分布轮廓与局部特征融合的云模型不确定性相似度量
2022-04-21王国胤
代 劲 胡 彪 王国胤*③ 张 磊
①(重庆邮电大学计算智能重庆市重点实验室 重庆 400065)
②(重庆邮电大学软件工程学院 重庆 400065)
③(重庆邮电大学旅游多源数据感知与决策技术文化和旅游部重点实验室 重庆 400065)
1 引言
不确定性是客观世界的真实存在,直接导致作为信息加工与知识获取的人类认知过程具有显著的不确定性特点。此外,从视知觉拓扑结构和功能层次来看,人类认知还存在“整体优先”(全局认知优于局部特征)特点[1],通过大范围优先策略形成对目标的快速判断,并不需要大脑进行精确的、深层次的定量分析,一定程度上加剧了认知的不确定性。因此,随着海量数据分析与挖掘任务的急剧增长,研究不确定性知识的表达、处理,寻找并且形式化地表示不确定性知识中的规律性,让机器模拟人类的认知过程,使其具有智能,成为当前人工智能领域的研究热点[2,3]。
概念是知识表达的基本组成,认知的不确定性也不可避免导致概念存在较大的不确定性。其中随机性和模糊性是不确定性的最基本内涵,而对应的概率论[4]、模糊集[5]、粗糙集[6]等理论模型在实践应用中都存在一些不足。例如,在模糊集合中,隶属度通常是依据专家的先验知识给定的,具有较强的主观性;在概率论中,最基本的假设是排中律,但自然语言中的概念则未必满足该假设;在粗糙集中,还存在着过拟合难题,导致数据挖掘效率不高。究其原因,以上理论对于认知的不确定性理解还存在一定的片面性[7]。在概率论和模糊数学基础上,云模型[8]从概念的随机性和模糊性角度综合进行不确定性分析,建立了定性模糊概念与定量精确数据的双向转换模型,较好地解决了概念的不确定性表示及转换,广泛应用于决策分析、智能控制等领域[9–12]。作为云模型的重要研究内容,基于云模型的不确定性相似度量(简称相似度量,以下同)也越来越受到学者重视。例如在决策系统评估中,运用云相似性度量给出的结果更符合人的认知[13];在协同过滤推荐系统中,基于用户喜好的相似度量可有效提高推荐的精度[14]。
现有的云模型相似度量方法主要集中在基于精确数值的量化计算或基于云模型本身的形状特征方面,度量结果具有较大的片面性,不能充分体现云模型的随机性与模糊性特点,需要将两者进行综合考虑。基于此思路,借鉴“大范围优先”理论基础[15],本文提出了一种结合云模型整体几何特征与微观云滴分布贡献的不确定性相似度量方法。该方法首先利用较大范围(即粗粒度)上云模型整体几何特征(包络带)来确定云模型间的相似性计算范围;其次,在此计算范围内,结合云模型的微观云滴分布贡献,最终得到综合考虑粗粒度和细粒度两方面的度量结果。
