基于数字孪生自动色环机的设计知识图谱研究*
2022-04-26王佳皓张太华
王佳皓,张太华
(1.贵州大学现代制造技术教育部重点实验室,贵阳 550025;2.贵州师范大学机械与电气工程学院,贵阳 550025)
0 引言
数字孪生体是连接物理空间和知识空间的桥梁和纽带,通过它来提高产品创新能力和产品附加值,而产品知识的支持是提升数字孪生体质量的关键要素。目前,关于数字孪生体及知识管理方面的研究已得到国内外学者和业界的高度重视,并取得了一定的成果。庄存波等[1]把数字孪生体定义为与真实物理实体完全一致的数字虚拟模型,可实时模拟自身在真实世界中的性能和行为。陶飞等[2]对基于数字孪生体的产品设计和工艺设计进行研究和分析,指出基于数字孪生体的产品设计表现出新的转变和新突破,其中提到新设计知识和工艺知识挖掘、分析与建模等关键点。于勇等[3]基于数字孪生体的工艺知识挖掘可全面有效地挖掘和总结行业工艺“设计经验”和“设计知识”。
目前关于知识推理的研究,官赛萍等[4]总结了基于传统的知识推理、单步推理、多步推理所包含的推理方法。马忠贵等[5]总结了知识图谱的技术架构,从知识抽取、知识融合、知识推理三个方面进行了系统性阐述并作出展望。自动色环机按照设计要求进行计算后,在方案制定时需要对零器件进行选型,以在满足客户要求的同时降低设备的成本。但是对于零器件的选择需要咨询相应的厂家,并按照厂家提供的图纸对产品数字孪生体的几何模型进行反复修改或者重建。而且在以往的设计过程中,产品设计公司往往累积了大量的设计知识。但是,设计人员的设计能力各不相同,设计的效率也差异较大。所以如何利用整合公司的设计知识与设计人员的设计经验以达到知识的快速推理,为创建产品数字孪生体提供服务是这类公司迫切需要的。
所以,在产品数字孪生体的构建过程中,对产品功能性能、结构层次、几何特征、产品特性等方面知识图谱进行推理,可以提升物理产品的创新水平和质量,从而提供宏观尺度和微观尺度的产品知识服务支持,方便产品数字孪生体构建人员进行知识的理解、查询和应用,提高产品数字孪生体构建的质量及效率。
1 产品数字孪生与知识图谱技术
1.1 产品数字孪生
产品数字孪生体是产品的物理实体在虚拟空间的映射。构建产品数字孪生体不止是构建相应的虚拟样机,虚拟样机主要用于验证在设计初期系统的某些关键决策,提高系统的安全系数[6]。本文设计的自动色环机用于对航天连接器中的插孔和插针的外表面进行上色,如图1所示。本文的设计要求自动色环机数字孪生体可以根据用户的需求进行改进,并随时与设计需求进行交互优化;模拟工艺流程以验证该工艺的可行性,并且对工艺执行过程有动态的可视化认识;检查装配过程是否有干涉等问题存在。
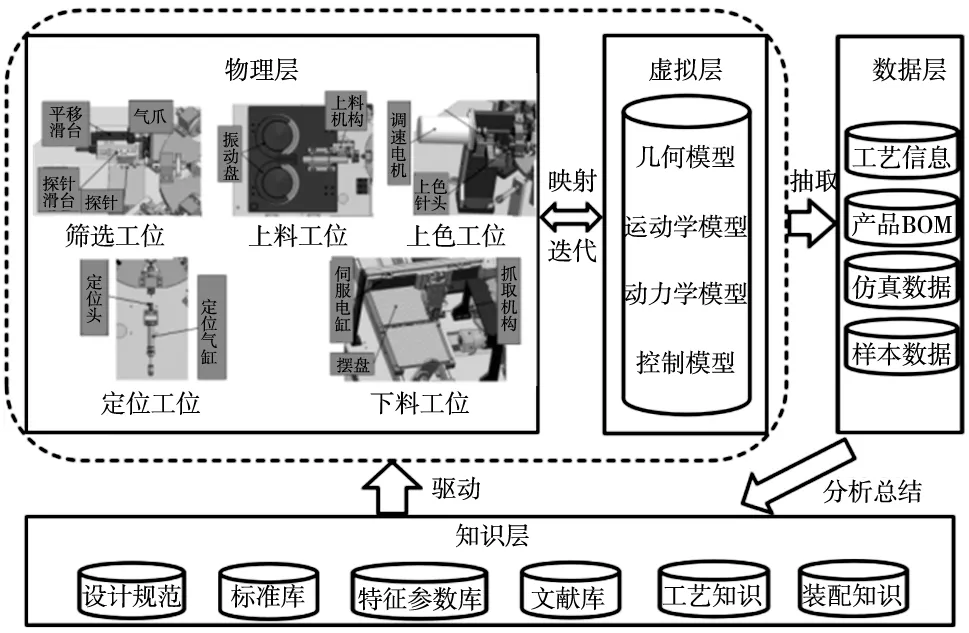
图1 产品数字孪生的设计框架
