基于SVM的煤矿岩巷爆破参数智能判断及优化
2022-03-04翟中华魏泽洋覃逸峰黄河念王镜宇黄承民张斌弛张子健于佳龙
翟中华,魏泽洋,覃逸峰,黄河念,王镜宇,黄承民,张斌弛,张子健,于佳龙
(中国矿业大学(北京)力学与建筑工程学院,北京市海淀区,100083)
0 引言
岩石巷道爆破掘进是煤巷建设中广泛使用的一种掘进方式,但由于影响爆破设计的因素众多,且存在众多可定性描述但难以定量分析的影响因素,尤其是由于岩性的多变使得爆破参数需要实时调整和变化,而在实际工程中参数的实时调整对现场技术人员的工程经验要求较高。完全由公式计算出的爆破参数往往不能满足爆破需要。随着计算机技术的发展,将机器学习引入爆破研究中具有重要意义。唐跃[1]基于交叉验证理论通过支持向量机模型参数寻优中,得到最优爆破块度预测模型;马鑫民等[2]基于综合分析法确定影响煤矿岩巷爆破效果关键指标,提出基于GA-SVM融合技术的爆破效果预测模型,实现爆破效果的合理预测;张钦礼等[3]设计了9组爆破参数正交试验,利用RBF神经网络模型对试验结果进行预测,使用爆破综合期望指数得到最优爆破参数;岳中文等[4]建立PSO-SVM模型进行关键参数寻优,验证了模型在不同核函数上的预测准确率,结果表明RBF核函数的预测效果最佳;崔年生等[5]采用进化径向基神经网络方法优化爆破参数,得出了一套适用于多铜矿岩台阶爆破的最优爆破参数,取得了良好的爆破效果;XU Shida等[6]提出了一种结合主成分分析(PCA)和支持向量机(SVM)模型来预测爆破振动,结果证明了PCA-SVM模型在爆破估计方面的优越性;LIU Kaiyun等[7]将遗传算法(GA)与改进的支持向量回归(ISVR)算法耦合对爆破参数进行优化,根据应用结果得到ISVR模型可行和可靠;岳中文等[8]利用主成分分析(PCA)提取主成分作为模型的输入变量,结合遗传算法(GA)获得支持向量机(SVM)的最优超参数,建立了露天矿爆破振动速度预测模型,此模型具有更高的精确度;张耿城等[9]通过随机森林算法(Random Forest)选择出对于爆破效果影响更大的相关参数,创立了基于支持向量机的露天矿爆破效果预测模型,预测结果比BP神经网络建立的模型更精确、误差更小;HASANIPANAH M[10]等建立了一种支持向量机(SVM)模型用于预测爆破作业中的峰值粒子速度(PPV),并比较了SVM和经验方程的结果。
