云环境下面向数据密集型应用的容错性资源配置研究
2022-03-25李宏梅杨天国张磊莫瑞超许小龙徐占洋
李宏梅,杨天国,张磊,莫瑞超,许小龙,3,徐占洋,3
(1.云南电网有限责任公司德宏供电局,云南 德宏 678400; 2.南京信息工程大学计算机软件学院,江苏 南京 210044; 3.南京信息工程大学江苏省网络监控中心,江苏 南京 210044)
0 前言
随着近些年来互联网行业的快速发展,互联网应用所产生的数据规模在不断扩大的同时,数据的复杂性也在逐渐增加[1]。为了给用户提供丰富且良好的互联网服务,如何及时有效地处理这些应用数据是现在互联网行业所面临的巨大难题[2-3]。
云计算作为一种分布式计算模式,通过将计算任务部署在拥有超强计算能力的资源池中,各计算任务能够根据自身需求获取计算资源,从而使得计算任务能够得到高效的执行[4]。随着近些年来云计算技术的快速发展,云计算的相关技术日渐成熟,通过构建大型云平台以满足用户的计算资源需求,使得互联网应用所产生的数据能够得到有效的处理,已经成为目前的一种趋势[5]。
数据密集型应用作为一种对数据的访问频率十分密集且数据量大的特殊应用,其要求产生的数据需要在极短的时间内得到有效处理。相比与非数据密集型的应用,数据密集型应用对数据处理时延极其敏感。当应用所产生的数据不能够得到及时的处理将会带来较差的用户体验。云计算技术虽然为应对数据密集型应用的计算需求提供了充足的计算资源,但在云平台中部署数据密集型应用时仍有一些问题需要解决[6-7]。在云平台中有许多因素可能导致计算结点死机,例如计算结点过载,操作系统的故障等等[8-9]。当任意托管应用的计算节点发生故障时,部署在该故障结点的计算任务不能够及时的在正常运行的计算结点得到恢复将会引发各种后果(例如,数据丢失,数据密集型应用完成时间延长等),而这些后果将会给用户(比如:电力行业)带来巨大损失[10-12]。总的来说,在云平台出现故障后,如何为故障结点上部署的任务选择合适的资源配置策略依旧面临着巨大挑战。一方面,为宕机结点上部署的计算任务选择出最优的资源配置策略需要使得数据密集型应用的完成时间尽可能的短,另一方面,云平台计算结点的负载均衡也需要被考虑,通过优化负载平衡,云平台所有计算节点都工作在稳定状态,这有利于提高云平台的资源利用率。此外,保证云平台的负载均衡能够降低了数据密集型应用执行过程中出现问题的可能性,从而进一步提高了云平台的容错能力。
针对现存的故障任务迁移问题上,国内外学术界和工业界都开展了广泛的研究:Zhu等设计了一个随意的工作流容错框架,并提出了一种动态容错调度算法,用于对虚拟化云中的实时工作流进行资源配置[13];文献[14]中,Asvija等结合实际的气象工作流建立了MM5模型作为计算网格工作流程的支持框架以解决故障任务的迁移问题;Chen等提出了一种普通任务失效建模模型,该模型采用基于最大似然估计的参数估计过程来模拟工作流工作的性能,该模型的提出在一定程度上解决了故障任务恢复的问题[15];文献[16]中,Ding等从云平台的角度提出了一种容错弹性调度算法,可以应用于云平台来执行工作流;而在文献[17]中,Yao等设计了一种独特的容错工作流调度算法,该算法结合了基于复制和基于重新提交的策略,以实现其容错功能。
但是当前的研究工作忽略了在任务恢复过程中任务的执行完成时间问题,而且也忽略了任务故障恢复对数据中心负载均衡所造成的影响。因此,本文针对性提出了一种云计算环境下面向数据密集型应用的容错性资源配置方法,以实现任务故障恢复,并能够保证故障恢复后的任务的完成时间与云平台所有计算结点的负载均衡需求。
1 基于VL2网络拓扑结构的云平台
虚拟层2(Virtual layer 2,VL2)[18]是一种实用的网络拓扑结构,分为中继交换机层(Intermediate Switches Layer)、汇聚交换机层(Aggregate Switches Layer)和TOR交换机层(Top of Rack Switches Layer)[15]。通过部署大量的网络设备和网络链接,VL2网络拓扑结构实现了网络的全二等分带宽,为建立高性能的云平台提供了良好的基础[18]。
如图1所示,在根据VL2网络拓扑结构搭建的云平台中,不同的区域根据实际的计算需要部署任务备份节点和计算节点。在同一区域的所有计算节点和备份节点都被连接相同的TOR层交换机。此外,为了保证两个区域之间的数据通信,两个相邻区域的TOR层交换机被连接到同一个汇聚层交换机上。同时,汇聚层的所有交换机都被连接到中继交换机上以保证网络中所有区域之间的数据通信。因此,在VL2网络拓扑结构所搭建的云平台中每一个终端计算节点到中继交换机的最长距离为3跳,这使得在云平台部分结点发生错误的时候,宕机任务能够得到有效的恢复。

