基于PyEcharts的数据可视化
2022-03-19张玉叶
张玉叶


摘要:图表的应用不但可使得数据的显示更加清晰、直观,而且可大大增强Web页面的功能和显示效果。针对目前大数据时代背景下如何将数据进行合理有效的可视化展示,从而快速获取数据中所包含的关键信息这一广泛需求,文章通过对一商品销售数据分析介绍了如何利用Python的第三方扩展库PyEcharts来对数据进行合理有效的可视化展示,给出了具体实现方法和代码。
关键词:数据可视化;PyEcharts;Python;图表
中图分类号:TP311.1 文献标识码:A
文章编号:1009-3044(2022)02-0024-04
在信息时代飞速发展的今天,每天都在产生海量数据,如何从这些海量数据中快速发现和获取有用信息,最常用的方法就是数据的可视化。数据可视化是传达数据分析结果的重要环节,是对所获取信息、知识、模式的图形化展现,其核心目的是清晰、美观、有效地传达与沟通信息[1]。数据可视化的方案有很多,可根据实际使用场景来选择。本文使用的是Python的第三方扩展库PyEcharts。PyEcharts 是一个用于生成 Echarts 图表的JS类库,Echarts 是百度开源的一个数据可视化工具包。利用PyEcharts,通过编写少量代码就可方便快捷地生成Echarts风格的各种图表,是大数据时代进行数据可视化的常用方案[2]。
本文通过饼图、柱状图、玫瑰图等不同形式图表多角度地解读示例数据,通过此例来展示如何将数据合理有效地可视化,从而快速获取我们所需要的关键信息。
1 数据集
在此以一个商品在全国各地的销量及损坏量的数据集作为示例数据,要分析的数据集中部分数据如表1所示(在此只显示了整个数据集中的前10行数据)。
表1中各字段含义:date(销售日期)、sales(商品销量)、destroy(商品损坏量)、area(销售地区)。
2 开发环境
本文示例所采用的开发工具及相应扩展库的版本:Python3.6、Pandas1.0.3、PyEcharts1.7.1。所有代码在Jupyter notebook中实现。
要在Python中使用PyEcharts,首先需要安裝PyEcharts,使用命令pip install pyecharts进行PyEcharts库的安装[3] 。
3 数据可视化
使用PyEcharts绘制图表的大体过程可分为以下步骤:
1)导入相应的包;
2)准备绘制图表所需要的数据;
3)生成图表;
4)对图表进行相应的设置;
5)渲染图片。
3.1 各大区销量分布情况
假设要想查看商品在全国各大区的销量分布占比情况,可采用饼图来展示。具体绘制过程如下:
1)导入相应的包
利用PyEcharts绘制饼图,需要导入两个包,一个是用于绘制饼图的Pie包,另一个是用于进行系列配置和全局配置的options包。
对应代码如下:
from pyecharts.charts import Pie # 用于绘制饼图的Pie包
from pyecharts import options as opts # 用于进行设置的options包
2)准备绘制图表所需要的数据
绘制饼图需要的数据是类似[[‘华东,3000],[‘华北,2800]]这种形式的数据,要显示商品在各大区的销售分布情况,因此需要各大区及其所对应的商品销售总量。数据集中给出的是每天不同地区的销售量,因此需要先将地区转换成所属的大区,然后按大区对商品销量进行分组汇总,即可得到各大区的商品总销量。
首先定义一个将地区转换成大区的函数,代码如图1所示。
然后读取数据集,对数据集进行相应的处理,分组统计各大区的销量,将统计结果转换成绘制饼图所需要的数据格式,代码如下:
data = pd.read_csv('data/商品销售情况表.csv') # 读取数据集
data['zone'] = data['area'].apply(zone) # 将地区转换成大区
grp_data = data.groupby('zone')['sales'].sum() # 分组汇总
pie_data = [[i,v] for i,v in zip(grp_data.index,grp_data)] # 数据格式转换
