基于函数型主成分聚类的失业人口研究
2022-03-06冉星
冉星
(重庆师范大学 数学科学学院,重庆 401331)
1 理论知识
1.1 函数曲线的拟合
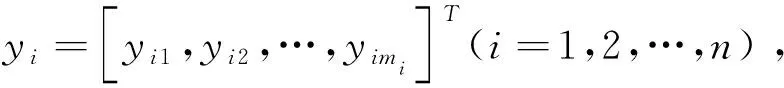
yij=xi(tij)+εij,
(1)


(2)
其中ci=(ci1,ci2,…ciK)T为待估的系数向量,K为选择基函数的个数。令

X(t)=CΦ.
(3)
下一步就是通过基函数展开去估计系数向量,本文利用最小二乘法光滑模型来求解待估的系数向量。则估计的目标函数为
(4)
解出待估系数向量,从而就可以求得待估曲线xi(t)。
等高线图可以反映各因素交互作用对响应值的影响。圆形表示因素间交互作用不显著,椭圆表示因素间交互作用显著。由图2可知,漂烫温度与漂烫时间交互作用较显著,当漂烫时间大于4 min时,标准化得分逐渐降低。漂烫时间越长,温度越高,导致样品组织结构破坏严重,品质变差,影响最终标准化得分[20]。
1.2 函数型数据的主成分分析
函数型主成分分析[7]的思想与多元统计中主成分分析的思想类似,多元统计中主成分分析的实质就是求解协方差矩阵的特征值与特征向量问题,而在函数型主成分分析中,就是求解协方差函数的特征函数问题,即求解如下极大值的优化问题:
(5)

(6)
具体的求解过程就是求解特征方程
(7)
其中λ是GX(s,t)的特征值,φ(s)是与特征值λ相对应的特征函数。
常用的估计方法有离散化和基底函数展开法,详细参见[8]。下面利用基底函数展开法来求解特征方程。设特征函数φ(s)由相同的基底Φ(t)进行拟合,则特征函数φ(s)的基函数展开式为
(8)
其中b=(b1,b2,…,bk)T为待估参数向量,由此(7)式的左边为
(9)

N-1ΦT(s)CTCWb=λΦT(s)b.
(10)
由于该方程对所有s都成立,故N-1CTCWb=λb,求解该矩阵方程的特征值问题可得特征函数φ(s)。通过下式可得主成分得分
(11)
1.3 函数型数据的加权K-means聚类
通过函数的主成分分析降维得到各函数曲线的主成分得分,现根据累计方差贡献率(CPV)大于等于95%的原则,提取各函数曲线的前几个主成分得分代替原始的函数型数据进行加权的k-means聚类。定义加权k-means聚类的相似性度量如下:
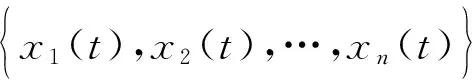
(12)
为函数曲线xi(t)和xj(t)之间加权的主成分得分距离,其中q为距离参数。
2 相关应用
本研究选择我国31个省、市、自治区2001~2019年的失业人口数据作为研究对象。数据来源于国家统计局网站。鉴于上述的理论知识,将我国31个省、市、自治区2001~2019年的失业人口进行函数型数据的加权K-means聚类,具体流程如图1。
2.1 曲线的拟合及相关的描述性分析
用4次B样条基函数拟合并通过MATLAB编程[9-10]绘制了我国31个省、市、自治区2001~2019年的失业人口的标准差函数图和均值函数图如图2、3所示。