李浩等[7]提出了基于数字孪生的复杂产品设计制造一体化体系,对比了传统设计与基于数字孪生的设计方法,从3个方面构建了基于数字孪生的复杂产品设计制造体系框架。本文主要讨论自动色环机的产品数字孪生体虚拟设计过程。如图1所示,自动色环机的设计流程由以下4个方面组成:

图2 自动色环机本体(部分)图
(1)用户需求。自动色环机的设计要求设备除人工添料外,插孔插针所有零件实现自动上料排序功能;实现自动识别插针插孔孔径大小功能;实现识别插针插孔孔径后上指定颜色;实现自动摆盘;完成上色后成品应满足图纸要求;生产速度3~5 s/件。
(2)方案设计。自动色环机的方案设计包括机械系统、工艺设计和控制系统设计。在此过程中需要对机械结构、工艺流程、控制系统进行设计或选型并优化以确保最终方案的可行性。
(3)建立虚拟模型。如图1所示,本文建立了自动色环机的虚拟模型。此设备由振动盘、分割器、滑台摆盘、下机柜、上机罩、操作臂6大部分组成。
(4)样机装配与调试。在自动色环机组装过程中可能会产生新的误差。因此,需要在确定自动色环机虚拟模型高保真的前提下对实物样机进行装配与验证。如果未达到预期目标,则需要进行校准。
基于自动色环机设计流程,本文总结了其基于数字孪生的自动色环机设计框架,如图1所示。
物理层包括筛选工位、上料工位、上色工位、定位工位、下料工位共5个功能模块。通过分度转盘将这5个功能模块连接起来实现对插孔或插针在各个工位的流转。各个工位主要通过气缸、电机进行插针或插孔的拾取与摆放,用探针来筛选合格品。
虚拟层主要建立了自动色环机的虚拟模型,其中包括了几何尺寸、装配关系、运动逻辑等;对每一模块进行动力学和运动学进行仿真,检查干涉、时序、速度、受力分析等问题;建立控制模型,进行控制仿真。
数据层将物理层和虚拟层所产生的数据信息抽取到数据层中,包括了工艺信息、产品BOM、仿真数据、虚拟样机数据等。
知识层在自动色环机的设计过程中会使用很多知识,同时也会产生新的知识。新的知识可以从大量的数据中分析总结而来,同时知识层包含已有的知识。这些知识可以很好地驱动自动色环机的设计。
1.2 知识图谱技术
知识图谱是知识库的一种,是知识的一种可视化表示、逻辑化组织、关联化储存形式。知识图谱的构建通常基于语义知识,利用语义符号和符号的链接描述各个实体间的关系,最终形成一个便于人理解的图结构。
类似自动色环机这样的非标自动化设备的在产品数字孪生体创建中会产生大量的设计知识与数据。因此,结合产品数字孪生与知识图谱技术对自动色环机进行设计可以快速高效可靠地形成设计方案。基于产品数字孪生设计的4个阶段,我们可以先创建基于知识图谱的初本体。所谓初本体,是指在创建产品数字孪生体过程中提取的本体,用来在知识图谱创建中关联知识抽取的范围。
