基于自编码器和HMM 的民机接地点远事件检测
2022-04-29霍纬纲李继龙王慧芳
霍纬纲,李继龙,王慧芳
(中国民航大学计算机科学与技术学院,天津 300300)
飞机的着陆过程大致可分为下滑接地和接地后的减速滑跑2个阶段。下滑接地是飞机经跑道入口从离地垂直高度50 ft点(1 ft(英尺)=0.304 8 m),以进场速度开始进场,经过下滑拉平至主轮着地的阶段。飞机在下滑接地阶段经过的水平距离称为接地距离。接地点远事件(long touchdown exceedance,LTE)是指飞行着陆过程中的接地距离大于规定范围的超限事件。该事件是造成飞机冲出机场跑道的重要因素之一。目前,民航业内的飞行品质监控(flight operation quality assurance,FOQA)工作仅依据飞行下滑接地期间地速的积分距离判定接地点远事件的发生,无法结合多个快速存取记录器(quick access recorder,QAR)参数取值检测并分析发生接地点远事件的原因。以单个QAR参数进行超限事件检测效率较高,但是很容易出现由于相应参数记录值缺失而无法判断超限事件情形,或由于数据噪声而导致“假事件”现象。一方面,实际上在某一超限事件发生时,会有若干个相关联的QAR参数都有异常变化[1],如果能综合运用多个QAR参数进行超限事件检测,便可以降低发生如上问题的机率。另一方面,现有的监控标准大多来自飞机制造商提供的各种手册或航空公司内部规定,这些标准大多只考虑了一般情况。然而飞机的飞行过程会受到运行环境、飞机自身机械状况、飞行员的驾驶水平等众多因素影响。在天气异常、或特殊机场等情形下,飞行员可能必须采取“大尺度”操纵,此类操纵也容易被误判为超限事件。QAR记录了大量飞行参数的变化规律,反映了飞机运行环境及飞行员对各种事件的反应及处理过程。因此,若能从多个QAR参数的角度检测并解释超限事件,将有助于进一步提高FOQA的管理水平。
为提高航空安全管理水平,近年来研究人员围绕民航业内积累的大量QAR数据开展了许多研究工作。文献[2]通过对QAR数据聚类分析挖掘隐含的着陆阶段以油门和杆位表达的飞行操作模式,分析FOQA指标值与挖掘的操作模式之间的关联关系,量化飞行操作模式的风险水平。文献[3]分析了飞机着陆阶段拉平操作过程中QAR参数取值的方差特征,在此基础上采用回归模型分析了拉平操作对接地距离及重着陆事件的影响。文献[4]基于正态云理论建立了飞行员着陆操作风险评价模型。上述研究都是从安全风险评估的角度开展工作[2-4],这些模型涉及的QAR参数个数相对较少。另外机器学习算法已被应用于从海量多维QAR数据集中发现异常飞行事件[5-10]。文献[5-6]将多维时序QAR数据转化为高维向量,由基于密度的噪点空间聚类(densitybased spatial clustering of applications with noise,DBSCAN)聚类算法检测异常航班。文献[7]应用聚类技术识别与飞行风险相关的QAR参数。文献[8]通过采样技术将单个QAR数据转化为多个时序向量,由基于高斯混合模型的聚类算法检测不安全事件。文献[9]采用向量自回归模型表示每个航班的QAR数据,基于回归模型参数计算航班之间的距离矩阵,由局部离群因子(local outlier factor,LOF)检测算法检测异常航班。文献[10]提出了融合半马尔可夫和向量自回归模型的飞行安全隐患检测方法。文献[5-8]中的模型训练前对QAR数据的特征提取方式有可能丢失检测飞行安全隐患所需的关键信息,不能较好地捕获QAR参数值的时序特征和参数之间的耦合关系。文献[9-10]的向量自回归模型仅能表达QAR参数之间的线性关系,且该类模型对噪声也比较敏感。
