基于深度学习的人物肖像全自动抠图算法
2022-05-09苏常保龚世才
苏常保,龚世才
基于深度学习的人物肖像全自动抠图算法
苏常保,龚世才
(浙江科技学院理学院,浙江 杭州 310000)
针对抠图任务中人物抠图完整度低、边缘不够精细化等繁琐问题,提出了一种基于深度学习的人物肖像全自动抠图算法。算法采用三分支网络进行学习,语义分割分支(SSB)学习图的语义信息,细节分支(DB)学习图的细节信息,混合分支(COM)将2个分支的学习结果汇总。首先算法的编码网络采用轻量级卷积神经网络(CNN) MobileNetV2,以加速算法的特征提取过程;其次在SSB中加入注意力机制对图像特征通道重要性进行加权,在DB加入空洞空间金字塔池化(ASPP)模块,对图像的不同感受野所提取的特征进行多尺度融合;然后解码网络的2个分支通过跳级连接融合不同阶段编码网络提取到的特征进行解码;最后将2个分支学习的特征融合在一起得到图像的图。实验结果表明,该算法在公开的数据集上抠图效果优于所对比的基于深度学习的半自动和全自动抠图算法,在实时流视频抠图的效果优于Modnet。
全自动抠图;轻量级卷积神经网络;注意力机制;空洞空间金字塔池化;特征融合
抠图算法研究的是如何将一张图像中的前景和背景信息分离的问题,如何实现高质量又无需人工交互的抠图一直是工业界和学术界努力追求的目标。1984年PORTER和DUFF[1]提出了这类问题的数学模型

其中,为一张自然图像;为图像中的前景,为背景;为图像的半透明度,其是前景和背景信息的线性混合表示方法。的取值通常介于0和1之间,0为像素点明确属于背景,1为前景,而大多数的自然图像,其像素点均属于明确的前景或背景,但是对于图像前景的边缘,对应的值通常介于0和1之间。所以对于抠图来说,只要求解出,就可以用原始图像与线性组合得出抠图的区域,但准确估计的取值却是一个非常重要且困难的问题。
传统抠图算法通常只考虑图像的低层级特征,例如颜色等。一般分为抽样[2-4]和传播[5-6]2类算法,但是面对复杂的场景图像,这些算法的抠图效果通常不尽人意。随着近些年深度学习的快速发展,许多研究人员提出了基于深度学习的抠图算法,使得这一问题有了很大的进步。但是现在大多数基于深度学习的抠图算法[7-12]均需要人为进行交互。即以自然图像和根据图制作的三区图(trimap)作为算法的输入,预先为需要抠图的图像提供先决的约束条件,抠图的质量虽然很高,但效率大打折扣,因为trimap的制作通常耗时又耗力。为了解决此问题,大量学者研究无需输入trimap的全自动抠图算法。SENGUPTA等[13]的BackgroundMatting算法使用图像的背景替代trimap和图像同时输入算法进行抠图,达到了很好的效果;LIU等[14]使用前景粗略标注改进抠图效果,在主流的语义分割数据集上实验,发现对语义分割标签的标注精度提高明显;QIAO等[15]提出注意力机制引导的层级结构融合的图像抠图算法,抠图精度较高,在自动抠图领域中取得了突破性的进展;KE等[16]提出了MODNET算法,为实时视频抠图迈进了一大步。
1 数据集制作
1.1 a图制作
目前学术界公开的抠图数据集并不多,已经开源的数据集中具有较高质量图的有Adobe[8],Distinctions-646 (DT-646)[15]和RealWorldPortrait- 636 (RW-636)[17],其中Adobe和DT-646数据集包含的人物肖像比较少。为了扩充前景的数量,本文使用PhotoShop抠图工具标注了640张只有人物肖像的前景图,图1为部分前景图及其图。