如图2所示,基于产品数字孪生,本文用对自动色环机的初本体进行初步建模,为后续知识图谱建立提供参考和依据。
自动色环机设计的知识图谱属于垂直行业知识库,属于封闭域[8]。知识图谱构建过程主要由知识抽取、知识融合和知识推理3部分构成。将知识图谱技术应用于自动色环机的设计形成了图3的设计体系框架,也为类似产品设计开发提供理论参考。如图所示,结合初本体与PDM、标注库、行业库进行知识抽取,形成三元组。三元组中实体与属性存在映射关系,各个实体间通过关系相互连接。知识融合则通过基于属性实体进行实体对齐与链接。形成的产品研制知识库适用于类似自动色环机的设备研究,形成产品系列开发设计知识库。由此知识库中基于设计需要与实体属性可以抽取初自动色环机设计知识图谱,最后本文进行知识推理以发现更多路径以改善自动色环机的设计。

图3 自动色环机知识图谱构建框架
1.2.1 知识抽取
知识抽取主要从大量的结构化、半结构化与非结构化的设备设计知识中抽取出实体、关系与属性。自动色环机的知识抽取范围主要在企业产品数据、标准库与行业库。
(1)实体抽取。自动色环机设计所需要的知识从企业产品设计流程、部门论文、知识点、参考资料、标准库与行业知识库进行抽取。企业设计该类型的设备的零部件种类与数量有限,所以可以采用基于规则和词典的方法[9]进行实体抽取。
(2)关系抽取。根据图2可以看出自动色环机的实体间关系相对简单,可以采用基于规则模板的方法进行实体关系抽取,具有较高的准确率。但是此方法的人力成本较高,故可以采用半监督学习的方法对实体关系进行抽取。
(3)属性抽取。自动色环机所构成的实体属性主要有尺寸、形状、运动参数、功率等。这些属性决定了实体是否适用于自动色环机的设计,而且每一个实体具有独特的属性。因此,它与实体之间有着映射关系。
1.2.2 知识融合
自动色环机设计过程中所涉及的知识来源多样,可能存在知识重复、知识表现形式不同等情况,例如同一实体的不同表述指向同一属性。知识融合需要把这些知识、数据进行整合、合并,最终形成对知识的正确表述。本文在自动色环机的设计过程主要涉及实体对齐与实体链接两部分。
(1)实体对齐。对于自动色环机的同一实体,由于生产厂家的不同可能有两种叫法,例如感应器和传感器。通过实体对齐,将这类同义不同名的实体合并为同一名称。对于本文实体来说,属性是其区分不同实体的重要依据。所以,可以基于实体属性对实体进行对齐。
(2)实体链接。在已建立的自动色环机设计知识库基础上,给定一个外来文本,实体链接需要将外来文本的实体对应到已有知识库的实体。对于知识库中不包含的实体,则将该实体添加到知识库中。对于添加依据,则可以依据实体属性与原有知识库中相似命名实体进行比较,其主要通过计算实体属性中字符串的相似度来判断两个实体是否相同。
1.2.3 知识推理
