基于透视降采样和神经网络的地面标志检测
2022-05-09李玉珍
李玉珍,陈 辉,王 杰,荣 文
基于透视降采样和神经网络的地面标志检测
李玉珍1,陈 辉1,王 杰1,荣 文2
(1. 山东大学信息科学与工程学院,山东 青岛 266237;2. 山东高速信息集团有限公司,山东 济南 250000)
在智能驾驶领域,为实时精确检测路面的导向标志,提出一种基于透视降采样和神经网络的地标检测方法,有效解决传统检测方法实时性较差、复杂场景和远处小目标检测准确率较低的问题。首先,选取图像感兴趣区域进行透视降采样,降低道路图像近处分辨率,缩小图像尺寸,同时消除透视投影误差。其次对YOLOv3-tiny目标检测网络进行改进,采用k-means++算法对自建数据集的边界框聚类;添加卷积层强化浅层特征,提升小目标表征能力;改变特征金字塔融合尺度,将预测输出调整为适合地标尺寸的26×26和52×52。最后,在自建多场景数据集上测试,准确率由78%提升到99%,模型大小由33.8 MB减小为8.3 MB。结果表明,基于透视降采样和神经网络的地标检测方法鲁棒性强,对小目标检测精度更高,易于在低端嵌入式设备上部署。
透视降采样;YOLOv3-tiny;地标检测;数据集;k-means++
自动驾驶和智能辅助驾驶技术作为当今热门的研究领域,一直是国内外学者研究的热点。地面交通标志检测作为自动驾驶研究的关键技术之一,主要包含车道线检测和地面转向标志检测。目前,针对车道线识别技术的研究较多,地面转向标志识别的研究较少。地面标志检测能实时精确定位和识别车道上的导向标志,在智能驾驶情况下对道路环境进行感知,帮助驾驶员或智能驾驶系统正确、安全地行驶。路面各种箭头、字母等包含重要的交通指示信息,对道路场景的理解有重要的作用。驾驶员可能因树影遮挡、光照变化等情况未注意地面标志,或不了解某个地标的具体含义等情况,导致严重的交通事故,影响正常交通秩序。
在地面标志检测方面,目前常用的检测方法可分为以下3类:
(1) 基于传统二值化方法。REBUT等[1]使用全局二值化和用于箭头标记的形态算子产生道路标志候选区域,通过傅里叶算子和K最近邻算法识别标志,对目标轮廓完整性要求较高,对损坏或遮挡标志检测效果不理想;FOUCHER等[2]利用局部阈值提取边缘,并通过汉明距离和基于投影的直方图图像比较来分类,涉及阈值数量多,真实检测率低;WU和RANGANATHAN[3]选取道路图像中最大稳定的极值区域,从中检测到角作为模板特征,采用基于角特征的结构匹配识别转向标志,对阴影敏感、误报率高;LIU等[4]提出一种基于感兴趣区域(region of interest,ROI)透视变换的道路标记识别方法,通过逆透视变换(inverse perspective mapping,IPM)将梯形ROI转为正方形,利用模板匹配进行检测识别,对旋转、尺度变化等鲁棒性差;HE等[5]采用局部结合点特征实现了导向箭头的特征编码,采用编辑距离(edit distance)度量箭头相似性来分类识别,对遮挡和磨损标志的召回率较低。
