基于快速字典学习的压缩感知地震数据重建
2022-03-24李婷婷段中钰
李婷婷, 段中钰
(北京信息科技大学 信息与通信工程学院,北京 100101)
0 引言
地震数据重建是地震数据处理中的基础步骤,通过重建可以增强地震数据中的有效信号,抑制不利于后续数据处理和解释的成分,从而提高地震勘探的准确性,降低油气开发的成本。
近几年来发展起来的压缩感知理论[1-3]为(Compressed Sensing,CS)为地震数据重建提供了新的思路,稀疏信号可以在低于奈奎斯特采样频率的条件下恢复出原始数据,数据的稀疏表示是压缩感知地震数据重建的前提和基础。地震数据的稀疏表示主要有单一变换域的稀疏表示和字典学习的稀疏表示。单一变换域的稀疏表示主要是数据通过固定正交基进行变换(Curvelet变换[4]、Seislet变换[5]、Shearlet变换[6]、小波变换[7]等),这种方法虽然构造简单, 计算复杂度低, 但是变换基是固定的, 不能根据地震数据复杂的细节结构自适应的调整。字典学习解决了单一变换无法对复杂地震数据进行理想稀疏表达的问题。字典学习即用字典中若干个原子来表示信号,每组原子可以独立的张成完备的空间,在超完备空间里,信号不是唯一的,这样的优点在于可以通过学习训练的方式自适应地寻找最佳的基底原子组合,实现信号的最稀疏表示。学习型字典能够通过样本地震数据不断地学习训练得到含有地震数据信息的自适应字典,从而刻画地震数据的本质特征,得到地震数据的最稀疏表示。常用于压缩感知地震数据重建的超完备字典学习算法是K-SVD(K-singular value decomposition)[8-9]。周亚同等[10]提出压缩感知框架下K-SVD字典学习对地震数据进行稀疏表示,再结合正则化正交匹配追踪算法有效地实现了缺失地震数据的重建。但是K-SVD字典学习算法存在无法得到全局最优解并且不能保证收敛的问题,会影响地震数据重建精度,且在数据量较大的重建任务下字典训练时间长、迭代较慢。笔者针对以上问题,提出快速字典学习算法(Fast Dictionary Learning,FDL),①将稀疏表示目标函数优化求解分为两个子优化问题进行循环求解;②在稀疏编码阶段将稀疏约束上限与字典相干性结合,自适应获取稀疏上限。在此基础上提出基于压缩感知理论的FDL重建地震数据的模型,使用模拟和大庆油田实际地震数据对本方法进行了验证。
1 方法原理
1.1 压缩感知理论
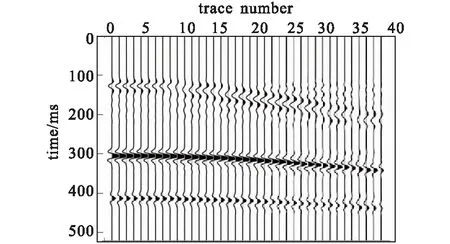
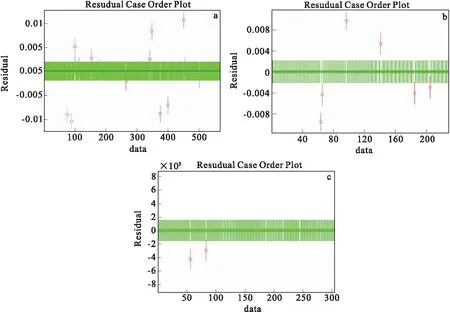
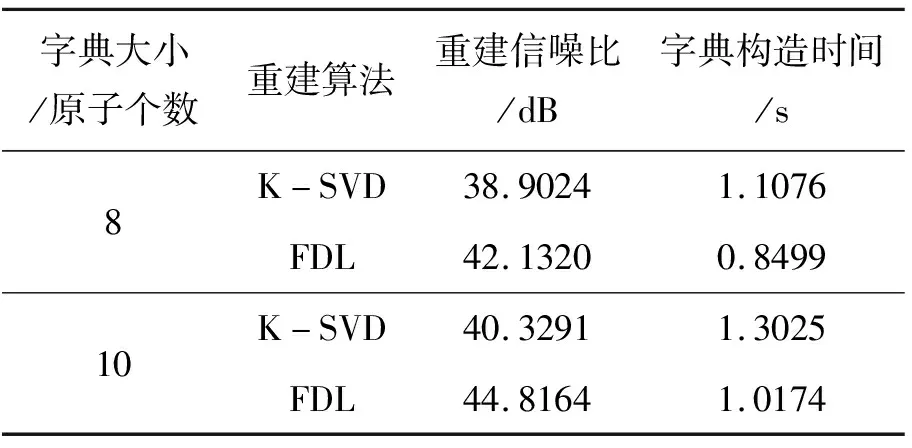
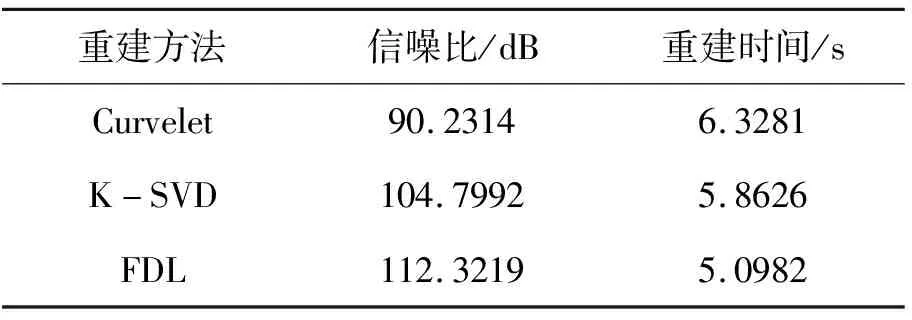
压缩感知理论指出对于稀疏信号xi∈Rn(i=1,2,…,N),可以利用一个与变换基Ψ不相关的观测矩阵Φ∈Rm×n(m< 已知原始信号在观测矩阵的观测值为: y=Φx (1) 用观测矩阵不相关的变换基Ψ对原始信号进行稀疏表示,得到稀疏矩阵Θ: x=ΨΘ (2) y=ΦΨΘ (3) (4) (5) 字典学习稀疏表示的主要思想是利用字典矩阵D稀疏线性表示原始样本X。用字典学习对地震数据进行稀疏表示可以描述为: X=DΘ (6) 其中:X={x1,x2, …,xN}∈Rn×N表示包含N个子地震数据块的输入矩阵;D∈Rk×K表示含有K个原子dk的字典矩阵;Θ∈RK×N表示与字典D对应的稀疏系数矩阵。 稀疏矩阵和字典矩阵通过求解优化问题得到: (7) 其中,T0为稀疏表示系数中非零分量数目的上限。 快速字典学习算法稀疏表示目标函数定义如下: (8) 其中:Θi为矩阵Θ第i列;Dj为矩阵D的第j列。