本文对自动色环机设计知识图谱的知识推理进行研究,将部分知识图谱其代入强化学习环境,建立了知识推理框架模型,以便后续类似非标自动化设备开发。自动色环机的知识推理框架模型如图4所示。
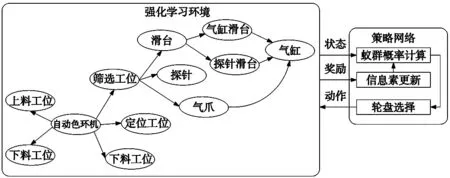
图4 自动色环机知识推理框架模型
2 基于强化学习与蚁群算法的知识推理算法
2.1 平移原则与TransE
基于平移的知识图谱表示的基本思想是把知识图谱中的每一个三元组都映射在几何空间上,使知识图谱的图结构在几何空间具有一致性[9]。
TransE模型的基本思想:在知识图谱中,每一条知识都由一个三元组(h,r,t)表示,即头实体、关系、尾实体。知识图谱的TransE表示模型希望对每一个实体都分配一个表示向量e,即头实体向量h,关系r,尾实体t,且它们的关系为:
h+r=t
模型的目标是使知识图谱中的每一个三元组在几何空间中都是平移关系,则可以求解优化目标。
2.2 基于强化学习的路径发现
强化学习[10]的主要思想主要是把推理过程看做是马尔科夫决策过程。强化学习很好地利用了知识图谱的嵌入表示,通过对奖励函数与策略网络的构建建立模型。
马尔科夫决策过程(MDP)由一个四元
依据文献[11],本文的全局奖励为:
(1)
另外,较短的路径比较长的路径更加有效率,路径效率的奖励函数为:
(2)
式中,lengthp为可达路径的距离。
2.3 策略网络的设置
本文对于智能体Agent的设置采取蚁群算法[12]的路径选择策略:
(3)
式中,i、j分别为路径的起点和终点;τij为t时间i到j的信息素浓度;ηij=1/dij为能见度,是两点i、j间距离的倒数;allowedk为尚未访问过的节点的集合;α是信息启发式因子;β是期望启发式因子。
计算完访问各个实体的概率之后,采用轮盘赌的方法选择下一个访问的节点。为了不让蚂蚁选择已经访问过的节点,采用禁忌表来记录蚂蚁走过的路径。当蚂蚁到达目标实体,将禁忌表中记录的路径转移给可达路径p,并清空禁忌表。
2.4 信息素更新
在蚁群算法中,信息素的更新是蚁群算法的核心。其公式如下:
(4)

(5)
式中,dij为第k只蚂蚁走完路径后所得到的路径的总长度。
在本文中达到目标实体后,信息素按照如下方式更新:
(6)
Rtotal=γ1×rglobal+γ2×rrefficiency
(7)
式中,γ1、γ2为控制迭代速度的参数。
通过将强化学习的奖励代入到蚁群算法的信息素更新中,对算法进行了创新,使算法不仅能求解多种路径,并且在求解知识图谱可达路径中的最短路径中能够快速实现。算法流程如图5所示。

图5 算法流程图
3 实验过程与结果
首先基于平移原则与TransE模型将各个实体映射到坐标系中,最终得到各个实体在二维坐标平面上的坐标值如表1所示。

表1 实体坐标值
