基于题目关联知识的试题难度预测研究
2022-05-11宋慧媛徐行健孟繁军
宋慧媛,徐行健,孟繁军
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
计算机技术的快速发展对高校教学管理提出了新挑战[1],在试题难度评估方面,传统方法有两类:一类是通过人工对试题进行预估[2],但存在个人倾向较强、难以保证客观性的不足;另一类是通过教育数据挖掘进行试题评估[3],利用学生作答记录对试题得分进行建模进而评估试题参数和学生能力。但学习者水平不同,依赖评估者的水平和对试题的认知程度,容易造成先验知识的依赖[4]。深度学习与考试的深度融合,改善了试题质量评估的方法,具有理论和实践意义。
因此,本文提出基于深度神经网络模型,利用试题文本信息的同时结合考生作答记录,建立试题文本信息和实际难度间的关联性,进而解决测试中试题难度参数的预估等问题。Huang 等[5]在标准考试中对英语阅读理解题进行难度预测,通过给定段落和试题推断试题正确答案,但无法直接应用于其他类型试题如单项选择题难度的预测。故本文以大学计算机基础单项选择题为例,提出一种基于题目关联知识的试题难度预测模型,自动预测选择题的难度,并通过大学计算机基础单项选择试题难度预测,验证该方法的准确性和有效性。
1 相关工作
1.1 教育心理学中的问题难度预测
经典测量理论CTT[6]是教育心理测量学理论的分支,利用心理测试和统计方法来测试题目的难度或考生的能力。胡子璇等[7]研究了试题因素与相应试题难度之间的关系,项目反应理论IRT 利用数学模型对人和问题的潜在特征(难度、区分度等)进行评估[8]。Rasch 是IRT 的一种概率模型[9],通过逻辑类函数和学生作答记录等反馈信息来评估试题的难度,但这些模型的共同局限性在于过度依赖于评估者自身的认知水平和对试题的认知程度,使得预测结果的客观性、准确性精度较低。
1.2 自然语言处理领域中的难度预测
目前已有众多研究工作使用自然语言处理方法(NLP)来预测问题的难度[10]。Loukina 等[11]研究了基于多个文本的复杂性特征系统,利用单词的不熟悉性和较长语句的平均频率可以预测试题的难度。朱永强[12]利用文本挖掘方法分析文本词法、语义特征等,但需要手工设计文本特征,只限于特定的一些模型结构。佟威等[13]针对数学试题,利用题面分析、试题题干和选项进行难度预测。基于CNN、RNN 的体系结果对文本信息进行表示,通过对文档、试题题干及选项的语义表示全连接进而得到难度。在阅读理解试题、数学试题中,问题的答案可从给定段落中推断得出,意味着给定的段落对于难度预测的解决至关重要,但其难度预测模型都不可直接应用于一般单项选择题中。为解决这类模型的局限性,本文提出一种基于题目关联知识的试题难度预测模型(MR-ABNN),对题目关联知识信息文本摘要的抽取来丰富试题题干背景知识,利用神经网络模型挖掘试题文本信息并建模,输入试题特征到模型中可得到试题的难度预测值。
2 MR-ABNN 框架
2.1 问题定义
在所学科目中,计算机基础试题形式较为简洁,设问方式也较为单一,最符合本文模型对试题形式的要求。表1 为一道计算机基础试题文本实例,数据包括试题ID,题目信息、选项和答案。输入到模型的数据需为真实有效的试题和考生作答记录,试题可从随堂测验、期末试题及月考中获得。让Q表示一组计算机基础试题,每个Q∈Q 都有一个难度属性P值,一个正确答案A和3 个干扰选项(C1,C2,C3)。问题定义在形式上,给定试题集Q,目标是利用所有的问题Q∈Q 训练模型MR-ABNN,来预估试题的难度值。表2 为考生作答记录实例,每条记录代表每个考生在一场考试中对于某一道题的得分。传统方法中试卷难度系数[14]用来表现试题的难易程度,难度系数越大,试题得分率越高,难度也就越小。
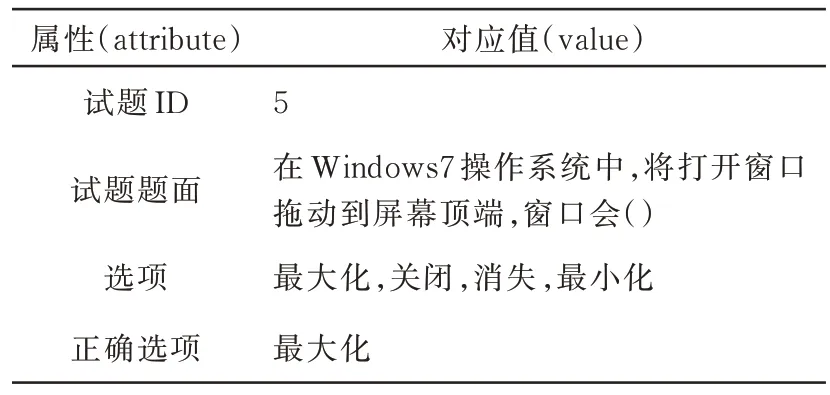
表1 计算机基础试题文本实例Tab.1 Computer basic test text examples

