非均权-动态规划地址匹配算法设计与实现
2022-03-03徐嘉康王柳静张贵军
徐嘉康,张 晨,王柳静,张贵军
(浙江工业大学 信息工程学院,杭州 310023)
1 引 言
地址匹配是将待匹配的地址文本与对应的地理坐标及标准地址进行匹配的过程,是地理编码的核心部分,也是现代物流配送[1]、交通运输[2,3]中的重要环节之一.标准地址模型、搜索文本等诸多因素均会对中文地址匹配结果产生影响,使得此类问题的求解更为困难.随着信息技术与计算机技术的快速发展,各行各业不同类型的地址不断产生,当前大多数中文地址匹配方法都是通过非结构化、非空间化、非标准化且缺乏空间坐标信息的地址直接匹配地理编码数据库,往往需要大量的分词训练且造成算法对特定格式地址库的依赖,导致算法在匹配信息不完整的情况下得到的结果不精确.因此,在重新构建地址匹配模型的基础上进行地址匹配算法的再设计有着重要的现实意义.
随着地理信息技术、计算机技术的发展,文本匹配技术越来越受到国内外学者的重视,并进行了许多富有意义的研究工作.Wang Xiaoli使用了基于文本序列距离的K最近邻方法获得最相似匹配序列[4];Manish Patil使用编辑距离作为衡量标准提出了一种位置限制对齐方法[5],提高了相似文本匹配效率.Qin Tian针对较为复杂的中文地址字符匹配问题,在优化地址建模、地址标准化的基础上,提出了一种中文地址分词匹配方法[6],在中文地址匹配中取得了良好的效果;Waterman提出的基于动态规划思想的局部序列匹配方法在生物信息领域中得到了广泛应用[7],提高了序列匹配的精度与效率;Amihood Amir提出一种模板近似匹配方法,有效减少了匹配项中出现局部错误的情况[8];程昌秀建立了存储标准地址数据集的标准地址库和自定义的地址匹配规则库,提出一种基于规则的模糊中文地址编码方法[9],提高了模糊地址文本的匹配成功率;王斌设计了一种支持移动编辑距离的索引结构,借助字母出现的频率权重,提出一种优化字母查询算法[10],通过增强索引的过滤能力,提高了地址文本查询效率.
借鉴生物信息学序列比对思想,设计动态地址匹配模型与非均权算子,不依赖于任何特定格式的地址库,也无需对标准库进行标注,避免大量分词训练过程,从而使得算法在匹配信息不完整的情况下也可以得到较为精确的匹配结果.在杭州市标准地址数据上(1∶30万)进行了算法验证,实验结果证明了算法的有效性.
2 中文地址匹配模型
中文地址匹配模型可以表示为:输入地址字符串S={s0s1s2s3…sm},m为S的长度;地址库字符串T={t0t1t2t3…tn},n为T的长度.其中sm表示输入地址字符串S第m+1位的字符,tn同理.S与T匹配评分得到打分矩阵C,cij表示字符si与字符tj的相似性得分.本文假设输入地址和地址库各地址相互独立,在满足约束条件的情况下,最大化匹配得分.匹配问题的数学模型可以用公式(1)描述:
(1)
其中R表示根据单字在地址库中的重要性差异生成的权重矩阵,R(si,tj)表示字符si与tj的权重匹配得分;Wk表示输入地址字符串上k个空位的惩罚分,Wl则表示地址库字符串l个空位的惩罚分.
3 模型求解
Smith-waterman算法是生物信息领域的重要算法[7],其优势在于可以在给定的打分评估准则下找出两个序列的最优比对块,使得局部匹配成为可能.本文改进Smith-waterman算法,在动态打分匹配的基础上引入空位罚分策略,通过地址单字检索求权算法(Word Frequency-InverseTable Frequency,WF-ITF)构建了置换矩阵,可以有效解决中文地址匹配问题.
3.1 空位罚分策略
动态规划算法使用的矩阵可以用公式(2)表示,其中cij为文本匹配过程中对应位置字符的比对得分.本方法进行局部匹配时需要进行回溯最高分的操作,因此将初始打分矩阵的第1行和第1列都置0.
两文本之间一般存在着错位相似的情况,空位的引入能够很好的解决错位匹配的问题.但是没有代价的空位也会导致算法倾向于大量使用空位来匹配两文本中的字符,造成过
(2)
度匹配的现象出现.因此空位模型会对文本匹配产生巨大影响.这里认为连续的长空位比分散的空位更可靠.使用空位罚分避免算法过度匹配文本,用公式(3)表示:
Wk=u(k-1)+v
(3)
其中Wk是空位的惩罚得分;k表示当前匹配添加的空位数,k为1时就只是起始空位罚分v,当k大于1时,会由常系数u给出额外的连续空位惩罚.