隐马尔可夫模型(hidden Markov model,HMM)为结构最简单的动态贝叶斯网,主要用于时序数据的建模。基于HMM 的时间序列的异常检测方法一般主要包含2个重要步骤:①符号化时间序列;②参数学习与概率估计。符号化时,旨在以字符串序列表示原始时间序列,不仅可以达到数据降维的目的,而且符合HMM 对观测序列的要求。文献[11]将HMM应用于飞机着陆操作的异常检测中,采用K-means聚类算法将原始时间序列转化成由K个簇标记表示的符号序列。文献[12]将HMM应用在多维时间序列上的异常检测中,分别采用模糊C均值(fuzzy C-means,FCM)聚类算法和模糊积分技术将多维时间序列转换成单维的符号序列,提高HMM 的异常检测能力。文献[13]的研究表明如果在符号化过程之前不对原始序列进行特征提取,序列中噪声会对异常检测效果造成影响,提出了基于感知重要点技术的符号化方法,但其需要计算每个点对于时间序列的影响力,计算复杂度较高。文献[11-12]在符号化过程中均没有对原始序列进行特征提取。自编码器是一种由编码器和解码器构成的无监督学习算法,能从大量无标记的数据中学习数据的有效信息,实现对输入数据的非线性压缩和重构。文献[14]提出了基于自编码器和HMM的多维时序数据异常检测模型,由自编码器生成多维时间序列的低维特征表示,对这些特征表示聚类处理,实现多维时间序列的符号化,研究表明该模型能显著提高HMM在多维时序数据上的异常检测效果,但自编码器无法表达多维时序数据的时态依赖关系。
本文提出了一种基于长短时记忆网络自编码器(long short term memory networks auto encoder,LSTM-AE)[15]和HMM 的接地点远事件检测方法(long touchdown exceedance detection method based on LSTM-AE and HMM,LTED-LSTM-HMM),该方法采用LSTM-AE学习多维QAR数据的特征表示,使获得的特征表示能更好地表达QAR数据的时序信息,并由此建立了基于HMM 的接地点远事件检测模型,实验表明了本文方法的有效性。
1 LTED-LSTM-HMM 方法
LTED-LSTM-HMM方法的具体流程如图1所示。从QAR译码文件中截取飞机着陆阶段相关QAR参数取值,将生成的数据集合划分为训练集、验证集和测试集,其中训练集只包含未发生接地点远事件的QAR样本,测试集和验证集包含发生和未发生接地点远事件的QAR样本。本文方法首先利用滑动窗口将所有QAR样本按固定分段数目进行分段,按分段位置形成若干QAR片段样本集。由训练集不同位置的QAR片段样本训练各个分段的LSTM 自编码器网络,从而得到QAR样本各个片段的低维特征表示。采用Kmeans算法对这些表示向量集聚类处理,实现QAR样本的符号化。在训练集QAR样本的符号化序列上,采用Baum-Welch算法[16]构建检测接地点远事件的HMM模型λ1。在模型λ1下,计算验证集中每个QAR样本符号序列出现的概率,并在出现概率的最大值和最小值之间均匀划分若干个值,根据F1值最大原则来确定接地点远事件检测阈值。由包含发生及未发生接地点远事件QAR样本片段集训练LSTM 自编码器,采用K-means算法对LSTM 编码器中每个LSTM 单元隐藏层的输出向量进行聚类,实现QAR样本每个片段的符号化,由所有QAR样本分段的符号序列建立HMM模型λ2,采用Viterbi算法[16]确定接地点远事件在QAR样本片段内的具体位置。