我国大多数煤矿地质条件复杂,爆破影响参数多且难以准确记录,这导致数据收集难度很大。神经网络算法在面对大样本数据时能取得更好的效果,但对小样本的数据预测容易过拟合。支持向量机(Support Vector Machine,简称 SVM)具有很强的非线性建模能力和小样本推广能力强等优点,针对小样本、非线性及高维问题时表现出很多独特的优势,在优化爆破参数方面更加适用。笔者采用误差分析法选取重要变量作为模型输入参数,解决了爆破参数选择问题。使用SVM在解决非线性分布时,需要通过核函数对其进行升维,但是对于这一过程,不同的核函数选型及超参数选择对数据模型影响很大,对此笔者采用了网格搜索和麻雀搜索优化算法两种超参数寻优方法寻找最优超参数,以此得出一个可以根据现场情况智能得出最佳爆破参数的预测模型。
1 SVM算法理论
SVM是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
对于一个样本集F(xi,yi),i=1,2,…,n,(其中x作为已知参数是一个多维向量称为特征,y作为输出变量,也称为标签),存在一个空间超平面(ω·x)+b=0可以将不同标签的数据分开,求解这个超平面即是最终目的。经过数学演算其可以变化为一个最小值问题:
再引入拉格朗日乘数法即可对其求解。但在实际上很多数据往往是线性不可分的,需要对其使用核函数进行升维以找到一个超平面。根据周志华[11]的研究,如果特征的数量大到和样本数量差不多,则选用线性核的SVM;如果特征的数量小,样本的数量正常,则选用高斯核函数;如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。实际已有数据中爆破参数特征数量远小于样本数,由此可以选出高斯核函数(RBF)作为实验用核函数。
2 SVM超参数优化方案
基于高斯核函数对于核函数参数选择十分敏感,为了取得适应度更佳的模型,需要对其参数(c,gamma)进行优化调整。c为惩罚系数,即为对于误差的宽容度;gamma为影响参数,定义了单个样本对于整个超平面的影响大小。笔者采用了目前主流的两种参数优化方式:网格搜索、群智能优化算法。
2.1 网格搜索(Grid Search)
网格搜索方法即将待求参数视作高斯坐标轴,设定起点,终点,布局,以此来形成一张“网”,再以网格的数值代入核函数中,用其建立模型并计算出预测准确率,根据其得出的准确率结果。由准确率结果即可直观得出最优解数值,同时还可以对结果较为优异的区域进行放缩,以此来进一步提高准确率,但这一方法运用于数据量大的模型中往往需要较大的运算能力,并且部分计算机编程语言不能发挥出计算机全部的计算能力,会导致计算机运算速度过慢。所以选择适合的步距和范围,对于搜索区域进行一定次数的缩放可以减少运算时间,并且爆破数据量较小,这使得网格搜索十分适用于此类问题的SVM调参。
