基于异质信息网络的恶意代码检测
2022-03-08刘亚姝侯跃然严寒冰
刘亚姝,侯跃然,严寒冰
(1.北京建筑大学 电气与信息工程学院,北京 100044; 2.北京邮电大学 网络技术研究院,北京 100876;3.国家计算机网络应急技术处理协调中心,北京 100029)
恶意代码可以定义为任意对用户、计算机或网络做出危害的软件[1]。一般来讲,恶意代码包括病毒、蠕虫、后门、漏洞攻击程序、特洛伊木马、rootkit等。随着技术的发展,恶意代码的产生越来越简单,恶意代码的变体也越来越多,对网络安全和信息安全造成了严重的威胁。
恶意代码的检测可以分为静态分析和动态分析两大类别。动态分析需要在沙箱中或者虚拟机里实际运行可执行文件,分析执行程序的行为来识别各种潜在的危害行为和攻击行为,以便识别代码的恶意性。动态分析是恶意代码分析的一个重要研究方向,相对静态分析方法而言,动态分析更常用于工业应用中。
本文通过在沙盒中观察样本的动态执行过程,提取动态API的访问序列、调用的DLL等信息构建异质信息网络(heterogeneous information network,HIN)。在所获得的节点类型不充足的情况下,改进随机游走策略,选取合适的方法描述元图特征,从而实现恶意样本的检测和分类。
图是一种直观地表现出对象之间关系的工具。通常用有向图描述对象之间的联系,这样的有向图也称为信息网络。图中顶点表示对象、边表示对象间联系。如果信息网络中描述的对象类型是不同的,也就意味着图中有多种类型的数据及多种关系,则被称为异质信息网络,否则称为同质信息网络[2-3]。与同质信息网络相比,异质信息网络更能反映真实条件下对象之间的关系,具有更丰富的结构和语义信息。常见的异质信息网络有社交网络、科技文献、医疗系统等。
由于异质信息网络的研究对象类型、链接关系多样化,传统的图方法并不适用。2011年,Sun等[4]提出了元路径(meta path)的概念,给出了异质网络的分析工具,通过对称元路径抽取2个节点之间的链接关系,同时定义了一种名为PathSim的相似度度量方法,用于在异构网络中寻找对等对象。2012年,Sun等[5]提出了元路径的聚类方法——PathSelClus。异质信息网络中一个很重要的任务是将元路径提取的分散语义信息进行聚合。PathSelClus采用在用户提供一个小的对象种子集合的指导下(称为用户指导)实现元路径聚类。PathSelClus方法可以自动学习和设置元路径聚集时的权重问题,与其他方法相比具有聚类结果稳定、隐含语义信息的效果。2014年,Shi等[6]提出了在异质信息网络中用统一框架判断相同类型节点和不同类型节点的相关性方法——HeteSim。异质信息网络中的元图会存在奇数路径(odd path),也就是路径不对称及任意路径(arbitrary path)的问题。HeteSim通过约束路径搜索的方法将奇数路径转换为等长路径(even path),这样2个节点之间的相关性概率通过路径上的所有概率之和获得,从而能够计算在元图中无路径到达的2个节点的相关性。2015年,Cao等[7]提出了HCLP方法用于节点之间多种类型的链接关系的预测,给出了相似链接规则及不同类型节点间相关性度量方法(RM)以便计算不同类型节点间的存在概率。2016年,Huang等[8]建议使用元图/元结构(meta graph/meta structure)度量对象之间的相似程度。元图是一种有向无环图,可以描述2个对象之间的复杂关系。例如,文献[8]中指出KDD上的2篇论文具有相同类型的主题和相关的作者,这样就改变了原有元路径方法,必须是顺序结构的要求,并给出了基于元图的2个节点之间的相关性判断策略。