图1 人工标注a图((a)前景图和a图示例1;(b)前景图和a图示例2))
1.2 Trimap的制作
Trimap是一个粗略的图,将其划分为前景区域、背景区域和未知区域3部分。通过trimap的引导,让抠图任务主要专注于确定未知区域中的值,进而将抠图任务变得相对简单。
本文的全自动抠图算法不需要事先加入trimap图,但需要模型自动获取trimap的信息,而为模型制作其标签。本文trimap无需手绘,可通过图像的图膨胀腐蚀得到,其中膨胀腐蚀的卷积核尺寸均设置为10×10。膨胀腐蚀后的trimap中像素值分别为0,128和255。其中,明确属于背景是黑色,像素点的值为0;明确属于前景是白色,像素点的值为255;而未知区域是灰色,像素点的值为128。其trimap的生成过程如图2所示。
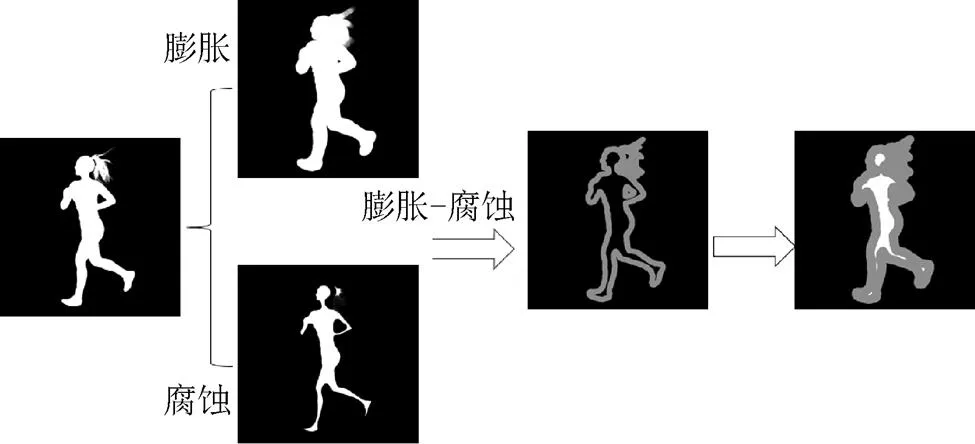
图2 Trimap生成过程
根据图2,首先对图分别进行腐蚀和膨胀操作,然后将腐蚀和膨胀的结果相减得到灰色的未知区域,最后将灰色未知区域和腐蚀的图像相加得到最终的trimap图。
1.3 合成图像
为了扩充数据集前景的数目,增加模型的泛化能力。本文使用了Adobe,DT-646和RW-636等数据集的人物肖像图和自制的640张数据集。一共1 800张前景图像,然后将每张前景图像分别和20张不同的背景图像进行合成,本文使用的背景图像是公开的BG-20K数据集[18]。合成规则遵循式(1)进行,最终合成了36 000张图像,训练集使用35 000张图像,验证集使用1 000张图像,每个数据集部分合成图如图3所示。