图1 基于VL2网络拓扑结构的云平台
2 系统模型
2.1 数据密集型应用模型
为了简化数据密集型应用的工作流程,在本文中将数据密集型应用被定义为有向无环图(Directed Acyclic Graph, DAG),用D={T,R}来表示,其中T={t1,t2,...,tn}代表着完成该数据密集型应用做需要执行的任务集合,而R用来表示任务之间数据依赖集合。两个任务之间的数据依赖可以用ri,j=(ti,tj)的形式来表示,在这种 情 况 下,任 务ti(1≤i≤n)表 示 为tj(1≤j≤n)的前驱任务,相应的tj则作为ti的后继任务。一般来说,一个任务的开始需要传入来自前驱任务完成得到的数据。此外,tstart和tend这两个虚拟任务分别作为应用的开始任务和结束任务被引入,使得应用中只包含一个入口和出口。
在数据密集型应用模型中,从开始结点到结束结点花费时间最长的路径被称为关键路径,为了找出关键路径,应用中的每一个任务的最早开始时间(Earliest Start Time, EST)、最早完成时间(Earliest Finish Time, EFT)、最晚开始时间(Last Start Time, LST)和最晚结束时间(Last Finish Time, LFT)需要被计算出来以便判断该任务是否处于关键路径。任务ti的最早开始时间可以通过下面的公式计算出来:

其中,p(ti)代表的是任务ti的所有前驱任务集合;αjexe是任务完成所需要的执行时间;ctfi,j代表的是任务ti获取其前驱任务数据所需要花费的时间。
2)迭代:在NSGA-III的迭代过程中,父代种群Ho经过选择和突变产生子种群Qo,然后将来自父代种群Ho和子种群Qo的所有个体融合到Ro中,然后通过非优势排序从Ro中选择合适的个体,然后通过参考点法从N个个体形成新的种群N个个体选取新的个体以构建新的种群Ht+1。当数据密集型应用的完成时间和云平台的负载均衡的结果收敛后,NSGA-III的迭代过程将会停止,而此时种群中的个体将形成一个解集,称为帕雷托(Pareto)最优解。
粗选磁场强度110 kA/m,精选磁场强度110 kA/m,扫选磁场强度110 kA/m。磨矿细度80.00%-0.074 mm,给矿浓度35.00%。试验结果见表9,试验原则流程图及数质量流程分别见图3、图4。

任务ti的最晚开始时间通过下式可以计算出来:

其中,c(ti)代表的是任务ti的后继任务集合。此外,应用的最晚开始时间表示为:
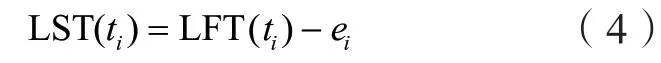
通过上述分析,可以得到应用上每一个任务的最早开始时间和最晚开始时间,而后根据关键路径的定义可知,当一个任务的最早开始时间和最晚开始时间相等,则该任务是关键路径上的任务,称该任务为关键任务。根据关键任务可以找出应用的关键路径,从而计算出该数据密集型应用的最大完成时间D。
2.2 宕机任务恢复时间计算模型
在数据密集型应用模型基础上,假设由于计算结点发生故障导致工作流产生的宕机任务集合为FT={ft1,ft2,...,ftn},为了恢复ftz(1≤z≤n),该任务的备份镜像数据和前驱任务完成所产生的数据需要被发送到恢复该任务的计算结点,从而使得ftz能够继续执行。然而,恢复任务的计算结点接收宕机任务的镜像数据和其前驱任务所产生的数据并且重启ftz需要花费一定的时间云计算平台是不能够被忽略的。假设恢复任务ftz所需要的时间为HFSz,则HFSz表示为:
扶贫资源滥用,扶贫资金被截留和贪污,扶贫政策监管和执行中出现偏差,一个重要的原因就是缺乏有效的跟踪反馈[4]。由于观念原因,有些脱贫人口仍死死扣留“贫困帽子”,不愿退出。由于上级下达的贫困户指标有限,真正需要帮助的贫困户无法进入。部分地区返贫率高,没有返贫人口再入机制,贫困人口退出机制和再入机制不健全,一些人甚至出现“被脱贫”、“假脱贫”现象。由此可以看出,缺乏动态管理和监管,对黑龙江省精准脱贫产生了巨大的束缚。

本文提出了一种容错性资源配置方法(Fault- tolerant Resource Provisioning Method,FRPM)使得在云平台发生错误之后,宕机任务能够找到最优的恢复策略,保证部署在云平台上的数据密集型应用的完成时间最短的同时,云平台的负载均衡也能够得到保证。本文所提出的FRPM是基于参考点的非支配排序算法(Non-dominated Sorting Genetic Algorithm III, NSGA-III)[19],该算法是一种能够针对目标进行同时优化的遗传算法,FRPM在实现过程中将数据密集型应用的完成时间和云平台的负载均衡作为算法优化的目标,借助NSGA-III为宕机任务找到能够同时满足数据密集型应用的完成时间最短和云计算平台的负载均衡这两个目标的资源配置策略。
假设云计算中心当前未发生故障的计算结点的集合为Ps={ps1,ps2,...,psl},且每一个计算结点所剩余的计算资源表示为cd(1≤d≤l)。此外,镜像服务器集合为Pm={pm1,pm2,...,pmk}。假设ftz会在psd(1≤d≤k)上重启,则psd需要从不同的结点获取ftz的镜像数据和其前驱任务所产生的数据。假设恢复ftz所需要的镜像数据和前驱任务所产生的数据分别存放在pam(1≤a≤k)和psb(1≤b≤l)上面。
根据VL2的网络拓扑结构特点,不同的结点之间的位置关系存在3种情况,为了便于表示恢复任务计算结点与前驱任务数据所在结点以及任务的备份数据所在结点之间的关系,使用ξ来表示这三种情况:
1)ξ=0代表着两个计算结点连接到了同一个TOR;
2)ξ=1代表着两个计算结点未连接到同一个TOR交换机,但是连接到了同一个汇聚层交换机;
3)ξ=2代表着两个计算结点未连接到同一个TOR交换机或汇聚层交换机,但是两个结点连接到了同一个中继层交换机。同理,计算结点和任务镜像结点之间的关系也可以用ξ来表示。
与传统的遗传算法相比,NSGA-III通过采用精英策略,能够很迅速找到多目标优化问题的全局最优解,所以在本文中采用NSGA-III来解决多目标的宕机任务恢复问题[20]。在遗传算法中,染色体的基因型表示多目标优化问题的解。在本文中为了找到宕机任务恢复策略,对云平台中未发生错误的计算结点进行编码,将每个计算节点的编号作为基因,这些基因被组合在一起形成一条染色体,染色体通过不断的变异和进化从而为宕机任务找到最优的资源配置策略。此外,由于宕机任务不能够在出现问题的计算结点恢复,也不能在计算容量不能够满足运行该任务的计算结点上执行,所以对每一条染色体,式(13)和式(14)给出了适应度函数。
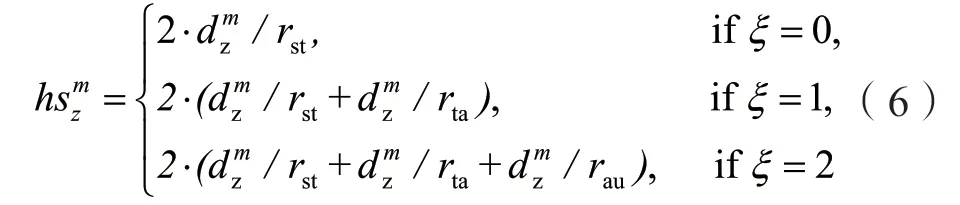
for 关键任务 do
当psd在得到了ftz的镜像数据之后,需要获取来自该任务的前驱任务的数据,假设前驱任务的数据大小为dmz,则获取前驱任务所产生数据需要的传输时间hssz表示为:

此外,由于ftz的前驱任务可能会是一个或多个,所以需要从多个计算结点获取数据,但是psd在获取这些前驱任务的数据是同时进行的,所以将在这个过程中需要的最长时间作为hssz。
2.3 负载均衡模型
在对宕机任务进行恢复的过程中,需要考虑到这些任务都属于数据密集型的任务,对计算结点所处的状态有一定的要求。具体来说,如果宕机任务在过载或者即将过载状态的计算结点进行恢复,将会引发云平台的计算结点再次出现宕机的情况。因此,在对宕机任务进行恢复时一定要考虑到云平台所有计算结点的负载均衡状态,降低由于恢复宕机任务而导致计算结点负载不均衡的可能。在本文中,云平台所有计算节点平均利用率的方差被用来表示云的总体负载平衡。云计算中心所有计算结点的负载均衡方差的值越小,就表明云中各计算节点的整体负载越均衡。假设完成任务td(1≤d≤n)所需的虚拟机容量是vmd,且每个计算节点的平均利用率由ρd来表示,可以表示为:
①系统覆盖范围和用户较广。在管理内容上覆盖了水利、供水、排水、水文四大行业;在管理范围上覆盖了国家、直辖市、区(县)三级管理;在建设范围上覆盖了自动化和信息化等方面集成;在用户使用上覆盖了水行政主管部门、企业、科研规划部门、社会公众等。

其中,ω(ti)表示的是判断任务ti是否运行在计算结点psw(1≤w≤l)上,表示为:

此外,ρ被用来表示云平台中所有计算结点的平均资源率,表示为:

最后,通过以上计算得出了云平台各计算结点的平均资源利用率和云平台总体的平均资源利用率,由此可以的得到云平台的负载均衡,可以表示为:

2.4 目标函数
在云平台的计算结点发生错误时,需要尽快对部署在这些计算结点上的计算任务在其他正常计算结点重新启动,以确保数据密集型应用的完成时间D最短的同时,也要保证云平台各计算结点的负载均衡U。本文所需要实现的目标和约束具体表示为:

3 本文方法
其中hsmz代表的是下载ftz镜像数据所需要的时间,hsfz是获取该任务的前驱任务执行产生数据所花费的时间,hssz是在计算结点上重启ftz所需要的时间。
基于前文分析,从深层原则与基础理念看,近代以来西方社会管理的基本要素或基本原则主要有两个:一是个人主义,二是理性主义。
3.1 数据密集型应用完成时间计算方法
数据密集型应用的完成时间是指从开始任务到结束任务所需要的最长执行时间,也就是关键路径上所有任务完成所花费的时间的总和。为了计算出数据密集型应用的完成时间,在算法1中,首先需要找出数据密集型应用中的关键路径,然后对关键路径上面的关键任务所需要的时间进行求和,从而得到数据密集型应用的完成时间。
算法1 数据密集型应用的完成时间
输入 数据密集型应用
输出 数据密集型应用的完成时间D
2、外部信息沟通不顺畅。电力企业为更好地实现往来账款信息的及时清理,建立了有关往来款核对的第三方平台,用于信息的及时核对。但现实操作中,往往会出现一家供应商与多个业务部门之间的往来业务,导致最终的询证函发放工作还在财务部门。这种一对多的往来信息核对无法依靠第三方平台实现,很容易因财务的人工核对造成错误。
初始化关键任务集合V
for 所有的宕机任务结点 do
根据式(1)、(2)计算任务的最早开始时间和最早结束时间
根据式(3)、(4)计算任务的最晚开始时间和最晚结束时间
if 该任务的最早开始时间和最晚开始时间相等 do
将该任务放置到关键任务集合V中
end if
end for
其中,计算结点和TOR层交换机之间的带宽表示为rst,TOR层交换机与汇聚层交换机之间的带宽表示为rta,汇聚层交换机与中继层交换机的之间带宽表示为rau。
if 该任务是tstart
首先讨论超级人工智能。超人无比强大。对于人类与超人的关系,不是人类面对超人人类该怎么办,因为人类根本没有应对能力,根本无法控制超人,而是超人会如何对待人类。
fortstart的后继任务
选择tstart需要花费时间最长的后继任务ti
D+ti完成所需要的时间+数据传输时间
end for
要做到“两个过程”的合理性,即从数学知识发生发展过程的合理性、学生认知过程的合理性上加强思考,这是落实数学核心素养的关键点.前一个是数学的学科思想问题,后一个是学生的思维规律、认知特点问题.
end if
end for
返回数据密集型应用的完成时间D
3.2 基于NSGA-III容错性资源配置方法
基于以上的分析,恢复任务的计算结点需要获取宕机任务的镜像数据和该任务前驱任务所产生的数据,首先假设宕机任务ftz的镜像数据大小为dmz,则在psd上获取该任务的镜像数据所需要的时间hsmz可以表示为:
1)基因操作:在遗传算法中,基因操作分别是交叉和变异。其中交叉(Crossover)是指通过将两条父母染色体经过交换部分基因的方式产生两个新的后代,这样产生的子代染色体会继承优良基因从父母,并且可以形成子代染色体自身独特的基因型,方便找到最优解。此外,突变(Mutation)作为另一种基因操作,染色体通过小概率的基因突变会使得该染色体上的一个基因型被该染色体上的另一个等位基因所取代,从而形成一个新的个体。通过多次基因操作有效提高了种群的多样性,加快了目标解的结果收敛。
根据公式(1)计算出来的最早开始时间和完成任务所需要花费的时间ei,任务的最早结束时间可以由下式计算出来:
3)选择优化:事实上,由于NSGA-III可以生成多个表示故障任务资源供应策略的解决方案。因此,为了得到最优解,实现了简单加权法(Simple Weighting Method, SAW)和多准则决策(Multiple Criteria Decision Making, MCDM)从多种策略进行归一化处理,从而选出最优资源配置策略。使用SAW和MCDM计算每个解决方案的效用值,并选择效用值最大的解决方案作为最终的资源配置策略。假设EiD和FiD分别表示两个目标的值,EDmax、EDmin、FDmax和FDmin分别表示两个目标函数的最大和最小值。此外,ε1和ε2作为数据密集型应用完成时间和负载平衡的权重指标,两者之和为1。
FFD:该方法的核心思想是首先将云平台中还在正常运行的计算结点按照剩余容量进行升序排序,然后每一个宕机任务将在剩余容量可以满足该任务的计算结点重启,该方法最大的特点就是一旦找到能够满足该任务的计算结点就不再继续找其他更合适的计算结点了。
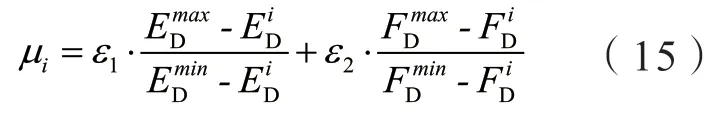
4 实验评估
4.1 实验环境
本实验是在一台配有Intel Core i7-5500U 处理器和8GB 内存的电脑上完成的。本文使用云平台发生错误后数据密集型应用的完成时间、云平台的负载均衡这两个评估标准来展示FRPM的在动态资源分配的优越性。此外,实验中使用的VL2网络拓扑结构搭建的云平台的具体参数如表1所示,网络的具体参数配置是根据文献[18]而来。
在我国,小麦的面积和总产仅次于水稻和玉米,为第三大粮食作物,在国民经济中占有重要地位。面粉颜色是小麦品质评价的重要指标,而籽粒黄色素含量是影响面粉颜色的主要因素。因此,研究小麦籽粒黄色素含量形成机制及其相关基因,对我国小麦面粉颜色品质改良具有重要意义。