2014年,Tamersoy等[9]基于置信网络传播算法,通过未知文件与已有标签的文件的关系实现无标签文件恶意性的判断。2015年,Chen等[10]将同质信息网络用于恶意代码文件关系网络的构建。2018年,Fan等[11]将异质信息网络应用到恶意代码检测中,通过多种信息——压缩包、API、DLL及上报恶意文件所在的机器或位置等信息构建异质信息网络,获得其语义信息,通过不同的元图获得多种类型的特征描述,并通过主角度分析将特征向量映射到低维空间。该成果在Comodo反病毒产品中得到了应用。
本文将异质信息网络应用于恶意代码动态分析中,通过改进Metagraph2vec游走方式及网络嵌入方法,以获得样本特征描述,并将该特征用于恶意代码分类。实验结果证明,本文方法在仅可获得有限信息的情况下,可以大大提高恶意代码检测、分类的性能。
1 相关工作
目前,异质信息网络最新分析工具是元路径和元图,下面给出元路径和元图的详细说明。
1.1 元路径与元图
2011年,Sun等[4]提出了元路径的概念,用于异质信息网络中网络模式的特征描述。下面给出相关的符号定义。一个异质信息网络定义为
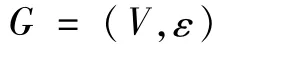
其网络模式为
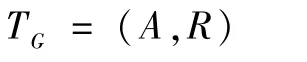
式中:A为有向图TG的顶点;R为有向图的边。则有对象类型的映射τ:V→A,链接的映射Φ:ε→R。

图1给出了P1和P2路径(S为元图结构)。可以通过统计2个对象节点x和y的路径数量、随机游走等方法计算对象节点的相似度s(x,y),从而构建节点的特征向量。元路径直接反映了对象节点之间的单一链接关系,如果对象间关系复杂,则需要处理成多条元路径。如图1中的有向图S所示,需要处理成P1和P2路径并做线性组合。但是,元路径这样的处理方法无法约束节点之间的共享关系,会造成共享信息丢失的问题。为此,Huang等[8]提出了元图的概念,来刻画节点间的信息共享关系。元图相关性度量的方法有元图计数、结构约束的子图扩展等。

图1 元路径与元图示例Fig.1 Examples of meta path and meta graph
1.2 Metapath2vec
2014年,Perozzi等[12]提出了DeepWalk方法用于社交网络的特征表示。Deep Walk使用随机游走(random walk)的方式在网络中查找当前节点的“上下文”节点,体现了节点与节点的共现关系。随机游走从局部一定程度上保持了节点与其相邻节点之间的连接性,即网络结构信息。然而对于异质信息网络来说,由于节点与连接节点的异质性的存在,异质信息网络嵌入最大的难点在于如何有效地在多种类型节点之间保存“节点上下文”的信息。
2017年,Yu等[13]提出了异质网络嵌入模型Metapath2vec。Metapath2vec是基于预先指定的元路径进行随机游走的。通过“有指导的”元路径游走,从而能够保持“节点上下文”的概念。
Metagraph2vec是在Metapath2vec的基础上提出来的。区别之处是:Metagraph2vec同时有2个随机游走的路线,如果初始给定的2个游走的起始点一致,Metagraph2vec退化为Metapath2vec。若元图M的基本模式如图2所示,则可以有PVP和PTP两个游走路径。

图2 元图M示例Fig.2 Examples of meta graph M
采用skip-gram建模,并分别做归一化得到节点的表示。在多元图上会得到同一个节点的不同表示,则需要通过权重的设置将这些节点表示融合起来。
