移动源排放遥测主要影响因素分析及预测
2022-04-20许镇义王瑞宾康宇曹洋张聪王仁军
许镇义,王瑞宾,康宇,4,5∗,曹洋,张聪,王仁军
(1合肥综合性国家科学中心人工智能研究院,安徽 合肥 230088;2中国科学技术大学自动化系,安徽 合肥 230036;3安徽大学计算机科学与技术学院,安徽 合肥 230601;4中国科学技术大学先进技术研究院,安徽 合肥 230088;5中国科学技术大学火灾科学国家重点实验室,安徽 合肥 230027;6合肥市生态环境局,安徽 合肥 230601)
0 引 言
随着我国经济的发展,城市机动车数量不断增多,在人们生活水平日益提高的同时,移动源污染排放已经成为城市大气污染的重要来源,受到越来越多的关注[1,2]。
何春玉和王歧东[3]利用综合排放模型(CMEM)对北京市机动车尾气排放进行了研究,计算出了CO、HC与NOx排放量,并与实际排放因子及排放特征进行对比分析,得到较好的一致性。于坤等[4]等根据车载排放测试系统(PEMS)实际工况下测量的机动车油耗与各污染物排放数据,并结合油耗理论建立了综合预测模型,获得较好的预测效果。Hao等[5]使用PEMS对农村地区的机动车进行测量,使用速度和加速度作为解释变量,各污染物排放浓度为被解释变量,利用外部插值法进行拟合构建预测模型,模型预测数值与实际值误差较小。王志红等[6]使用PEMS对重型柴油车进行道路污染物排放特性测试,利用所测的车辆比功率(VSP)为输入,分别搭建CO、NOx双隐含层反向传播(BP)神经网络排放预测模型,实验结果在瞬时排放和整体排放特性上预测准确性较高。左付山等[7]使用BP神经网络分别建立了汽油机CO、HC、NOx的预测模型。李昌庆等[8]使用长沙市大型客车监测所得的速度、加速度、比功率等属性特征构建BP神经网络模型,实现了对CO、CO2和NOx排放的可靠预测。
以上研究或是使用传统的统计方法计算回归方程进行预测,或是使用智能预测方法拟合数据进行预测,这些预测方法都很少关注外部条件对移动源污染排放数据采集的影响。然而在实际的机动车尾气排放检测工作中,车型、驾驶习惯、环境条件等一系列因素都对数据的准确性有着一定的影响。本文的数据主要是通过尾气遥感监测获取,其利用光学原理获得机动车污染排放等属性,通过这一技术使得机动车污染监测更加高效快捷,然而由于技术上的限制,这项技术尚未成熟,在实际使用过程中还存在着抗外部干扰能力差、单车重复性低等缺点[9]。
本文基于合肥机动车尾气遥测数据和车辆年检数据,对检测到的外部环境因素和车辆基本信息使用Spearman系数分析各因素与移动源污染排放监测之间的相关性,并利用最小绝对收缩算子(Lasso)算法计算各影响因素权重系数,作为污染排放较大影响因素的选择依据。在此基础上引入BP神经网络,针对移动污染源排放中的CO、HC、NO分别建立基于多源外部因素的浓度预测模型。最后,通过与其他模型对比,验证了本文所构建的网络模型预测的准确性与稳定性。
1 分析方法与过程
1.1 移动源污染遥测数据获取
布设在安徽省合肥市各交通路段的尾气遥感监测设备和机动车年检站的多种尾气排放监测手段整体构成了城市路网机动车尾气排放监测系统,本工作所使用的机动车尾气排放污染数据通过该系统采集。尾气遥感检测系统使用的是一种光谱分析技术,其原理如图1所示。光源探测器发射出探测光束,经激光分束器分成测量光路和参考光路。当检测车辆通过监测区域时,测量光路信号通过尾气烟羽后光源强度发生变换,再通过反射装置反射到激光接收器。反射光路和参考光路经信号放大处理后,通过计算光强差分信号从而测算尾气烟羽中各组成成分的体积浓度分数,并将测量结果最终存储在工控机上。水平式机动车尾气遥测系统主要适用于单车通过尾气污染排放测量,垂直式机动车尾气遥测系统通过垂直分车道检测可实现多车道尾气监测,水平式和垂直式尾气检测设备如图2所示。