图1 流程图

图2 标准差函数曲线
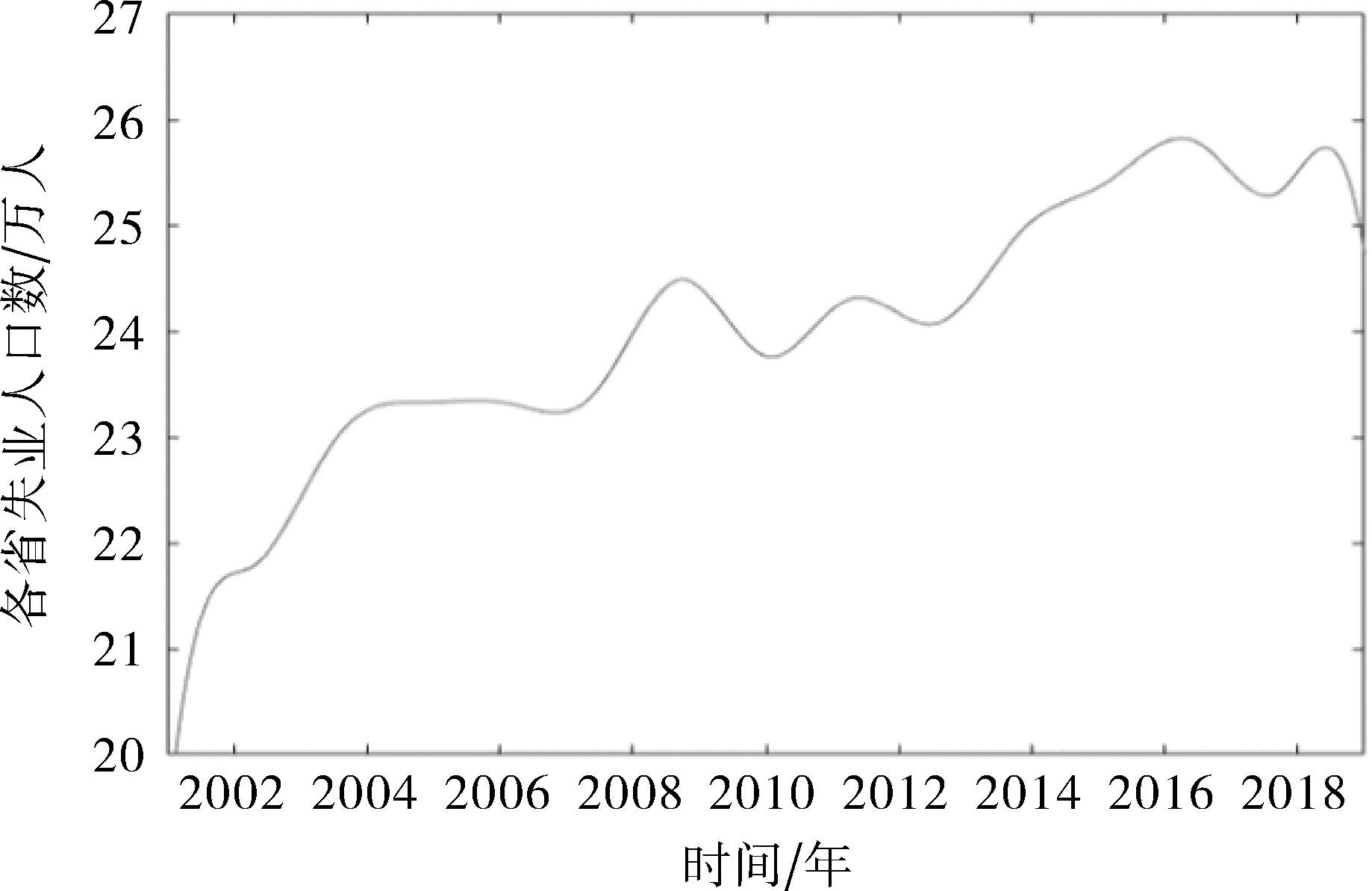
图3 均值函数曲线
由图2标准差函数曲线可以发现我国各个省的失业人口数前两年的变化差别大,随后呈缩小拉大交替的趋势,但最后从整体上看各省份失业人口差距逐渐缩小,一定程度上可以反映出我国近年来各个省、市、自治区的发展差距在逐渐缩小。由图3可以看出我国的平均失业人口数自2001年以来一直处于不平稳的增加趋势,特别是2008年至2010年突然急剧上升之后又急剧下降, 出现这种原因可能是受全球金融危机的影响,导致2008年失业人口急剧上升,2009年金融危机之后失业人口数开始急剧下降,但我国整体平均失业人口数上呈现缓慢增长趋势。
对我国31个省、市、自治区的失业人数的函数曲线进行函数型主成分分析(FPCA),根据累计方差贡献率大于等于95%的原则,提取了前两个主成分,贡献率分别为91.76%和5.16%,可以代表曲线的绝大部分信息。利用31个省的第一和第二主成分得分,画出了各省失业人口的主成分得分图(如图4所示)。
根据图4大致可以将31个省分为四类:第一类是辽宁省、湖北省、江苏省;第二类是四川省、河南省、河北省;第三类是西藏自治区、海南省、青海省、宁夏回族自治区、北京市、甘肃省、新疆维吾尔自治区、重庆市、上海市、贵州省、吉林省、福建省、广西壮族自治区;剩余的省份为第四类。以上的分类只是根据图4主观进行的大致分类,除第一类比较靠近第一主成分以及第三类相对比较集中外,第四类与第三类、二类、一类之间的界限也不是特别的明显,为了更加客观的对我国各省失业人口差异进行分类,运用加权主成分得分的k-means聚类对我国失业人口数进行定量的分类。