2 恶意样本的异质信息网络构建
应用程序对系统资源访问、注册表访问、活跃的进程、被进程载入的DLL、进程属性等,都是其是否具有恶意性的判断标志。而这些信息仅仅依靠对样本的静态分析是很难获得的,有很多恶意的特征只有在执行过程中才会动态展现。
本文主要从动态分析角度提取样本的特征,并基于异质信息网络构建多种类型对象之间的关系,采用改进的随机游走策略获得特征向量并实现样本恶意性的检测。
2.1 恶意代码网络模式的定义
Fan等[11]刻画的恶意代码异质信息网络中的信息包括:上报样本所在的主机(M)、样本文件(F)、文件所属的压缩包(Z)、动态调用的API(A)、动态调用的DLL(D)。分析这些类别信息之间存在的关系是有利于恶意代码检测的。例如,在2个PE文件中,如果其具有相同的压缩包、有属于同一个DLL的API,那么这2个PE文件具有很高的概率同属于一个类别。图3刻画了以上述类别为顶点的恶意代码网络模式。
Fan等[11]研究中使用的数据集来源于Comodo反病毒平台,可以获得图3中全部类型的节点数据。但是,通常在研究中很难获取机器信息、压缩包信息等。为此,如何在有限信息的情况下获得更好的异质信息网络的描述是本文的研究重点。
在恶意代码动态分析中,API(A)、DLL(D)是最常能够获取到的信息。本文在构建异质信息网络时,不仅考虑了样本的内容——API、DLL,也考虑了样本文件(F)与样本之间的关系。图3中虚线框内部分为本文构建的异质信息网络。
根据图3中虚线框内的网络模式可以得到图4所示的4种元图结构。

图3 恶意代码网络模式Fig.3 Network schema of malicious code
图4所示的元图中,节点之间涉及到的关系如下:
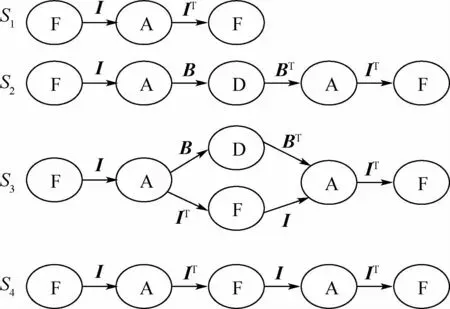
图4 四种元图Fig.4 Four types of meta graph
1)关系R1。被调用API是否属于同一个文件。用矩阵I描述,这里,sij∈{0,1,…,n}表示文件i是否包含了第j个API及包含的次数。
2)关系R2。被提取的API是否属于同一个DLL(如“WriteFile”与“CreateFileA”都属于“KERNEL32.DLL”)。用矩阵B描述,这里bij∈{0,1}描述第i个API是否在第j个DLL中。
2.2 改进的Metagraph2vec
从图4中给出的4个元图结构上可以看到,在可获得对象类别有限的情况下,通过对象类别之间构造多种链接结构会获得更多的信息。为了获得恶意代码异质信息网络的描述,本文采用了改进的随机游走策略。
根据元路径的对称性,在实际游走的过程中做了加速处理;限定的、多次随机游走,以获得尽可能多的上下文信息。将随机游走获取的节点上下文的信息作为CBOW 输入,提取节点对象的特征向量。
2.2.1 改进的随机游走策略
随机游走模型用来描述不稳定的移动。以图4中S1为例说明如何通过随机游走获取样本文件的环境信息(上下文信息)。为了在大量数据时游走算法依然保持灵敏,本文采取如下加速策略:
1)减少大量相关但帮助性不强的信息。采用TF-IDF将普遍出现的关系信息去除。
2)由于所有的元图都是在2个样本文件之间对称,仅仅取其中一半的节点进行随机游走,就可以刻画在这个元图下样本文件的周围环境信息。
关系R1中反映的是样本文件与其包含的API及API出现的次数。则可根据样本文件中所包含的API数量确定随机游走的概率。通过游走可获得F→A→F之间的关系。