基于以上策略,本文提出了一种基于包络带及其云滴贡献度的云模型不确定性相似度量方法(Envelope Area of the Contribution based on Cloud Model, EACCM),该方法利用两个云模型的含贡献度包络带重叠面积来衡量其相似性,综合考虑了云模型模糊性与随机性两方面的特点,其相似度量结果更加合理可信。本文的工作及创新主要如下:
(1)分析了当前云模型相似度量方法存在的问题,提出了从整体定性形状结合微观定量贡献度综合进行度量的策略,并在此基础上进一步提出了基于包络带及其云滴贡献度的云模型相似度量方法;
(2)借助云模型数字特征对本文方法进行深入分析,揭示相似度变化趋势及特点;
(3)通过仿真实验对比其他几种方法,证明本文方法其度量结果更为科学合理,更贴合实际情况。
2 相关研究
云模型相似性度量的首要问题在于选取合适的相似性计算模型。现有的云模型相似性度量方法主要包括以下几类方法:
(1)基于随机云滴的距离度量方法。例如,SCM(Similar Cloud Measurement)[16]方法基于云滴之间的距离计算云之间的相似度,但由于云滴的选取具有一定的随机性,因此会造成度量结果不稳定,而且对大量云滴进行距离的计算会带来较高的时间复杂度;文献[17]提出了一种基于α截集的云相似度计算方法,该方法通过计分函数计算相似度,但是计算结果依赖云滴的数量,稳定性差。
(2)基于云模型数字特征的度量方法。例如,LICM(LIkeness comparing method based on Cloud Model)[14]方法将云模型的3个数字特征组合在一起作为一个向量,利用两个向量夹角的余弦值来衡量云之间的相似性,然而该方法只考虑了云模型数字特征而并没有考虑云模型的整体分布特征,而且当某个数字特征占优时,会忽略其他数字特征的影响,产生较大的误差;PSCM[18]方法(Position and Shape based Cloud Model)将云相似度分为形状相似度和位置相似度,利用云模型数字特征分别计算这两方面的相似度,然后将两者相乘得到最终的云相似度,该方法较好地解决了计算复杂度高的问题,但主观地将形状相似度与位置相似度进行简单运算缺乏合理性。