(2) 基于机器学习支持向量机(support vector machine,SVM)的目标分类方法。随着机器学习的不断发展,AdaBoost[6]和SVM[7]被应用于地面导向标志识别中。WANG等[8]采用IPM预处理,小波函数提取特征,多层SVM进行导向箭头识别。QIN等[9]采用局部和全局二值化生成识别候选区域,基于具有轮廓特征的多分类SVM对地标分类。SCHREIBER等[10]利用分水岭分割算法二值化图像,利用基于SVM和光学字符识别(optical character recognition,OCR)对地面标志分类。
(3) 基于神经网络的地面标志检测算法。神经网络是近年来国内外学者的研究热点,GIRSHICK等[11]将卷积神经网络(convolutional neural networks,CNN)与候选框相结合,提出了基于卷积神经网络特征区域 (regions with CNN features,R-CNN)的目标检测和图像分割的方法,为提高效率,又引入空间金字塔池化网络[12]。REN等[13]在Faster R-CNN加入区域候选网络(region proposal networks,RPN),将全图像卷积特征进行共享,提高了GPU上的检测速度。两阶段神经网络检测精度较高,但实时性较差。
现有的地面导向标志识别方法中,多数研究都是基于传统的二值化方法和机器学习中的SVM,实时性不高,遇到标志模糊、光照变化、阴影遮挡等情况,识别的准确率大幅降低。针对上述问题,为了提高检测鲁棒性,本文将YOLO (you only look once)[14]算法应用于地面标志检测中,提出一种基于透视降采样和神经网络的地标检测算法,适用于城市及高速公路等场景。以YOLOv3-tiny算法为基础,利用k-means++算法[15]选择最佳先验框尺寸,强化浅层信息,更改特征金字塔网络(feature pyramid networks,FPN)融合尺度,提高算法鲁棒性和小标志的表征能力。实验结果表明,本文算法兼顾精度和速度,可以在嵌入式设备上灵活部署。
1 YOLO基本原理
1.1 检测原理
YOLO是一种采用CNN实现端到端目标检测的算法。与传统基于候选框的方法不同,其直接将整幅图输入网络训练模型,将目标检测看作回归问题,采用滑动窗口的方式寻找目标中心位置,能够实时预测多个目标的类别和位置。YOLO网络借鉴了GoogLeNet[16]分类网络结构。首先将输入图像划分为×个网格,若目标物体的中心位置落入其中,则这个网格负责预测该目标。每个网格将输出分类置信度和位置边框,YOLO检测原理如图1所示。因此,输入图像只经过一次检测,就能得到图像中所有物体的位置及其所属类别的置信度,即每个边界框中包含物体的概率为
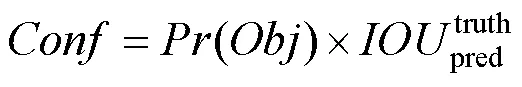
其中,为置信度评分;()为边界框含有目标的可能性;truth为实际标注的边界框面积;pred为预测的边界框面积;为交并比,代表truth和pred的交集与并集的比值。对结果预测时,由条件类别概率和目标置信度乘积得到类别的置信度,即
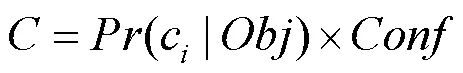
其中,为边界框类别的置信度,代表该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏程度;(c|)为该单元格存在物体且属于第类的概率;c为目标种类中的第个类别。最后利用非极大值抑制(non-maximum suppression,NMS),去掉冗余预测窗口,得到置信度最高的预测窗口,即为检测结果。