表1 参数设置
4.2 对比方法
为了充分展示出FRPM的性能,在本文实验过程中选择了Benchmark、FFD和BFD[5,9]进行比较,三种方法的基本原理如下:
非线性偏微分方程有很多的应用,尤其是非线性方程的孤子解,在工程、光纤和物理等领域都起着很重要的作用。因此求解非线性偏微分方程的孤子解变得越来越重要了,但是它的求解是非常困难的,尤其是高阶非线性偏微分方程。直到最近几十年,随着计算机软件的发展,如MATLAB、Mathematica等,许多的求解非线性偏微分方程孤子解的方法被提出,非线性方程求解方向获得很大发展[1-16]。
Benchmark:该方法的核心思想是为每一个宕机任务随机选取一个正常运行的计算结点进行恢复。
鄂麦398田间综合抗病性较好,但抗性鉴定结果表明该品种高感条锈病和纹枯病、中感赤霉病和白粉病,生产中应注意防治条锈病、纹枯病、赤霉病和白粉病,搞好“一喷三防”。
5.统一规范,把好项目资料关。规范基础工作是审计项目顺利开展的前提和保障,审计组长在强化审计项目质量的同时,要摈弃“重成果、轻基础”的错误导向,按照“规范、全面、标准”的要求,实行审计基础工作标准化管理,保证审计资料归档的及时性、准确性、完整性,促进审计质量和工作效率的提高。
BFD:该方法的核心思想是首先将云平台中还在正常运行的计算结点按照剩余容量进行升序排序,然后每一个宕机任务将在剩余容量刚好满足该任务的计算结点重启,该方法最大的特点就是宕机任务找到的重启任务的计算结点的剩余容量是所有正常运行计算结点中最小的。
4.3 实验结果与分析
4.3.1 应用完成时间对比
数据密集型应用的完成时间是评价宕机任务恢复方法的关键标准。在云平台的计算节点发生故障后,宕机任务需要得到有效的恢复以使得数据密集型应用的完成时间尽可能短。在本实验过程中,首先随机选取五个宕机任务,而后每次向宕机任务集合中添加两个宕机任务。在数据密集型应用的完成时间这一指标中,Benchmark、BFD、FFD和FRPM的实验结果如表2所示。其中,Benchmark、BFD和FFD算法所为宕机任务找到资源配置策略虽然能够使得任务得到恢复并继续执行,但是算法在执行过程中未考虑到数据密集型应用的整体的完成时间,而FRPM方法在迭代寻找资源配置的过程中始终将数据密集型应用的完成时间作为考量指标,所以也就导致使用Benchmark、BFD和FFD对宕机任务进行恢复后的完成时间明显长于FRPM。此外,在实验过程中为了避免FRPM所找出的资源配置策略出现局部最优解,所以对FRPM所得出的解借助SAW和MCDM进行了归一化处理,从而避免出现局部最优解的问题。
“当然有啊,”陆教授说,“古代又没有电脑制图,也没有现代化的造币机,那么第一批样钱,也就是我们说的雕母,当然是纯手工造的啊。而且肯定比别的钱造得精细。要是样品都造得随随便便,成品钱就不象样了。”

