基于DeepSORT与改进YOLOv3的车间安全帽检测系统研究
2022-04-11白家俊何青松
白家俊 何青松


摘要:生产实践表明佩戴安全帽可以有效减少安全事故带来的人员伤亡,基于此,提出了一种判断生产人员的安全帽是否正确佩戴的方法,并对现有YOLOv3算法进行了优化,提高安全帽检测精度和速度,减少无效报警。结合DeepSort目标跟踪技术提高检测算法的实时性。基于开源SHMD数据集进行测试,结果显示优化YOLOv3算法的平均检测准确率达到96.80%,比现有YOLOv3算法提高12%,执行速度每秒32帧,在各种自然场景下都有出色的检测效果。
关键词:DeepSORT;改进YOLOv3;车间安全;安全帽;目标跟踪
中图分类号:TP391文献标识码:A
文章编号:1009-3044(2022)05-0091-03
近些年,我国建筑行业发生的安全事故中有60%以上的伤亡者未佩戴安全帽,可见佩戴安全帽是保障工人生命安全的重要措施。监督工人佩戴安全帽已成为安全生产管理中的必要措施[1]。现有的安全帽佩戴监控方式以人工监督为主,效率低,效果差,和工业4.0时代计算机化、智能化的安全生产要求相差甚远。如何实现安全帽佩戴自动化检测成为安全生产管理领域亟待解决的问题。目前,安全帽检测领域缺乏高鲁棒性的分类算法[2]。在深度学习理论和方法的持续完善的背景下,以其为核心的目标识别跟踪算法发展迅速,为安全帽检测技术的研究提供了新的选择。本次研究提出了基于深度学习神经网络检测方案,通过处理工厂车间的视频图像模型,准确检测工人的安全帽佩戴情况。
1系统架构设计
本次设计的安全帽检测系统检测基本流程见图1,系统由安全帽检测、人员目标跟踪两大模块构成。
安全帽检测模块的主要功能是基于摄像头捕捉到的监控视频,通过大量数据训练完成视频内容检测,分析视频中人员安全帽佩戴情况,并记录视频中检测目标的信息,以便后续进行目标跟踪。
人员目标跟踪模块基于安全帽检测模块发送的采集目标帧初始化跟踪集,再运用[DeepSORT]算法实现目标集跟踪。人员目标跟踪模块负责跟踪视频图像中的每一个人员目标,及时收集人员位置信息,在确保检测精度的情况下尽量减少警报的漏报、虚报[3]。
后台程序基于改进的YOLOv3检测算法和DeepSORT算法获取数据集,及时更新跟踪器,找出未佩戴安全帽的人员目标,系统发出警告。
2 数据集构建
本次设计以开源安全帽数据集SHWD (Safety Helmet Wear Dataset)作为基础训练数据。SHWD数据集共有7581个Pascal-VOC格式标注图片,主要分为未戴安全帽、已戴安全帽两种图片[4]。SHWD数据集正/负例样本分布不均匀,同时场景相对单一。因此,本次研究基于SHWD数据集存在的问题补充了4800张安全帽拿在手中或放在桌上等复杂图像数据,与SHWD数据集合并用于进行算法训练和测试。
3 安全帽检测模块设计
3.1 模型算法
本次设计的安全帽检测系统主要由两个主要部分组成:安全帽检测模块和人员目标跟踪模块。安全帽检测模块是整个系统的核心,在比较了不同的算法之后,本次设计选用YOLOv3检测框架,为提高算法检测的准确率,本文重点介绍YOLOv3算法的三个部分:特征提取网络、特征聚合、损失函数[5]。YOLOv3算法的基本原理是将残差网络函数与多尺度预测相结合,在中小型物体的检测进度与检测速度之间达到平衡,但[416×416]的输入图像对应的特征图尺寸最小为[13×13],感受野太大,严重影响检测精度,尤其是中小型物体的检测效率很低,检测重复、错误、遗漏的概率很大。因此,本文基于现有YOLOv3算法进行优化给出更加高效的YOLOv3算法,其大致框架见图2。