各个实体之间的距离即为各个关系向量的模。根据策略网络,将初始信息素浓度设置为1,α设置为1,β设置为2,根据式(3)计算得到各个实体之间选择的概率如表2所示。
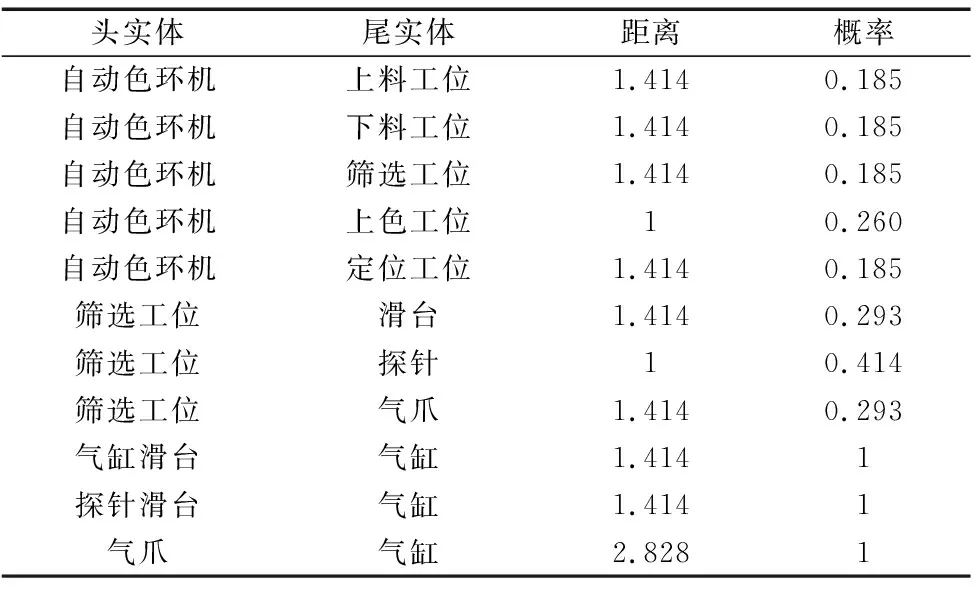
表2 实体间距离与选择概率
根据各个实体选择的概率,采用轮盘赌的方式来选择从一个实体到另一个实体。
在本文中,通过智能体决策的下一个实体可能为空,如图4所示到达上料工位时,下一个实体为空,这时的奖励函数为-1,智能体重新回到上一个状态。通过设置max_step来限制智能体返回的次数。本文设置最大搜索次数为10次。
实验结果如图6所示,起始的实体为自动色环机,坐标点为(0,0);目标实体为气缸,坐标为(4,2)。经过多次训练后,寻找到可达路径如表3所示。
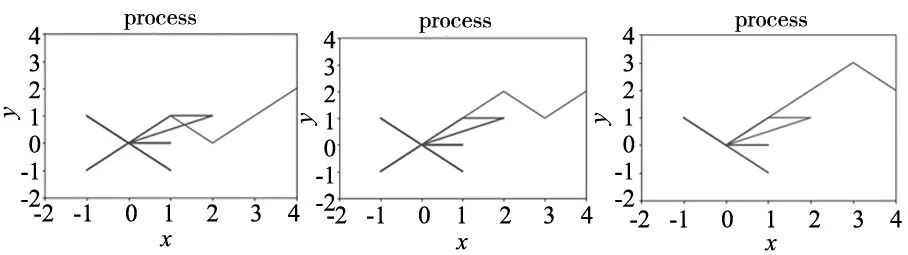
(a) 路径1 (b) 路径2 (c) 路径3图6 3种路径结果
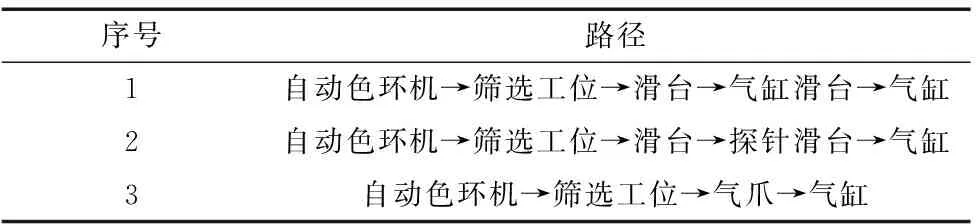
表3 可达路径
在一次到达目标实体后,记录可到达路径。通过式(4)、式(5)、式(6)、式(7)对信息素进行更新。通过信息素的更新,可以使得新一轮的寻找路径速度加快。本文可以通过设置参数γ1、γ2与信息素的挥发速度系数来控制迭代速度。将信息素挥发系数为0.5,将可达路径上的信息素浓度为其他路径上1000倍作为稳定状态条件,结果如表4所示。

表4 算法达到稳定迭代次数
根据表4,通过将蚁群算法信息素更新和结合强化学习奖励的信息素更新进行对比,可以看出改进后的算法迭代次数降低一倍,可以快速收敛,由此可见结合强化学习和蚁群算法可以有效降低运算时间。但是,若将γ1、γ2设置过大,容易陷入局部最优,所以本文将γ1、γ2设置为2进行迭代。实验结果如图7所示,以其中一条路径为例,每次迭代后,经过信息素的更新,选择可达路径上的信息素浓度有效累积,最终达到稳定状态。
(a) 第1次迭代 (b) 第2次迭代
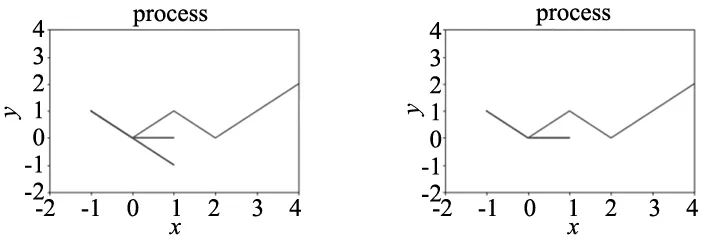
(c) 第3次迭代 (d) 第4次迭代
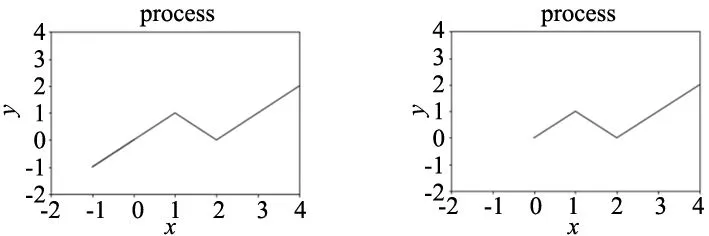
(e) 第5次迭代 (f) 第6次迭代
4 结束语
本文结合了数字孪生与知识推理,对自动色环机进行了虚拟设计和本体建模,设计了基于数字孪生和知识图谱的自动色环机设计框架,为类似设备的设计提供参考;结合强化学习和蚁群算法对知识推理的算法进行了研究。其中,采用TransE将知识图谱转化为坐标向量;将蚁群算法中的路径选择与信息素更新当做强化学习的策略网络,对信息素的更新进行了改进。结果说明算法再经过多次训练后,可以快速找到起始实体与目标实体的路径,为以后知识推理算法的研究提供参考。