1.2 YOLOv3-tiny算法介绍
YOLOv3-tiny网络是YOLOv3网络[17]的简化版,使用较少的卷积层和池化层进行特征提取,未使用Darknet-53中的残差模块。其具有相对较高的检测速度,但识别精度不高,对复杂场景的检测能力较低。
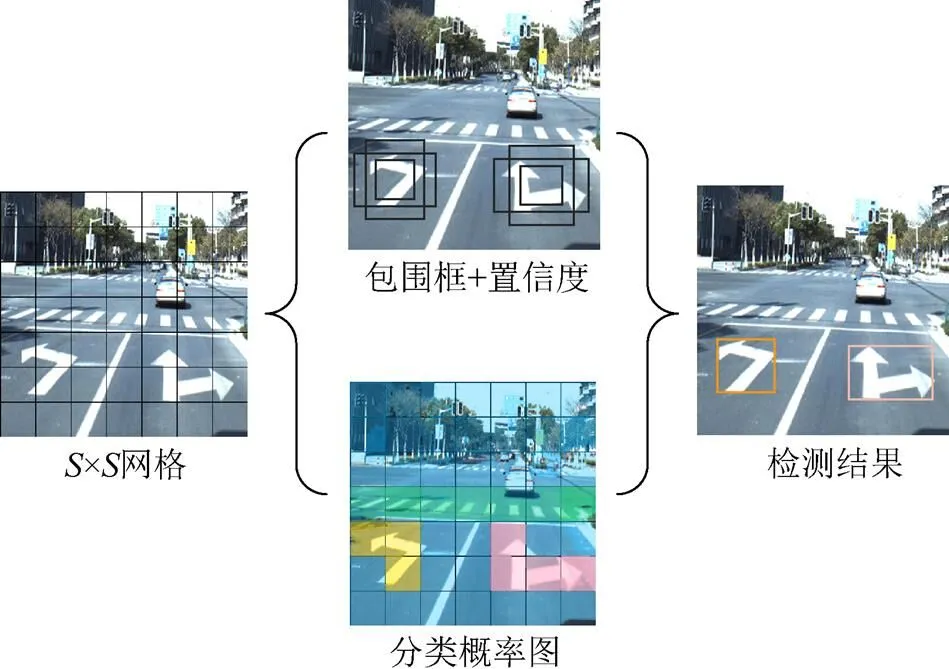
图1 YOLO原理图
YOLOv3-tiny包含24个网络层,分别是13个卷积层(convolutional)、6个池化层(maxpool)、2个路由层(route)、2个输出层(yolo)和1个上采样层(upsample)。主干网络采用卷积层和池化层串联结构,骨干网络类似于YOLOv2[18]中的Darknet-19网络,由1×1和3×3大小的卷积核提取特征,采用FPN[19],融合输出了2个13×13和26×26尺度的特征信息,输出通道直接得到包含目标框的坐标(,,,)和目标置信度。YOLOv3-tiny的网络结构框架如图2所示。
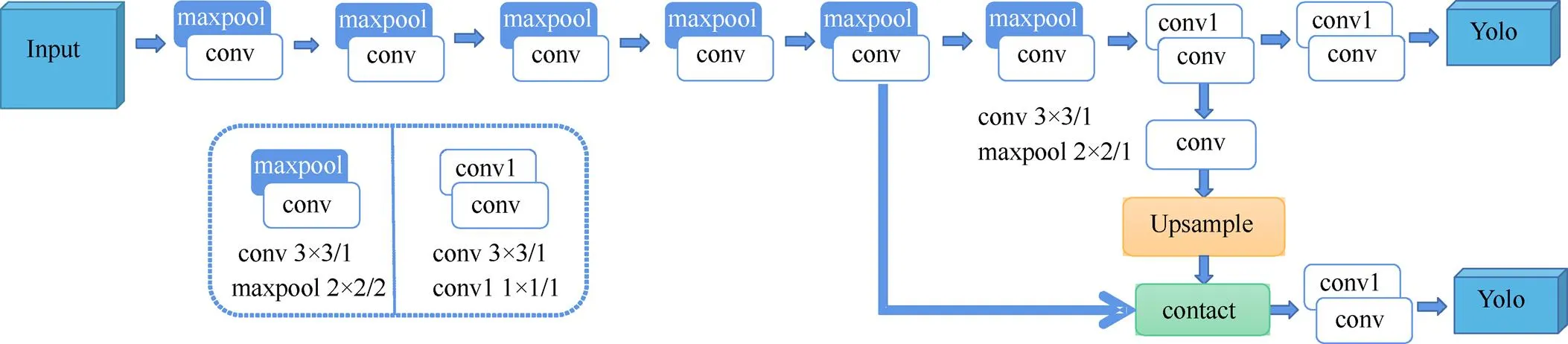
图2 YOLOv3-tiny网络框架
2 实时地标检测框架搭建
2.1 数据集制作
地面较为常见的标志有导向箭头和限速标志等,本文以导向箭头标志为主,主要研究5类常见的标志,分别为直行或右转、直行或左转、直行、左转、右转。
目前,针对地面交通标志的研究较少,没有公开的数据集。本文首先构建了一个可用于深度学习训练和测试的地面标志数据集,一部分数据来自济青高速、山东大学青岛校区周边的车载相机数据,另一部分来自百度阿波罗公开道路数据集中带有地标的部分,使用LabelImg标注制作22 000余张数据。为降低数据集冗余度,每隔5帧抽取1张图片作为数据集样本,最终得到4 311张图片的数据集,包含不同城市的不同场景。数据集满足Pascal VOC数据集格式,按照7∶2∶1比例将数据集分为训练集、测试集和验证集。Landmark数据集统计见表1。
为了简洁直观地显示类别,用SorR,SorL,S,L和R分别表示直行或右转、直行或左转、直行、左转、右转。
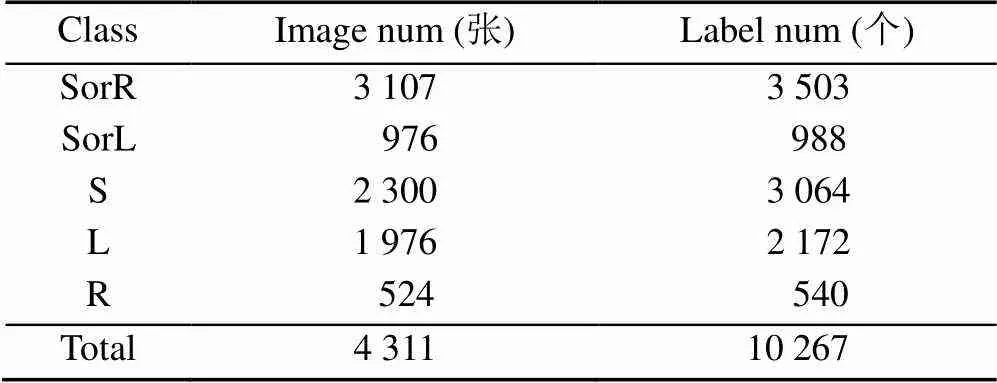
表1 Landmark数据集统计表
2.2 透视降采样
数据集图片尺寸为2700×2400和1920×1080,使用原图训练速度慢,训练特征图感受野较大,不适宜检测小目标。为了在嵌入式系统中进行实时目标检测,将图像导入低端设备时,首先将图像进行降采样操作,降低图像分辨率,加速训练。普通降采样对大小为×的图片进行倍缩放,原始图片变为(/)×(/),原始图像中每×的像素点转化为降采样图片中的一个像素点。经过数倍普通降采样后,有效像素较少的目标特征不明显,甚至整个目标丢失。
车载相机采集的图像存在较强透视效应,且多为复杂场景下的数据,涵盖大量车辆、行人、建筑物等复杂信息。为消除透视投影误差,可对透视图进行IPM,以减少无关信息对模型性能的影响。原IPM模型直接对整张道路图像进行变换,虽对远处的小目标分辨率影响较小,但生成的俯视图呈“下窄上宽”的倒梯形,保留了很多地标之外的干扰信息,转向标志占俯视图的比重较小,且被限制在俯视图的中央区域,效果如图3所示。

图3 逆透视变换(2700×350)