图3 部分合成训练集图像
2 抠图网络架构
2.1 本文算法网络架构
本文抠图网络结构分为编码网络、过渡网络、解码网络3部分,如图4所示。编码网络采用的是轻量级网络MobilenetV2[19],过渡网络由注意力机制模块和空洞空间金字塔(atrous spatial pyramid pooling,ASPP)模块组成,解码网络由3个网络分支构成:①对图像的前景、背景、未知区域进行分类学习,即语义分割分支(semantic segmentation branch,SSB);②对图像边缘细节信息学习,即细节分支(detail branch,DB);③将前面2部分学习到的图进行汇总,即混合分支(combination branch,COM)。根据MobilenetV2的特征提取尺寸的变化过程,共将MobilenetV2的特征提取分为5个部分,分别用1,2,···,5表示,即图4中的Encoder模块。过渡网络由2个模块构成,即图4中的SENet[20](SE)和ASPP模块。
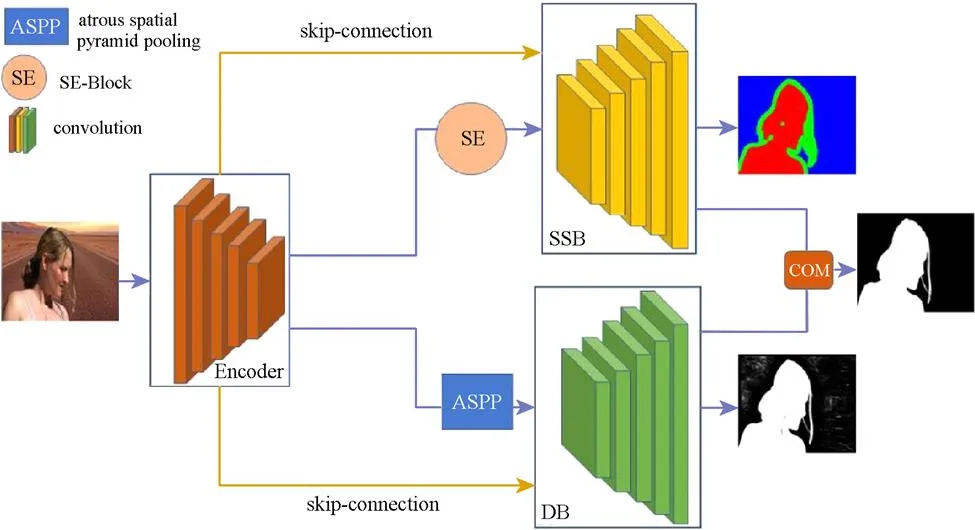
图4 本文算法网络结构
2.2 语义分割分支
在计算机视觉任务中,对图像语义信息的理解至关重要。语义信息是指一张图像所包含的内容,而抠图任务中的语义信息可看作这幅图像中的前景和背景。在抠图任务中,语义信息直接决定了抠图的整体效果。
2.2.1 注意力机制
本文算法在SSB网络中加入了注意力机制SE模块。SE模块源于SENet,可以嵌到其他分类或检测模型当中,目的是在模型关注图像特征通道的同时可以自动学习到不同通道的重要性,有利于模型处理分类问题。
SE模块的网络结构如图5所示。给定一个输入,其特征通道数为,首先对进行Squeeze操作,将每个二维的特征通道变成一个实数,某种程度上这个实数应该具有全局的感受野,所以本文使用全局池化操作。其次通过Excitation操作压缩后的1×1×的特征生成权重,本文使用2个全连接层,1个激活层,其中激活层放在2个全连接层的中间。最后对特征的通道进行加权操作,通过乘法操作,将Excitation操作生成的权重逐通道加权到特征上,完成对特征的通道注意力标定。

图5 SE模块网络结构[20]
2.2.2 语义分割分支网络结构
SSB网络是基于分类思想设计的,该分支网络的主要任务是将一张图像的背景、前景、以及背景和前景交叉的未知区域分离开,其分支共设置了11个卷积层,每个卷积层后均接着归一化层和激活层,其中最后一层卷积层使用的是softmax激活函数,主要是便于计算像素点的交叉熵损失。
SSB首先将编码特征5经过注意力机制模块,进行通道重要性加权,然后将编码网络的前4个阶段的特征1~4分别与解码网络的不同阶段进行concat特征融合。然后通过SSB网络卷积和上采样操作,最终输出一个具有三通道的特征图,每一个特征图分别代表一个类别。
2.2.3 语义分割分支损失函数
由于SSB的预测其实是在做一个三分类的问题,分别是预测图像的背景、前景和未知区域,所以SSB以trimap作为标签,主要学习trimap的信息,故采用交叉损失熵作为SSB的损失函数,即
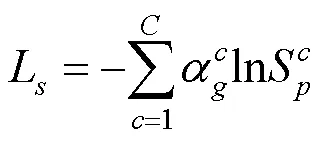
2.3 细节分支
2.3.1 空洞空间金字塔池化
空间金字塔池化(spatial pyramid pooling,SPP)可以在多个范围内捕捉上下文信息。为了获得更大尺度的上下文信息,DeepLabv V2[21]提出了ASPP,使用不同采样率的并行空洞卷积层捕获多尺度信息。本文算法在DB加入ASPP,主要目的是通过扩大卷积核的感受野,引导模型聚合不同感受野的特征,使得位于未知区域的值可以有效地联系前景和背景信息,从而实现更加精准的预测。
本文的ASPP架构是基于Deeplabv3+[22]进行改进的。ASPP模块中共设置了6个卷积层,其中卷积核尺寸设置为1×1和3×3,3×3尺寸的卷积核空洞率分别设置为1,2,4,8。如图6所示,ASPP网络模块中前5个卷积层是对编码网络的特征图5分别进行卷积操作,最后一个卷积层采用1×1卷积核对前5个卷积层的输出特征图concat后进行通道压缩获得最终的输出。