本次改进的算法是一种多目标检测算法,其基本框架为深度残差网络。在典型的视频目标检测环境中,检测目标是中小型目标,因此他们不需要非常大的感受野。此外,为改善针对中小型目标(生产人员)的检测能力,新算法需要基于大量浅层特征图进行预测。考虑到目标识别的速度、时间复杂度和可靠性[6],本次设计在原有YOLOv3框架基础上增加一个卷积层,将特征图与平面残差网络相结合,和原有YOLOv3的三个卷积层共同组合形成一个包含四个不同分辨率卷积层的特征金字塔,具体包括包[64×64,32×32,16×16,8×8]的分辨率。在2-stage特征金字塔中进行采样并结合Deep Rest网络形成深度融合的安全帽快速检测模型。本次改进的YOLOv3算法的检测识别数据是整幅图像,输出被检测目标的位置信息以及安全帽佩戴信息。首先,改进YOLOv3算法使用深度残差网络(Deep Residual Network,DRN)来提取目标人员特征。然后,在DRN后设置卷积层,将其分为四个分支,共同构成图像特征预测网络[7]。出于提高图像信息价值的考虑,本次改进的YOLOv3算法将图像特征预测网络的特征图与DRN的图像特征图结合。最后,通过非极大值抑制達到去除重复图像边界框的目的,最终得到安全帽佩戴检测结果。相比传统的YOLOv3,改进后的算法效果更好,可以有效减少复杂疑难场景下的误检,大大提高安全帽佩戴检测准确率。
3.2 基于DRN提取图像特征
新算法通过构建DRN残差网络提取目标头部特征。DRN包含若干残差块,块与块之间依次堆叠,对应的公式如下:
[at+1=Ft(at)+at]
[at]表示第[t]个残差块的输入向量、[at+1]表示第[t]个残差块的输出向量,[Ft(at)]表示残差分支的传递函数。构建的DRN有利于图像特征信息流动,可提高算法训练效率。DRN的第一个卷积层利用16[×]33的滤波器以[512×512]的分辨率对输入图像进行滤波,再以步长2对浅层图像进行滤波,并添加残差块增加网络的深度,得到特征图分辨率为[256×256],通过类似方法得到分辨率分别为[64×64,32×32,16×16,8×8]的特征图,将分辨率为[64×64,32×32,16×16,8×8]的特征图与上采样特征图合得到特征金字塔,以便进行安全帽佩戴预测。
3.3 基于多尺度卷积网络预测目标人员位置
本次改进的算法在多尺度目标特征图上对目标人员安全帽佩戴情况进行回归预测。不同分辨率的卷积层分为四个分支,即分别率分别为[64×64,32×32,16×16,8×8]特征图,基于特征图分别进行图像预测,各分支均包含若干卷积层,对各分支进行上采样。为强化特征金字塔表征能力,将上采样特征与残差块特征融合,以识别安全帽,四个分支共享通过DRN提取的图像特征。通过多尺度卷积网络预测算法可以生成分别代表图像边框、人员头部、人员颈部以及安全帽佩戴类别的三维张量。
3.4 基于锚点机制预测人员头部边界框
