差尽量小,尤其是在未知数据集上的分类误差(泛化误差)尽量小[13]。

图3 模型准确率与特征数量关系图Fig. 3 Relationship between model accuracy and feature quantity
2.3 特征数量的选择
2.2节中的n值为特征数量,代表着模型在实际场景使用过程中需n/25 s的视频数据进行预测。n值越大表示预测某时间点的燃料流量及热释放速率需要持续时间更长的视频数据。在精细高斯SVM分类模型中改变特征数量n值,查看n值变化带来的模型准确率差异,结果如图3所示。燃烧器尺寸不同时,预测模型的准确率与特征数量的关系都具有相同的趋势。随着特征数量n的增加,模型准确率在特征数量较小时增长迅速,最后趋于一个稳定值,且均接近于100%。考虑实际应用的效率,我们选取特征数量为60,即预测某时间点的燃料流量需要60帧(2.4 s)连续的火焰体积数据。
选定特征数量n为60后,重复2.2中的随机抽取及排序操作得到训练数据集,将训练集输入精细高斯SVM分类器中进行训练,得到火焰体积-热释放速率预测模型,模型准确率约为99%。由于火焰平均体积与燃烧器尺寸没有明显的相关性[12],故不同燃烧器分别训练得到不同的预测模型,共6个。同理可得到火焰高度-热释放速率预测模型。