图5为关系R1的矩阵I的信息示例。F1的API信息在第2行,先从行的角度,随机抽取API的信息,假设抽取到第2列数据,即A1,然后沿着第2列继续抽样,抽取到某一行,即得到Fi。这样的游走是在元图S1指导下的游走,获得F→A→F之间的关系。若从Fi出发继续游走,获取Aj信息,从Aj列游走获取Fk,…,这样的游走是在元图S4的指导下的游走。以上游走需要进行多次,以便获得更为丰富的信息。
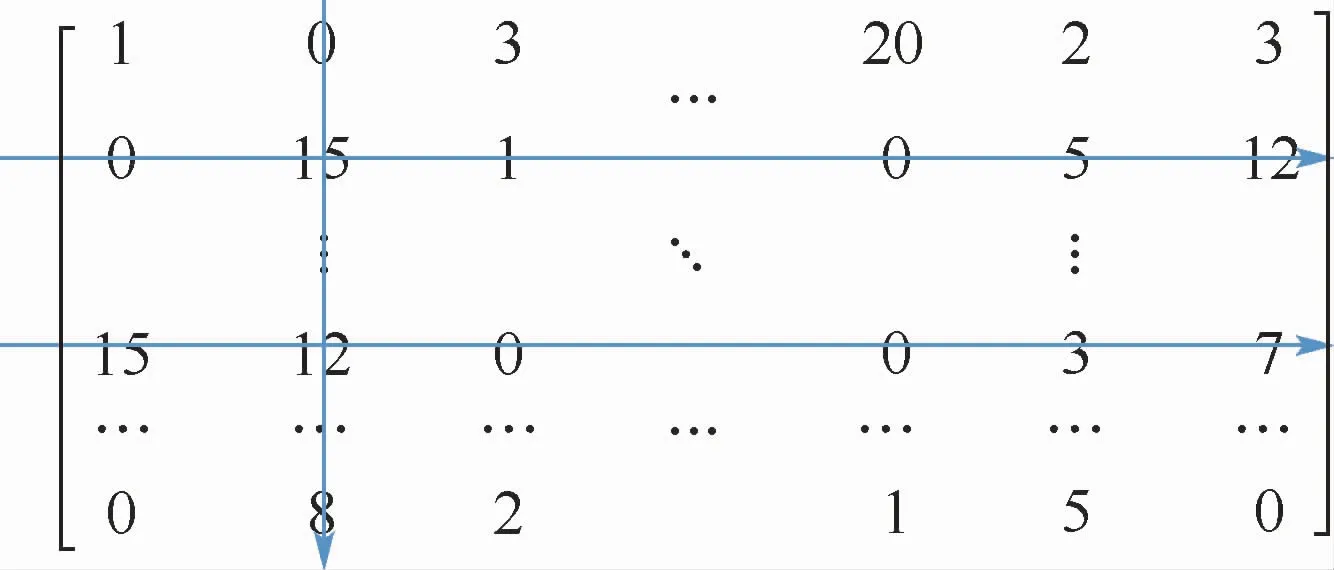
图5 关系R1的矩阵I示例Fig.5 Example of matrix I on relationship R1
游走获得的数据具有实际的物理含义,行表示的是每个样本文件中出现的API信息。根据Fi行游走得到的Ai信息,即得到样本文件中包含Ai(API)的次数,按照图4所示的4个元图,根据元图结构在关系R1、R2上随机游走得到Ai信息,即得到样本文件中包含Ai(API)的次数,根据Ai获得该API在其他样本文件中出现的次数。
按照图4所示的4个元图,根据元图结构在关系R1、R2上随机游走获得相对应的上下文信息,以此作为各个元图的词向量模型。
2.2.2 CBOW 模型与skip-gram模型
CBOW 模型与skip-gram模型都包含3层结构——输入层、投影层和输出层[14-15]。
skip-gram模型的训练方法是:中心词和周围某个词成对进行训练,中心词做输入、周围某个词做输出,描述中心词对周围词的推断。因此,可以将skip-gram输出词向量理解为对输入词典的降维。而CBOW 模型的训练,是将中心词周围多个词和中心词进行训练,周围多个词做输入,中心词做输出,描述通过周围词推测中心词的过程。
本文采用CBOW 模型进行词向量的网络嵌入,原因为:①图4所示的4个元图是从不同角度获得样本文件与周围API、DLL异构节点的分布关系。②使用CBOW 模型可以直接获得样本的特征。
3 实验与分析
本文实验采用了CNCERT实验室提供的数据集,该数据集共有10个家族,每个家族1 500个恶意样本,共15 000个恶意代码样本。由于动态分析需要实际执行每一个样本,非常耗时。在实验中随机选择3个家族,下面以某次随机选取的3个家族Allaple、Virut、Agent为例完成实验结果分析和评价。
实验中为了获得样本的动态信息,需要在Cuckoo沙箱内运行样本。Cuckoo沙箱是一款著名的开源沙箱系统,已被业界广泛使用。在Cuckoo沙箱内运行这3个家族4 500个样本,共获取3 948个有效样本的信息。
3.1 异质信息网络构建与信息表示
通过解析Cuckoo报告文件——“report.json”包含的字典中“apistats”子项,获得各个进程下的API统计信息;解析Cuckoo monitor中的hook脚本,获得API中DLL信息。本实验中共检测到365个API、27个DLL。
本文获得了图4所示的4张元图,主要描述样本文件、API及DLL的关系。关系R1的矩阵I为3 948×365大小的矩阵,行表示样本Fi对365个API的调用情况及调用的次数。根据API和DLL的对照,得到关系R2的矩阵B,矩阵B为365×27维。
根据2.2.1节,按照图4所示的元图做有指导的随机游走。在实验过程中,为了获得更为丰富的信息,这样的随机游走需要进行多次才能刻画出一个样本点周围的节点信息,获得的API分布才会尽可能接近样本的API实际分布,同时可以获得大量相关的样本文件作为辅助信息。