锚点机制源于FasterR-CNN,用于发现目标边界[8]。锚点机制可快速精准预测YOLOv2、YOLOv3、SSD等检测框架中物体的边界。因此,本次设计也使用锚点机制来预测目标人员的头颈部边界。特征图可分为[N×N]个网格,单个网格可预测三个锚框,单张图像可包含65280个预测帧,从而有效确保目标头部位置的检测与识别精度。Faster R-CNN可以基于单个滑动窗口生成9个锚点,这些锚点先通过人工标记,再基于实际情况进行修正以进行数据集训练。本文改进的算法采用与YOLOv2相同的方法,对大量训练数据进行聚类以获得最佳的先验锚点框,用于检测目标人员是否佩戴头盔,算法公式如下:
[d(box,centroid)=1-IOU(box,centroid)]
基于不同場景需求,如召回率、精度方面的不同要求可以为当前的场景选择更好的IOU值。目标人员的头部位置通过本次改进算法直接预测,分成四个坐标信息,[tx],[ty],[tw],[ty]定义分别如下:
[bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phetA]
其中,[cx,cy]表示网格到图像左上角的水平和垂直距离,[pw,py]表示边界框的宽度和高度。
4 目标跟踪模块设计
本次设计的安全帽检测系统基于DeepSort算法预测目标人员的位置,根据目标的形状、运动情况进行跟踪,其两个核心算法是卡尔曼滤波和匈牙利算法,分别负责状态估计和适当的目标分配。DeepSort目标跟踪算法使用8维向量([μ、υ、γ、h、x、y、γ、h])来描述被跟踪目标人员的具体状态。其中[(μ,υ)]表示目标框的中心坐标,[γ]表示纵横比,[h]表示高度,其余变量则用来描述目标在图像坐标系中的运动状态。基于标准卡尔曼滤波器来预测目标人员的运动状态,预测结果可表示为[(μ、υ、γ、h)]。此外,DeepSort算法将目标人员的外观、运动方面的信息关联起来,以解决相机移动造成目标ID频繁切换的问题。目标检测框与跟踪器预测框之间的马氏距离用于表示运动相关程度。
[d(1)(i,j)=(dj-yi)TS-1i(dj-yi)]
[yi]为预测第[i]个目标人员的位置,[dj]为第[j]个检测框的位置,[Si]表示检测位置之间的方差矩阵。通过检测位置、预测位置的标准差来衡量目标运动状态的不确定性。提取目标特征向量作为目标的外观信息,并将每一帧的匹配结果缓存为特征向量集。对于每个目标识别帧,特征向量和特征向量集的所有跟踪器都计算到最小余弦距离,计算公式如下:
[d(2)(i,j)=min{1-rTjr(i)k|r(i)k∈Ri}]
[Ri]为第[i]个跟踪器的特征向量集,[rj]为第[j]个目标检测框的特征向量。使用两种关联方式的线性加权值[ci,j]作为最终匹配度量,[λ]为权重系数。
[ci,j=λd(1)(i,j)+(1-λ)d(2)(i,j)]
5 系统测试和结果分析
5.1 测试环境及方法
本文将SHWD数据集以及自建数据集共13955张图片按照8:2的比例分为训练集、测试集。在Ubuntu操作系统上进行数据训练,并使用GPU 加速工具,GPU为英伟达Tesla V100 @ 16 GB,RAM为32 GB,采取随机梯度下降(SGD),使用4x16小批量训练方法,动量为0.927,权重衰减0.00049。训练期间共进行20,000次迭代。根据需要调整学习率,当迭代次数达到80%、90%时,学习率降低到原来的10%,为了比较该算法与传统YOLO v3算法的检测效果,需要对两种算法的测试结果进行对比分析。
5.2 算法测试结果分析
本文以常用的平均准确率、平均精度均值、每秒检测帧数衡量算法效果。IOU取0.5,基于2791张图像的测试集测试新算法,测试结果见表1。
