基于遥感图像的多模态小目标检测
2022-05-09顾晶晶王秋红
胡 俊,顾晶晶,王秋红
基于遥感图像的多模态小目标检测
胡 俊,顾晶晶,王秋红
(南京航空航天大学计算机科学与技术学院,江苏 南京 210016)
由于遥感图像目标往往较小且容易受光线、天气等因素的影响,所以单一模态下基于深度学习的遥感图像目标检测的准确度较低。然而,不同模态间的图像信息可以相互增强提高目标检测的性能。因此,基于RGB和红外图像,提出了一种适用于遥感图像多模态小目标检测的平衡多模态深度模型。相比简单地相加、点乘和拼接的方式融合2个模态的特征信息,设计了一种平衡多模态特征的方法增强目标特征,以弥补单一模态信息不足的缺点。首先分别对RGB和红外图像进行浅层特征提取;其次,融合2个模态的特征信息并进行深层的特征提取;然后,基于YOLOv4方法,构建了多模态小目标检测模型。最后,基于VEDAI数据集,在遥感图像多模态小目标检测实验结果中验证了该方法的有效性。
遥感图像;平衡多模态深度模型;小目标检测;融合;VEDAI数据集
遥感图像在实时、动态、宏观等特点的基础上,为军事侦察、地质灾害调查与救治等方面提供了一种新的探测手段。近些年,随着卫星遥感技术和深度卷积神经网络(deep convolutional neural network,DCNN)技术的快速发展,遥感图像目标检测在军事、情报、商业、经济、规划等领域有着重要的应用。
早期基于传统机器学习方法的检测工作[1-3],其检测性能十分有限。随着发展,DCNN在目标检测任务中占据着主导地位,根据网络阶段可分为one-stage (YOLO[4],SSD[5])和two-stage (R-CNN[6],Fast RCNN[7],Faster RCNN[8])。2种方法在一般的目标检测任务中分别具有速度和精度上的优势,但面向由卫星、遥感器、无人机等设备采集的遥感数据时,由于遥感数据目标较小,这些算法容易受到光线、天气等因素影响,性能往往达不到预期,因此和一般的目标检测任务存在一定差异性,给检测任务带来了许多挑战。虽然已经开展了很多的遥感图像目标检测工作[9-17],但大部分还是仅针对RGB图像的目标检测。现今,用于航空目标检测的多模态数据的可用性显著增加,如高光谱、合成孔径雷达(synthetic aperture radar,SAR)和红外(infra-red,IR)图像,其均有自身的优势,为RGB图像提供了补充信息。考虑到RGB图像通常无法在较差的亮度条件下捕获信息,利用红外模式捕获更长的热波长,以完成不同天气条件下检测物体,有助于补偿特征信息损失来扩展RGB的能力。所以也有一小部分工作是关于RGB和IR图像相结合的目标检测,但只是通过特征提取[18-20]并简单地运用早期融合方式或相加、拼接[13, 21-23]等中期融合方式进行目标检测。
为了解决以上问题,本文结合了RGB和IR图像信息,提出一种适用于遥感图像多模态小目标检测的平衡多模态深度模型(balanced multimodal deep model,BMDM)。考虑到简单地相加、点乘和拼接的方式融合2个模态的特征信息往往达不到理想效果,本文设计了一种平衡多模态特征的方法增强目标特征,弥补了单一模态信息不足的缺点。