转向标志特征简单,近处大目标所在区域像素冗余。为满足实际需求,缩小图像尺寸,同时消除透视投影误差,本文提出一种透视降采样方法,结合IPM和普通降采样,将划定的梯形ROI区域投影在目标图像上。首先选取合适的ROI区域,根据ROI区域坐标和目标图像坐标计算出变换矩阵,即可对图像进行透视降采样变换。目标图像由远及近按比例进行降采样,远处小目标的分辨率基本不变,近处在保留原图信息的条件下降低图像分辨率。其计算公式为
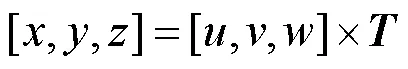
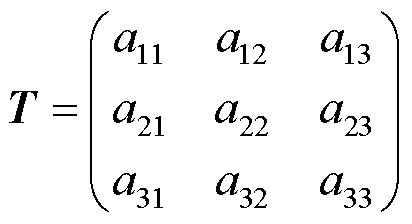
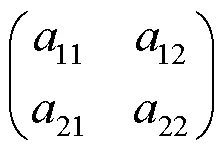

图4 远近目标结果对比图((a)真实图像;(b)普通降采样;(c)透视降采样)
图4(a)为真实图像和真实图像中红色方框区域的局部放大图,图4(b)和(c)分别为普通降采样、透视降采样到400×350的效果图。对比图4(a)和(b)可以看出,使用普通降采样将整张图像分辨率均匀降低后,图4(b)中近处大目标分辨率相比图4(a)降低,轮廓仍可见,不影响辨识目标类别,但远处小目标明显模糊,无法辨识目标轮廓和类别。图4(c)使用透视降采样,不仅保证远处小目标分辨率与原图4(a)中基本相同,还提高了小目标在整张图像中的占比,更易于检测;近处大目标的分辨率降低,与图4(b)中近处大目标的处理效果类似。即透视降采样方法主要依靠降低近处分辨率来缩小图像尺寸,基本不会影响远处小目标的分辨率。与原图像相比,透视降采样后的图像具有3个优点:①基本消除地标的透视形变影响;②缩小图片尺寸,提升模型计算速度;③划定ROI,减少路面之外的干扰信息,增强小目标特征信息。
2.3 改进YOLOv3-tiny网络结构
本文检测目标是5类转向标志,特征简单,选择计算量低、速度快的YOLOv3-tiny作为基准网络。由1.2节可知,其精度较低,本文通过改进YOLOv3-tiny网络结构,提出适合地面转向标志检测的改进YOLOv3-tiny,因改进后包含12个卷积层,本文将其简记为YOLOv3-tiny-12,网络结构如图5所示。
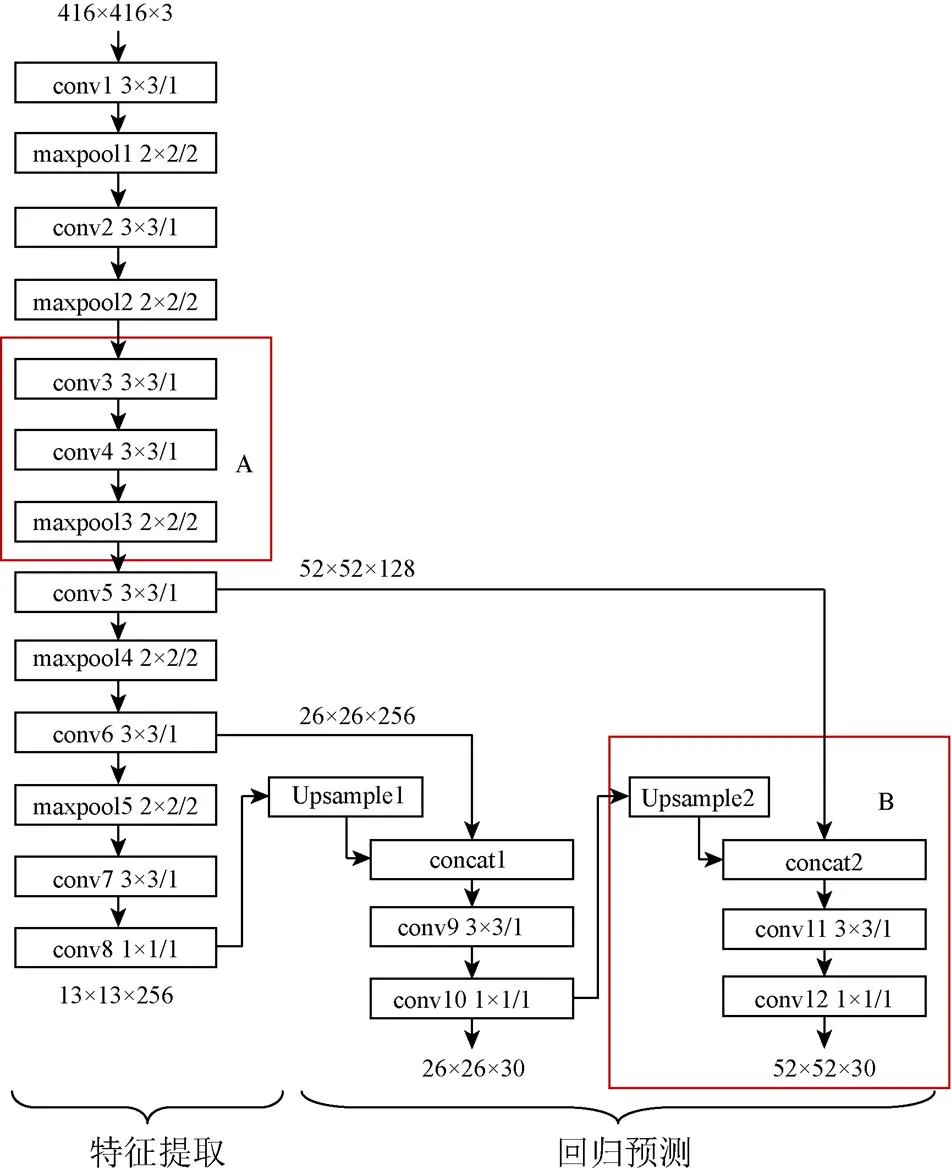
图5 YOLOv3-tiny-12网络结构
YOLOv3-tiny-12网络主要分为特征提取和回归预测。前者由卷积层和池化层组成,后者用于预测目标的边界框坐标和类别概率。根据地面转向标志特点,本文改进主要分为3部分:①计算自建数据集的聚类中心,更新网络中每个簇对应的先验框值;②添加卷积层对浅层信息进行强化重构,增强图像细粒度特征的提取;③根据目标近大远小透视特点,采用FPN实现不同分辨率的特征融合,提高网络对不同尺寸目标的检测性能。
2.3.1 基于自建数据集的边界框聚类
YOLOv3-tiny网络中使用先验框参数,训练时加入先验锚框尺寸,对预测对象范围进行约束,有助于模型加速收敛。先验框是根据训练集中的真实框(ground truth)聚类得到的不同尺寸框,在模型中即为尺度不同的滑动窗口。原始网络中的先验框由k-means算法对COCO数据集[20]聚类得到,划分了6个簇分别对应2个尺度。由于COCO数据集中不含与地标相关数据,原始先验框参数不能与地标尺寸对应,因此训练前对数据集标签进行聚类。考虑到k-means算法[21]选择初始聚类中心时有较大的随机性,为避免其随机选取初始聚类中心带来的聚类结果偏差,选用随机性更小的k-means++聚类代替k-means算法对图像标签进行聚类分析。