3.2 基于WF-ITF置换矩阵的字符权重
字符对匹配或错配的分数用置换矩阵表示,若匹配则加分,错配则扣分,具体见公式(4):
(4)
其中P表示在匹配时的得分,为正常数;N表示在错配时的得分,为负常数.
常值置换矩阵在所有的字符匹配情况下给出的分值没有差别,考虑到不同的字符在地址库中的重要性差异,引入字符出现频率来改进分值.单纯的字符出现频率无法很好地反应字符的重要性,因此使用TF-IDF方法来优化字符权重[11].TF-IDF是由Jones提出的一种统计方法,用以评估单一字词对于一个文件集或一个语料库中的其中一份文件的重要程度.字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比降低,用公式(5)、公式(6)表示:
(5)
(6)
其中m代表指定词语在单一文本中出现的次数;M代表文本中所有词语出现总数;N为文本库中文本总数;n为含有指定词语的文本数量.归一化后的传统TF-IDF公式如公式(7)所示:
(7)
其中Wij代表指定词语i在文本j中的重要程度权重;tfij表示词语i在文本j中的出现频率;N代表本文总数;ni代表存在词语i的文本数量.
由于地址的长度相对于通常文件来说短的多.传统的归一化TF-IDF算法无法适用于本文的单字权重计算,因此需要将TF-IDF方法进行改造[12],算法具体步骤如算法1所示.
算法1中N表示地址库中地址总条数,perWordRow表示地址库中出现单字w的条数,perWordSum表示单字w在地址库中出现总次数.itf-w和wf-w分别为单字w的频率权重值和逆频率权重值,由公式(8)与公式(9)得到,将两值相乘得到单字最终权重.
(8)
(9)
得到单字权重之后,将结果更新到置换矩阵中,更新方式如公式(10)所示:
(10)
其中E为固定的缩放因子常数;res为计算得到的单字权重,N为原置换矩阵中的负常数.
算法1. 地址单字检索求权:
输入:待统计的地址库T(dn)
第n条地址信息dn
输出:R(φn):经过统计计算地址的权重表;
φn:表中第n条的权重结果
1. initialization;
2.whileaddress-unvisited=∅do
3. next-address:j←selectAdd(i);
4.ifaddress-unvisited≠∅then
5.break;
6.else
7. next-address:w← selectAdd(0,1…Len);
8. perWordRow:w ← perWordRow+1;
9.end
10.end
11.Perform:
12. itf-w ←getItf(perWordRow,perWordSum);
13. wf-w ←getWf(perWordRow.perWordSum);
14.res← getRes(itf-w,wf-w);
15.Returnres
3.3 基于动态匹配的相似度打分
相似度计算是地址匹配过程中非常重要的环节,是提升匹配精度的重要方法.本文将连续的数字以及单个的中文字符作为字符单元,以此将地址文本转化为离散的字符单元的顺序排列,数字0-9以及字母a-z、A-Z因为本身特殊性,使用所有单字权重的均值[13,14]代替.记输入地址文本序列为S,比对地址序列为T,相似度计算的数学表达如公式(11)所示,结合置换矩阵、空位罚分策略和打分矩阵得到:
(11)
其中si为文本序列S的第i位字符,tj为文本序列T的第j位字符.k为文本序列S插入的空位数,l为文本序列T插入的空位数.
在计算矩阵C的过程中,矩阵元素Ci,j取3种计算方式得到的相似度的最大值作为该矩阵元素Ci,j的值,在序列S和序列T的空位插入会在匹配过程中出现,加入空位操作也会使对应参数加一.当完成C矩阵全部元素的计算后,遍历矩阵找到相似度最高的点即为匹配结果.从最优点出发往左上方回溯得到次大值即可得到最相似片段,输入地址文本S继续匹配,记录匹配得分,直至完成地址库中所有地址T的比对.
3.4 排序归一化
排序可以显著减少结果集合的冗余,提升匹配精度.结合归一化打分,能够兼顾全局和局部匹配能力的提升[15].排序归一化可以保留低分高相似地址,也能防止结果集重复冗余.
首先进行得分归一化.在计算出输入地址序列S和地址库中地址T之间的相似度k的基础上,除以两条序列较长者的长度,均衡长短序列的分值差异,即:m=length(S),n=length(T),max(m,n)=g,S和T的归一化计算公式如公式(12)所示:
(12)
i(S,T)的值代表相似得分与长度的比值,归一值越大,相似部分占序列本身的比例就越大.
在完成相似度计算与排序归一化之后,考虑到地址匹配结果多样性的要求,本文引入了小顶堆模型[16].小顶堆是一种特殊的树形数据结构,其特点能保证堆顶的值是整个堆中的最小值.小顶堆保证了每个节点的值都小于或等于左右子树的值.每次地址匹配的结果都根据其归一值i(S,T),更新到小顶堆地址树.小顶堆地址树的容量即为需要保留的地址数量.地址树的更新为两个阶段:地址树容量未满时进行地址树构建操作、地址树容量已满时进行地址树更新操作,具体情况见图1,其中字母代表地址元素,数字代表地址元素对应归一值.