表2 考生作答记录实例Tab.2 Example of answer record of candidates
2.2 模型整体框架
MR-ABNN 共包括三个模块,如图1 所示。首先是题目关联知识的抽取模块,利用抽取式自动文本摘要抽取方法,通过对试题所属各部分章节内容进行抽取,获得与试题关联的信息,丰富试题的上下文知识;其次是基于神经网络的试题难度预测模块,依据所获得的试题、考生作答记录信息,通过文本建模挖掘试题文本理解中蕴含的局部重点词句与试题难度的关联,进行试题难度的预测,同时以该题获得的实际得分率作为对比标签输入到该模型中训练;最后是测试模块,经训练后得到基于题目关联知识点的试题难度预测模型,将未经测试过的试题输入到该模型中,验证其难度预测值的准确性。
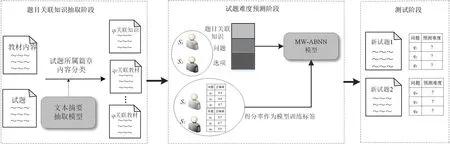
图1 模型整体框架Fig.1 Overall framework of the model
2.3 模型结构
2.3.1 题目关联知识信息抽取 MR-ABNN 主要有两个部分组成,第一部分是基于最大边界相关度的抽取式文本摘要模块,为丰富试题的上下文知识,利用词嵌入、句嵌入的方法将文本以向量表征的方式进行表示,通过计算句子间相似度、关键词与位置信息对句子重要性的影响,使句子按照得分高低排序,从而得到试题相关篇章内容的高质量摘要。
(1)数据预处理,指对试题所属篇章内容文本数据的处理。本文选取的是大学计算机基础一的教材内容数据,需要进行数据整理,包括对缺失值的处理和冗余信息的删除,除去一些无用的符号、空格等,保存成.txt 格式。
(2)特征提取,主要包括三部分。首先,关键词提取主要是利用TF-IDF 算法[15]提取得出,对文章中的词做词性标注且取得TF-IDF 值并排序,值越高,作为关键词的可能性越大;其次,句子的位置信息是指在段落中开头或结尾的句子,作为总结性的语句可大体代表文章的总体文义。由于对试题所属章节内容进行整合,没有分段,故只考虑位置信息在段首还是段尾;最后,句子向量表示,提取句子表征,计算句子与文章的相似度值,来获取更能表示文章主旨的语句。通过词嵌入思想获取单词的词向量,利用Word2vec 算法[16]训练词向量,得到句子中词语的向量表征,如公式(1)

其中:j表示文本中第j个语句,i为第j语句的第i个词语;wji为第j个语句中第i个词的词向量,m为第j个语句的长度。
(3)句子打分,首先对句子关键词打分,关键词在句子中出现频率越高,句子在文档中重要性越高,如公式(2)

其中:j为第j个语句,N(k)指第j个语句中关键词的个数;max[N(k)]为语句中包含关键词数最多的关键词数。
然后是对语句位置信息打分,考虑语句在段首还是段尾,如公式(3)

最后计算语句与篇章的相似度,相似度得分越高,该语句越能代表该段落的总体语义,如公式(4)

其中:Vj指语句的向量表示,由句子中词向量取均值可得;为篇章除第j句后其他语句的词向量的均值向量,计算二者余弦相似度S得到语句与篇章的相似度得分。获得句子关键词、语句位置信息及语句与篇章的相似度得分后,取其平均值得最终得分。
(4)关联知识信息文本摘要抽取,得到句子总分之后,基于得分对篇章中全部语句进行排序,得到每次循环的候选语句。为选取冗余性低、重要性高且全面、包含更多信息的语句,选取了最大边界相关度算法(MMR)。在候选语句中每次选取句子时都计算其MMR 分数[17],如公式(5)