2.2 麻雀搜索优化算法(Sparrow Search Algorithm)
不同的群智能优化算法基本上可分为两部分:使用随机算子对空间进行粗略的全局随机搜索;根据随机搜索的结果进行局部搜索找到全局最优解。这类寻优算法相较网格搜索运算点少,运算量低,只需要使用低于其数倍的时间就能得出相差不多甚至更佳的解。但其也具有随机性、结果不稳定的缺点。麻雀搜索优化算法是由薛建凯[12]在2020年提出的一种新型群智能优化算法,主要是受麻雀的觅食行为和反捕食行为的启发而提出的。使用数学模型来模拟麻雀种群在自然界中捕猎的行为,通过模拟麻雀的特性来捕捉全局最优解,寻优在这一过程可被看作麻雀通过叫声引导群体到达食物较多的地区,规避敌害,以此来找到食物最多的地区即全局最优解。
2.3 超参数优化过程
将优化算法与SVM相结合,对c和gamma参数调优,以得出最佳的超参数数值,两种超参数优化算法流程如图1所示。
麻雀搜索优化算法主要步骤如下:
(1)收集数据对样本数据进行预处理,进行归一化避免样本间的欧式距离度量不准,作为输入集;
(2)初始化种群,迭代次数,初始化发现者和加入者数量比例;
(3)计算初始种群适应度,并进行排序;
(4)更新发现者、加入者以及意识到危险的麻雀位置,计算适应度,获得当前最优值;
(5)如果未达到目标迭代次数则重复;
(6)达到则输出c和gamma。

图1 SVM超参数优选过程
网格搜索步骤如下:
(1)收集数据对样本数据进行预处理,进行归一化避免样本间的欧式距离度量不准,作为输入集;
(2)设置预估搜索范围、步距,以此来形成一张“网”,再以网格的数值代入核函数中;
(3)计算出每一个点位的准确率,从中选出准确率最高的点;
(4)判断最高准确率是否能达到要求,如果不能达到要求则回到步骤(2),改变预估搜索范围和步距。最高准确率达到要求则输出c和gamma。
3 煤矿爆破炸药单耗SVM预测模型建立
3.1 数据收集与前处理
为了保证煤矿爆破数据的丰富性,通过现场测试、问卷调查、文献查阅等方式共收集到144个爆破数据。为了提高数据的有效性,去除了存有异常值和缺失值的数据样本,最终得到可用于模型训练和测试的127个样本,见表1。