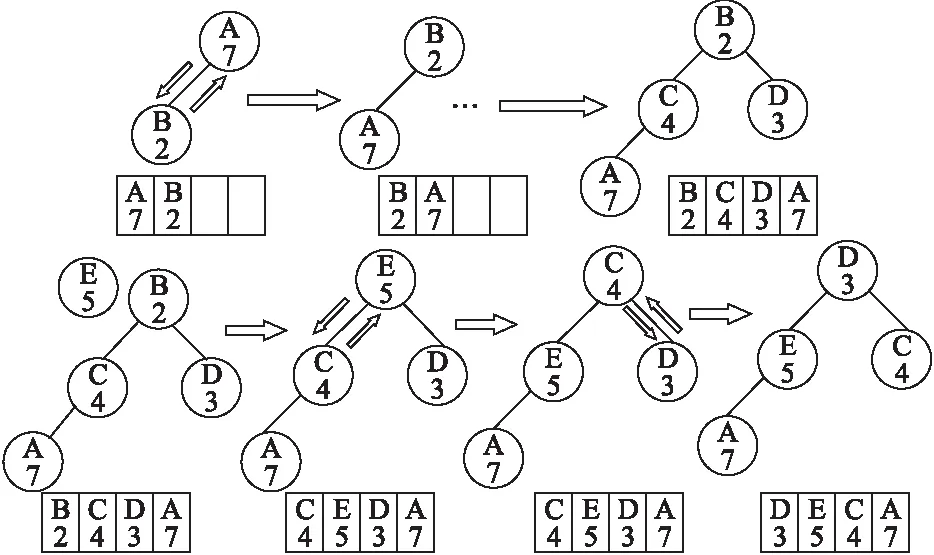
图1 地址树更新Fig.1 Address tree update
地址树构建:当地址树元素未满时,计算归一值,根据小顶堆的性质添加的合适的位置即可.
地址树更新:当地址树元素已满时,则对比新元素与堆顶元素归一值的大小,若新元素值小于堆顶元素值,放弃该元素,反之则弹出堆顶元素,放入新元素.小顶堆会将新放入的元素从堆顶交换到合适的位置,保证堆顶始终是堆中的最小值.小顶堆的最小值对应最差地址匹配结果,通过每次更新淘汰最差元素,保证了最后留在堆中的元素一定是所有匹配结果中归一值最靠前的.
3.5 算法流程
算法的基本思想是:首先,完成打分矩阵、置换矩阵以及空位罚分策略的初始化;统计地址库根据字符重要程度;其次,基于动态规划完成打分矩阵得到相似度,归一化得到最后分值;最后,匹配结果更新到小顶堆,保证结果集的精度以及多样性.算法流程见图2.具体步骤如下:
1)参数设置(空位延长单位罚分u,空位起始罚分v,单字权重缩放因子E);
2)初始化打分矩阵C;
3)初始化空位罚分Wk;
4)初始化置换矩阵R;
5)完成地址库字符出现次数统计,得到单字权重;
6)选中一条地址,结合单字权重,空位罚分完成打分矩阵计算,遍历得到最高分值,归一化之后更新到地址结果集;
7)判断是否完成全地址库比对,完成则输出地址结果集,否则回到步骤6).

图2 地址动态匹配算法流程图Fig.2 Address dynamic matching algorithm
4 实验结果与分析
地理数据集使用杭州市的矢量数据(1:30万),基于网络连通性构建了杭州市实际道路的路网模型.用以检验本文算法的有效性.
完全精准的地址匹配容易实现,但是现实生活经常有人会对地址进行错误描述.本文考虑到日常语言使用习惯,整理了3类错误类型:错别字,如注意力不集中导致的输入错误,或者认知中对同音字和形近字的误判;词义转化,意义相同,仅仅命名习惯存在区别,比如幢、栋、号、楼等等[17];去除地址非相关信息的简写.针对以上错误建立了测试集如表1所示,地址库中各区地址字段总数为Count,测试集地址字段总数Test为2000,对应区域所含待匹配地址字段总数为Test×Scale,如:测试集含萧山区地址字段总数为419.

表1 测试数据集Table 1 Test data set
4.1 算法性能分析
为了验证本文算法的有效性,实验测试平台使用8核CPU(R7-4800H),主频2.9GHz,16G内存笔记本;操作系统Windows10家庭版,基于Java的JDK1.8版本,进行算法验证.算法代码使用IntelliJ IDEA 2019.1编写.算法初始化参数设置空位延长单位罚分u为-1,空位起始罚分v为-1,空位初始个数k为0;单字权重初始值E为10,单字错配常数N为-1;小顶堆模型容量为10.