其中:R(Vj)为MMR 得分;Cj为第j个语句的得分;S1为语句Vj和当前摘要V' 的余弦相似度,相似度值越大,表示该语句与当前摘要相似度越高;η为调节参数。
MMR 算法通过计算候选语句中每个语句的MMR 得分,按照得分从大到小排序,得分最高者加入当前摘要中,更新当前摘要的长度,同时候选语句集进行更新。最后判断当前摘要长度如果大于设定的长度,则得到最终关联知识信息文本摘要。
2.3.2 基于神经网络的试题难度预测 第二部分是融合注意力机制的双向循环神经网络,该模型一共包括四层模型结构,有输入层、双向循环神经网络层、注意力层和预测层,如图2 所示。
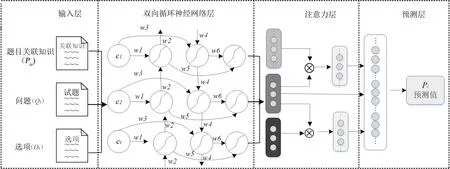
图2 试题难度的模型结构Fig.2 Model structure diagram of test difficulty
(1)输入层,该神经网络的输入是试题Qi的所有文本材料,包括文本摘要抽取得到的题目关联知识文本Pai,问题Qi及选项Oi。Pai表示文本词语的序列,即Pai={e0,e1,…,eN-1},N为词语表征个数。同样问题Qi及选项Oi也都利用word2vec 进行预训练,得到每个词语对应的d0=200 维的词向量。全部文本信息得到向量表征后输入到融合注意力机制的双向循环神经网络中获取语义理解。
(2)双向循环神经网络层,由于RNN 存在长距离依赖问题[18],需在RNN 中加入LSTM 单元,但RNN和LSTM 都只依据之前的时序信息预测下一时刻的输出,为联合上下文信息进行准确预测,本文采用两个LSTM 也就是Bi-LSTM,前向LSTM 网络负责获取前面时序信息,后向LSTM 负责获取后向序列信息,从正向、反向两方向学习试题语义逻辑,捕捉更多文本信息。
该层的输入序列为Eemb={e0,e1,…,eN-1},首先将文本序列中的e0,e1,…,eN-1分别在t0,t1,t2,…,tn时刻逐次输入Bi-LSTM 中,并且所有作为输入信息的词语都经过向量化表示,其中wi,i=1,2,…,6 表示为权值。假如在待标注序列的某个位置i,正向LSTM 得到隐层输出为,反向LSTM 则得到,则可认为获取了位置i前的历史信息获取了位置i后的未来信息,最后隐层输出为,其中⊕表示将两个向量链接起来,将hi从输出层中输出。
(3)注意力层,从Bi-LSTM 层获得语句的向量表示后,加入注意力机制计算问题的难度注意力表示。注意力权重表示句子对于决定试题难度的重要程度,得到篇章hP和hQ后,注意力层计算机出一个篇章单词和一个试题单词的成对匹配矩阵M,如公式(6)

当给出段落的第i个单词和问题的第j个单词时,注意力机制可对其进行点积来得到匹配分数,通过对M中每列用softmax 函数获取其概率分布,且每一列都表示单独的篇章级注意力,A1(Pan)表示第n个单词的篇章注意力,A2(Qn)表示第n个单词的问题注意力,如公式(7)和(8)

在获得试题对文本、文本对试题的注意力之后,计算二者的点积,将每个试题单词的重要性程度可视化,输出最终的文章级注意力向量A(Pai),用来衡量文章Pai中单词en的重要性,如公式(9)

同理问题Qi、选项Oi的注意力权重也可以上述方式建模。通过加入注意力机制有助于计算与试题更相关的段落或选项中词语的分数,有助于提升模型的准确性。
(4)预测层,在这一层中,使用文章注意力向量Pai,选项注意力向量Oi和试题Qi,预估试题qi的难度,将以上三个向量进行拼接,利用全连接层获取难度表示θi,使用Sigmoid 函数预估试题难度,如公式(10)和(11)

其中w1,b1,w2,b2为网络中可调整的参数。
3 模型验证实验
3.1 实验环境及数据集处理
本次实验使用Intel i5-10210U CPU@1.60 GHz 的实验环境,操作系统为Window7,利用Pycharm 中Anaconda3 与TensorFlow 框架。
实验中数据集为高校大学计算机基础一的期末考试试题、随堂测验试题和考生作答记录,其中每条数据都包括试题关联知识内容、问题、选项(正确选项、错误选项)及试题实际难度。实验数据集共包括21 000 条答题记录,由600 多名学生作答,有330 道不同试题。由于数据集在整理过程中受到人为因素或其他客观因素的影响,为保证数据的合理性,避免对预测结果产生影响,需对原始数据集进行清理,去除缺失值、冗余信息及具有干扰性的数据,表3 为大学计算机基础试题部分数据集示例。