图1 接地点远事件检测方法流程Fig.1 Flowchart of detection method of long touchdown exceedance
1.1 QAR样本分段及符号化


图2 QAR样本分段方法示意图Fig.2 Schematic diagram of QAR sample segmentation method

图3 LSTM-AE训练过程示意图Fig.3 Schematic diagram of LSTM-AE training process



1.2 基于HMM 的接地点远事件检测
HMM是由隐藏状态序列和观测序列构成的双重随机过程,序列的每一位置对应一个时刻的隐藏状态和观测值。检测接地点远事件的HMM记为λ1,λ1由Q1、V1、Π1、A1、B1描述,其中Q1表示隐藏状态集合,本文每个状态表达QAR样本内数据变化趋势,共设有平稳、轻微上升、轻微下降、突然上升和突然下降5种隐状态,V1表示所有可观测的表达QAR样本的符号集,其取值由符号化过程中K-means算法确定,Π1为初始状态概率向量,由各个隐藏状态的初始概率组成,A1为状态转移概率矩阵,由隐藏状态之间的转换概率组成,B1为输出概率矩阵,由隐藏状态下输出观测值的概率组成。



1.3 基于HMM 的接地点远事件位置检测
本文检测接地点远事件位置的HMM模型λ2的结构如图4所示。模型λ2由Q2、V2、Π2、A2、B2刻画。Q2表示隐状态集合,包含正常、异常2种状态,正常表示无接地点事件发生,用0表示,异常表示发生接地点远事件,用1表示,V2表示QAR样本片段的符号集合,Π2、A2、B2的含义与1.2节中模型λ1的Π1、A1、B1含义类似。将发生及未发生接地点远事件的QAR样本集X划分为训练集和测试集。按1.1节描述的分段符号化原理对X中的样本片段符号化。训练集QAR样本分段的符号序列集记为ST,ST中每个样本为长度e的符号序列。测试集QAR样本分段的符号序列集记为ST,ST中包含eT′N个片段符号序列,T′N为测试集样本数目。由ST采用无监督Baum-welch算法[16]训练HMM 模型λ2的参数。基于Viterbi算法[16]计算ST中每个片段符号序列在模型λ2下的最大概率状态转换路径,由该路径确定接地点远事件在片段内的具体位置。具体算法描述如下。
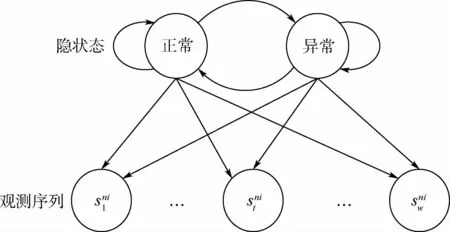
图4 检测接地点远事件位置的HMM模型结构示意Fig.4 Structure of HMM model for detecting the position of long touchdown exceedance
算法3 检测接地点远事件位置算法。
输入:在ST上训练的HMM模型λ2;测试集分段符号序列集ST。
输出:ST中每个片段符号序列中接地点远事件位置信息。
Begin
For ST中的每个符号序列Sni=(s1,…,st,…,sw)(1≤i≤e,1≤n≤T′N)

2 实验与分析
2.1 实验数据与环境
本文实验数据为某航空公司同一架机型737-800的飞机242个航班QAR数据,截取了飞机着陆阶段相关QAR参数取值。其中180个航班未发生接地点远事件,62个航班包含接地点远事件。接地点远事件检测实验中,训练集由144个正常QAR样本组成,测试集和验证集都由22个正常QAR 样本和31个发生接地点远事件的QAR样本构成。接地点远事件位置检测实验中,共使用了115个QAR样本,训练集由随机抽取的31个正常QAR 样本和31个接地点远事件的QAR样本组成,剩余QAR样本作为测试集。实验的软件环境为:Tensorflow1.10.0,Python3.6.2,Windows10 64位操作系统;硬件环境为:Intel(R)Core(TM)i7-3770处理器,4 GB内存。
根据飞机着陆过程的动力学模型[18],与接地点远事件直接相关的因素包括经跑道入口时的高度、下滑角、拉平阶段圆弧运动的半径。当飞机高于50 ft的垂直距离进入跑道时,飞机的接地时间会变慢,从而导致接地距离变长。此外进近速度偏大会导致飞机下降率大,飞行员有可能拉杆防止重着陆,这也可能导致飞机接地距离变长。根据以上分析,选取了某航空公司在飞行品质日常业务工作中常用的20个QAR参数。这些参数既包含接地点远事件直接机理因素数,也含有飞机姿态和运行状态的相关参数。表1给出了20个参数名称及意义说明。