1 平衡多模态深度模型
如图1所示,首先输入RGB和IR图像。在第1阶段,分别对输入的2种图像提取浅层特征(low-level feature),使用平衡多模态融合方法(balanced multimodal fusion,BMF)对提取的浅层特征进行融合,再经过深层网络提取深层特征(deep-level feature)。第2阶段,对第1阶段的特征进行空间金字塔池化(spatial pyramid pooling,SPP)和路径聚合网络(path aggregation network,PAN)处理。第3阶段,输出目标信息,并与真实数据计算损失来训练模型。
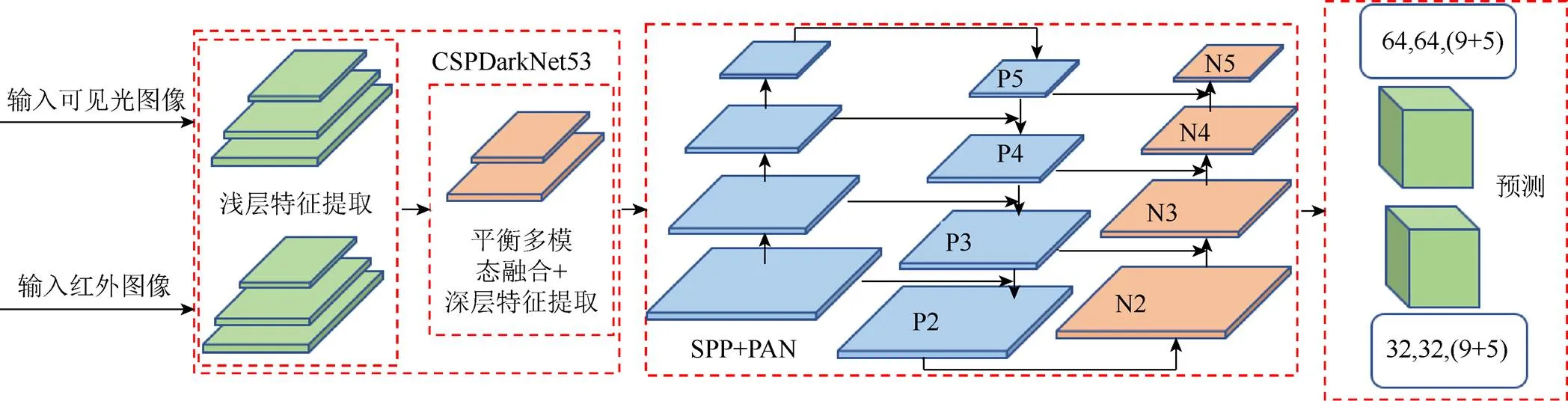
图1 平衡多模态深度模型框架结构
1.1 基于YOLOv4的遥感小目标网络结构
遥感小目标检测网络结构基于YOLOv4实现,整体分为主干、颈部和头部3部分。主干用于RGB和IR图像特征提取和融合。颈部是位于主干和头部的一些网络层,通常用来收集不同阶段的特征图。头部是目标的检测器,包括目标在图像的位置、置信度和目标类别信息。其中主干又包括浅层特征提取层(low-level layer)、中间特征融合层(mid-level fusion layer)和深层特征提取层(deep-level layer)。浅层特征提取层由1个卷积层和1,4,8个跨阶段局部残差块组成。中间特征融合层由一个全局平均池化层、全连接层和Softmax激活函数组成。深层特征提取层由8个跨阶段局部残差块组成。主干网络结构如图2所示。为了使网络获取更多小目标的特征信息,提高其检测率,BMDM在CSPDarknet53的基础上对网络结构进行改进,将该网络中的第2个残差块增加2个,同时去除第5个残差块。跨阶段局部残差块结构如图3所示。

图2 主干网络结构

图3 跨阶段局部残差块结构
(1) 浅层特征提取层。低层特征映射可保留小目标的位置信息,而高层特征映射可包含高层语义线索。网络输出2个3D张量,分别表示RGB和IR图像的低层特征。
(2) 中间特征融合层。为了平衡融合2个模态的局部特征信息,提出的BMF方法。
(3) 高层特征提取层。为了更好的丰富目标特征信息,将2个模态的特征信息融合后,再对其特征进行高层特征的提取。
(4) 颈部层。为了使输入的头部信心更丰富,将自底而上的数据流信息进行聚合,以使低层信息能更好地使用。颈部层使用了SPP池化层和PAN层。
(5) 头部层。输出预测目标的信息,与真实标注数据计算损失来优化网络。输出2个3D的张量,每个张量均包含检测出目标的位置、置信度和目标类别。
1.2 候选框的选取
候选框是一组宽高固定的初始框,对其选择会直接影响网络对目标的检测精度与速度。K-means聚类算法具有可解释性强、聚类效果较优、收敛速度快等优势。本文利用K-means聚类算法对遥感图像车辆检测数据集中的目标框进行聚类。对数据集进行聚类分析,度量方法采用均值交并比方法(average intersection over union,avg IOU),其目标函数为