(3)基于云模型几何形状特征的方法。如ECM(Expectation based Cloud Model)方法[19]、MCM(Maximum boundary based Cloud Model)方法[19]、CCM(Concept skipping indirect approach of Cloud Model)方法[20]等。这类方法以云的特征曲线与横轴围成的重叠面积作为衡量依据来度量云模型的相似性,计算复杂度较低且结果稳定,但是并没有准确地描述云的整体分布特征,从而导致以该重叠区域作为相似性标度缺乏合理性解释。
以上方法各有优势,但也存在不足之处:将云模型整体几何形状特征与微观云滴分布分离,度量结果具有较大的片面性。因此,迫切需要一种融合以上方法特点,综合考虑云模型几何形状特征与不同位置云滴分布贡献度差异的相似性度量模型。
3 理论基础

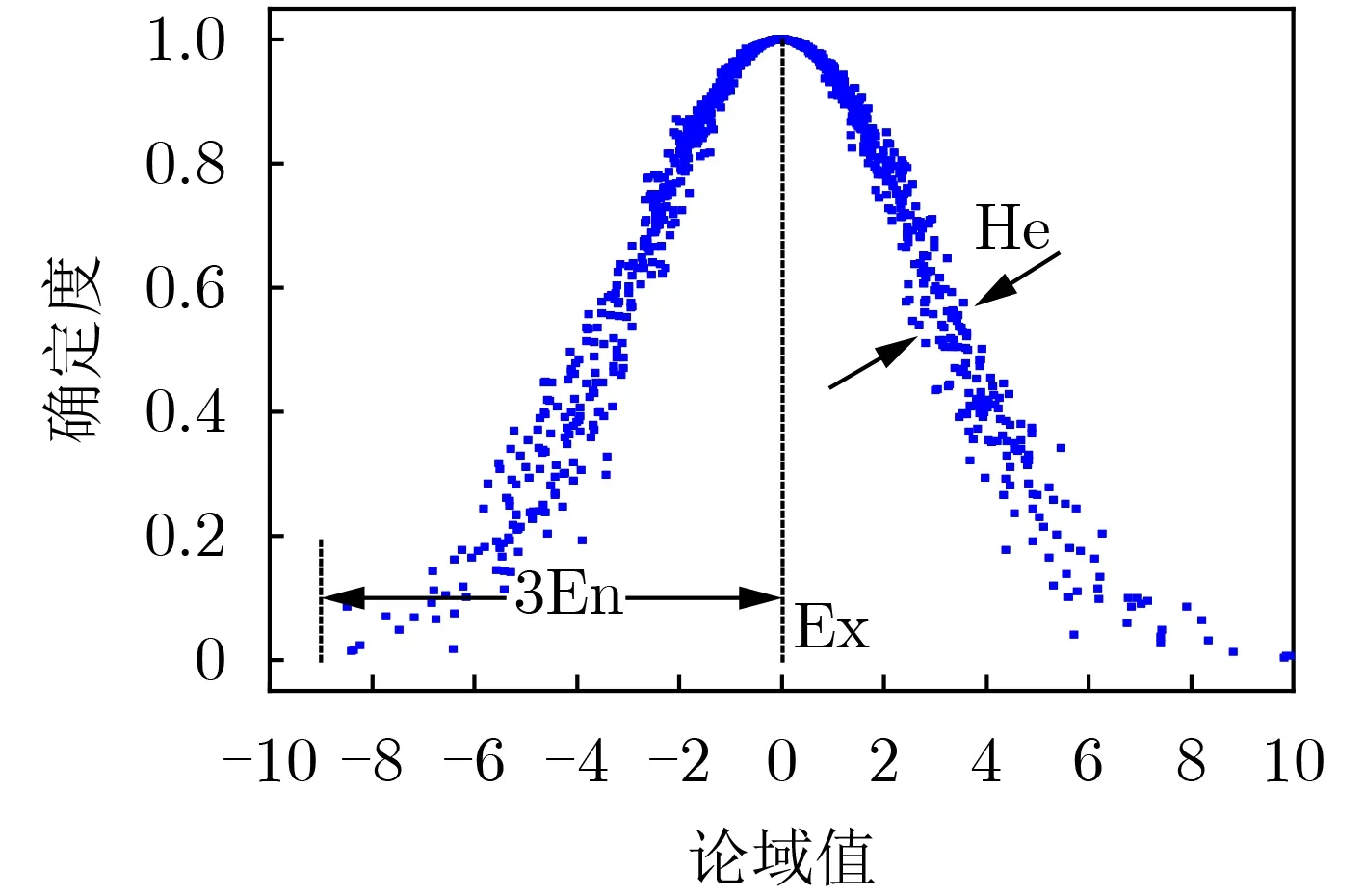
图1 正态云模型(0,3,0.3)
根据外包络曲线和内包络曲线的 3σ原则,包络带有以下性质:(1)横轴在[Ex−3(En+3He),Ex+3(En+3He)]之外的区域因贡献度非常低,不将其纳入包络带的计算范围内。(2)将横轴在[Ex−3(En+3He),Ex−3(En−3He)]之间的区域定义为曲边梯形(以横轴为直角边,横轴坐标为Ex−3(En+3He) 和Ex−3(En−3He)的两条线段为上下底,外包络曲线µw(x)为曲边)。同理,横轴在[Ex+3(En−3He),Ex+3(En+3He)]之间的区域也定义为一个曲边梯形(如图2所示,虚线矩形框中的阴影区域为曲边梯形,图中整个阴影区域就是本文所指的包络带)。
定义3 云滴贡献度[21]
1维论域U中,任一小区间上的云滴群Δx对定性概念C的贡献度为ΔA为,具体为

4 云模型相似度量方法
正态云是目前研究最多也是最重要的一种云模型,而且正态分布的普适性与钟形隶属函数的普遍性共同奠定了正态云模型普遍性的基础。基于此,本文所研究的相似性度量方法也是针对正态云模型。
4.1 相似度量策略
定性概念是认知的核心内容,其主要通过概念内涵与概念外延进行不确定性表达。因此,基于云模型的相似度量也应从概念内涵与外延展开。其中,概念内涵往往是根据大量的概念外延对象进行抽象而成的,其本身就具有一定的抽象性,不适合直接用于精确的相似性度量。因此,本文选择了基于云模型云滴的分布—即概念的外延来进行相似度量。