3 预测结果
3.1 已知数据预测结果
为验证模型的有效性,截取原视频中任意视频数据,对模型预测能力进行初步评估。验证视频时长需要大于特征数量对应的时长(2.4 s),故此次验证选取每组流量的3 s视频转化为74张图像进行数据处理,预测其中10个样本数据的热释放速率并进行对比验证,每种燃烧器直径验证样本数量为N*10。图4展示了6种不同燃烧器直径下根据火焰体积预测的热释放速率结果,三角形表示实际热释放速率,圆圈表示SVM模型预测得到的热释放速率。实际值按梯度增加时,预测值也相应增加。图4中两条线几乎重合,说明模型训练准确度较高。图4(c)、图4(d)、图4(e)中个别数据预测存在误差,但是误差较小,且出现误差的概率较低。图5展示了根据火焰高度预测的热释放速率结果,除图5(c)、图5(d)中有个别误差外,其余均根据60帧连续火焰画面精准预测了相对应的热释放速率,说明模型在已知数据的预测上有非常高的准确度。
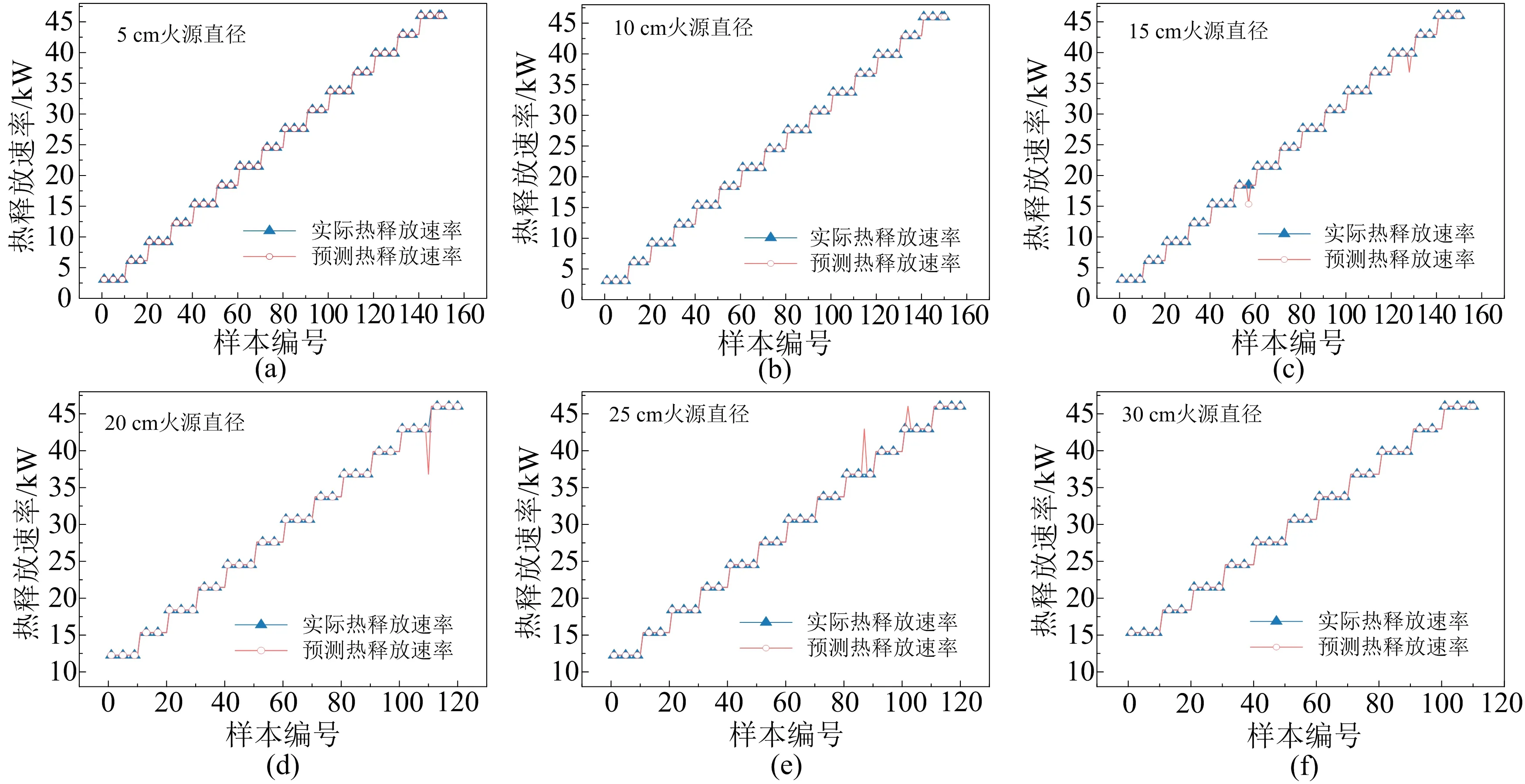
图4 基于火焰体积的热释放速率预测结果(原始数据)Fig. 4 Prediction results of heat release rate based on flame volume (original data)