其中,为样本号;为聚类中心的序号;为样本;为簇的中心;n为聚类中心样本的第个数;为样本的总个数;I(,)为簇的中心框和聚类框的交并比;聚类数分别选取=2,3,···,10进行聚类,得到与均值交并比的关系图(图4)。随着值的增大,目标函数也在变化,而=6后的曲线逐渐趋于平稳,因此选取候选框的数量为6,以加快损失函数的收敛,并消除候选框带来的误差。由于本文方法采用2个尺度对目标进行检测,所以尺度1和2分别对应的候选框为(22,10),(11,22),(20,19)和(22,40),(40,17),(47,43)。
图4 K-means聚类分析结果图
Fig. 4 K-means clustering analysis result
1.3 平衡多模态融合

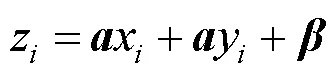


1.4 数据增强
鉴于遥感图像数据受环境和拍摄器等因素影响,使得图像不可避免的存在各种噪声,尤其是遥感图像中相对一般的检测目标要小得多,受这些噪声的影响更是严重。为了更好地训练模型,采用数据增强来减小噪声并且使得数据集“更强”,从而使目标检测器获得更好的精度且不增加推理成本,同时使模型在不同环境获得的图像具有更高的鲁棒性。数据增强包括:
(1) 几何变换,包括旋转、翻转、裁剪。
(2) 图像增强,包括高斯噪声、模糊处理、擦除、填充和颜色扰动。
(3) 混合削减,将图像的部分区域剪掉并填充上训练集中其他数据的区域值像素值。
(4) 马赛克数据增强,将4张训练图像组合成1张图像用于训练,使模型能够训练到小的目标。如图5所示,图5(a)为原图,经数据增强后得到图5(b)增强图。
1.5 网络输出
本文方法将整个图像分割成一个网格,且根据2.2节选择2个尺度,每个尺度有3个候选框。网络整体输出是2个3D张量(64×64×42,32×32×42),张量包含了位置、置信度和类别信息,2个张量分别对应32×32和16×16的网格。
对于第个网格,预测输出3×14维的向量对应3个候选框,每个候选框的输出为

其中,(x,y)为预测框的中心点,相对于该网格的左上角;为该预测框里目标的置信度,取值为0到1,越高说明置信度越大;,=1,2,···,9为预测框里目标的类别,类别对应于汽车、卡车、拖拉机、露营车、客货车、其他车、皮卡、船、飞机。同时,输出的评估方式采用平均正确率均值,即
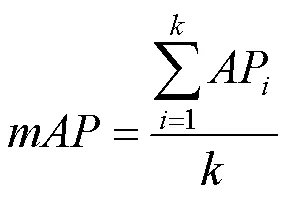

1.6 损失函数
方法的损失函数类似于YOLOv4,分为类别、置信度和位置损失,损失函数为
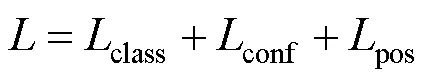
(1) 类别损失。预测框中存在目标时才进行类别损失计算,根据候选框与实际框的交并比判断是否存在目标。本文采用2个特征尺度,分别对应于8倍和16倍下采样。类别损失计算采用交叉熵损失计算,对每个类别计算交叉熵损失并进行求和运算,类别损失函数为
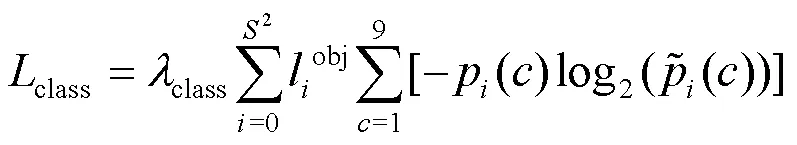