此外,云模型本质是一个边界模糊的泛正态分布,如何合理地描述正态云图(正态云模型的几何特征),即云滴的分布特点具有重要意义。理论上,表征某个定性概念的云是由无数个云滴组成的,而通常只用正向云发生器生成的有限云滴来描述整体云的大致几何形状,并进行概念定性表征。这些有限的云滴实际上不足以来描述云模型的整体特征,在此基础上度量云之间的相似性是不可取的。虽然云滴的确定度具有一定的随机性,但是根据第3节定义2可知,云滴绝大部分都是分布在包络带中。因此从概率上分析,用包络带来表示云滴分布区域更为合理。
基于以上分析,可进一步探究云模型相似性的度量方法。在云模型对定性概念的外延描述中,一个云滴代表的是定性概念在数量上的一次实现,云滴数量越多,越能反映这个定性概念的整体特征。在极限情况下,若云滴的数量趋于无穷大,则所有云滴必然会形成一个平面区域,在概率上可以近似等同于包络带。此时该平面区域可以最大限度地反映这个定性概念的整体特征,即云滴的分布特征(云模型的整体几何特征)。因此,通过云间的包络带进行相似度量,相当于是用两个定性概念的整体特征来进行相似性度量,显然更具有合理性。
4.2 包络带与局部云滴贡献相结合的相似度量模型

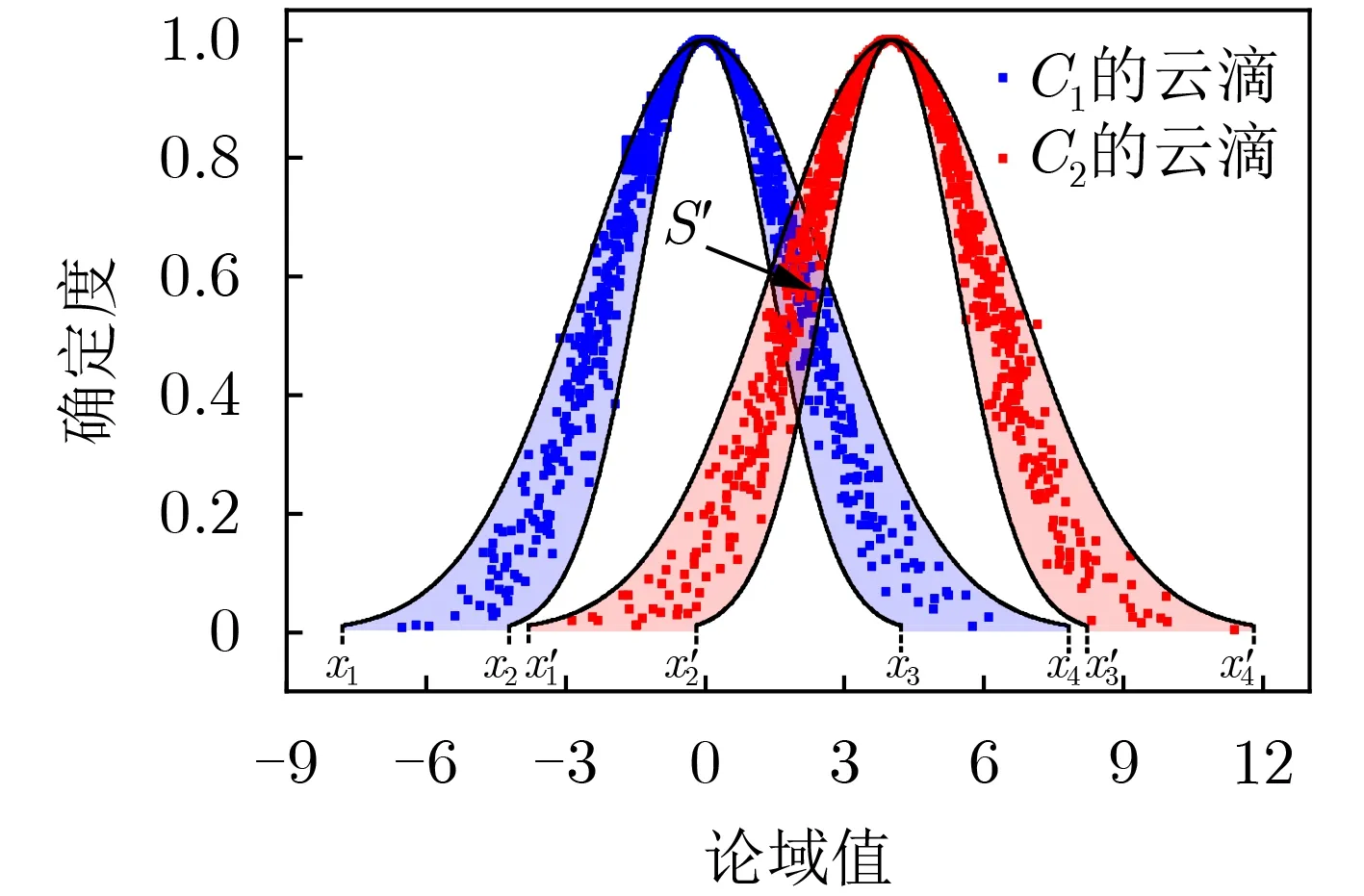
图3 云C1(0,2,0.2)和 C2(4,2,0.2)包络带重叠区域


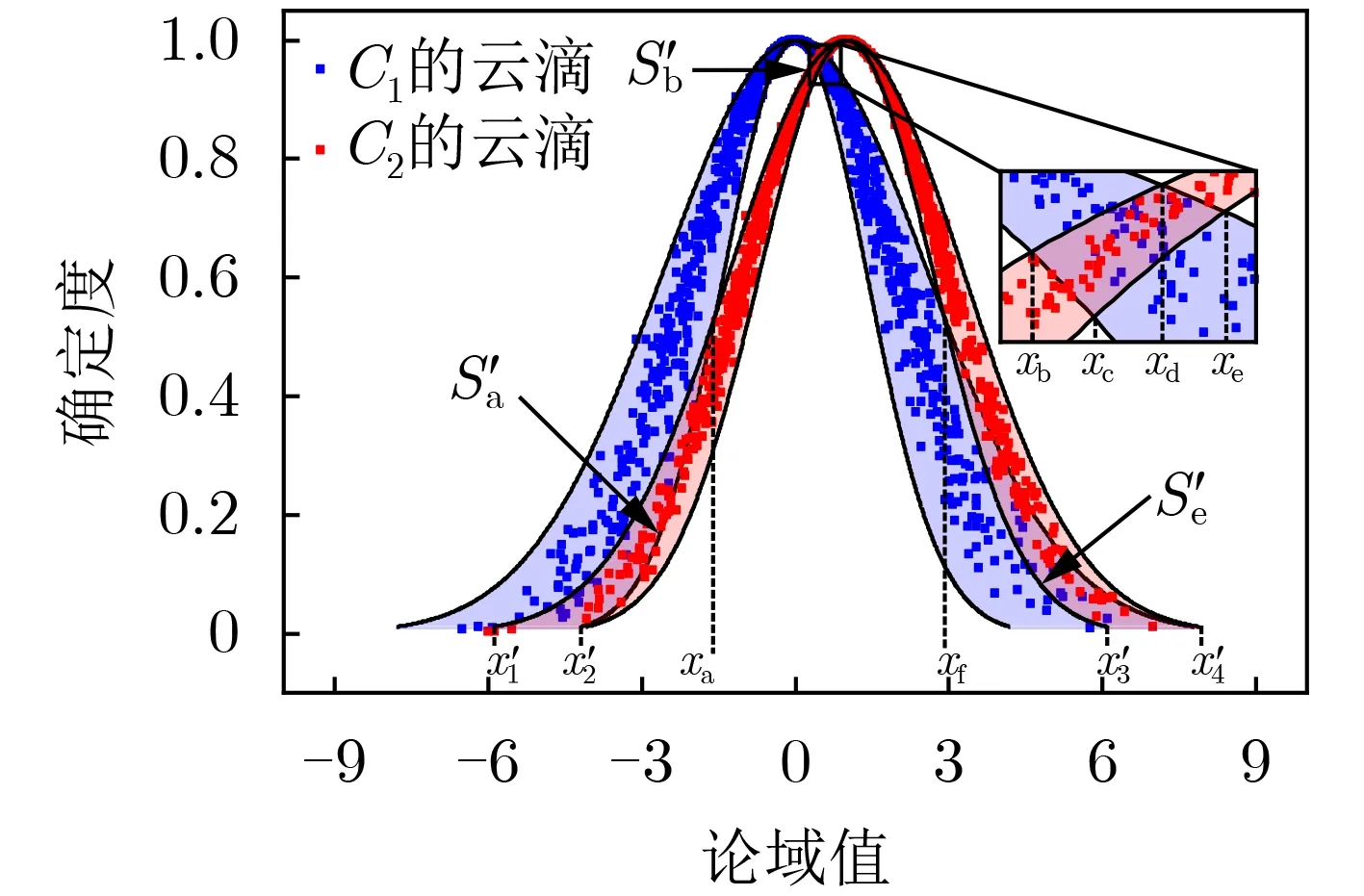
图4 云C1(0,2,0.2)和 C2(1,2,0.1)包络带重叠区域


5 相似度的影响因素及性质分析
5.1 位置对相似度的影响
根据两个云模型形状特征,可以将期望对相似度影响规律分析划分为下面两种情形:(1)一个云完全包含在另一个云的内包络曲线内(内含式);(2)两个云不存在一个云包含在另一个云的内包络曲线内(非内含式)。
(1)内含式3He1+3He2≤En1−En2。当两个云的形状特征满足:一个云完全包含在另一个云的内包络曲线内时(即满足3He1+3He2≤En1−En2),不失一般性,任取两个云模型C1(0,2,0.2),C2(0,0.5,0.1),假设Ex2变化,则可给定期望Ex2的变化过程Ex2∈[0,10.2](当超过10.2时,这两个云没有任何重叠区域)。如图6(a),其中显示了期望变化过程中两个云模型的3个典型的重叠情况,其中红色为云C2。在这个位置变化过程中,应用本文方法计算出相似度随期望变化所呈现的变化趋势,如图6(a)所示。
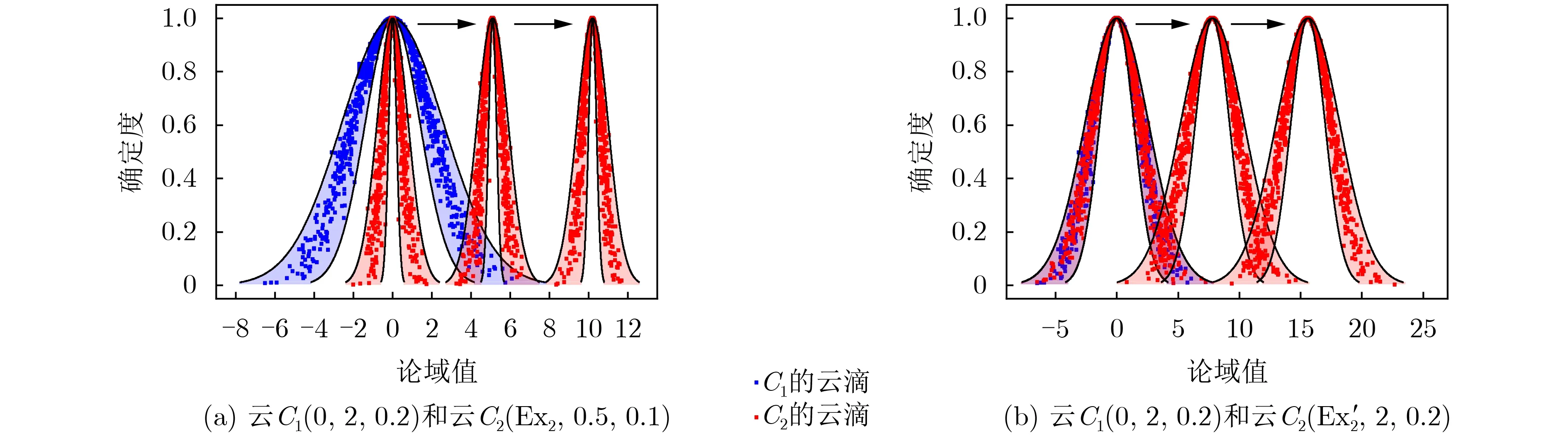
图5 云模型C 1和C 2相对位置随Ex2, Ex′2的变化
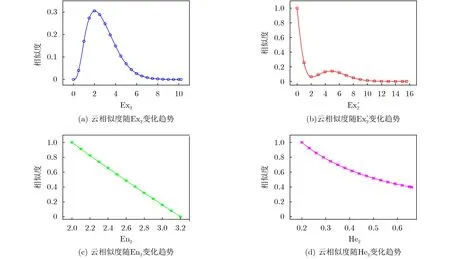