通过对数据集中标注框的宽和高进行聚类,得到6个聚类中心,设为初始先验框的宽和高,分别是(16,13),(28,29),(35,15),(35,87),(51,68),(69,99),聚类结果如图6所示。
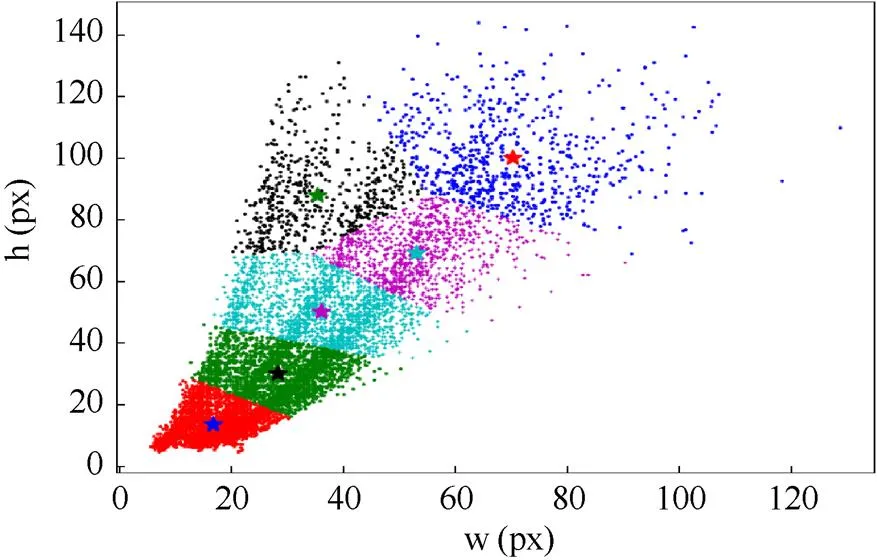
图6 数据集标注框聚类结果
2.3.2 增强浅层特征信息的提取
YOLOv3-tiny网络在特征提取过程中,由于串联式的卷积层、池化层结构,以及网络结构加深,感受野增大,导致复杂的背景特征增加,小目标特征减少。
对于CNN,不同深度的卷积层对应不同层次的特征信息。浅层网络包含更多小目标的边缘、纹理等信息。为了有效利用浅层特征,本文在网络特征提取部分强化浅层信息,增强对第3个串联式卷积池化层的特征提取效果,将maxpool层改为conv4层,卷积步长为1,不改变通道维度和特征图尺寸,在conv4层后添加maxpool层,步长为2,改变特征图尺寸,如图5红色标注框A所示。改进后既满足深层的语义信息区分目标和背景特征,也增加浅层特征图感受野,提高远处小目标检测精度。
2.3.3 基于特征金字塔的多尺度融合
YOLOv3网络允许输入不同尺寸的输入图像,如608×608,416×416等。原网络默认将不同长宽的图像统一调整分辨率为416×416,保证图像经过卷积、池化和特征融合等处理后,得到13×13和26×26尺度的特征图。此特征图有部分信息损失,满足对大目标的检测,但对小目标准确检测需要更细粒度的特征。因低层网络具有更高的分辨率和更详细的特征信息,故本文根据边界框聚类结果和先验框(表2),调整特征金字塔输出尺度为26×26和52×52,将小尺度的先验边界框分配给52×52特征图。YOLOv3-tiny-12中使用的金字塔结构如图7所示。

表2 先验框表
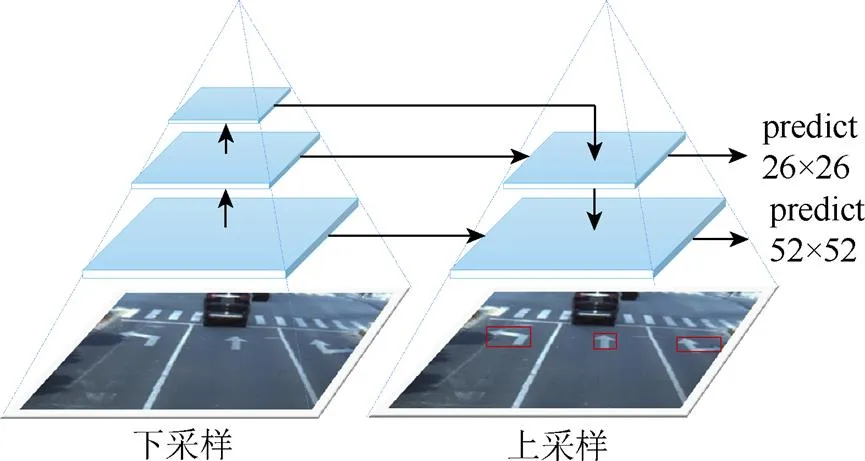
图7 特征金字塔
先验框(anchor)即在图像上预先设定不同大小、不同长宽比例的框。网络设置合适的先验框尺度,可更高概率地出现对目标有高匹配度的先验框,体现为高IOU。先验框尺寸一般都是经验选取或k-means聚类得到,YOLOv2中介绍,网络是通过k-means聚类代替人工经验选取,对训练集中的bounding box进行聚类,生成一组更适合数据集的先验框,使得先验框与数据集目标的匹配度更高,网络的检测结果更好。
增加的52×52尺度特征图融合conv5卷积层,如图5红色标注框B所示,将高层语义信息和浅层细节信息融合,通过更小的预选框提高小目标的检测精度,平衡不同尺度的地面标志。
3 实验结果及分析
3.1 实验配置
本文基于深度学习Darknet框架对数据进行训练和评估,实验操作系统为Ubuntu18.04.2,处理器为Intel Core i9-9900k,内存为64 G,使用的GPU型号为GeForce RTX 2080Ti。
3.2 实验结果