为了避免原始样本数量级之间较大的差异,还需对学习样本中的数据集进行归一化处理,否则将导致样本间的欧式距离不准,使得数值大的特征占主导作用。归一化的函数表达式为:
(3)
式中:y——数据归一化的结果;
xi——待处理的样本数据;
xmin——样本数据的最小值;
xmax——样本数据的最大值。
将炸药单耗按数值大小分为15类,每一类所占区间为0.2 kg/m3。通过数据归一化将样本数据的数量级和量纲单位进一步处理,其中掏槽方式中0为楔形掏槽,0.5为复合掏槽,1为直眼掏槽,得到经过归一化后的127组数据,见表2。

表1 煤矿爆破数据原数据集
表2 煤矿爆破数据经整理及归一化后数据集
3.2 影响爆破炸药单耗重要因素选取
影响爆破炸药单耗因素有很多,如巷道高、巷道宽、岩石普氏系数、炮眼深度、炮眼数、掏槽方式等。输入模型的影响因素并非越多越好,部分参数与目标变量相关性弱,或变化率过大,对于预测来说不仅会使数据加入过多的噪点,影响其学习精度,还会导致模型复杂化,造成模型过拟合。选取合适的输入参数能在简化模型的基础上提高预测准确率。随机森林算法里的误差分析法可以很好地解决参数难以选择的问题,误差分析法通过对每一个预测变量随机赋值,如果该预测变量更为重要,那么其值被随机替换后模型预测的误差会增大,该值越大表示该变量的重要性越大,使用误差分析法得到的炸药单耗影响变量的重要性排序,如图2所示。
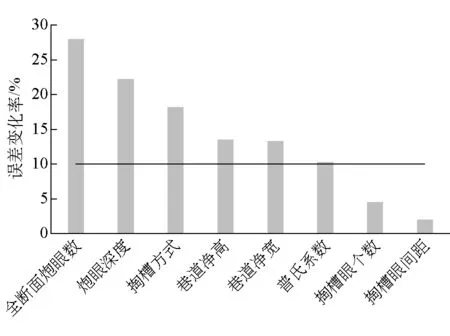
图2 各变量重要性排序
根据图2给出的变量重要性,选取导致误差增大10%以上的变量作为模型的最终输入变量。最终选取的输入变量为:巷道净宽、巷道净高、普氏系数、炮眼深度、全断面炮眼数、掏槽方式,以爆破炸药单耗作为输出参数。
3.3 建立基于SVM的爆破炸药单耗预测模型
模型采用Python作为编程语言,并调取Scikit-Learn库作为SVM的运行基础,选取高斯核函数进行预测,使用网络搜索和SSA对超参数进行调优。以通过误差分析法确定的6个指标作为模型输入参数,爆破炸药单耗作为输出参数,分别带入经过SSA优化算法和网格搜索得到的超参数c和gamma,建立起基于SVM的煤矿巷道爆破参数预测优化模型。然后使用训练集对模型进行训练,最后将测试集输入模型中对模型预测性能进行检验。
3.4 SVM模型预测结果对比