图1 尾气遥感检测系统原理[10]Fig.1 Mobile emission remote sensing detection system[10]
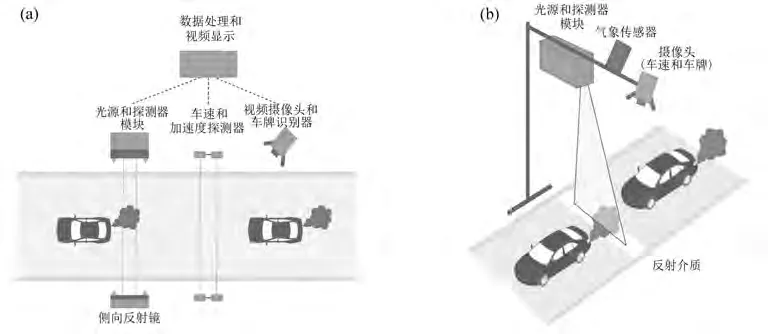
图2 水平式(a)和垂直式(b)遥感检测设备示意图[10]Fig.2 Schematic of horizontal(a)and vertical(b)remote sensing detection equipment[10]
1.2 分析方法流程
国内相关部门对移动源污染排放的数据处理、分析开展了各种研究[11,12],大多采取的是利用污染排放与各待定影响因素建立多元线性回归模型,并使用最小二乘法估计回归方程参数,这种方法对数据的依赖性很大,无法处理多重共线性,并且不能保证所求的解是全局最优解。Lasso算法是近年来被广泛应用的变量选择和参数估计方法,在做参数估计时可以很好地解决变量之间的多重线性问题。因此本研究采用由Robert[13]提出的Lasso这种有偏估计方法对变量进行筛选。Lasso参数估计定义为

式(1)可以使用二次规划进行求解,其计算量往往较大,且式中λ很难给出准确值,因此下面使用最小角回归(LARS)和交叉验证方法解决Lasso计算问题[14]。
图3为基于移动源遥感监测的影响因素分析及排放预测方法的流程,主要包括以下步骤:
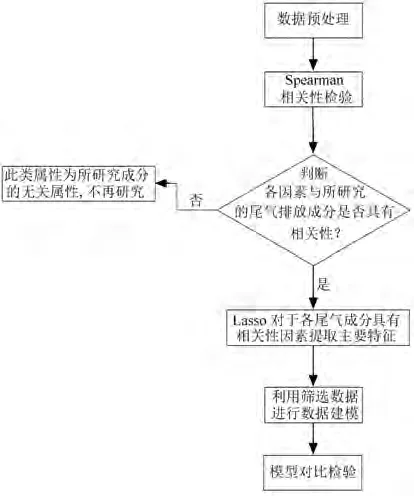
图3 机动车尾气排放预测模型流程Fig.3 Flow chart of vehicle exhaust emission prediction model
1)从车辆检测数据库中提取尾气检测表和车辆基本信息表,抽取尾气遥测数据、车检数据以及环境数据等相关数据。
2)对步骤1)抽取的相关数据进行预处理,得到建模数据,进行Spearman相关性分析并建立Lasso变量选择模型。
3)在Lasso变量选择的基础上,采用神经网络对尾气遥测数据建立训练模型,得到尾气污染物CO、碳氧化合物(HC)、NO排放浓度预测模型。
2 移动源污染排放影响因素分析及预测模型构建
对预处理好的数据进行描述统计性分析,变量描述性统计结果如表1所示。表中右边四列从左到右分别为各属性的最小值、最大值、均值、方差。

表1 主要变量的描述性统计Table 1 Descriptive statistics of main variables
根据预处理后的数据计算各属性Spearman系数公式为

式中ρ为某一因素与排放物的Spearman系数,xi为影响因素的第i个样本值,为该属性的均值,yi为污染物的第i个样本值,为其均值。根据相应属性的Spearman系数ρ计算其统计量T值为

式中T为影响因素与排放物的统计量;n为样本数目,此处样本数为3560。
图4是依据式(2)、(3)计算的移动源污染排放中RCCO、RCHC、RC NO与其他外部变量的Spearman秩序相关系数热力图和在α=0.05下的T值检验的统计量热力图。从图中可得出,在显著性水平α=0.05(T=1.645)下,CO浓度与车长没有统计学意义;HC浓度和基准质量、速度、风向没有统计学意义;NO浓度和风速、温度、大气压没有统计学意义。

图4 变量的Spearman秩序相关系数(a)和T检验数值(b)Fig.4 Spearman′s rank correlation coefficient of variables(a)and T-test value of variables(b)
表2为利用Lasso得到的各影响因素的系数。从表中可以看出,Lars-Lasso变量选择模型将与CO相关因素中的基准质量、车长、风向的权重系数压缩为0,与HC相关的因素中的基准质量、加速度、车长、比功率的权重系数压缩为0,与NO相关因素中的使用年限、加速度、比功率、温度的权重系数压缩为0。

表2 影响因素系数Table 2 Coefficient of influencing factors
针对移动源污染排放中的三类主要气体CO、HC、NO,将Spearman显著性检验中与各变量无统计学意义和Lasso变量选择方法系数为0的属性删除,使用各自剩下的关键影响因素分别建立神经网络预测模型。神经网络采用基于TensorFlow的Keras库搭建线性叠加模型。将预处理后的数据零均值归一化后,数据集按照8:1:1的比例,将数据(3560条)划分为训练数据集(2848条)、验证数据集(356条)和测试数据集(356条)。
大量研究表明[17-19],三层神经网络可以逼近任何一个非线性函数,本研究采用这一经典BP神经网络结构,依据经验公式可大致确定隐藏层神经元数量,再使用随机搜索去寻找最合适的神经元数量和批量大小,基于经验手动调整学习率,各层使用Relu函数为激活函数。隐藏神经元数的经验公式为