根据表1数据可以看出,本次改进的算法基于深度残差网络进行特征深度融合,模型运算量显著提升。如果不运用DeepSort目标跟踪算法,则系统运行效率,即每秒检测帧数低于传统YOLOv3,但从识别准确率来看,改进算法使用的特征提取网络特征表达能力或更强,识别准确率(96.81%)与传统YOLOv3(84.26%)相比有显著提升。
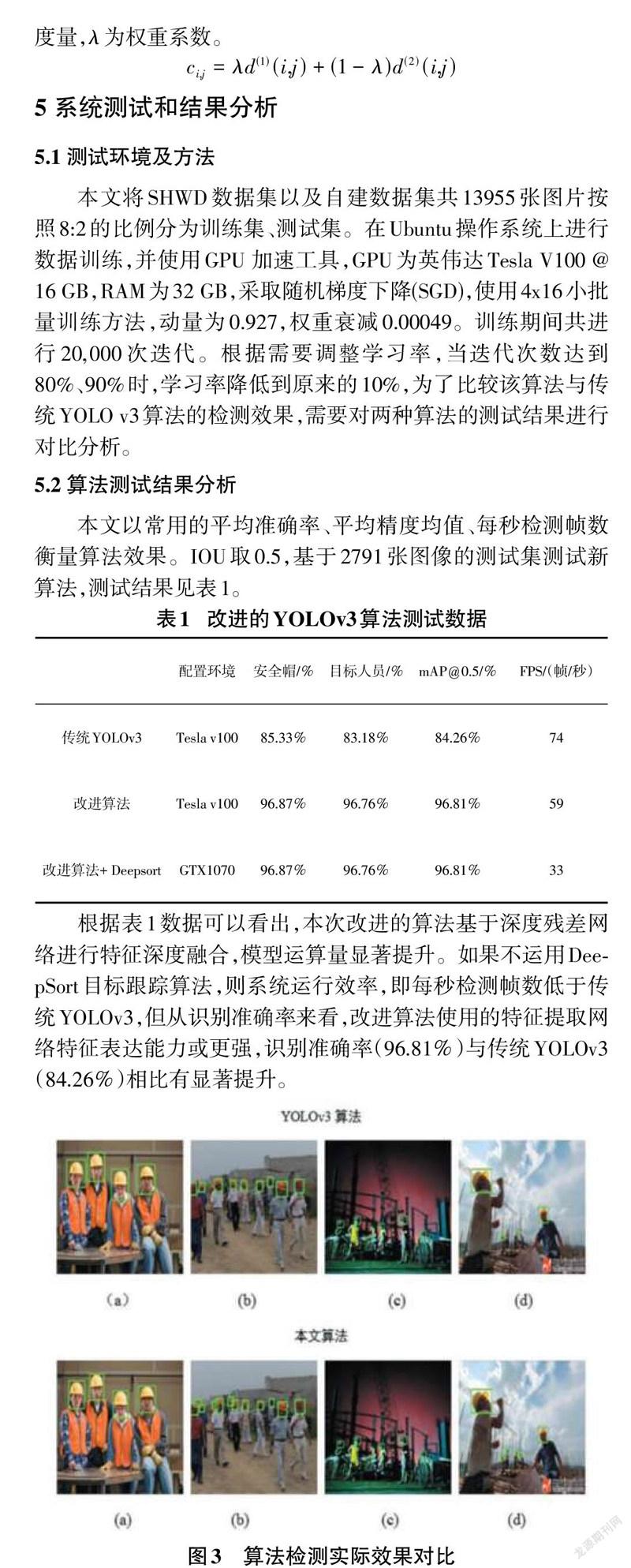
如图3所示,在一般场景中,传统YOLOv3和本次改进的算法都获得了良好的检测效果,但在遮挡较多的多人群场景中,传统YOLOv3漏掉了一些模糊的目标,改进算法则没有漏掉检测目标。如果目标很小,则传统YOLOv3算法的识别准确率严重下降,而本次改进的算法检测识别效果很好。
6结论
综上所述,本次研究提出了一种改进的YOLOv3检测算法,该算法在传统YOLO v3算法的三个卷积层基础上增加一个特征图尺寸更大的卷积层,构成四层卷积层结构,以提高算法对中小型目标的检测识别效率。不同尺度的四个卷积层构成的特征金字塔,同时以步长的2倍进行向上采样,与深度残差网络融合以进行特征提取。将获得的特征图用于模型训练和测试,经过系统测试,本次改进的算法整体性能优于传统YOLOv3算法,可以很好地满足生产实践中的安全帽检测需求。为进一步提高系统运行效率,本次研究使用DeepSORT目标跟踪算法进行目标人员识别。在英伟达GTX 1070显卡环境得到系统的每秒检测帧数为33帧,识别准确率达到96.81%,说明本次提出的算法效果良好。在未来研究中需要对算法结构进行持续改进和完善,提高算法对小目标以及遮挡场景下的目标检测准确度。
参考文献:
[1] 宋艳艳,谭励,马子豪,等.改进YOLOV3算法的视频目标检测[J].计算机科学与探索,2021,15(1):163-172.
[2] 陈佳倩,金晅宏,王文远,等.基于YOLOv3和DeepSort的车流量检测[J].计量学报,2021,42(6):718-723.
[3] 李震霄,孙伟,刘明明,等.交通监控场景中的车辆检测与跟踪算法研究[J].计算机工程与应用,2021,57(8):103-111.
[4] 朱健,杨云飞,苏江涛,等.基于深度学习的太阳活动区检测与跟踪方法研究[J].天文研究与技术-国家天文台台刊,2020,17(2):191-200.
[5] 吴强,季晓枫,冯育,等.一种基于YoloV5和DeepSort的地面互动投影系统中人体检测跟踪方法:CN112668432A[P].2021-04-16.
[6] 赵守风,沈志勇,姚一峰,等.基于YOLOv4模型和DeepSORT模型的跟踪方法:CN112634332A[P].2021-04-09.
[7] 宋欣,李奇,解婉君,等.YOLOv3-ADS:一种基于YOLOv3的深度学习目标检测压缩模型[J].东北大学学报(自然科学版),2021,42(5):609-615.
[8] 郑含博,李金恒,刘洋,等.基于改进YOLOv3的电力设备红外目标检测模型[J].电工技术学报,2021,36(7):1389-1398.
【通联编辑:代影】
收稿日期:2021-05-26
作者简介:白家俊(2001—),山西长治人,专科,主要研究方向为软件技术;指导老师:何青松(1987—),男,江苏徐州人,助教,硕士研究生,主要研究方向为心理学、法学、软件、人工智能。