经过多次游走实验,最终确定30次随机游走可获得足够多的信息。因此,本文实验中规定任意的元图都将反复进行30次随机游走。以S1为例,经过30次随机游走获得文件节点F周围的信息,即获得30组“F-A-F”信息。将这些信息统计到一个字典上,这个字典包含所有的API、样本文件及DLL,长度为4 340(即3 948+365+27=4 340)维。经过30次随机游走,可以获得30个字典长的向量,其语义信息是:按照规定的元图找到当前样本与周围节点的关系。以此作为样本根据这个子图获得的训练结果。
在4个元图上,都可以通过上述随机游走方法获得对应的上下文信息,最终会获得4个相应的词向量模型。
经过随机游走后,获得的词向量高达4 340维,为了达到降维的目的,本文采用CBOW 模型对词向量降维,将4 340维字典嵌入(embedding)到128维中。
3.2 基于元图的分类结果分析
实验中,在每个元图指导下的随机游走获取的词向量经过降维后都可以独立用于样本分类。
1)单元图分类测试
实验代码由Python语言编写,采用kNN、RF(random forest)及线性SVM分类器分别完成分类实验。所有实验均采用了十重交叉验证。
经多次实验验证,当k=2时,kNN算法得到的分类结果最好,如表1所示。RF分类器中决策树的数目设置为10时,结果如表2所示。SVM分类器中kernel参数为“linear”(线性核)、惩罚参数C=1,分类结果如表3所示。

表2 单元图模型RF分类结果Table 2 Classification results of each meta graph model using RF

表3 单元图模型线性SVM 分类结果Table 3 Classification results of each meta graph model using linear SVM
表1~表3中,S1、S2、S3及S4分别为在图4中4个元图的指导下,根据改进的Metagraph2vec随机游走策略和CBOW 模型获得的特征向量的分类结果。
可以发现,根据S1元图游走获得的特征向量具有最好的分类准确率、最低的误报率和漏报率。这说明通过调用的API来判断样本之间的相似行为,具有非常好的鉴别能力。S2元图中在寻找2个样本的关联关系中增加了DLL信息,也可以获得较好的分类结果。
S4元图相比S1元图增加了通过API获取多样本之间关联性的游走。3种分类器的分类结果表明,这种游走会对样本之间的相似性判断产生干扰。
根据S3元图游走获取的特征向量具有最差的分类结果。S3元图在S2元图的基础上增加了S4元图的游走路线,影响了分类效果。
2)多元图融合的分类测试
为了综合应用这4个元图的分类结果,本文采用了投票的方法以便确定权重。在4个元图中分别对每个测试样本的词向量特征采用投票的方法确定样本属于哪一个家族,投票结果以百分比表示。通过主角度分析方法,确定各个元图分类结果的权重。
主角度α的计算方法为:假设有空间Yi和Yj,则其角度可以定义为

式中:θ=0,当且仅当Yi∩Yj≠0;θ=π/2,当且仅当Yi⊥Yj。
设θ1,θ2,…,θd为空间Yi和Yj主角度,则Yi和Yj的几何距离为

则权重αi为

根据式(3)可以计算4个元图模型投票结果的权重,结果如表4所示。根据表4的权重,融合4个元图最终可获得如表5所示的分类结果。
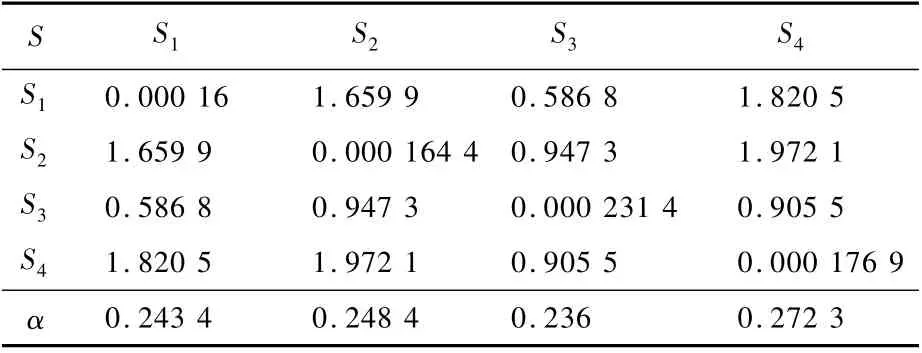
表4 元图权重结果Table 4 Weight values of meta graphs
表5 主角度融合分类结果Table 5 Classification results using principal angle hybrid method