3)生成图表
首先调用Pie()方法生成一个饼图对象,然后调用其add()方法添加数据。
PyEcharts支持链式调用,因此两个方法可连续书写,对应代码如下:
pie_ = Pie().add('',pie_data)
4)图表设置
图表设置通常包括系列设置和全局设置。
系列设置中最常用的是饼图上是否要显示数据标签,默认设置为不显示,如果要想显示,可通过如下代码进行设置:
pie_.set_series_opts(label_opts = opts.LabelOpts(formatter = '{b}:{d}%'))
全局设置中通常需要设置的是图表的标题。设置代码如下:
pie_.set_global_opts(title_opts = opts.TitleOpts(title = '各大区销量分布情况'))
5)渲染图片
生成的图片可直接放到HTML文件中,也可直接在notebook中显示。
如要将图片放到HTML文件中,可使用代码:
pie_.render('各大区商品销量分布情况.html')
如要直接在notebook中显示图片,则使用如下代码:
pie_.render_notebook()
全国各大区商品销量分布饼图绘制完整代码如图2所示:
运行上述代码,会生成相应的HTML文件“各大区商品销量分布情况.html”,用浏览器打开该HTML文件,结果如图3所示。
当鼠标停留在饼图的某部分上时,会突出显示此部分,并显示相应的销量信息,效果如图4所示。
通过饼图,可清晰地看到商品在不同大区的销量分布占比情况,同时也可方便快速地查看指定大区的销量情况。
上面绘制的是商品在不同大区的总销售量,用同样方法也可绘制商品在不同大区的损坏数量等,只需要将所需数据源替换一下即可。类似这种需要分布占比情况数据的可视化,用饼图都是一个不错的选择,所以饼图通常用于展示各部分的占比情况。
3.2 商品销量前10的地区
想要查看商品在哪些地区的销量最好,可采用柱状图来展示。在此显示销量最高的前10个地区。
1)导入相应的包
from pyecharts.charts import Bar
from pyecharts import options as opts
2)准备绘制图表所需要的数据
要想获取商品销量前10的地区,需将数据集先按地区分组统计总销量,然后按总销量降序排列,最后取其前10个即可,对应代码如下:
data = pd.read_csv('data/商品销售情况表.csv') # 读取數据集
area_data = data.groupby(by='area',as_index=False).sum() # 按地区分组汇总
bar_data = area_data.sort_values(by='sales',ascending=False)[:10] # 销量前10地区
3)绘制相应的柱状图及设置相应的配置
柱状图的绘制相对比较简单,只需分别指定X轴和Y轴的数据,配置项通常只需设置图表标题,在此将图表绘制及配置项设置直接采用链式写法,相应代码如下:
bar = (
Bar()
.add_xaxis(bar_data['area'].tolist()) # x轴为地区名称
.add_yaxis('', bar_data['sales'].tolist()) # y轴为商品销量
.set_global_opts(title_opts=opts.TitleOpts(title= '商品销量前10地区') #设置标题
)
4)渲染图片
在此直接利用代码:bar.render_notebook()在notebook中渲染图片。
完整的代码如图5所示。
运行上述代码,结果如图6所示。
3.3 商品损坏量前10地区
商品在运输或储存过程中会有相应的损坏,数据集中存放有商品在不同地区的损坏量。如果要想查看各大区的商品损坏量,可以利用前面介绍的饼图来展示;如果要查看商品损坏量前10地区,可以利用柱状图来要展示。如果是除了想查看商品损坏量最高的前10地区外,还想看看各地区商品损坏量在这10个地区中商品总损坏量中的占比情况,这时更好的可视化图表是南丁格尔玫瑰图。南丁格尔玫瑰图实际上就是一种特殊的饼图。