图6 ASPP模块网络结构
2.3.2 细节分支网络结构
DB采用特征融合的思想进行设计,共设置了12个卷积层,每个卷积层后均接归一化层和激活层,其中最后一个卷积层的激活函数采用的是sigmoid,主要是将预测值控制到0和1之间。
DB网络首先将编码特征5经过ASPP结构提取图像的多尺度信息,然后采用高层语义与低层语义信息特征融合的方式进行解码操作,特征融合的具体方式和SSB的一样。最终通过DB解码阶段的上采样和卷积操作,对图的细节信息进行学习。
2.3.3 损失函数
由于DB主要预测的是图像的边缘细节信息,所以损失函数也主要约束未知区域,这样对于确定属于前景和背景的预测可能不准确,但是对确定属于前景和背景的部分本文认为SSB已经学习到了。本文DB采用smoothL1损失函数,即
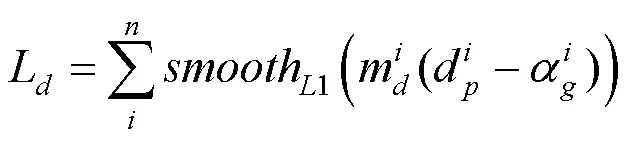


2.4 混合分支
2.4.1 混合分支网络结构
COM主要是预测最终的图,共设置了2个卷积层,最后一层采用sigmoid激活函数,目的是将预测的值直接控制在0和1之间。
COM将SSB和DB的特征进行融合,其融合特征分别来自各个分支的最后一个卷积层的结果,将2个特征图的通道进行concat操作,最终输出单通道的图。
2.4.2 混合分支损失函数
COM的损失函数分为预测出的图和合成图损失2部分,均采用L1损失函数,其数学模型为

其中,为预测值;为真实值;L来自于文献[8],表示用预测出的图合成图像和真实图像的损失。
本文算法最终通过3个分支的损失函数总和进行端到端的训练,即

其中,,,为3个超参数,用来平衡3个分支的损失,本文设置==1,=10。
3 实验结果及分析
3.1 实验参数设置
为了提高模型的泛化性能,数据集预处理时做了图像随机裁剪和随机翻转操作。本文采用python语言编写,基于pytorch框架,在一块GeForce RTX 2080 11 G GPU进行训练。实验训练图像的尺寸为320×320,batchsize设置为8,初始学习率为0.01,每迭代10次学习率下降为原来的1/10,选择SGD优化器进行梯度下降优化参数,最终实验共迭代了20次。
3.2 对比实验
为了比较本文算法的有效性,本文分别采用基于深度学习的半自动DIM[8]、全自动LFM[23]和全自动Modnet[16]3种基于深度学习的抠图算法,在验证集1 000张合成图上做对比。图7是几种算法在验证集-1k上的抠图效果。

图7 几种方法在验证集-1k上的抠图结果((a)原图像和不同算法的抠图效果1;(b)原图像和不同算法的抠图效果2;(c)原图像和不同算法的抠图效果3)
图7分别展示了原图和几种方法的抠图结果以及人工标注的图(GroundTruth(GT))。直观上看,基于深度学习的半自动抠图算法DIM对于图像的整体部分抠图结果虽然较为完整,但是细节部分还是有所欠缺,主要是因为半自动算法trimap的制作直接影响了图像的边缘效果。基于深度学习的全自动的抠图算法LFM和Modnet对于图像的细节部分抠图效果虽然有所提升,但是没有trimap作为辅助输入,图像的语义部分抠图效果并不完整。相比之下,本文算法(Ours)在图像的语义部分更加完整,细节部分抠图效果更加精细,更接近GT。
3.3 实验指标评价
为了定量分析4种方法在验证集上的抠图质量,本文采用抠图算法中常用的2个评价指标平均绝对误差[16](mean absolute error,MAD)和平均方误差[24](mean squared error,MSE),即