图4 各省失业人口得分图
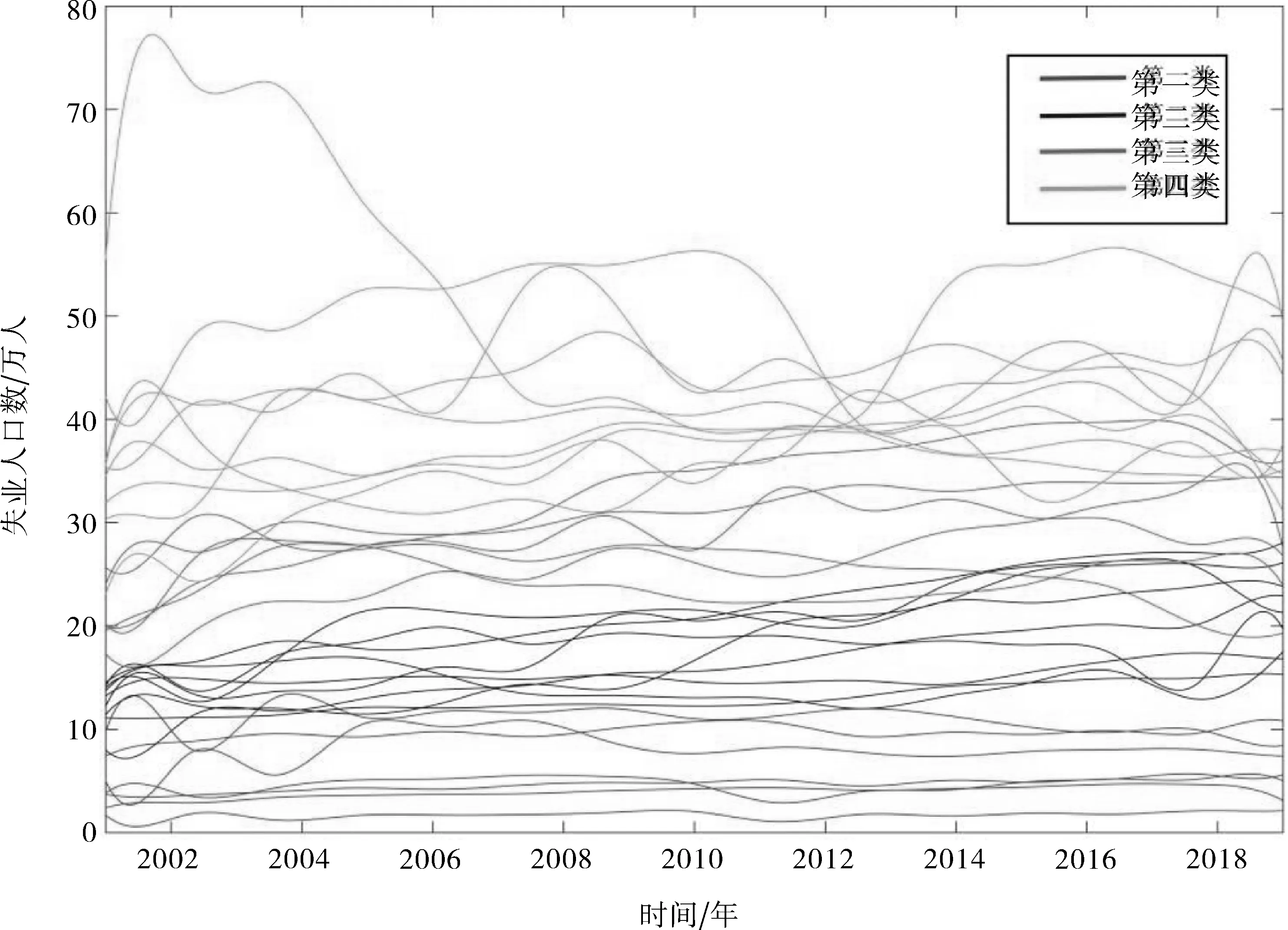
图5 聚类效果图
2.2 加权主成分得分的K-means聚类
利用上述前两个主成分得分代表原始数据,对我国31个省、市、自治区进行加权主成分得分的k-means聚类,将(12)式作为距离的相似性度量,其中距离参数q取2,其聚类的结果如表1所示,相应的分类效果图如图5所示。