在测试集上完成算法的运行,统计得到本算法在不同错误类型上的表现.具体结果如图3所示,通过图3看出,本算法在应对不同错误类型时表现出明显差异:词义转换类结果最好,正确率达到了100%.错别字类也得到了较好的结果,平均正确率89.46%,而且效果并没有随着错别字的增加而变差,证明了本算法能够较好的应对错字.删除非相关字符类别的错误结果较差,正确率为51%,考虑到文本过度精简容易丢失关键信息[18],地址库层面的匹配难以判断,故正确率仍在可接受的范围内.

图3 地址测试集多组别类型结果Fig.3 Address test set multi-group type result
为了更好的衡量算法的性能,这里将实验结果进行细分统计,使用了召回率R、查准率P以及F值作为评价指标.
假定在测试数据的分类结果中,X代表错误地址的匹配结果集里存在对应的标准地址且排名第一位为该标准地址的地址数;Y代表错误地址的匹配结果集里存在对应的标准地址但该标准地址不为排名第一位的地址数;Z代表错误地址的匹配结果集里不存在对应的标准地址的地址数.具体的公式表示为:
(13)
(14)
(15)

图4 地址测试相关统计结果Fig.4 Address test set multi-group type result
通过表2与图4可以得出,在测试结果集里各错误类型地址的查准率表现均为良好,在错别字与词义转换类型上更是高达94%.召回率R可看作算法的鲁棒性,可表征结果集中包含标准地址的概率,其值越大说明算法鲁棒性越强,能给使用者提供较为合理的结果.F值综合考虑了查准率P与召回率R,数值上表现良好,说明该算法比较稳定.
表2 测试数据相关统计参数
Table 2 Related statistical parameters of test set results
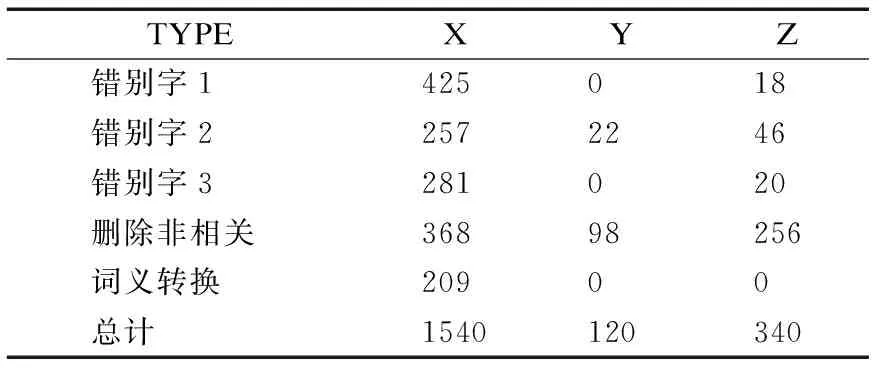
TYPEXYZ错别字1425018错别字22572246错别字3281020删除非相关36898256词义转换20900总计1540120340
为了验证匹配结果的地理分布情况,根据3.4节的归一化值i(S,T),我们将每组测试数据中i值最大的地址作为基准点,分别与其余次优点作距离计算,求得平均置信距离.置信距离计算公式[19]具体如下:
(16)
(17)
(18)
f3=cosφ2cosφ1
(19)
其中d为各组的基准点与次优点之间的地理距离,r为地球赤道半径,φ2为基准点的经度弧度,φ1为次优点的经度弧度,λ2为基准点的纬度弧度,λ1为次优点的纬度弧度.
由图5可以看出来,置信距离小于20千米的测试案例占72%,其中置信距离小于10千米占测试案例的48%.考虑到此计算思路非计算各地址点的平均绝对距离而是通过确定一个基准点算其两者的平均相对距离.说明该算法匹配结果聚散情况良好,可满足于实际的地理聚散程度要求.

图5 组间平均置信距离Fig.5 Average confidence distance between groups
最后将该算法运用于实际路网系中测试,从图6中可以看出次优地址(如图6中圆形所示)分布在最优地址(如图6中五角星所示)附近,说明在满足多样性的要求下,匹配结果的各地址之间相距良好,说明可适用于实际模糊搜索场景.

图6 匹配结果Fig.6 Result of matching
5 结 论
本文针对常见的中文地址错误类型,提出了一种基于动态规划的地址匹配方法.参考生物信息学的序列比对思想,引入非均值权重与空位罚分策略增加了动态匹配算法的性能,提升了匹配精度.使用排序均一化策略提升了匹配的效率,提升了结果的多样性.最后在杭州市实际路网上验证了算法的有效性最后将算法应用到杭州市实际中文地址匹配问题上,实验结果证明了本文算法是可行且有效的.