表3 大学计算机基础试题部分数据集示例Tab.3 Examples of some data sets of basic examination questions of university computer.
3.2 对比实验
为验证本研究提出模型(MR-ABNN)的效果,选取下述几种基线预测算法做对比。
(1)支持向量机(SVM)[19]:SVM 使用核函数向高维空间进行映射,使用分类与回归分析来分析数据的监督学习模型,但对缺失数据、参数和核参数的选择较为敏感。
(2)决策树(DT)[20]:DT 是递归地选择最优特征,对应于模型的局部最优,但适合高维数据,信息增益偏向于更多数值的特征,易忽略属性之间的相关性。
(3)逻辑回归(LR)[21]:LR 建立代价函数,通过优化迭代求解出最优的模型参数,但在处理大量多类特征或变量时具有局限性。
(4)RNN+Attention(ARNN)[5]:ARNN 可从提取向量表征的角度挖掘文本材料,获取段落的语义信息,但由于缺乏题目关联知识无法直接应用于单项选择试题难度预测的应用场景。
3.3 评价指标
为衡量MR-ABNN 模型的性能,本文利用较为广泛使用的均方根误差(RMSE)[22]、皮尔逊相关系数(PCC)[23]和决定系数R2[24]来进行评价。RMSE 的取值范围在[0,+∞),数值越小意味着预测难度与实际难度的差值越小,说明预测准确度越高。PCC 取值范围为[-1,1],绝对值越大表明试题预测难度与实际难度线性相关性越高。R2的取值范围为[0,1],数值越大表明预测难度与实际难度越接近。
3.4 实验结果及分析
为观察模型在不同数据集大小的效果,随机选取40%、60%、80% 到90% 的训练集进行测试。同时,为防止过拟合,确保试题为未经过测验的新试题且测试集与训练集试题之间没有重叠,MR-ABNN 模型的实验结果见表4。

表4 各模型在难度预测任务上的效果对比Tab.4 Comparison of effects of each model on difficulty prediction tasks
(1)SVM、DT 及LR 为三种机器学习模型,SVM 回归效果最差,DT 和LR 模型回归效果较SVM 更好,可知一般的回归模型并不能很好地进行试题难度预测任务;ARNN、MRABNN 神经网络模型的实验结果明显优于前三种回归模型,说明神经网络对试题难度预测可以更好地建模。
(2)ARNN 为神经网络模型,加入注意力机制的Bi-LSTM 循环神经网络不仅可以度量计算机基础知识资料中知识点对试题的重要程度,提高模型对试题与其相关语句表征的关注程度,还解决了RNN 中长序列依赖问题和梯度消失问题。同时基于题目关联知识的试题难度预测模型MR-ABNN 在利用文本信息摘要抽取方法,获取与问题关联的文本信息来丰富题干的上下文知识后,与ARNN 的性能效果相比具体大幅度提升。
(3)ARNN、MR-ABNN 两种神经网络模型效果随训练数据量比例的增加得到提升。将训练数据量增加到60% 时,MR-ABNN 的性能优于其他方法,RMSE、PCC、R2值可达到0.19、0.67、0.46 以上;在训练集的比例达到90% 时,MR-ABNN 模型的PCC、R2值达到最高,分别达到0.75、0.53 以上,RMSE 值达到最低0.14 左右。故可以得出,在实际大学计算机基础一考试中,MR-ABNN 能够以更强的能力捕获更多的语义信息,且数据量足够满足模型要求时,试题难度预测任务完成度可达到最优。
4 结语
本文提出一种基于题目关联知识的试题难度预测模型MR-ABNN,用于考试中单项选择题难度的自动预测。模型MR-ABNN 首先构建题目关联文本信息摘要的抽取模型,用于丰富题干的上下文知识,解决单项选择题没有背景知识支撑的问题,然后基于加入注意力机制的双向循环神经网络模型实现试题难度的自动评估。在真实测试数据集上的实验结果表明该模型的优越性和有效性。目前,只在计算机基础选择题考试中应用MR-ABNN,如果其他科目或领域也有对应的教材内容和真实考试记录,也可用该模型进行试题难度的预测。在未来研究中还可考虑针对不同类型试题、不同学科设计精度更为准确地难度自动评估模型。
