基于多模态音视频融合的质量评价算法
2022-05-24袁同庆
袁同庆, 席 鹏
(1. 安徽师范大学 a. 智能教育研究院, b. 教育科学学院, 安徽 芜湖 241000; 2. 中国科学技术大学 苏州研究院, 江苏 苏州 215000)
目前,质量评价任务主要采用调查问卷的形式搜集评价目标相关的主观评价资料,这种方式主要采用评价主体的主观评价,不仅耗时、费力且采集的调查问卷不易保存,难以分析和利用[1-3].近年来,随着互联网技术和信息技术的快速发展,质量评价逐渐采用网络形式展开,不仅可以搜集评价目标的主观评价结果,而且评价主体可以提交充分的材料以佐证评价结果[4].采用信息化的质量评价与采集方式,可以及时、全面地采集评价主体对于评价目标的反馈情况[5-7].虽然这种方法简化了传统的质量评价采集方式,但仍需花费大量的人力资源和时间对这些评价进行分析与处理.为了提升质量评价的精度和速度,国内外学者提出了基于机器学习方法[8]、基于深度学习方法[9]和基于情感词典方法[10-11]对评价主体的调查问卷进行分析.其中,基于情感词典的方法通过构建包括形容词、程度副词和否定词的情感词典对评价文本进行分类;基于机器学习的方法采用传统的机器学习技术来完成文本情感数据的分类;而基于深度学习的方法使用深度神经网络从文本数据中提取特征,并进行情感分类[12-13].虽然这些方法使基于调查问卷的质量评价得到了显著的提升,但若仅采用调查问卷数据进行质量评价仍显说服力不足.
随着多媒体技术的普及,在信息化评价过程中留下了大量的视频和语音资料,如何充分挖掘这些多媒体数据中的有效信息成为了研究的热点.本文充分利用多媒体资源,提出了一种基于多模态音视频融合的客观质量评价算法.该算法充分考虑评价目标的视频、音频和文本信息,并挖掘信息间的相关性进行评价与分类.
1 多模态特征提取
本文采用多模态数据进行客观质量评价.为了实现多模态数据的统一输入和处理,对不同的模态提取不同的特征,并根据其特点选择相应的分类器进行预测分类.最后,对各模态的分类预测结果进行融合训练,组成一个综合分类器,从而得到质量分类结果.
1.1 文本特征提取
文本数据包含了对评价目标的直接评价,然而文本数据包含着复杂的语言种类和语法,使得对其分析与建模异常困难.为了有效提取出文本中包含的与评价目标相关的特征,本文首先使用Jieba分词工具对输入文本进行分词,即将文本序列表示成词向量集合;然后过滤掉与评价目标无关的停用词,包括中英文标点符号、特殊字符、阿拉伯数字和一些影响较小的高频词汇;最后,使用Word2vec模型将词向量表示为多维空间向量.
本文通过提取文本的互信息作为文本特征,互信息通过衡量事件发生所提供的信息量来衡量文本特征对于评价结果的影响[14].互信息计算表达式为
(1)
式中,X和Y分别为文本特征集合及类别集合.本文选取前K个互信息最大的特征作为输入文本集合的特征.
1.2 语音特征提取
语音作为评价目标的一种信息媒介,不仅包含评价目标的内容,且包含事件发生时周围环境.本文通过提取语音信息特征,从语音信号中获取评价目标的相关信息.首先对语音信号进行预加重、分帧和加窗等处理,然后提取语音的梅尔频谱倒谱系数(MFCC)特征.其中,预加重处理采用数字滤波的方法来提升语音信号的高频衰减;分帧是将语音信号分割成较短的帧序列;加窗则是采集在增强采样点附近的语音信号.MFCC特征是根据人类听觉的临界频带效应来模拟人耳对不同声音的感知和响应,从而提取特征.具体的特征提取过程如下:
1) 使用快速傅里叶变换对N帧语音序列x[n](n=0,1,2,…,N-1)进行变换.
2) 将傅里叶变换后得到的频率信号转换为梅尔尺度Mel(f)=2 597lg(1+f/700).
3) 计算三角形滤波后的结果,即
F(l)=∑wl(k)|x[k]| (l=1,2,…,L)
(2)
式中:k为转换后的频率;
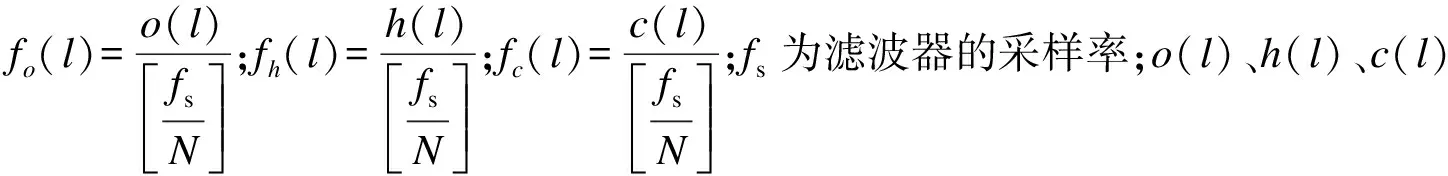
4) 对步骤3)中得到的结果进行对数运算和离散余弦运算,得到MFCC特征为
(3)
1.3 视频特征提取
本文使用循环神经网络提取视频特征,该网络采用CNN结构来提取输入帧的表征特征,采用堆叠的RNN单元来捕捉时序信息.提取单元结构如图1所示,R为ReLU(Conv())函数,用来提取输入帧的表征,T为Sigmoid(Conv())函数,用来提取时序信息,oi,t为网络输出,ci,t表示第t帧在第i个循环单元的记忆状态.
本文采用堆叠的循环特征提取单元来提取输入视频的深度特征.由于深度网络在建模长序列时容易出现梯度消失的问题,本文使用跳跃连接来加深网络.为了训练该网络以提取评价目标相关的特征,本文直接使用BP算法对输出特征进行分类训练,通过最小化网络输出与评价标签之间的交叉熵损失来完成迭代优化.
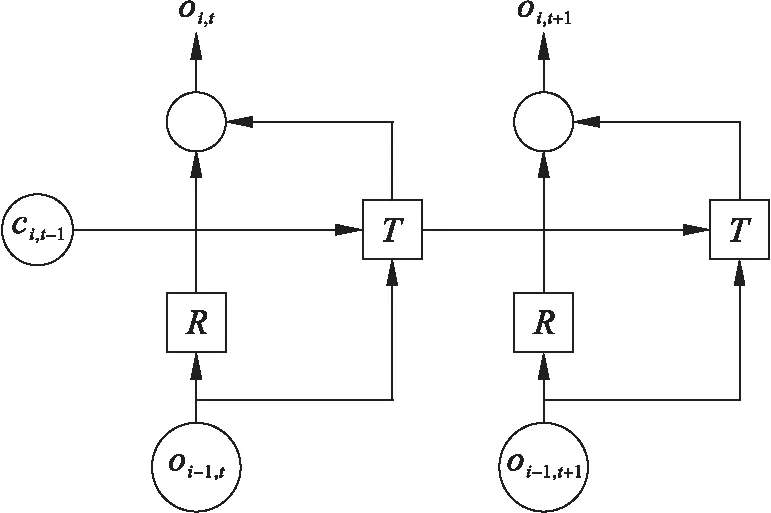
图1 循环特征提取单元Fig.1 Recurrent feature extraction unit
2 基于Stacking算法的客观评价分类
由于评价数据中存在大量的与客观质量评价无关的数据,需要对这些数据进行筛选和过滤,以此实现客观评价质量的分类.本文使用了Stacking算法构建客观质量分类模型来融合不同数据间的特点.算法分别对视频、语音和文本所提出的特征构建预测分类模型,然后使用一个元分类器对其分类结果进行融合,并得到最终的课程评价结果.相比于其他集成学习方法,该算法适用于异构数据和异质分类器,且最终的分类结果采用更复杂的元分类器,而并非传统集成学习方法所采用的平均法或基于投票的方法.本文使用朴素贝叶斯算法(NB)对文本特征进行分类,使用支持向量机算法(SVM)对语音特征进行分类,使用BP算法对视频特征进行分类,而元分类器则采用SVM分类器.文中各分类器将输入数据分类为正向情感、负面情感和无关三类,其中无关类即为不包含任何情感倾向.
文中提出的算法主要包含两层学习:多模态初始学习器和元学习器,其中多模态初始学习器采用K折交叉验证的方式进行训练,在训练预测器的同时生成训练元数据所需的数据;在得到这些数据后,训练元学习器实现多模态数据的融合和评价质量的预测.元学习器的输入为基学习器的输出,而不同模态的数据具有不同的特点,故本文为每个初始学习器赋予了一个权重.