图6 相似度随Ex2, Ex′2, En2和He2变化趋势
由图6(a)可知,相似度随着期望的增大呈现先增大后减小的趋势,且开始点和结束点的相似度都为0。原因在于起始位置和结束位置两个云的重叠面积都为0,因此根据本文相似度的计算公式,此时相似度为0,而在中间位置,两个云重叠面积不为0,因此相似度随着期望的增大呈现先增大后减小的趋势且相似度存在最大值。图6(a)并不是个例所呈现出的趋势,而是所有满足内含式的云模型组其位置对相似度的影响趋势。也符合人类的认知特点:两个不同的定性概念之间的相似度不可能一直增大直到1,除非这两个概念是一样的,否则一定存在一个最大相似度。

由图6(b)可知,非内含式云模型组在开始位置时相似度为1,在结束位置时相似度为0,而且中间相似度变化并不是单调递减,而是存在波动,不具有完全一致的规律。这里出现的波动性是由云模型的形状特征(重尾分布[22])所决定的,同时这种复杂性也是由定性概念的不确定性(随机性和模糊性)所决定的:定性概念存在较大的不确定性,其变化过程中其与另一个概念间的相似度常常会呈现出波动性。
5.2 形状对相似度的影响
(1)熵 En对相似度的影响。假设初始两个云模型完全相同,不失一般性,令C1(0,2,0.2),C2(0,2,0.2)。若En2变化,可给定En2的变化过程En2∈[2,3.2](当En2≥3.2时,由5.1节的情形1可知相似度为0)。图7(a)和图7(b)显示了熵En2变化过程中开始和结束时两个云模型的重叠情况,其中红色为云C2。在这个形状变化过程中,应用本文方法计算出相似度随熵变化所呈现的变化趋势,如图6(c)所示。
由图6(c)可知,在开始位置时,云C1与云C2完全重叠,相似度为1,随着En2的增大,两者的相似度逐渐减小,直到云C1完全被包含在云C2的内包络曲线内,即5.1节中情形1的情况,此时相似度为0。图6(c)说明当两个云的期望和超熵相等时,其形状相差越大(熵相差越大)则相似度越低。当两个云的期望和超熵不相等时,不具有完全一致的规律。
(2)超熵 He对相似度的影响。假设初始是两个云模型完全相同,不失一般性,令C1(0,2,0.2),C2(0,2,0.2)。若He2变化,可给定He2的变化过程He2∈[0.2,0.66](当3He2≥En2时,云C2雾化)。图7(a)和图7(c)显示了超熵He2变化过程中开始和结束时两个云模型的重叠情况,其中红色为云C2。在这个形状变化过程中,应用本文方法计算出相似度随超熵变化所呈现的变化趋势,如图6(d)所示。