3.2 未知数据预测结果
模型在原始数据上具有优秀的表现能力,为检验模型在未知数据上的表现和真实应用中的预测能力,本文选取原始数据集之外时长为3 s的火焰视频数据,计算其火焰体积和高度形成相应的预测数据集。使用训练好的模型进行预测,由预测的燃料流量计算得到的热释放速率结果如图6和图7所示。图6为根据火焰体积得到的热释放速率预测结果。对于SVM分类模型“从未见过”的数据,预测结果相比于原有数据集的准确率会较低一些,但是在部分的预测过程中结果完全正确,其他工况的结果也与正确流量相差不大,误差都在允许波动的范围之内。图7为根据火焰高度预测得到的热释放速率,与体积预测的结果表现相似,在部分数据上存在波动,除个别特殊点外,误差基本为2 L/min或4 L/min。
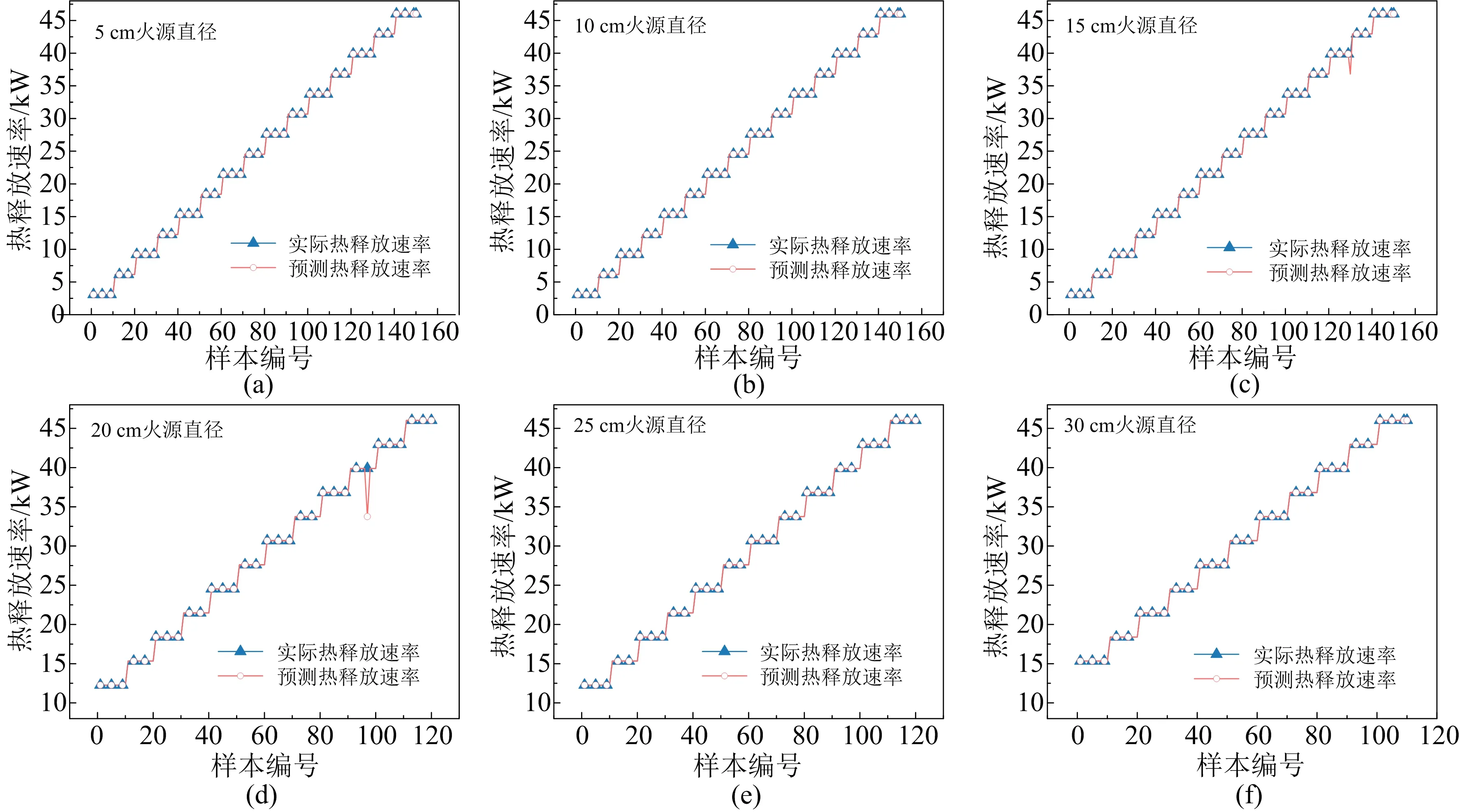
图5 基于火焰高度的热释放速率预测结果(原始数据)Fig. 5 Prediction results of heat release rate based on flame height (original data)
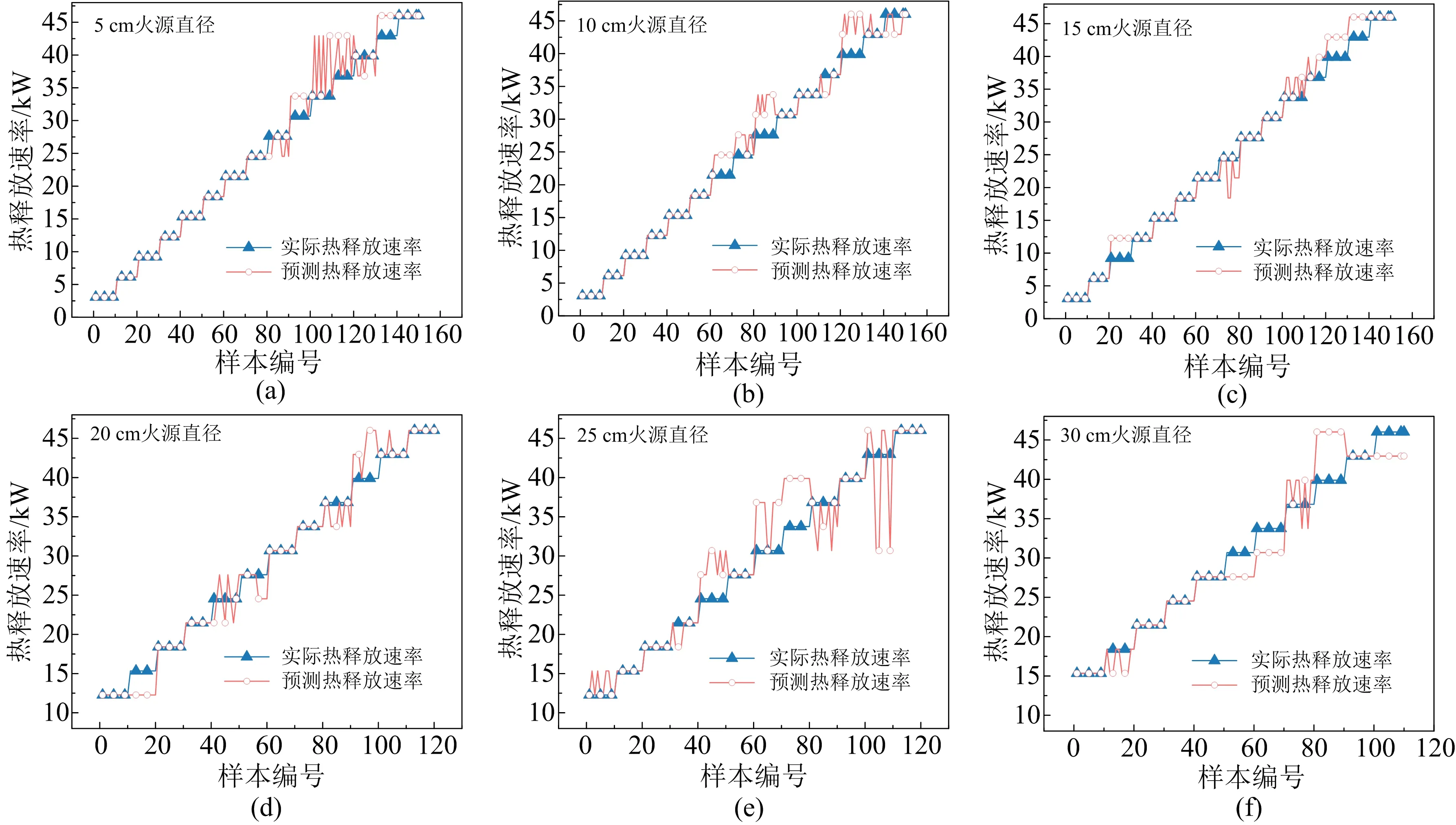