1)导入相应的包
from pyecharts.charts import Pie
from pyecharts import options as opts
2)准备绘制图表所需要的数据
要想获取商品损坏量前10的地区,需将数据集先按地区分组统计各地区商品损坏总量,然后按商品损坏总量降序排列,最后取前10个即可,对应代码如下:
data = pd.read_csv('data/商品销售情况表.csv') # 读取数据集
area_data = data.groupby(by='area',as_index=False).sum() # 按地区分组汇总
destroy_data = area_data[['area','destroy']].sort_values(by='destroy',ascending=False).values[:10]
3)绘制图表
绘制南丁格尔玫瑰图时除了设置普通饼图所需要的系列名称和数据外,通常还需要设置内外半径和圆心位置及玫瑰图的模式。玫瑰图有两种模式:radius和area。radius模式是通过半径区分数值大小,角度大小表示占比。area模式是角度都相同,通过面积而表示数值大小。可根据情况自行选择,在此采用area模式,对应代码如下:
pie = Pie().add(series_name = "商品损坏数量", # 系列名称
data_pair = destroy_data, # 数据
radius = ["20%", "80%"], # 设置内半径和外半径
center = ["60%", "60%"], # 设置圆心位置
rosetype = "area" # 玫瑰图模式
)
4)配置项设置
将图表中的标签文字形式设为:“地区:占比(%)”的形式,通过设置系列配置项来完成,代码如下:
pie.set_series_opts(label_opts = opts.LabelOpts(formatter="{b} : {d}%"))
然后设置图表标题及位置、图例及位置,通过全局配置项来完成,代码如下:
pie.set_global_opts(title_opts = opts.TitleOpts(title="商品损坏量前10地区",
pos_right = '40%'),
legend_opts = opts.LegendOpts( orient='vertical',
pos_right="85%",
pos_top="15%")
)
5)渲染图片
在此直接利用代码:pie.render_notebook()在notebook中渲染圖片。
完整的代码如图7所示。
运行上述代码,结果如图8所示。
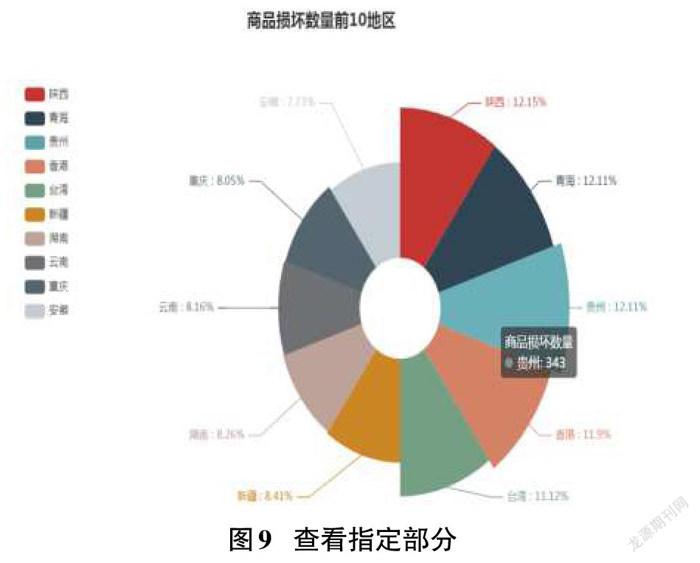
将鼠标移动到某部分上,可显示其对应的具体数据,效果如图9所示。
4 结束语
通常,使用自然语言、数字等形式表达的概念是枯燥的、不易懂的,而可视化的技术可增加数据的生动性[4],因而人类通过视觉获取数据比任何其他形式的获取方式更好[5]。图表的应用不但可使得数据的显示更加清晰、直观,而且大大增强了Web页面的功能和显示效果。本文介绍的利用Python的第三方扩展库PyEcharts绘制图表的方法,其实现简单方便,在目前大数据时代背景下有着广泛的应用领域和良好的使用前景。读者可参考其实现思路稍微改动一下即可实现更多类似的数据可视化效果,从而提高数据可视化处理能力。
参考文献:
[1] 张延松,徐新哲.数据分析与数据可视化实战[M].北京:电子工业出版社,2020.
[2] 零一.Python 3爬虫、数据清洗与可视化实战[M].北京:电子工业出版社,2018.
[3] 董付国.Python数据分析、挖掘与可视化[M].北京:人民邮电出版社,2019.
[4] 吴振宇,李春忠,李建锋.Phthon数据处理与挖掘[M].北京:人民邮电出版社,2020.
[5] 柳毅.Python数据分析与实践[M].北京:清华大学出版社,2019.
【通联编辑:谢媛媛】