为了评价测试模型性能,本文主要选用平均精度均值(mean average precision,mAP)、平均耗时、运算量 (billion float operations,BFLOPs)和模型权重大小(size)作为评价指标。mAP用于评估算法检测的准确率;平均耗时主要用于评估算法的实时性能,表示处理每张图片消耗的时间(单位:ms),平均耗时越少,速度越快;BFLOPs描述算法进行卷积运算需要的十亿次浮点运算次数,表示算法的计算复杂度。部分指标为
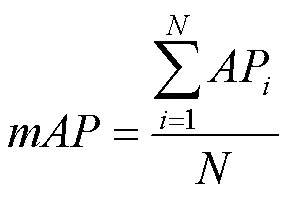
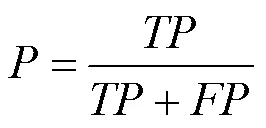
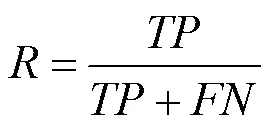
其中,为检测类别数;(Precision)和(Recall)分别为精确率和召回率;,,分别为正确分类的正例、负例错分为正例、正例错分为负例个数。
表3是YOLOv3-tiny与其他几种目标检测算法性能对比实验结果。
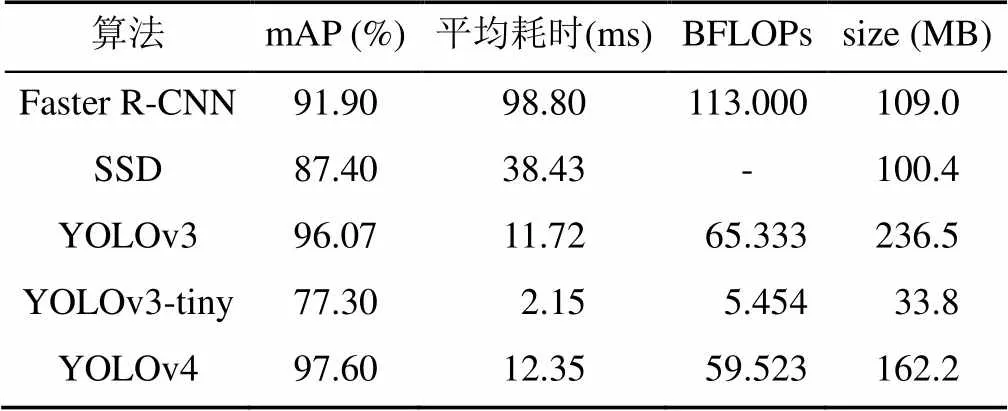
表3 不同检测算法性能对比
从表3数据可看出,使用原始图像进行训练测试时,YOLOv3-tiny算法检测每帧图片的平均耗时为2.15 ms,速度快于其他4类算法,计算复杂度降低10倍以上,模型体积缩小数倍,但是算法精度比Faster R-CNN,SSD[22]和YOLOv4[23]算法低,符合理论预期。Faster R-CNN的检测速度慢,计算复杂度是YOLOv3-tiny的20倍,且模型权重文件较大。综上,本文选取计算复杂度低、模型体积小的实时检测网络YOLOv3-tiny作为基准网络。
为进一步提升模型准确率,选取图像车前区域(12 m×60 m)为ROI,设定生成图像分辨率为400×350,对数据集进行透视降采样(perspective down-sampling,PD)。消除透视形变和目标近大远小对精度的影响,降低复杂场景对模型性能的干扰,在建立的数据集上使用YOLOv3-tiny验证,透视降采样前后的目标平均精度对比如图8所示。
图像进行透视降采样后,测试集上的mAP值为96.1%,相比原mAP值提高18.8%。其中右转R的AP最高,透视降采样后提升到99.84%,提升了16.32%。直行S透视降采样后平均精度提升25.37%,相比其他4类提升最大。但直行S最终的AP最低,为89.40%。结合数据集测试结果和类别形状分析,直行标志与斑马线、车道线虚线等交通标志的相似度程度较高,标志损坏或涂改后易错检,测试结果中一些正样本标志被判定为负样本,FN和FP偏高导致AP偏低。
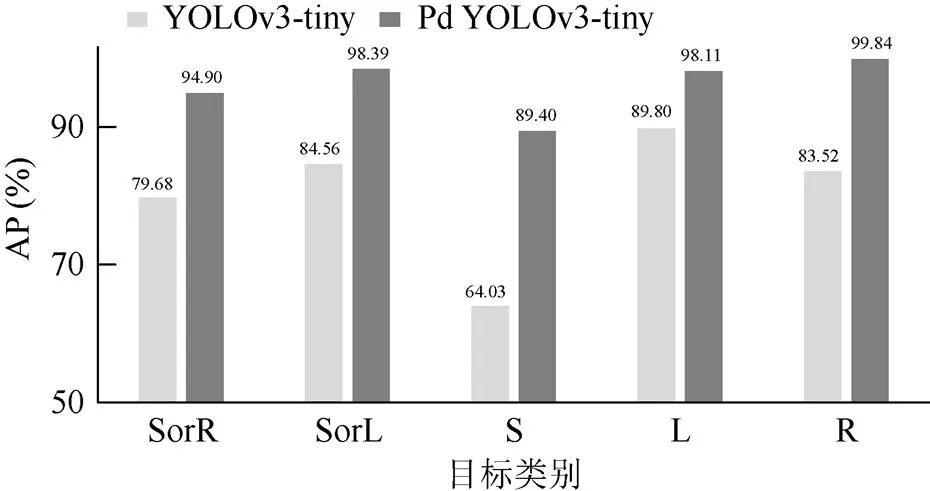
图8 透视降采样前后测试结果对比
本文对网络改进后,预测特征图的感受野减小,远处小目标的检测效果增强,mAP值提高了3.1%,处理每帧图片的平均耗时由2.11 ms缩短到1.89 ms,模型计算复杂度降低了7%。模型权重文件保存为训练的网络各层权值,由于网络层数减少为23层,卷积核个数、通道数等减少,及卷积核尺寸变小等因素,模型大小由33.8MB减小为8.3MB,占原模型权重的25%左右,适宜在嵌入式设备部署。原网络训练8 000个epochs用时约4.5 h,改进后训练时长仅需1.5 h。网络改进前后的速度和计算复杂度对比见表4,目标的平均精度测试结果见表5。