基于该权值计算方式,本文基于Stacking算法构建的质量分类模型的训练步骤如下:
1) 定义训练数据集D={(x1,y1),(x2,y2),…,(xK,yK)}=(X,Y),初始学习器M1,M1,…,MZ;
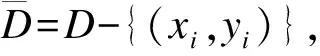
3) 对于每个分类器计算其权重.根据各初始分类器的预测结果对训练数据进行筛选,删除与质量预测无关的数据.
4) 使用上述步骤得到的初始分类器,针对各训练数据的预测结果和各分类器的权重来训练元分类器.
3 实验与分析
本文以质量评估为例进行仿真试验与分析.为了对模型进行训练和测试评估,本文搜集了某高校20门公共课程的多媒体数据,包括教学视频、语音和文本评价,共采集了包括30名学生对于各门课程的评价结果.其中约有20 TB视频数据,10 GB语音数据和5 GB文本数据,每一门课程对应的视频、语音和文本的比例大约为1∶12∶60.通过统计各课程的评价结果,并将其作为标签进行模型训练评估.随机选取该数据集中15门课程的数据作为训练集,使用剩下的5门课程数据作为测试集进行仿真分析.本文实验平台为Intel Xeon CPU E5-2430,使用Ubuntu操作系统,并采用Python实现所提出的分类算法.文中使用预测准确率和预测结果的F1值作为算法性能的评价指标,F1计算方式为
(4)
(5)
(6)
式中:TP为正确分类的正类;FP为错误分类的正类;FN为错误分类的负类.本文将每条评价对应的类别作为正类,将其他类别作为负类.
首先验证了各个基础分类器的分类准确率与F1值,结果如表1所示.其中朴素贝叶斯算法采用多项式朴素贝叶斯算法,其平滑参数设置为1.支持向量机算法采用径向基核函数,核带宽设置为0.5,惩罚因子设置为1.BP算法采用3层神经网络设计,其输入神经元数量为100,输出神经元预测类别数量为3,包括正向评价、中性评价和负面评价.从表1结果可以看出,使用文本评价数据可以得到最高的分类精度,而使用视频和语音得到的评估精度相对较低.综合各初始分类器的预测结果后,可以得到精度更高的质量评价结果.由此表明,融合多模态数据可以提升质量评价的精度.