表1 参数说明Table 1 Parameter description
在训练检测接地点远事件的HMM 过程中有2个重要参数:一个是QAR样本的片段个数,另一个是QAR样本符号化过程中K-means算法的聚类数目K。本文中采用步长为2的滑动时间窗口将每个QAR样本划分为6个不等长的多维时间序列片段。K-means算法的K值由肘部法确定。图5为肘部法确定符号个数过程中,聚类数目K与平均畸变程度的变化趋势。其中图5(a)为QAR样本符号化的实验结果,当K=8时,平均畸变程度变化较高,因此符号个数取为8;图5(b)为QAR样本片段符号化的实验结果,当K=5时,平均畸变程度变化较高,故符号个数取为5。
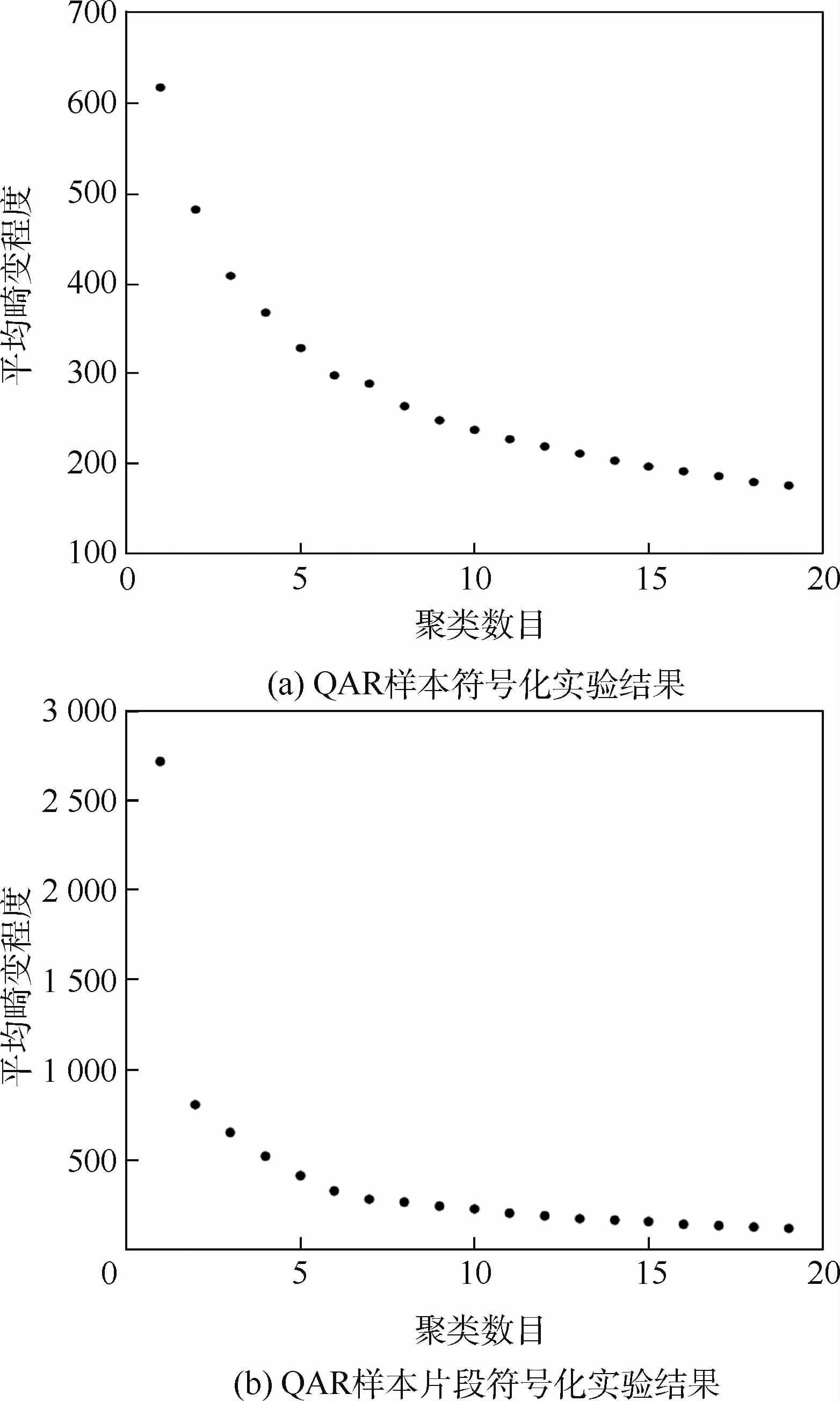
图5 聚类数目K与类簇平均畸变程度的变化趋势Fig.5 Changing trend between clusters number K and average distortion degree of cluster
2.2 接地点远事件检测实验结果
为了验证LTED-LSTM-HMM 方法的有效性,分别采用了文献[12]和文献[14]提出的多维时间序列异常检测方法做对比。文献[12]分别采用主成分分析(principal component analysis,PCA)和FCM将多维时间序列转化成单维时间序列,再基于正常单维时间序列进行HMM 建模,将训练后的HMM用于异常检测;文献[14]提出了基于自编码器和HMM的多维时间序列异常检测方法(autoencoder and HMM-based anomaly detection,AHMM-AD),该方法的实现原理与LTED-LSTMHMM方法相同,主要区别为:AHMM-AD方法采用具有3层神经网络的自编器学习多维时间序列片段的低维特征表示。实验结果如表2所示。