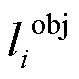
(2) 置信度损失。区分有目标和无目标的置信度损失,采用交叉熵损失,置信度损失函数为
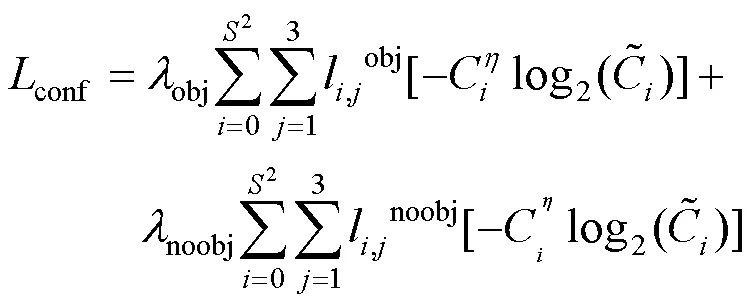
(3) 位置损失。采用完全交并比损失(complete intersection over union,CIOU)[24],即

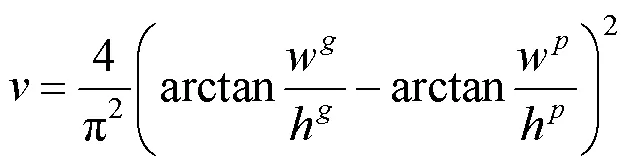
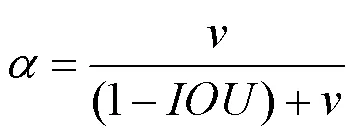


其中,,分别为预测框和真实框;,分别为2个框的中心点;为2个框的最小包围矩形框的对角线长度;为预测框和真实框的中心端距离;和分别为真实角度值和预测角度值。
2 实 验
将本文方法在遥感图像车辆检测库(vehicle detection in aerial imagery,VEDAI)中进行测试。实验条件:操作系统为Red Hat 4.8.5,深度学习框架为PyTorch,CPU为i7-5930 K,内存为64 G,GPU为GeForce RTX 3090,GPU内存为16 G。
2.1 实验数据集和设置
VEDAI (https://downloads.greyc.fr/vedai/)是一个用于遥感图像中车辆检测的数据集,是在无约束环境中对自动目标识别算法进行基准测试的工具。数据库中包含的车辆除了体积小之外,还表现出不同的问题,如多个方向、照明阴影变化、镜面反射或遮挡。此外,每幅图像均有多个光谱波段和分辨率。该数据集包含1 272张1024×1024的遥感图像,对应于1 272张512×512遥感图像,空间分辨率为12.5 cm。所有图像均是从同一高度拍摄的,每幅图像有2种模态:RGB和IR图像。数据集划分为汽车、卡车、拖拉机、露营车、客货车、其他车、皮卡、船和飞机9个类别。本文使用的是512×512的图像,所有类别均包括在内,见表1。
训练集和测试集的划分比例为9∶1,即1 146张图像用于训练集,126张图像用于测试集。模型总共训练300次迭代,每次训练的最小批量为4张图像,梯度累计间隔为4次最小批量迭代。使用Adam优化器进行训练,初始学习率为0.001,权重衰减系数为0.000 5,动量参数为0.93。在训练模型中,每一次训练迭代均计算了测试集的平均正确率均值。
2.2 实验结果
在该数据集中,正负样本十分不均衡,负样本数量太大,占总损失的大部分,且多是容易分类的,因此使得模型的优化达不到理想,导致检测准确度不理想。因此在损失函数中采用了focal损失函数,该函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本来提升检测的精确度。在实验中,本文分别设置focal损失参数为=0,1,2,3,由此选取更适合的focal损失参数。实验结果如图6所示,同时本文还对比了YOLOrs模型不同focal损失参数的训练结果。根据实验结果可知=1和=2时,测试集的平均正确率均值相差不大,但是在接近300次迭代时=2的平均正确率均值有下降趋势,因此本文选取了=1作为focal的参数。