表2 数据密集型应用完成时间对比 (单位:秒/s)
4.3.2 平均资源使用率对比
大量的计算资源被部署在云平台以满足用户对计算能力的需求,一般情况下,云平台的计算资源是希望被充分利用,所以云平台的计算资源是否被充分利用也是衡量资源配置策略有效性的重要因素。在本文中,通过计算每个计算节点所占用的虚拟机数量来评估云平台的平均资源利用率。如表3所示,对比了Benchmark、BFD、FFD和FRPM在 不 同宕机任务情况下的云平台的平均资源利用率。可以看出:由于FRPM在为宕机任务进行资源配置时对当前云平台所有计算结点的资源使用率进行了充分考量,所以随着宕机任务数量的增加,云平台的资源利用率也随之增大;而Benchmark、BFD和FFD在进行资源配置的时候仅考虑单一计算结点的资源使用率,并没有考虑云平台整体的资源使用率,所以不能为宕机任务进行均衡的资源配置。
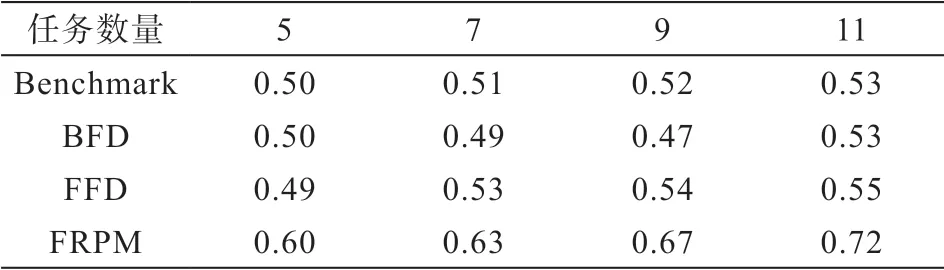
表3 平均资源使用率对比(*102%)
4.3.3 负载均衡对比
负载均衡作为宕机任务恢复方法的一个重要评价指标,一方面,当云平台总体保持负载均衡时可以在最大程度上发挥各计算结点的性能。另一方面,当云中的所有计算节点都保持负载平衡状态时,所有的计算结点都处在较为稳定的状态,降低了计算节点出现问题的风险,在一定程度上提升了云计算中心的容错性。一般情况下,负载平衡方差的值越小,就表示云计算中心所有计算节点的负载平衡越好。如表4所示,随着宕机任务数量的增加,在Benchmark、BFD、FFD和FRPM对宕机任务进行资源配置之后,云计算中心计算结点的负载均衡方差都在随之增加。其中,FRPM所得到的负载均衡方差值最小,BFD的负载均衡方差比FRPM大,而Benchmark和FFD得到的负载均衡方差值最大。主要原因时由于Benchmark和FFD在为宕机任务进行资源配置的过程中不考虑各计算节点的负载而直接进行资源配置,所以导致两种算法在为宕机任务进行资源配置的时候云计算平台的负载均衡方差值相差无几;BFD在为宕机任务进行资源配置的时候,首先会考虑最所剩容量适合宕机任务的计算结点,所以使得云计算中心的负载较好;而FRPM在寻找宕机任务资源配置策略时会综合考量云计算中心所有计算结点当前所处的负载状态,因此得到的资源配置策略使得云计算中心处于更好的负载均衡状态。
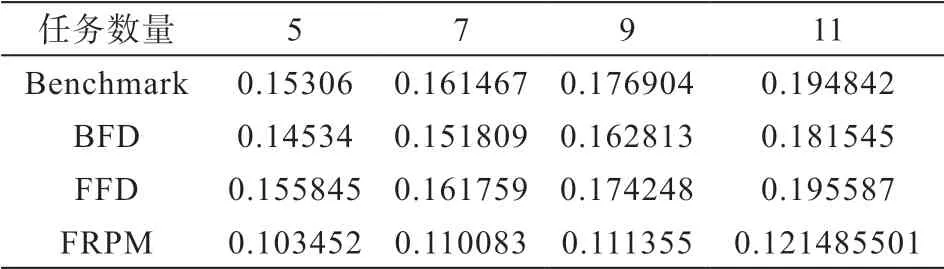
表4 负载均衡对比
5 结束语
在本文中,为了保证在云平台发生故障时,部署在云平台的数据密集型应用的完成时间最短的同时,云平台的负载均衡也能得到有效的保证,本文提出了一种基于NSGA-III的FRPM方法。该方法为云平台中发生错误的数据密集型应用进行有效的资源配置以保证数据密集型应用在云平台发生宕机时的完成时间最短的同时,也能够保证云中所有计算节点的负载均衡。最后,通过大量的实验对FRPM的有效性进行了验证。在未来的工作中,在恢复宕机任务过程中,应用数据的隐私问题需要被考虑。
大数据时代下,企业的发展依赖于信息化平台的建设,资源共享平台建设是会计信息化的重要发展趋势和前进方向。资源共享平台的构建会为管理者决策行为提供可靠保障,为了避免会计信息化发展过程中信息孤岛的出现,资源共享平台的开拓有着十分重要的意义。