字典矩阵D和稀疏矩阵Θ是非凸的,但在稀疏编码阶段,固定字典D,则对于Θ为凸的;在字典更新阶段,固定稀疏矩阵Θ,则对于D为凸的。K-SVD算法稀疏编码阶段通常使用正交匹配追踪算法,字典更新阶段使用奇异值分解,但正交匹配追踪算法收敛速度较慢,且无法得到全局最优解。与K-SVD不同的是,FDL将目标函数分解为两个子优化问题,对于每个子优化问题,用块坐标下降法直接求出目标函数的全局最优解。因此,FDL算法的稀疏编码阶段优化问题为: (9) 字典更新阶段优化问题为: (10) 每次更新Θ的一行或是D的一列,更新速度与字典大小相关联。 为了使字典能够对地震数据表示更稀疏,将稀疏约束上限与字典的相干性关联,从而获得自适应稀疏约束上限。 引入定理1: 给定字典D∈Rk×K(K>n),其相干性为μ(D),假设x=Dα有稀疏解α,其稀疏度S若满足: (11) 则能从字典D中找出最佳的S项原子的线性组合。其中字典的相干性μ(D)∈[0,1],μ(D)=max|[di,dj]|,i≠j其描述了字典中原子间的最大相似程度,当μ(D)值很大时,字典原子间相似程度很强,反之很弱。 定义Lp为每次迭代过程中的稀疏约束上界: (12) 由定理1可知稀疏约束上限Lp能够保证稀疏信号被精确重建。使用Lp代替式(9)中的T0,则稀疏编码阶段即为求解如下的优化问题: (13) K-SVD算法地震数据重建流程图如图1所示。 图1 K-SVD地震数据重建流程图 K-SVD算法地震数据重建: 1)随机挑选个K原子形成初始字典,初始化稀疏矩阵为零。 2)稀疏编码阶段。固定字典D,使用正交匹配追踪算法更新稀疏矩阵Θ。 3)字典更新阶段。固定稀疏矩阵Θ,奇异值分解逐列更新字典D。 FDL算法地震数据重建流程图如图2所示。 图2 FDL地震数据重建流程图 FDL算法地震数据重建: 1)根据缺失地震数据随机挑选K个原子形成初始字典D0,设置迭代次数i=0。 2)根据初始字典D0计算式(12)得到初始化稀疏约束上限L0。 3)稀疏编码阶段。固定字典Di和稀疏约束上限Li,使用块坐标下降法计算式(9)逐行更新得到最优的稀疏矩阵Θi+1。 4)字典更新阶段。固定稀疏矩阵Θi+1,使用块坐标下降法计算式(10)逐列更新得到本次迭代的最优字典矩阵Di+1。 5)用步骤2)、步骤3)、步骤4)得到稀疏约束上限、稀疏矩阵和字典矩阵更新目标函数即式(8)。 6)判断是否达到收敛条件,通过计算(f(i)-f(i+1))/f(i)>1×10-5进行判断,若是则返回步骤2),若否则停止迭代,输出字典矩阵D和稀疏矩阵Θ。 字典大小对重建精度有影响,但是只能根据经验选取,首先根据地震数据随机选择K个原子,随后在将字典大小改为K±j,j=1、2…,最终选择重建信噪比最高,重建性能最好的字典。 采用信噪比作为地震数据重建性能的评判标准为式(14)。 (14) 模拟地震数据共38道,时间采样率为0.004 s,如图3所示,其进行随机采样,采样率为0.3,采样后数据如图4所示。分别用传统稀疏表示方法Curvelet、经典K-SVD字典学习算法以及FDL算法,对缺失地震数据稀疏表示然后进行重建,重建结果如图5~图7所示。由图5~图7可知,Curvelet、K-SVD字典学习和FDL算法在压缩感知的框架下都实现了缺失地震数据的重建,但是从图5可以看出,部分地震数据没有被完全恢复,地震波附近出现抖动,且原来未缺失数据受到影响(图中箭头所示);从图6可以看出,K-SVD字典学习重建地震数据结果较Curvelet更好,基本实现了缺失数据的重建,但是存在重建振幅与原始数据振幅不一致的问题(图中箭头所示);而从图7可以看出,FDL算法重建后数据振幅连续性良好,重建精度较高,很好地实现了缺失数据的重建。 