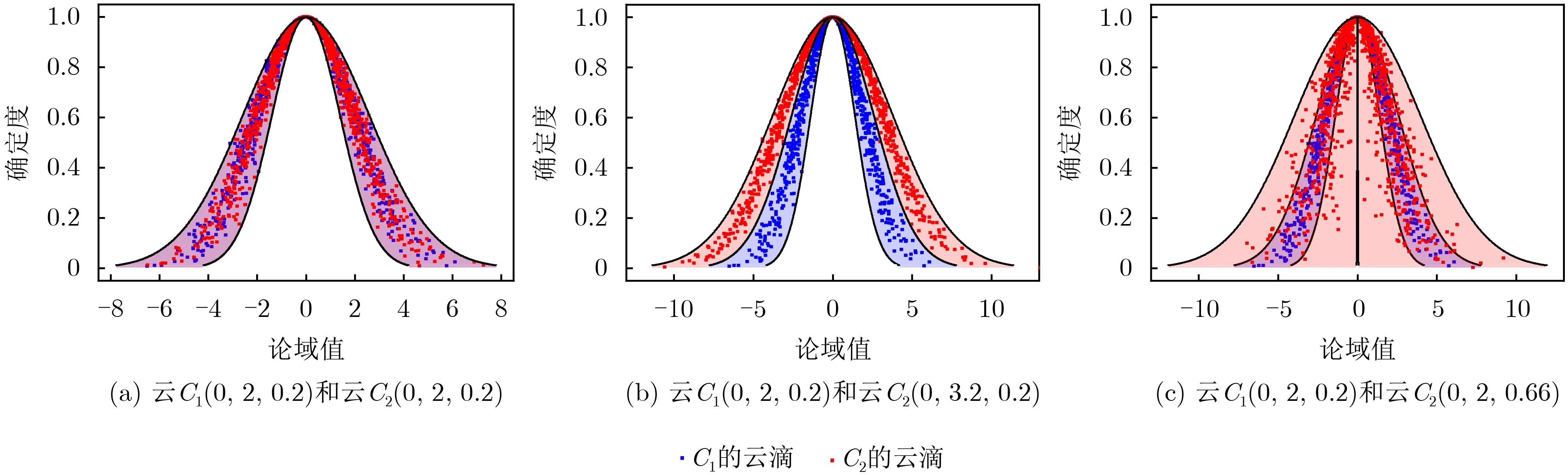
图7 云模型C 1和C 2相对位置随En2和He2的变化
由图6(d)可知,在开始位置云C1与云C2完全重叠,相似度为1,随着超熵的增大,云C2的包络逐渐包裹着云C1,两者的相似度逐渐减小,直到云C2雾化,此时不在本文方法度量范围内。图6(d)说明当两个云的期望和熵相等时,其形状相差越大(超熵相差越大)则相似度越低。当两个云的期望和熵不相等时,不具有完全一致的规律。
两个云的相似度在直观上会受其位置和形状的影响,其影响并不相互独立,不能将两者割裂开来,也不能将两者简单地进行运算,这也是单独讨论位置和形状对相似度影响的复杂之处。以上例子分析了某些情况下具有的一般规律,但是多数情况下还需要根据具体的云模型组来分析其位置和形状对相似度的影响。
5.3 相似度性质分析
(1)连续性。由式(4)可知,相似度SimEACCM(C1,C2)由S1,S2,Sg1和Sg2共同决定,而这4个面积是通过两个云的数字特征计算而来的。由式(5)—式(10)可知,S2,S1,Sg1和Sg2作为数字特征的函数,显然具有连续性。因此,相似度作为数字特征的函数也具有连续性。
(2)单调性。(a)由5.1节可知,固定 En和H e不变, Ex变化,此时相似度为 Ex的函数。在内含式和非内含式中,相似度随 Ex的变化并没有呈现明显的单调性。(b)由5.2节可知,固定 Ex和H e不变且两个云的期望和超熵相等时, En变化,此时相似度为 En的单调递减函数;当两个云模型的期望和超熵不相等时,需要根据具体的云模型组来分析。(c)固定 Ex和 En不变且两个云的期望和熵相等时,He变化,此时相似度为H e的单调递减函数;当两个云模型的期望和熵不相等时,需要根据具体的云模型组来分析。
本节分别从云模型位置特征和形状特征两方面研究了其对云模型间相似度的影响,对应于云模型的数字特征,也就是其3个数字特征对相似度的影响。可以看出,每个数字特征对相似度都具有一定的影响,这也客观说明了忽略任意一个数字特征都是不合理的。同时根据相似度的计算公式和云数字特征对相似度的影响,分析了相似度的连续性和单调性。
6 实验及分析
6.1 装备保障系统能力评估实验
为了进一步验证本文方法的应用价值,将本文方法应用于军队某装备保障系统能力评估[20,23,24],并与CCM方法[20]、MMDCM方法[23]、文献[17]和文献[24]中的方法进行对比。实验中,采用黄金分割法将装备保障系统的能力论域([0,100])进行划分,共包括优、良、中、差和极差这5个能力等级(语言原子),对应子区间以及建立的评估标尺云如表1所示。