表1 函数型数据聚类结果分类表
3 结果分析
从表1可知,北京、海南、西藏、甘肃、青海、宁夏、新疆这7个省份为第一梯度,失业人数最低,北京作为我国的超一线城市,虽然人口基数大但大多都是年轻人,相对于人口年龄结构老年化的省份,失业人口比较低。海南作为我国的经济特区,以其天然的自然地理优势有着丰富的旅游资源,随着旅游资源带动的其他服务业等,不仅促进了海南的经济发展,同时也提供了更多的就业机会。而其余失业人数较小的省份全部来自西部和西北地区,由于中央政府近年来实施的一系列西部大开发的政策,使得西部地区的产业资源优势得以进一步的提升,从而对劳动力的需求量也明显增加。由表1可知失业人数在第二梯度的省份大多在华北地区和西南地区,西南地区同样得益于西部大开发战略,在产业升级、结构转型的发展背景下,有效解决了城镇下岗失业人员再就业问题。其中重庆处在“一带一路”和长江经济带的联结点上,其自身的“区位优势”、生态优势、“产业优势”以及“体制优势”都尤为突出,因此其对劳动力的需求量自然较大。
由表1可知失业人数最多的省份在第四梯度,其中辽宁省和黑龙江省位于东北部地区,作为老工业基底的代表,随着产业结构的调整和企业技术革新的步伐加快,使得辽宁省和黑龙江省与其他省份相比失业人数尤为突出,主要可以从两个方面进行解释:第一,随着产业结构的调整,东北地区一些老工业基地在技能结构和劳动力年龄结构等方面与市场需求不相匹配,从而导致劳动力达不到市场的需求进而导致失业人口数增加;第二,为了顺应时代的发展,加快企业技术的革新进程,部分企业会引进一些先进的设备、机器、技术等,而这些硬件设施的提升在短时间内会对就业产生“挤出”效应,进而导致失业人数增加。除了河南省和山东省外,其余7省的人口老龄化均进入全国前12名,一般老龄化严重的地区,经济发展活力相对不会太高,相应能提供的就业岗位就减少,就业竞争压力大,失业机率相对较高。
综合以上分析,该分类结果基本符合我国各省的失业人口之间的差异情况。
4 总结和建议
在经济新常态的背景下,紧密关注我国失业人口数具有重要意义,本文利用加权函数型主成分的聚类方法对我国失业人口的差异进行聚类,并结合相关政策和各省产业发展的优势等对我国失业人口数的差异进行原因分析。一方面,有助于国家针对各省失业人口的数量进行产业结构的调整,出台一系列的相关战略政策提供科学的依据;另一方面,由于我国长期处于经济发展不平衡的状态,我国各省失业人数的差异一定程度上反应了我国经济发展的不协调,因此有利于国家在促进经济发展的同时,考虑到我国失业人口的差异,适当增加就业岗位;实证结果表明我国劳动力失业人口的动态变化特性存在一定的区域异质性,为了平衡我国不同地区失业人口之间的差异,鉴于前面的分析,提出以下两点建议:
1)促进我国经济健康平稳增长,缩短不同地区经济增长的差距。经济发展是第一要务,是解决失业问题的根本途径。缩短我国不同地区经济增长的差距,政府应该提出相应的宏观经济政策,调整经济增长方式,增加就业容量。
2)大力推动私营、中小型企业的发展。虽然国企和大型企业是国家经济发展的重要基石,但是作为吸纳就业的中小型、私营企业才是提供就业岗位的中流砥柱。国家应该加强对中小、私营企业的帮助,避免选择性失业的同时鼓励大学生创业,为劳动力市场提供更多的就业岗位。