基于两种不同的算法对参数进行优化得出参数后对训练集进行测试,原数据集共128组,按照3∶1的比率分为测试机和训练集。两种参数优化方法在测试集上得到的预测结果如图3、图4所示。不同算法预测结果对比见表3。由表3可知,两种方法找到的最优参数c和gamma有着较大的区别,但最终在训练集上的预测效果只相差1个百分点,在测试集上SSA优化算法比网格搜索预测效果更好。
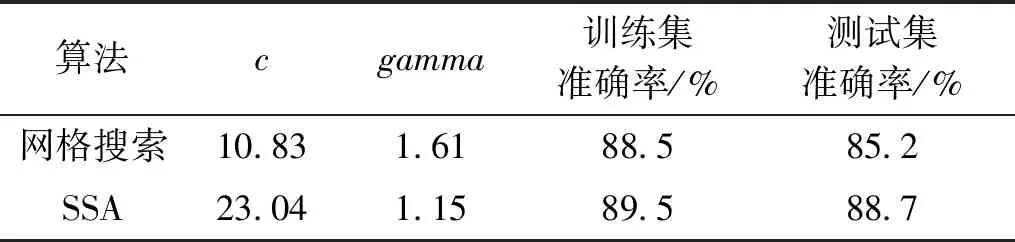
表3 不同算法预测结果对比
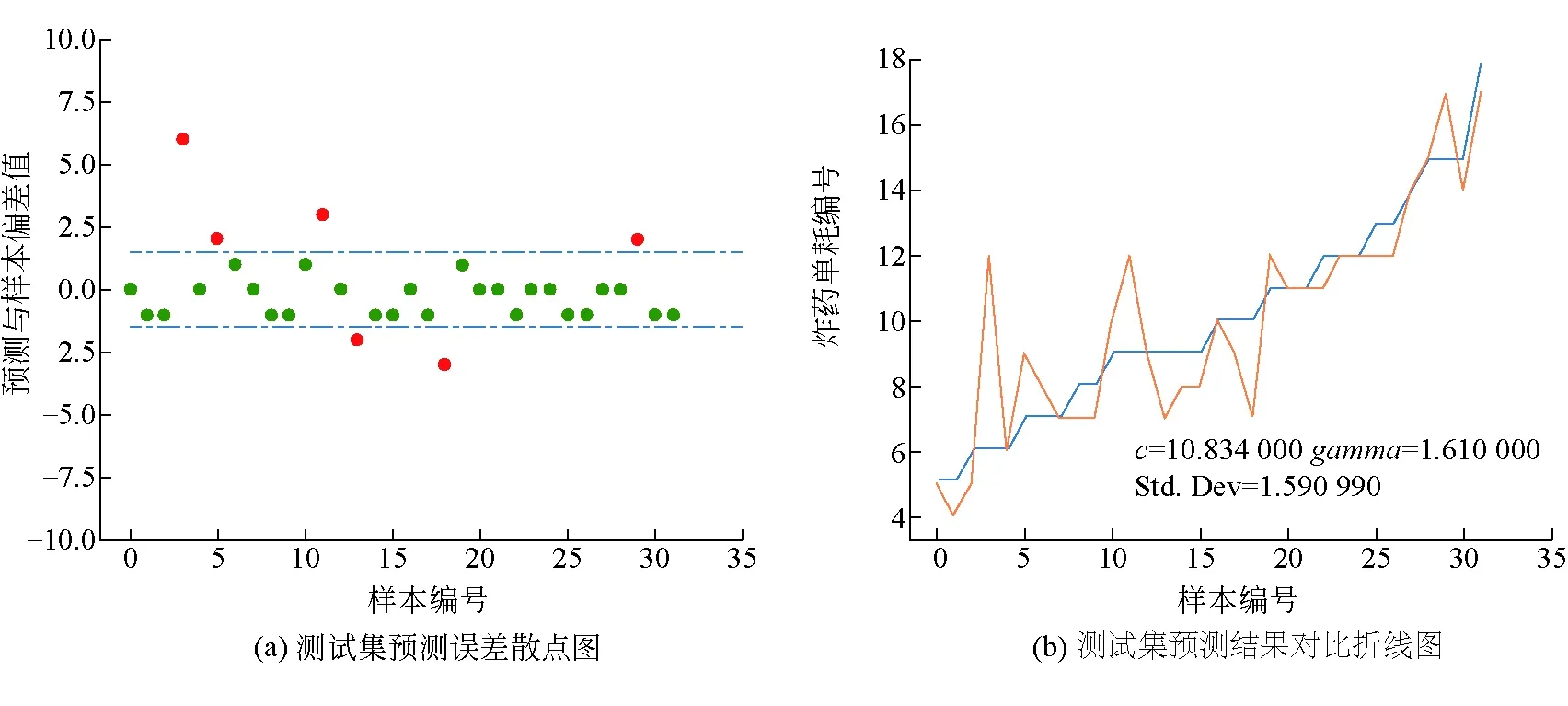
注:Std.Dev为标准差 ;散点图中横线所包围的数据点为偏差小于1的数据点,即测装药量偏差小于0.2 kg/m3图3 基于网格搜索优化得出的模型预测结果
4 工程应用
为了测试基于SVM的煤矿岩巷爆破参数预测模型的效果,以安徽省淮北煤矿作为工程背景,现场收集了12组爆破数据进行上述技术的应用实践检验,见表4。
选择SSA优化算法得到的最优超参数c和gamma,利用上述确定的6个输入参数建立SVM预测模型,使用上述的训练集对模型进行训练,然后将实际工程中得到的12组爆破数据输入到该预测模型中对炸药单耗进行预测,得到的预测结果如图5所示。由图5可知,在实际工程得到了12组数据,SVM模型得到的炸药单耗预测值与实际值接近,模型准确率为92.3%。基于SVM的预测模型在经过SSA优化算法调参后在预测爆破参数方面表现出很好的效果。

图4 基于SSA优化算法得出的模型预测结果
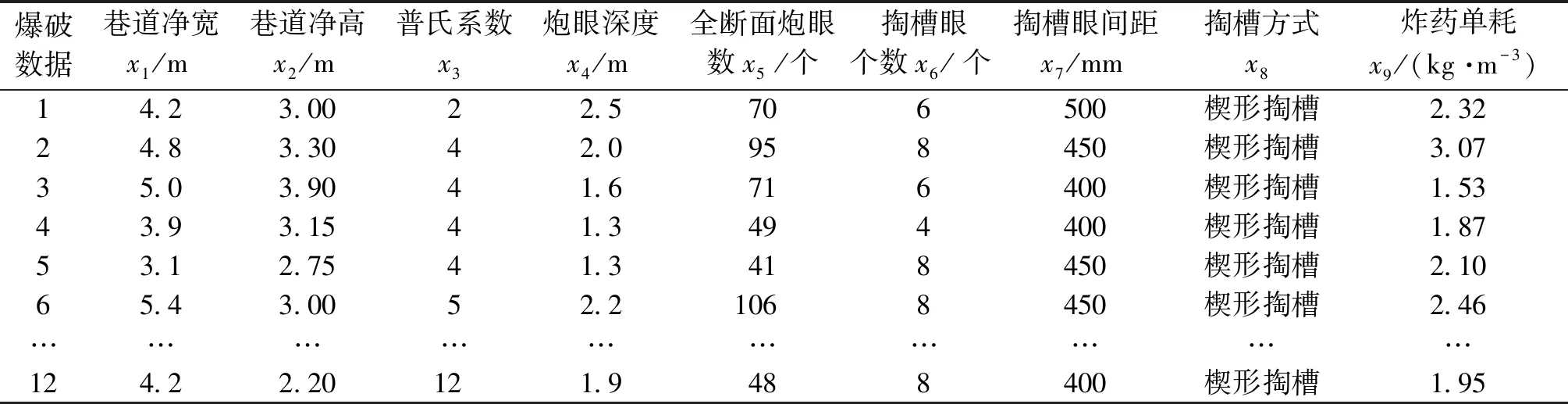
表4 实际工程爆破数据集
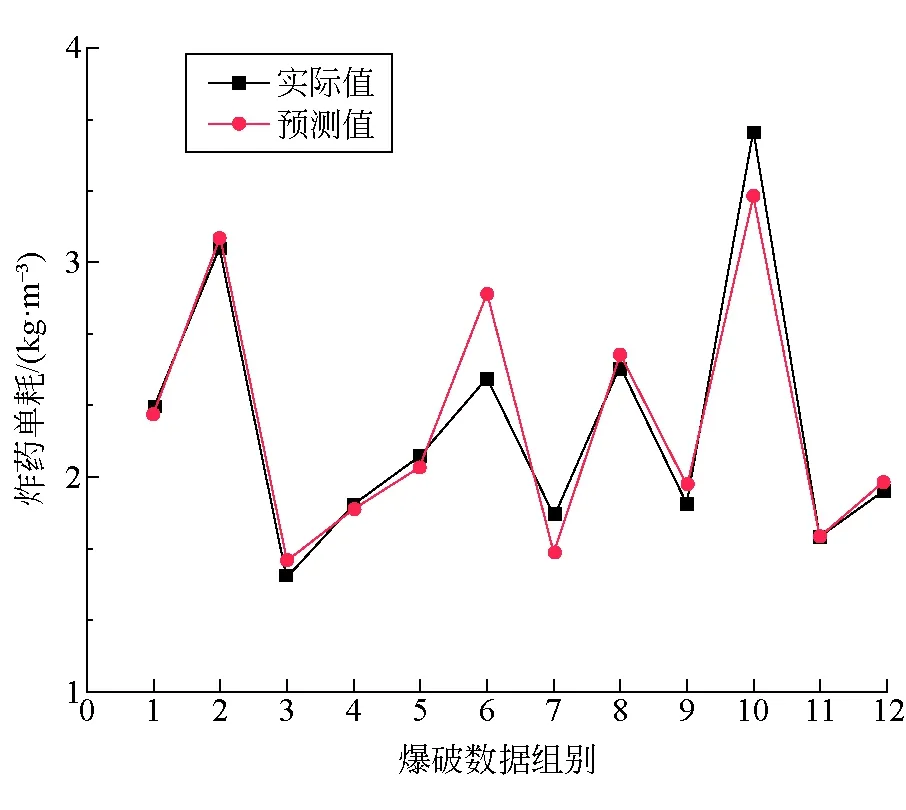
图5 SVM工程预测结果
5 结语
(1)以误差分析法对影响煤矿巷道爆破炸药单耗的多个因素进行重要性排序,最终以巷道净宽 、巷道净高、普氏系数、 炮眼深度 、断面炮眼个数和掏槽眼布置方式6个指标作为模型输入参数,爆破炸药单耗作为输出参数,建立起基于SVM的煤矿巷道爆破参数预测优化模型。
(2)SVM模型对煤矿巷道爆破炸药单耗预测适应性良好。通过 SSA优化算法得到的核函数参数最优组合分别为c=23.04,gamma=1.15,通过网格搜索得到的核函数参数最优组合分别为c=10.83,gamma=1.61。比较两种参数优化方法得到的预测结果,结果显示使用SSA群优化算法优化得到的参数在预测模型中取得更好的效果。将该模型应用于实际工程中,预测准确率达到92.3%,预测结果与实际工程相近,对于其他爆破参数或工程具有一定的参考意义。