表5中的分类准确率是S1、S2、S3及S4的融合结果(分类器的参数设置同单元图中的分类器参数设置)。相对表1~表3,表5的结果说明,融合的方法使得S3及S4元图的分类准确率得到了很大的提升。这说明,多元图相比单元图而言,可以对部分单元图的信息给与补充,可以通过α的物理意义得以解释。
3)特征有效性分析
动态分析受运行条件、触发条件的影响较大,而恶意代码为了不被检测到,很多都增加了抗检测技术。因此,在Cuckoo沙箱中获取的API、DLL可能会存在漏报、误报的情况。为了分析Cuckoo沙箱获取的信息对本文方法的影响,采用DynamoRIO工具对Cuckoo沙箱中可执行恶意样本再次分析,重新获取API、DLL信息,并将二者结果做对比、合并。
在3个家族3 948个有效样本中Cuckoo沙箱共获得365个API、27个DLL。DynamoRIO再次分析这些样本,共获得373个API、27个DLL及3 948个有效样本。将Cuckoo与DynamoRIO结果合并之后,获得3 948个有效样本、375个API及28个DLL。
根据合并后的样本文件、API、DLL信息构造异质网络,并再次完成单元图分类测试。表6为k=2时k NN算法得到的分类结果。

表6 合并2个沙箱结果后单元图模型k NN分类结果Table 6 Classification results of each meta graph model with two sandboxes results using k NN
可以发现,表6与表1的结果基本一致。同样地,采用RF与SVM 分类器可以得到与表2、表3相似的实验结果,在此不再赘述。
从对比实验结果可以看到,本文采用的单元图指导下的多次随机游走策略,可以降低单特征(如API、DLL)在异质信息网络中对分类结果的影响。
4)与其他文献结果的对比
Fan等[11]基于Comodo平台构建了12个元图,涉及到样本文件、API、DLL、压缩包、样本来源的机器(Machine)等信息,采用的是基本的随机游走策略及skip-gram方法描述样本特征。在该研究中,记录了单元图在Comodo公司提供的数据集上的分类准确率、召回率等,多元图融合后准确率可达0.983;但是对于单元图(元路径)的准确率只有0.75左右。将Fan等[11]的方法应用到本文数据集上,在S1元图的指导下,RF的分类准确率只有0.56,远远低于本文的单元图的分类准确率(见表1)。这说明本文采用的随机游走和CBOW 策略在单元图的分类效果是优于Fan等[11]的方法的。
由于Comodo公司的数据集并未公开,本文在CNCERT数据集上只能构造出有限种类的元图。在这种情况下,采取改进的Metagraph2vec随机游走策略与CBOW 相结合的方式获得单元图特征向量描述,并取得了较好的分类准确率,这说明本文为信息类型不够丰富的异质信息网络的信息表示及提高单元图分类准确率方面提供了一个可行的研究方法。
4 结 论
本文从动态分析的角度分析恶意样本,将异质信息网络应用到恶意代码动态分析中,为恶意代码动态分析提供了一种新的特征构造、描述方法。本文实现了:
1)通过在沙箱中运行样本,获得PE文件的动态访问信息,例如API、DLL等。通过构建异质信息网络的4个元图,获得样本文件与API、样本文件与DLL、API与DLL、样本文件与API及DLL之间的关系。
2)提出改进的随机游走策略,并结合CBOW模型获得元图的特征描述。本文方法相比Fan等[11]的方法提高了单元图分类准确率。
3)通过投票和主角度权重设置实现了多元图分类结果的融合。
实验中发现,多元图融合后的分类准确率提高程度没有达到Fan等[11]给出的融合效果。经分析,这是由于本文异质信息网络节点类型不够丰富造成的,这将是下一步研究中要解决的问题。