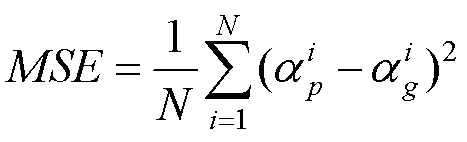
本文在相同的实验环境下,对4种算法在验证集-1k的合成图的预测结果做了MAD和MSE的计算,见表1。

表1 4种算法在验证集-1k的误差值
由表1可看出,本文算法对于MAD和MSE的值均最小,客观上证明了本文算法的有效性。
3.4 实时流视频抠图
为了验证本文算法在自然图像上的抠图效果,本文又对2k网络摄像头的实时捕捉画面进行抠图。实验设备均采用GeForce RTX 2080显卡,将实时画面均裁剪为320×320大小,其原视频帧画面和抠图画面如图8所示。
由于实时流视频抠图对算法的实时性要求较高,所以本文只对比了Modnet抠图算法,如图8所示,本文对于自然图像下的实时抠图,泛化性依然很鲁棒,人物抠图相对较为完整,明显优于Modnet算法。经测试,本文采用分辨率为320×320的实时流图像,抠图速度为每秒25帧以上。

图8 2种方法实时流视频抠图结果((a)原视频帧画面和不同算法的抠图效果1;(b)原视频帧画面和不同算法的抠图效果2)
4 结束语
本文针对目前主流抠图算法存在的自然图像抠图精度较低、抠图任务繁琐等问题,提出了一种基于深度学习的人物肖像全自动抠图算法。①首先采用2个单独的分支网络分别对抠图的语义信息和细节信息进行学习,然后将二者学习的图信息汇总,并用总的损失函数进行约束,实现了端到端的全自动抠图算法;②采用轻量级网络进行特征提取,实现了高效率抠图;③为了实现高质量的抠图效果,网络中加入注意力机制和ASPP结构。在合成数据集上的实验证明了抠图效果有所提升。此外,本文算法还支持实时流视频抠图,由于实际场景的变化,抠图效果可能有所不同。
[1] PORTER T, DUFF T. Compositing digital images[C]//The 11th Annual Conference On Computer Graphics And Interactive Techniques - SIGGRAPH ’84. New York: ACM Press, 1984: 253-259.
[2] FENG X X, LIANG X H, ZHANG Z L. A cluster sampling method for image matting via sparse coding[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 204-219.
[3] JOHNSON J, VARNOUSFADERANI E S, CHOLAKKAL H, et al. Sparse coding for alpha matting[J]. IEEE Transactions on Image Processing, 2016, 25(7): 3032-3043.
[4] KARACAN L, ERDEM A, ERDEM E. Image matting with KL-divergence based sparse sampling[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 424-432.
[5] AKSOY Y, AYDIN T O, POLLEFEYS M. Designing effective inter-pixel information flow for natural image matting[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 228-236.
[6] AKSOY Y, OH T H, PARIS S, et al. Semantic soft segmentation[J]. ACM Transactions on Graphics, 2018, 37(4): 1-13.
[7] CHO D, TAI Y W, KWEON I. Natural image matting using deep convolutional neural networks[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 626-643.
[8] XU N, PRICE B, COHEN S, et al. Deep image matting[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 311-320.
[9] LUTZ S, AMPLIANITIS K, SMOLIC A. Alphagan: generative adversarialnetworks for natural image matting[EB/OL]. (2018-07-26) [2021-09-19]. https://arxiv.org/pdf/1807.10088.pdf.
[10] LU H, DAI Y T, SHEN C H, et al. Indices matter: learning to index for deep image matting[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 3265-3274.
[11] TANG J W, AKSOY Y, OZTIRELI C, et al. Learning-based sampling for natural image matting[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 3050-3058.
[12] LI Y Y, LU H T. Natural image matting via guided contextual attention[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11450-11457.
[13] SENGUPTA S, JAYARAM V, CURLESS B, et al. Background matting: the world is your green screen[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 2288-2297.
[14] LIU J L, YAO Y, HOU W D, et al. Boosting semantic human matting with coarse annotations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 8560-8569.
[15] QIAO Y, LIU Y H, YANG X, et al. Attention-guided hierarchical structure aggregation for image matting[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 13673-13682.
[16] KE Z H, LI K C, ZHOU Y R, et al. Is a green screen really necessary for real-time portrait matting?[EB/OL]. (2020-11-29) [2021-09-19]. https://arxiv.org/abs/2011.11961.
[17] YU Q H, ZHANG J M, ZHANG H, et al. Mask guided matting via progressive refinement network[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 1154-1163.