在对比试验中,为了不让模型受focal损失参数的影响,本文统一设置=1。本文对比了YOLOrs (4通道)[13]、改进的YOLOv4 (RGB)、改进的YOLOv4 (IR)、改进的YOLOv4 (点乘融合)、SSD[5](4通道)、RetinaNet (4通道)(注:RGB是3通道图像,IR是1通道图像,4通道表示将2个模态的图像合并为4通道作为模型的输入;RGB表示只输入RGB图像;IR表示只输入IR图像;点乘融合表示使用BMF网络,融合方式采用点乘方式)。YOLOrs是专为多模态遥感图像实时目标检测而设计的,采用中期拼接方式融合。SSD为经典的一阶段目标检测算法,使用focal损失函数。RetinaNet使用ResNet+FPN作为主干,是一种使用focal损失参数的一阶段目标检测模型。实验结果见表2。实验结果表明融合方式十分重要,这是因为2种模态图像均包含着丰富的特征信息,模型能够利用不同模态中有用的信息作为补充信息。表3给出了本文模型对9个类别的准确率和召回率。
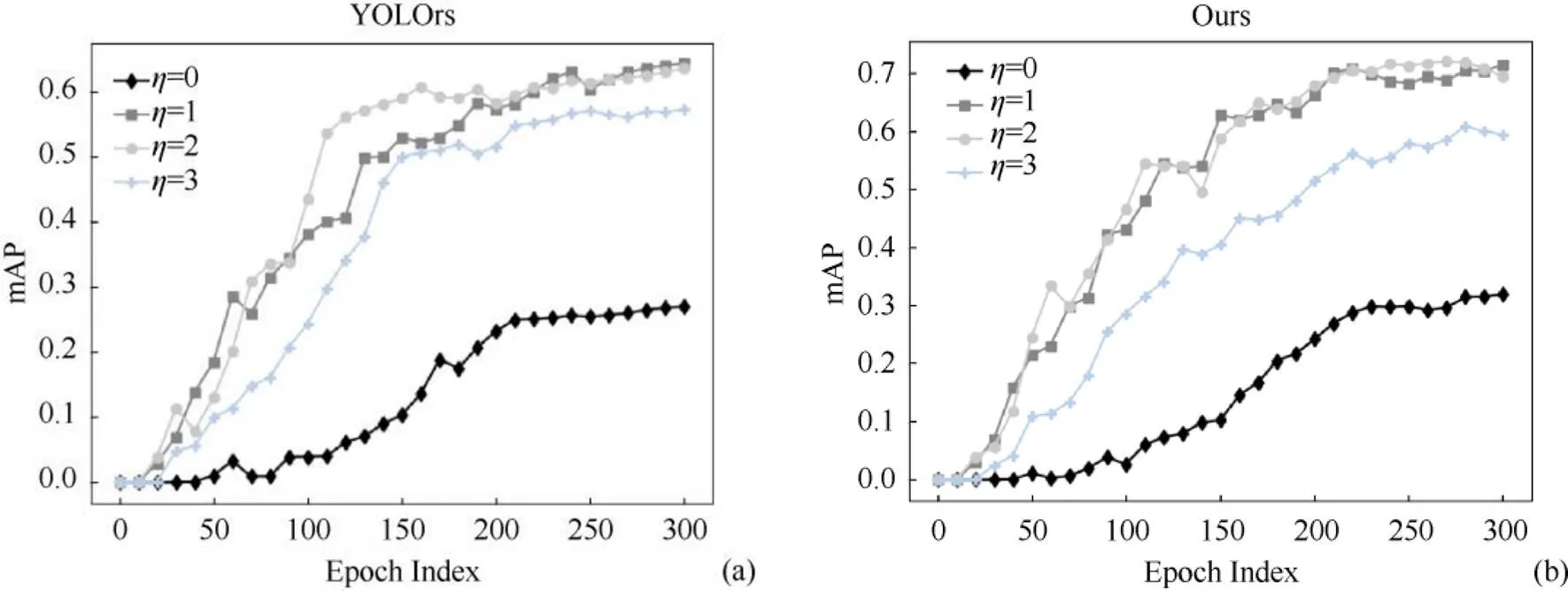
图6 Focal参数对比结果图((a) YOLOrs的不同focal参数结果图;(b)本文方法的不同focal参数结果图)

表2 测试集上精度对比
注:加粗数据为最优值
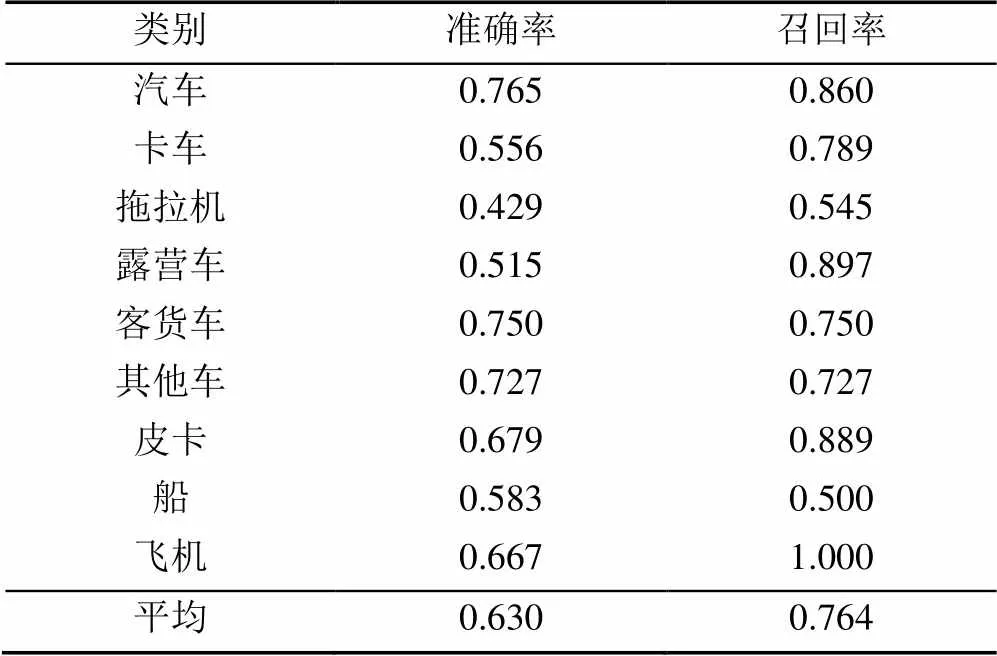
表3 平衡多模态方法的准确率和召回率(%)
(1) 定量对比。本文方法在平均正确率均值结果中有着不俗的表现,达到71.5%,排名第1,相比第2名提高了11.0%。是因为在模态融合时2种模态的信息互补,增强了模型对目标的检测。其中卡车、露营车、客货车、其他车、船类别均优于其他模型。
(2) 定性对比。图7第1~3列分别为本文、YOLOrs和Improved YOLOv4(multiplication)方法的检测结果,数字1,2,···,9对应9个类别,其中所标出的红色框为多检和错检结果。YOLOrs模型容易出现多检的情况,Improved YOLOv4 (multiplication)模型容易出现多检和错检的情况,而本文模型能够精准地检测出目标。
2.3 消融实验
本文设计了一系列的消融实验以分析平衡多模态方法和其每一部分的优势,并对比了使用该网络的单模态RGB实验。
(1) 数据增强。对于遥感图像的目标检测任务是十分重要的。实验中本文对比了使用和不使用数据增强的单模态和多模态方法,从实验结果可知数据增强会大幅度提高检测的精确度。
(2) 平衡多模态。相比单模态RGB图像检测,平衡多模态目标检测受环境等因素的影响更低,由此泛化性也更高。表4展示了该方法在遥感图像小目标检测的精度上更高。

图7 可视化检测结果图((a)本文方法;(b) YOLOrs方法;(c)改进的YOLOv4(点乘)方法)

表4 消融实验的平均正确率均值
注:加粗数据为最优值;√为使用本模块;- 为未使用本模块
(3) 正则项矩阵。其为了防止过拟合,从而增强模型的泛化能力。实验结果也表明了正则项矩阵的优势。