表1 各类预测结果的准确率和F1值Tab.1 Accuracy and F1 values of various prediction results
为了验证所提出自适应加权算法的有效性,对加权前后模型的分类精度进行测试,结果如图2所示.从图2中可以看出,采用加权算法不仅可以提升元分类器的性能,还可提升各初始分类器的性能,表明所提出的分类器加权方法能够明显提升预测精度.

图2 加权前后分类精度比较Fig.2 Comparison of classification accuracy before and after weighting
本文对于不同数据采用了不同的分类器,并使用元分类器集成所有分类器的预测结果.为了验证该多样性集成方法的有效性,将所提出的方法与仅采用单一分类器的方法进行比较,结果如图3所示.从图3中可以看出,所提出的多样性集成方法具有最优的分类精度,且相对于仅使用单一分类器的方法有明显提升.根据不同数据的特点,选择不同的分类器将有助于提升质量评价的精度.
为了比较本文与传统算法性能间的差异,使用提出的数据集进行了验证实验,结果如表2所示.其中,文献[4]采用纯调查问卷的方式进行质量评价;文献[7]只使用文本特征提取的方法进行评价.从表2中可以看出,相比于传统的算法,本算法具有明显的性能优势.其中,文献[7]方法所使用的特征比较单一,而本文算法融合多模态的特征进行评价,说明使用多模态特征可以明显增强评价的精度.

图3 集成模型与初始分类器比较Fig.3 Comparison of ensemble model and initial classifier

表2 不同方法的性能比较Tab.2 Performance comparison of different methods
4 结 论
本文提出了一种基于多模态音视频融合的质量评价算法,该算法根据客观质量评价过程中产生的视频、音频和文本等多媒体数据对相关的具体情况进行分类.通过对不同模态数据提取不同的特征,并使用Stacking算法挖掘不同特征间的关联关系,从而预估出评价结果.以质量评价为例,搜集和整理了质量评价数据集,在该数据集上的测试结果表明,本文所提出的方法能有效提升评价精度.