图6 基于火焰体积的热释放速率预测结果(全新数据)Fig. 6 Prediction results of heat release rate based on flame volume (new data)
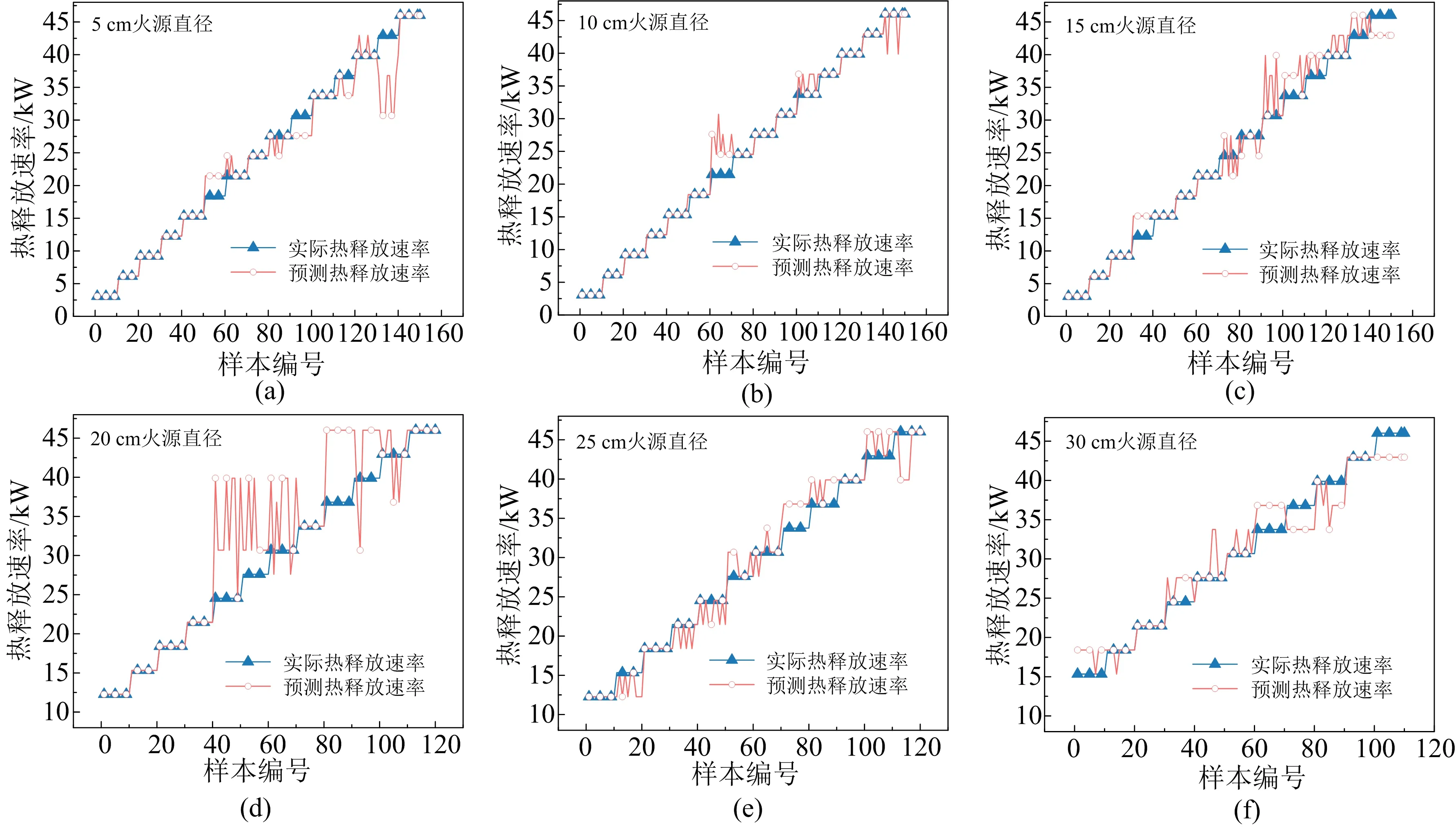
图7 基于火焰高度的热释放速率预测结果(全新数据)Fig. 7 Prediction results of heat release rate based on flame height (new data)
可燃物燃烧过程中火焰形态每一时刻都在变化,60帧火焰视频有无数种火焰形态排列组合。经过训练的模型在已知数据上有很好的表现能力,但其泛化能力受到训练数据集量度和广度的影响,对于陌生数据,模型很难达到和已知数据集一样高的准确率。火焰脉动过程中易出现火焰收缩和部分火焰脱落上升等现象,这些现象会影响火焰高度的计算,导致火焰高度在某些时刻存在过高或过低估计,与相同流量下平均火焰高度相差过大的数值会影响火焰体积和后期预测的结果,导致个别样本预测得到的燃料流量及热释放速率出现较大的偏差。另外,误差的产生也与拍摄环境、实验操作等外界因素有密不可分的联系。