3 总结与展望
为提升目标检测中小目标的检测精度,以解决光线弱、能见度低等环境下目标检测效果不理想的问题,本文联合挖掘了RGB和IR图像2种模态数据之间的相关性及可实现互补增强,并基于改进的CSP-DarkNet53网络提出了基于YOLO的平衡多模态多类检测网络,以实时检测遥感图像中的小目标。该方法不仅对遥感图像小目标更敏感,且通过BMF方式利用2种模态信息互补增强,进一步提升网络的小目标检测精度和鲁棒性。同时,算法采用数据增强减弱噪声的影响,进一步优化了训练数据集。在公开的VEDAI数据集上进行验证,相比其他方法,本文方法在多个类别的mAP均处于领先,总体上也实现了最好的性能表现。
综上所述,本文提出的BMDM方法通过融合图像的多模态信息而实现对遥感图像中小目标的精确检测,有效提升了小目标的检测性能,并为后续其他融合方法的选取与尝试提供了参考。虽然目前本文的BMDM方法在小目标检测精度上有了较明显地提升,但由于网络需要对2个模态的图像进行特征提取并融合,致使网络计算速度上受到限制,且融合方式有待进一步挖掘。因此,如何进一步加速计算、改进融合方法、提高精度,是下一个阶段需要探索的目标。
[1] LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[2] VIOLA P, JONES M J. Robust real-time face detection[J]. International Journal of Computer Vision, 2004, 57(2): 137-154.
[3] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2005: 886-893.
[4] BOCHKOVSKIY A, WANG C Y, LIAO H Y. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2021-07-26]. https://xueshu.baidu.com/usercenter/paper/show? paperid=1q0h0p70e95d0ej0sj1202x0em679337.
[5] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 21-37.
[6] GIRSHICK R, DONAHUE J, DARRELL T, et al. Region-based convolutional networks for accurate object detection and segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(1): 142-158.