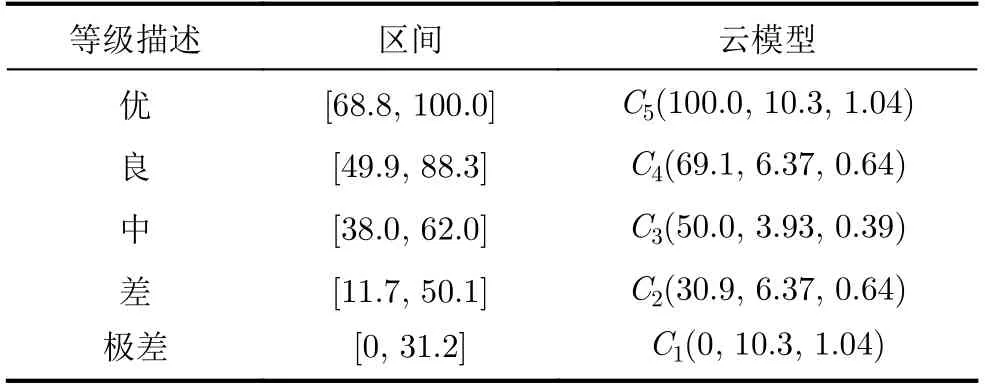
表1 能力等级划分对应的子区间及评估标尺
根据某装备保障系统能力评估的结果,建立的对应目标云为T(84.77,4.0,0.4),目标云T与各标尺云的相交情况,如图8所示(蓝色为标尺云,从左到右分别为极差、差、中、良和优,红色为目标云)。分别采用CCM方法、MMDCM方法、文献[17]和文献[24]中的方法以及本文的方法计算目标云对各评估标尺云的相似度,结果如表2所示。

表2 目标云与各标尺云的相似度
从图8可以看出,目标云T仅与标尺云C4和C5部分重叠,而与其他标尺云没有任何重叠,即目标云云滴与这些标尺云云滴分布在不同的区域中,在数量上的实现完全不同,此时认为目标云T与标尺云C1,C2和C3的相似度为0。而文献[17]方法计算的结果远大于0,这与以上分析相悖。此外,该方法计算出目标云T与标尺云C1,C2和C3的相似度差别较大(分别为0.01, 0.53和0.74),这意味着当两个云存在重叠时,该方法的区分度不高(未重叠时相似度已经高达0.74了,因此在重叠时只有小于0.26的尺度来描述相似度),容易忽略两个云之间的细节差异。因此,从上面两方面分析可知,文献[17]的方法存在一定的片面性。此外,本文方法和对比方法计算出的相似度结果显示,目标云与等级为“优”的评估标尺云最为相似,评估结果为“优”(根据最大相似度原则),与实际相符。
表2的方法其计算结果的差别主要体现在目标云T与标尺云C4和C5的相似度。因此,下面将详细分析利用除文献[17]外的方法计算目标云T与标尺云C4和C5相似度存在的差异。如表2所示,本文方法与对比方法在计算目标云T与标尺云C4和C5的相似度时,存在比较大的差异:对比方法计算出的目标云T与标尺云C5的相似度是目标云T与标尺云C4的相似度的3到4倍;本文方法计算的这两组云的相似度差异并不大。在图8可以直观地看到,目标云T位于标尺云C4和C5之间,在横轴上略偏向标尺云C5,而在形态上这三者的差异并不是很明显,反而从形态上目标云T与标尺云C4更为接近。因此,从直观上来看,这两组云的相似度相差不大。这与对比方法的计算结果相矛盾,与本文方法的计算结果相一致,这也进一步证明了本文方法更为科学合理,更加贴合实际情况。

图8 目标云T与各标尺云相交情况
6.2 时间序列分类实验