“火焰体积/高度-热释放速率预测模型”在未知数据集上表现优秀,证明用一段时间火焰体积/高度的连续变化特征对热释放速率进行反演计算具有可行性,大大降低了火焰高频脉动现象带来的干扰。基于支持向量机的热释放速率预测模型具有实时性和普适性。本文使用的数据信息均基于实验室条件下丙烷气体的燃烧实验,未来可以进行大量不同火焰形态、规模的实验,也可以与FDS数值模拟相结合建立更多的真实火灾场景,获得更丰富的火灾参数拓展数据库,进一步推进模型在实际火灾场景中的运用。
4 结论
本研究从热释放速率稳定的丙烷气体燃烧实验出发,开展了支持向量机分类算法在火灾中的应用研究,实现了根据数秒内火焰的体积或高度数据预测相对应的火灾热释放速率,大大降低了火焰脉动和收缩过程对反演计算带来的影响。实验结果证明,精细高斯支持向量机(SVM)在本数据集上具有很高的预测精度。在验证集上只有极少数数据会出现预测误差,在陌生数据集上也有很好的预测精度。
本文提出的“体积/高度-热释放速率预测模型”可以根据2 s~3 s内60帧火焰画面较精准地预测燃料流量和热释放速率,为后续的火焰相关参数计算提供了重要依据。SVM的准确性和快速性使得该模型可以在火场中发挥作用,帮助消防救援人员实时预测和判断火灾发展态势。实际应用中可以通过提升计算机配置,例如使用显卡和GPU等进行计算,可大幅缩短处理时间,提升模型的时效性和实用性。