[18] LI J, ZHANG J, MAYBANK S J, et al. Bridging composite and real: towards end-to-end deep image matting[EB/OL]. (2020-10-30) [2021-09-19]. https://arxiv.org/abs/2010.16188.
[19] SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 4510-4520.
[20] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7132-7141.
[21] CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05) [2021-09-19]. https://arxiv.org/abs/1706.05587.
[22] CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder- decoder with atrous separable convolution for semantic image segmentation[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 833-851.
[23] ZHANG Y K, GONG L X, FAN L B, et al. A late fusion CNN for digital matting[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 7461-7470.
[24] RHEMANN C, ROTHER C, WANG J, et al. A perceptually motivated online benchmark for image matting[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 1826-1833.
Fully automatic matting algorithm for portraits based on deep learning
SU Chang-bao, GONG Shi-cai
(School of Science, Zhejiang University of Science and Technology, Hangzhou Zhejiang 310000, China)
Aiming at the problems of low completeness of character matting, insufficiently refined edges, and cumbersome matting in matting tasks, an automatic matting algorithm for portraits based on deep learning was proposed. The algorithm employed a three-branch network for learning: the semantic information of the semantic segmentation branch (SSB) learninggraph, and the detailed information of the detail branch (DB) learninggraph. The combination branch (COM) summarized the learning results of the two branches. First, the algorithm’s coding network utilized a lightweight convolutional neural network MobileNetV2, aiming to accelerate the feature extraction process of the algorithm. Second, an attention mechanism was added to the SSB branch to weight the importance of image feature channels, the atrous spatial pyramid pooling module was added to the DB branch, and multi-scale fusion was achieved for the features extracted from the different receptive fields of the image. Then, the two branches of the decoding network merged the features extracted by the encoding network at different stages through the jump connection, thus conducting the decoding. Finally, the features learned by the two branches were fused together to obtain the imagegraph. The experimental results show that on the public data set, this algorithm can outperform the semi-automatic and fully automatic matting algorithms based on deep learning, and that the effect of real-time streaming video matting is superior to that of Modnet.
fully automatic matting; lightweight convolutional neural network; attention mechanism;atrous spatial pyramid pooling; feature fusion
TP 391
10.11996/JG.j.2095-302X.2022020247
A
2095-302X(2022)02-0247-07
2021-08-17;
2021-09-24
浙江省自然科学基金项目(Ly20A010005)
苏常保(1996–),男,硕士研究生,主要研究方向为图像分割。E-mail:schangbao20@163.com
龚世才(1970–),男,教授,博士。主要研究方向为图论,复杂网络等。E-mail:scgong@zafu.edu.cn
17 August,2021;
24 September,2021
Natural Science Foundation of Zhejiang Province (Ly20A010005)
SU Chang-bao (1996–), master student, His main research interest covers image segmentation. E-mail:schangbao20@163.com
GONG Shi-cai (1970–), professor, Ph.D. His main research interests cover graph theory, complex network, etc. E-mail:scgong@zafu.edu.cn