表2 异常航班数据检测的对比实验Table 2 Comparison experiment of abnormal flight data detection
从表2中的准确率、召回率、F1值可知,基于PCA和HMM的方法异常检测效果较差,可能的原因是:PCA对QAR样本降维时,只取了线性变换后方差最大方向上的样本信息,忽略了其他投影方向上的信息。基于FCM 和HMM 的方法引入隶属度的量化方法描述了QAR样本的各参数取向量与符号的关系,在符号化转换过程中使用了所有QAR参数信息,故异常检测效果有所提高。AHMM-AD方法的实验结果显示准确率比PCA+HMM、FCM+HMM方法提高了约0.06,但F1值分别减少了0.039和0.041。这主要是因为:AHMM-AD方法在符号序列之前对QAR样本片段进行了非线性的特征表示,但该方法只能处理等长多维时间序列数据,表示学习过程中将QAR样本划分为了窗口大小为28的等长时序片段,在划分不等长的QAR样本时去除了部分数据,这导致了召回率和F1值降低。LTED-LSTM-HMM方法通过固定时间序列分段数解决了不等长QAR样本的特征表示问题,而且基于LSTM自编器的表示考虑了QAR样本片段内的时序信息。本文的LTED-LSTM-HMM方法与AHMM-AD方法相比,准确率提高了约0.11,召回率提高了0.286,F1值提高了0.171,实验结果表明了本文方法的有效性。
2.3 接地点远事件位置检测实验结果
为便于分析发生接地点远事件的原因,缩小查找异常QAR参数的范围,依据领域专家经验,选取表1中的左右迎角、俯仰角、倾侧角、方向舵偏角、空速、垂直加速度、纵向加速度、下降率8个QAR参数取值训练用于检测接地点远事件位置的HMM 模型λ2。使用22个正常QAR样本和31个接地点远事件QAR样本的318个数据片段作为测试集。QAR片段的每个位置都有表征是否接地点远事件的标签,该标签由QAR译码软件标注。模型λ2的接地点远事件位置检测准确率为78.2%,位置检测准确率由检测出的真实接地点远事件时刻点总数除以检测出的接地点远事件时刻点总数计算。图6为某QAR样本片段实际状态值序列与异常检测结果状态值序列的对比,状态值1表示该位置异常,状态值0表示该位置正常。图6的实线中取值为1的部分表示发生接地点远事件的真实位置,虚线中取值为1的部分表示本文模型检测出的发生接地点远事件位置。虚线取值为1的片段可以覆盖实线取值为1的部分,因此本文方法能在QAR片段内正确标识出发生接地点远事件的位置。从实验结果中还发现,接地点远事件位置大多出现在QAR样本片段的开始部分。

图6 真实与异常检测结果状态值序列对比Fig.6 Comparison of state value sequence between real and anomaly detection results
选取2.2节实验过程中离检测阈值较近的观测概率较高的2个发生接地点远事件的QAR样本和观测概率最低的正常QAR样本的原始参数取值进行对比。图7分别展示了4个样本在发生接地点远事件的片段10 s内空速、俯仰角、左迎角、纵向加速度、下降率5个QAR参数取值变化趋势。从图7(a)可知,发生接地点远事件的3个样本空速都低于正常样本的取值。但是根据领域专家经验,着陆过程中空速越大越容易发生接地点远事件。本文中发现的3个样本虽然空速较低,但却出现了地速偏大造成接地点远事件的情况。结合其他5个参数的取值原因分析如下:①从图7(b)和图7(c)可以看出,发生接地点远事件的3个样本的俯仰角、左迎角片段取值较大,为了获得合适的升力,飞行员有可能收油门降低速度。另外从图7(e)中无接地点远事件样本的下降率变化趋势整体高于其他3个异常样本。俯仰角大,下降率低都有可能延长飞机下滑拉平距离,导致飞机超出接地区接地。②从图7(d)可知,接地点远事件样本2和样本3的减速方向上的纵向加速度大于正常样本,这使得接地点远事件样本2和样本3的空速低于正常样本。但从图7(e)发现,样本2和样本3的下降率比正常样本低很多,这有可能是飞行员为了防止大下降率,造成重着陆事件,从而延迟了飞机接地时间。

图7 有无接地点远事件QAR样本典型参数取值对比Fig.7 Comparison of typical parameter values between the normal and the long touchdown exceedance QAR sample
3 结 论
1)LSTM自编码器能较好地学习反映不等长QAR样本的特征表示,因此与已有的基于HMM的多维时序异常检测方法相比,LTED-LSTMHMM方法能更好地检测包含接地点远事件的航班。
2)通过QAR样本片段建立的HMM和Viterbi算法,本文方法能以较高的准确率确定接地点远事件在QAR片段内的发生位置,由此得到除地速之外的其他QAR参数异常取值,辅助领域专家分析发生接地点远的原因。
下一步可把本文方法推广应用于其他典型超限事件检测及分析,以期提高航空安全管理水平。