图3 原始地震数据 图4 缺失地震数据 图5 Curvelet地震数据重建结果 图6 K-SVD地震数据重建结果 为了更清楚地对比三种算法,将三种算法的重建结果与原始地震数据进行对比,选取缺失较多的25至38道数据,对比结果如图8所示。对比图8(a)、图8(b)、图8(c)可以看出,Curvelet算法重建振幅与原始数据振幅差异较大,K-SVD算法重建振幅差异较小,而FDL算法重建振幅与原始数据振幅一致。 图8 三种算法重建结果与原始地震数据对比 三种算法的重建信噪比与重建时间见表1。结合表1和图5~图7 可以看出,在相同采样率且K-SVD字典学习和FDL字典大小相同的情况下,传统Curvelet变换的方法重建信噪比最小,部分缺失数据未得到恢复,对缺失地震数据的重建效果最差,且重建耗时最长;K-SVD字典学习重建信噪比较Curvelet高,重建耗时也相对增加;而FDL地震数据重建信噪比最高,对缺失的地震数据实现了恢复,重建效果最好,且重建耗时最短。 表1 重建方法信噪比及重建时间 三种算法的重建残差图对比如图9所示。三种算法重建模型大部分都能较好的符合原始数据,但是相比来说Curvelet和K-SVD算法存在较多异常点,而FDL异常点较少,FDL算法重建性能相比较好。 图9 三种重建方法残差图 表2为字典数量差异及其重建性能。由表2可知,字典大小的选择对重建性能有一定的影响,字典越小,字典构造时间越短,重建信噪比越小;字典越大,字典构造耗时变长,信噪比越大。对于K-SVD字典学习和FDL算法,在构造相同大小的字典的情况下,FDL算法的重建信噪比更大,字典构造时间更短,性能更好。若要得到相同的重建信噪比,K-SVD字典学习相较FDL需更长的时间构造字典,从而重建所需时间更长。 表2 K-SVD与FDL性能对比 模拟地震数据验证了本文方法的有效性,因此将本文方法应用到大庆油田的三维地震数据中,选取其中的200道数据,200个采样点,时间采样率为1 ms,如图10所示,对该数据进行随机采样,缺失数据如图11所示。 图10 原始三维地震数据 分别用Curvelet变换、K-SVD算法以及FDL算法对随机采样后的地震数据进行重建(K-SVD字典学习和FDL的字典大小相同),重建结果如图12~图14所示。对比图12~图14,可以看出Curvelet重建地震数据效果一般,同相轴模糊不清,而FDL很好地实现了地震数据的重建,同相轴清晰,振幅连续。为了能更清晰地观察重建效果,将随机缺失较多的50道至60道数据与原始地震数据进行对比(图15),对比可以看出,Curvelet变换重建地震数据振幅与原始地震数据振幅相差较大,K-SVD重建振幅较Curvelet稍好,而FDL重建振幅与原始地震数据基本一致。三种算法的重建信噪比与重建时间如表3所示,由表3可知,FDL压缩感知地震数据重建耗时最短。 表3 重建方法信噪比及重建时间 图12 Curvelet重建地震数据结果 图13 K-SVD重建地震数据结果 图14 FDL重建地震数据结果 图15 三种算法重建结果与原始地震数据对比 笔者提出的基于快速字典学习的压缩感知地震数据重建,通过快速字典学习对地震数据块进行稀疏表示实现地震数据的重建。模拟和大庆油田地震数据验证可以得到以下结论:利用FDL比经典K-SVD字典学习能够更好的重建缺失地震数据,重建精度更高,重建耗时更短,对地震数据中复杂波形区域能够有效的重建。另外,对于含噪声的地震数据如何使用本文提出的方法进行去噪,是下一步研究的内容。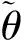
1.2 快速字典学习算法



2 技术流程
2.1 基于K-SVD的压缩感知地震数据重建

2.2 基于FDL的压缩感知地震数据重建

3 仿真验证

3.1 模拟地震数据仿真验证





3.2 实际地震数据仿真验证





4 结论