本文使用透视降采样后的图像进行模型训练,并使用YOLOv3-tiny和YOLOv3-tiny-12训练的最优权重测试,随机抽取不同场景、不同距离的测试图像结果对比如图9所示。

表4 速度和计算量对比
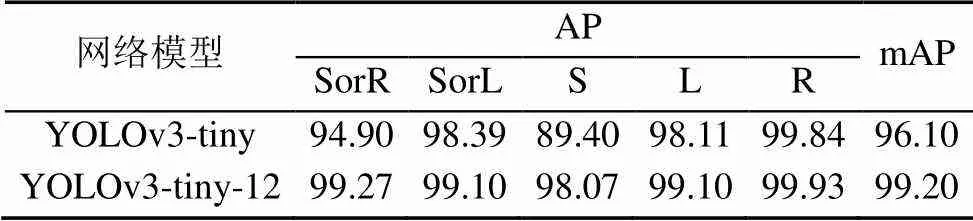
表5 测试结果对比(%)
由图9(a1)和(a2)可以看出,光线充足、路面状况良好的情况下,原网络可以较好地识别地面标志,但也存在较小目标漏检情况;改进后的网络预测尺度更适合小目标尺寸,检测精度更高,漏检情况较少。对于地面标志被树荫、建筑物阴影遮挡等情况,如图9(b1)和(b2),或由于长期磨损、涂改以及污染等情况,如图9(c1)和(c2),原网络检测精度有所下降,改进后网络的检测精度几乎不受影响。不同场景下的检测结果说明,通过对先验框尺寸进行重新聚类、增强浅层网络信息的提取等操作,网络的鲁棒性更强,更能适应多样的天气、光照和道路行驶环境等。
为进一步验证算法对远处小目标的准确率,采集不同距离的地标数据进行测试。车载相机距离地标的距离分别是5 m,25 m和50 m,部分测试结果如图9(d),(e)和(f)所示。从图中可以看出,采集距离为5 m和25 m时,如图9(d)和(e),由于目标尺寸较大,左转和前方直行或右转标志均被准确识别,且识别准确率接近100%。采集距离为50 m时,如图9(f1)和(f2),目标尺寸非常小,由于YOLOv3-tiny对浅层特征信息的提取不足,且预选框尺寸较大,目标识别准确率降低,图9(f1)中的直行或右转标志漏检。YOLOv3-tiny-12重新聚类了先验框的大小,使得预测时能更高概率的出现匹配度高的先验框,并且增强对浅层特征的提取,获得更多小目标的边缘、纹理等信息,使得小目标特征提取更充分,提高了检测精度。不同距离的测试结果表明,改进后的YOLOv3-tiny-12算法对小目标检测能力更强,预测尺度与小目标尺寸更匹配,在一定距离范围内,检测精度更高。

图9 YOLOv3-tiny与YOLOv3-tiny-12测试结果对比((a~c)不同场景对比; (d~f)不同距离对比)
4 结束语
本文为提高复杂场景的鲁棒性和小目标检测的精度,提出一种基于透视降采样和YOLOv3-tiny-12的地标检测方法。选取道路图像ROI进行透视降采样,减少了无关信息对模型的影响,缩小图像尺寸的同时不改变远处小目标的分辨率,提高了训练速度。改进YOLOv3-tiny算法,增加卷积层强化浅层信息,采用金字塔结构将预测尺度调整为适应地标的尺寸。通过平均精度均值、平均耗时和权重大小等对模型的性能进行了评估,在保证实时性的前提下,改进后的检测精度为99.2%,提升了21.9%,模型权重8.3 MB,易于在低端嵌入式设备上部署。
[1] REBUT J, BENSRHAIR A, TOULMINET G. Image segmentation and pattern recognition for road marking analysis[C]//2004 IEEE International Symposium on Industrial Electronics. New York: IEEE Press, 2004: 727-732.