[7] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[8] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[9] ETTEN A V. You only look twice: rapid multi-scale object detection in satellite imagery[EB/OL]. [2021-07-26]. https:// xueshu.baidu.com/usercenter/paper/show?paperid=196ddb2c129916b9f930a718f09e6348&site=xueshu_se.
[10] YANG X, YANG J R, YAN J C, et al. SCRDet: towards more robust detection for small, cluttered and rotated objects[C]// 2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 8231-8240.
[11] ZHANG G J, LU S J, ZHANG W. CAD-net: a context-aware detection network for objects in remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(12): 10015-10024.
[12] LONG H, CHUNG Y, LIU Z B, et al. Object detection in aerial images using feature fusion deep networks[J]. IEEE Access, 2019, 7: 30980-30990.
[13] SHARMA M, DHANARAJ M, KARNAM S, et al. YOLOrs: object detection in multimodal remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 14: 1497-1508.
[14] KOESTER E, SAHIN C S. A comparison of super-resolution and nearest neighbors interpolation applied to object detection on satellite data[EB/OL].[2021-07-26]. https://xueshu.baidu. com/usercenter/paper/show?paperid=1c520t20gw6f0m60e80u0g106f040545&site=xueshu_se&hitarticle=1.
[15] XIA G S, BAI X, DING J, et al. DOTA: a large-scale dataset for object detection in aerial images[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 3974-3983.