面向时间序列数据的分类方法是数据挖掘的重要内容,且分类过程中使用的相似度度量方法直接决定着分类结果的准确性。因此,本小节利用时间序列数据来进一步验证本文相似度量方法的有效性。本实验采用UCI中的常用时间序列数据集(synthetic control chart dataset),该数据集有6类数据,每类数据包含100个长度为60的时间序列数据。实验中,对每类数据采用10折交叉验证,即将每类的100个数据划分为相等的10份,每次测试取其中的一份为测试集,剩下的数据为训练集。
本实验从分析算法分类正确率入手,对比不同云模型相似度量方法在时间序列分类中的计算结果。在研究各方法分类正确率时,采用最近邻分类(K-Nearest Neighbors, KNN)算法进行分类实验(K=10)。每个时间序列可以通过MBCT-SR逆向云变换算法[25]生成的云模型来表示,然后利用不同的云模型相似度量方法分别计算每类测试集与其他数据(包括本类训练数据和其他类所有数据)的相似度矩阵,根据该相似度矩阵,利用KNN算法来计算分类结果,进而得到每类测试集的分类正确率(通过10折交叉验证得到),最后计算6类数据分类正确率的均值,得到各方法的分类正确率如图9所示。其中,对比方法为PSCM方法[18]、MCM[19]方法、文献[17]的方法和LICM[14]方法。
由图9可清楚看到,本文相似度量方法的平均分类正确率最高,其次为PSCM方法和MCM方法,然后是文献[17]的方法和LICM方法。因此,该实验验证了本文方法在时序序列数据分类中良好的性能,进一步说明了本文方法的有效性。
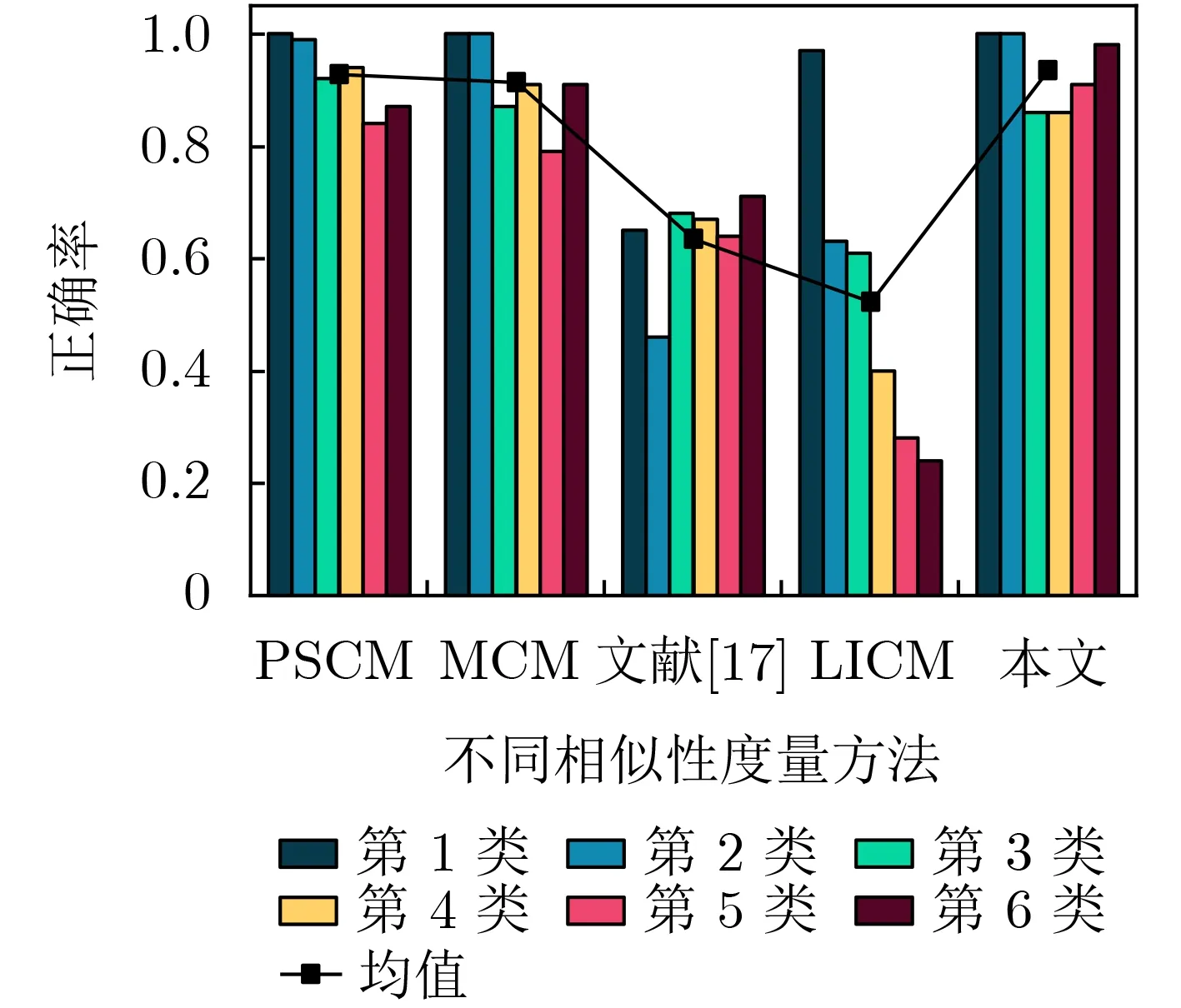
图9 不同度量方法分类的正确率
7 结束语
云模型作为不确定性知识获取的重要研究工具,通过随机性与模糊性的统一,较好地解决了概念的不确定性转换难题。当前云模型间的相似性度量主要集中在基于精确数据的量化计算上,缺乏对云模型整体特征综合考虑,度量结果缺乏科学性与有效性。综合考虑云模型整体几何特征与微观云滴分布贡献,本文提出了一种基于分布轮廓与局部特征融合的云模型不确定性相似度量方法。该方法既可合理地刻画出云模型微观云滴分布特征,又综合考虑其宏观数字特征,较好地实现了不确定性相似度量中基于定性概念内涵与外延的有效结合。为了分析该方法的合理性与有效性,本文还深入探究了云模型数字特征对云模型间相似度计算的影响,并通过仿真实验进行了验证。本文提出的相似度量方法是对云模型理论的有效补充完善,在实际应用中,可结合云模型的各种分析挖掘任务进行使用,进一步提升不确定性知识获取能力。