[2] FOUCHER P, SEBSADJI Y, TAREL J P, et al. Detection and recognition of urban road markings using images[C]//2011 14th International IEEE Conference on Intelligent Transportation Systems. New York: IEEE Press, 2011: 1747-1752.
[3] WU T, RANGANATHAN A. A practical system for road marking detection and recognition[C]//2012 IEEE Intelligent Vehicles Symposium. New York: IEEE Press, 2012: 25-30.
[4] LIU Z Q, WANG S J, DING X Q. ROI perspective transform based road marking detection and recognition[C]//2012 International Conference on Audio, Language and Image Processing. New York: IEEE Press, 2012: 841-846.
[5] HE U, CHEN H, PAN I, et al. Using edit distance and junction feature to detect and recognize arrow road marking[C]//The 17th International IEEE Conference on Intelligent Transportation Systems. New York: IEEE Press, 2014: 2317-2323.
[6] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[7] CORTES C, VAPNIK V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273-297.
[8] WANG N, LIU W, ZHANG C M, et al. The detection and recognition of arrow markings recognition based on monocular vision[C]//2009 Chinese Control and Decision Conference. New York: IEEE Press, 2009: 4380-4386.
[9] QIN B, LIU W, SHEN X, et al. A general framework for road marking detection and analysis[C]//The 16th International IEEE Conference on Intelligent Transportation Systems. New York: IEEE Press, 2013: 619-625.
[10] SCHREIBER M, POGGENHANS F, STILLER C. Detecting symbols on road surface for mapping and localization using OCR[C]//The 17th International IEEE Conference on Intelligent Transportation Systems. New York: IEEE Press, 2014: 597-602.
[11] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[12] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[13] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[14] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 779-788.
[15] Arthur D, Vassilvitskii S. K-means++: the advantages of careful seeding[C]//The 18th Annual ACM-SIAM symposium on Discrete Algorithms. New York: ACM Press, 2007: 1027-1035.
[16] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 1-9.
[17] REDMON J, FARHADI A. YOLOv3: an incremental improvement[C]//IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 1-4.
[18] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6517-6525.
[19] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[20] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[M]//Computer Vision–ECCV 2014. Cham: Springer International Publishing, 2014: 740-755.
[21] 吴夙慧, 成颖, 郑彦宁, 等. K-means算法研究综述[J]. 现代图书情报技术, 2011(5): 28-35.
WU S H, CHENG Y, ZHENG Y N, et al. Survey on K-means algorithm[J]. New Technology of Library and Information Service, 2011(5): 28-35 (in Chinese).
[22] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision–ECCV 2016. Cham: Springer International Publishing, 2016: 21-37.
[23] BOCHKOVSKIY A, WANG C Y, LIAO H Y MARK. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2021-08-28]. https://arxiv. org/abs/2004.10934.
Landmark detection based on perspective down-sampling and neural network
LI Yu-zhen1, CHEN Hui1, WANG Jie1, RONG Wen2
(1. School of Information Science and Engineering, Shandong University, Qingdao Shandong 266237, China; 2. Shandong Hi-Speed Information Group Co, Ltd, Jinan Shandong 250000, China)
In the field of intelligent driving, a neural network-based and perspective down-sampling-based landmark detection method was proposed to accurately detect the road guide signs in real time. This proposed method can effectively solve the problems of poor real-time performance of traditional detection methods and low detection accuracy for complex scenes and remote small targets. Firstly, the region of interest for the image was selected for perspective down-sampling to reduce the near resolution of the road image, reduce the image size, and eliminate the perspective projection error. Secondly, the YOLOv3-tiny target detection network was enhanced. The boundary frame clustering of self-built data set was implemented by k-means++. The convolution layer was added to strengthen the shallow features and enhance the small target representation ability. By changing the fusion scale of feature pyramid, the prediction output was adjusted to 26×26 and 52×52. Finally, the accuracy rate was elevated from 78% to 99% on the self-built multi-scene data set, and the model size was reduced from 33.8 MB to 8.3 MB. The results show that a neural network-based and perspective down-sampling-based landmark detection method displays strong robustness, higher detection accuracy for small targets, and is readily deployable on low-end embedded devices.
perspective down-sampling; YOLOv3-tiny; landmark detection; data set; k-means++
TP 391
10.11996/JG.j.2095-302X.2022020288
A
2095-302X(2022)02-0288-08
2021-06-21;
2021-09-26
山东省科技发展计划重点项目(2019GGX101018);山东省自然科学基金项目(ZR2017MF057)
李玉珍(1996–),女,硕士研究生。主要研究方向为计算机视觉辅助和自动驾驶、目标检测。E-mail:1874922136@qq.com
陈 辉(1963–),女,教授,博士。主要研究方向为对应点问题、虚拟现实、裸眼3D电视显示、计算机视觉辅助和自动驾驶。 E-mail:huichen@sdu.edu.cn
21 June,2021;
26 September,2021
Key Projects of Science and Technology Development Plan of Shandong Province(2019GGX101018); National Natural Science Foundation of Shandong (ZR2017MF057)
LI Yu-zhen (1996–), master student. Her main research interests cover computer vision, assisted autopilot and target detection. E-mail:1874922136@qq.com
CHEN Hui (1963-), professor, Ph.D. Her main research interests cover correspondence issues, virtual reality, naked eye 3D TV display, computer vision assistance and autopilot. E-mail:huichen@sdu.edu.cn