[16] LU X C, JI J, XING Z Q, et al. Attention and feature fusion SSD for remote sensing object detection[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 1-9.
[17] YANG X, LIU Q Q, YAN J C, et al. R3Det: refined single-stage detector with feature refinement for rotating object[EB/OL]. [2021-07-26]. https://xueshu.baidu.com/ usercenter/paper/show?paperid=133q0vw0wg7w04w0pq150pm0kn019941&site=xueshu_se.
[18] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(4): 640-651.
[19] SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[EB/OL]. [2021-07-26]. https://xueshu.baidu.com/ usercenter/paper/show?paperid=e405c047319275f1026702182776bfdc&site=xueshu_se.
[20] IANDOLA F, MOSKEWICZ M, KARAYEV S, et al. DenseNet: implementing efficient ConvNet descriptor Pyramids[EB/OL]. [2021-07-26].https://xueshu.baidu.com/ usercenter/paper/show?paperid=db44736c4000d1544d02905c43dbf413&site=xueshu_se&hitarticle=1.
[21] 邢素霞, 肖洪兵, 陈天华, 等. 基于目标提取与NSCT的图像融合技术研究[J]. 光电子激光, 2013, 24(3): 583-588.
XING S X, XIAO H B, CHEN T H, et al. Study of image fusion technology based on object extraction and NSCT[J]. Journal of Optoelectronics Laser, 2013, 24(3): 583-588 (in Chinese).
[22] 王春华, 马国超, 马苗. 基于目标提取的红外与可见光图像融合算法[J]. 计算机工程, 2010, 36(2): 197-200.
WANG C H, MA G C, MA M. Fusion algorithm for infrared and visible light image based on object extraction[J]. Computer Engineering, 2010, 36(2): 197-200 (in Chinese).
[23] YANG D F, LIU X, HE H, et al. Air-to-ground multimodal object detection algorithm based on feature association learning[J]. International Journal of Advanced Robotic Systems, 2019, 16(3): 1-9.
[24] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12993-13000.
Multimodal small target detection based on remote sensing image
HU Jun, GU Jing-jing, WANG Qiu-hong
(College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing Jiangsu 210016, China)
Since targets in remote sensing images are relatively small and easily affected by illumination, weather, and other factors, deep-learning based target detection methods from single modality remote sensing images suffer from low accuracy. However, the image information between different modalities can enhance each other to improve the performance of target detection. Therefore, based on RGB and infrared images fusion, we proposed a balanced multimodal depth model (BMDM) for multimodal small target detection from remote sensing images. As opposed to simple element-wise summation, element-wise multiplication, andconcatenation to fuse the feature information of the two modalities, we designed a balanced multimodal feature method to enhance target features to make up for the shortcomings of single modal information. We first extracted low-level features from RGB and infrared images, respectively. Secondly, we fused the feature information of the two modalities and extracted deep-level features. Thirdly, we constructed a multimodal small target detection model based on the one-stage method. Finally, the effectiveness of the proposed method was verified by the experimental results of multimodal small target detection performed on the public dataset VEDAI of remote sensing images.
remote sensing images; balanced multimodal deep model; small target detection; fusion; VEDAI dataset
TP 753
10.11996/JG.j.2095-302X.2022020197
A
2095-302X(2022)02-0197-08
2021-08-26;
2021-11-26
国家自然科学基金项目(62072235)
胡 俊(1994–),男,硕士研究生。主要研究方向为数字图像处理与数据挖掘。E-mail:hujunyn@163.com
顾晶晶(1986–),女,教授,博士。主要研究方向为网络数据挖掘、智能系统等。E-mail:gujingjing@nuaa.edu.cn
26 August,2021;
26 November,2021
National Natural Science Foundation of China (62072235)
HU Jun (1994–), master student. His main research interests cover digital image processing and data mining. E-mail:hujunyn@163.com
GU Jing-jing (1986–), professor, Ph.D. Her main research interests cover data mining, intelligent system, etc. E-mail:gujingjing@nuaa.edu.cn