式中n为隐藏层神经元数量,N为输入层节点数目,M为输出层节点数目,a∈[1,10]中的随机数。图5为BP神经网络结构(三层)示意图。

图5 BP神经网络模型Fig.5 BP neural network
对CO的建模中,将使用年限、行驶速度、行驶加速度、比功率、风速、温度、相对湿度、大气压这8项属性作为CO的影响因子,将CO的浓度作为预测输出;对HC的建模中,将使用年限、风速、温度、湿度、大气压这5项属性作为HC的影响因子,将HC的浓度作为预测输出;对NO的建模中,将基准质量、行驶速度、车长、相对湿度、大气压、风向这6项属性作为NO的影响因子,将NO的浓度作为预测输出。
表3为各研究成分网络模型的具体参数,基于该网络结构训练,设置训练次数为15000次,且使用早停法[20]避免过拟合,将早停法的停止条件设置为绝对误差减小的最大次数等于20。图6展示了基于神经网络预测模型(L-ANN)与支持向量回归(SVR)、随机森林(RandomForest)、未进行特征提取的神经网络ANN这三组对照模型的预测平均绝对误差(MAE)和均方根误差(RMSE)的对比。MAE和RMSE是衡量变量精度的两个常用指标,MAE是所有预测值和实际值之间绝对差值的平均值,反应实际误差的大小;而RMSE是预测值和实际值之间差异平方平均值的平方根,说明预测样本的离散程度。从图中可以看到,本文设计的模型在CO预测中MAE值为0.140%,RMSE值为0.224%;在HC预测中值为0.819×10-6,RMSE的值为4.776×10-6;在NO预测中MAE值为31.002×10-6,RMSE的值为89.820×10-6。预测的误差均在可接受范围内,且预测有着较高的准确性。
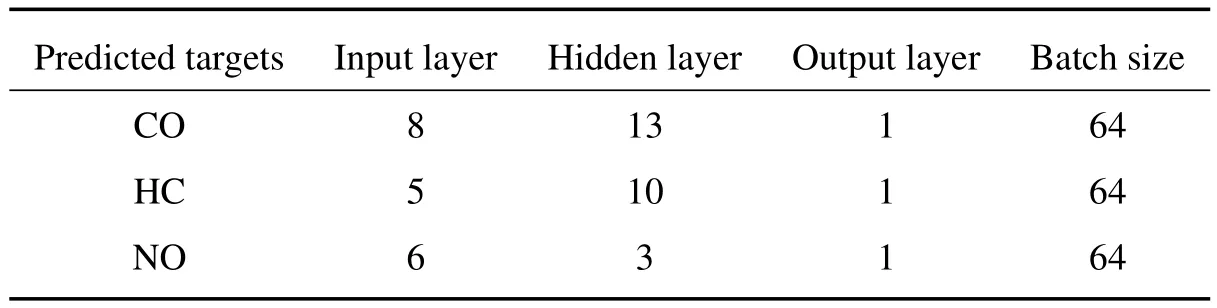
表3 预测模型参数Table 3 Parameters of prediction models
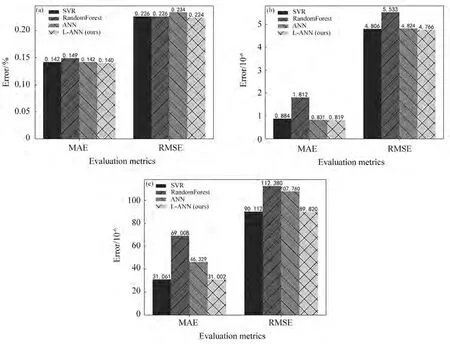
图6 CO(a)、HC(b)和NO(c)预测模型对比Fig.6 Comparison of prediction models for CO(a),HC(b)and NO(c)
总体来看,设计的L-ANN模型的MAE和RMSE比其他预测模型都要小,性能最好;其次,SVR回归模型的各项性能在绝大部分情况下优于其它两种模型。可见,在各项移动源污染排放成分预测中,L-ANN模型的预测有着较出色的表现。
3 结 论
在影响移动源污染排放遥感监测各成分的因素中,利用Spearman相关性分析和Lasso特征筛选确定使用年限、行驶速度、行驶加速度、比功率、风速、温度、相对湿度、大气压这8项属性是CO的关键影响因子;使用年限、风速、温度、相对湿度、大气压这5项属性是HC的关键影响因子;基准质量、行驶速度、车长、相对湿度、大气压、风向这6项属性是NO的关键影响因子。
在移动源污染排放成分预测结果对比实验中,通过将本文提出的L-ANN模型与SVR、RandomForest和ANN模型对比发现,针对移动源污染排放预测,L-ANN模型有着更高的准确性和稳定性。本研究可以有效地降低尾气检测的成本,并为有关部门实现尾气污染的高效监管提供技术支持。
模型的训练需要依靠大量的数据,在数据量较少的情况下很难得到理想的实验结果。为了克服这一点,在未来的研究中,可以依靠迁移学习,针对某一数据量足够的移动源训练得到模型后,再迁移到数据量缺乏的移动源中,以获得较为准确的污染预测。
